 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Emergent Communication in Competitive Multi-Agent Teams
Mar 04, 2020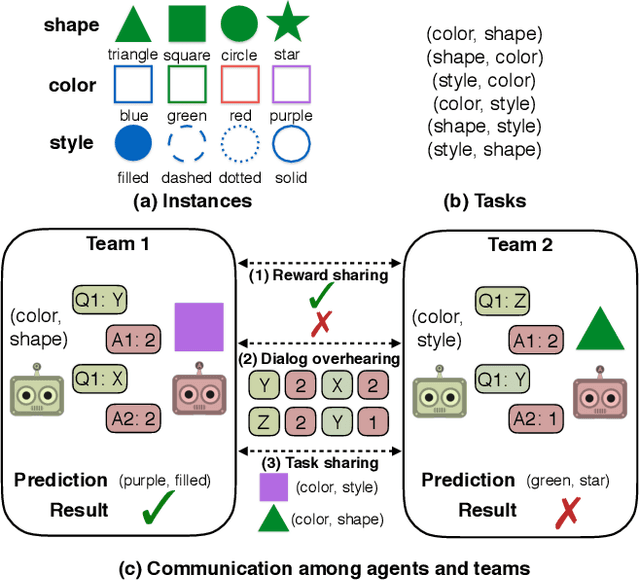
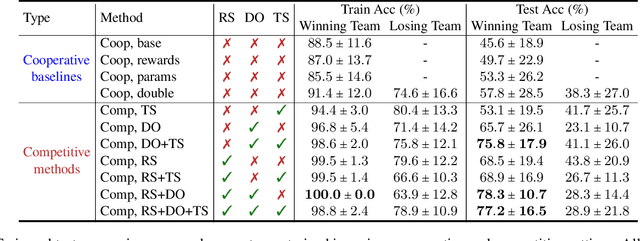
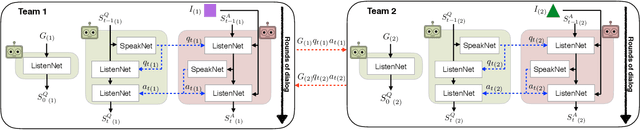
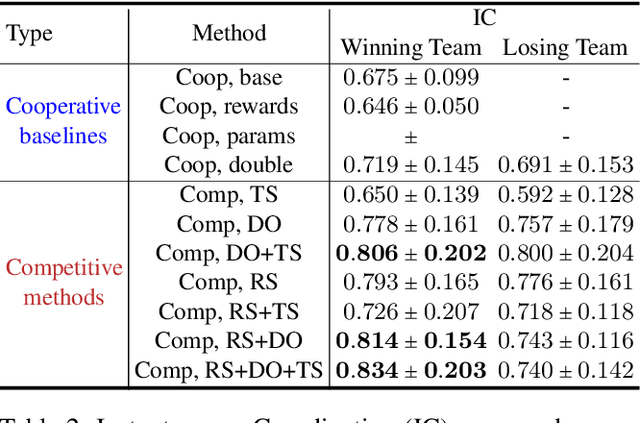
Several recent works have found the emergence of grounded compositional language in the communication protocols developed by mostly cooperative multi-agent systems when learned end-to-end to maximize performance on a downstream task. However, human populations learn to solve complex tasks involving communicative behaviors not only in fully cooperative settings but also in scenarios where competition acts as an additional external pressure for improvement. In this work, we investigate whether competition for performance from an external, similar agent team could act as a social influence that encourages multi-agent populations to develop better communication protocols for improved performance, compositionality, and convergence speed. We start from Task & Talk, a previously proposed referential game between two cooperative agents as our testbed and extend it into Task, Talk & Compete, a game involving two competitive teams each consisting of two aforementioned cooperative agents. Using this new setting, we provide an empirical study demonstrating the impact of competitive influence on multi-agent teams. Our results show that an external competitive influence leads to improved accuracy and generalization, as well as faster emergence of communicative languages that are more informative and compositional.
Capsules with Inverted Dot-Product Attention Routing
Feb 26, 2020
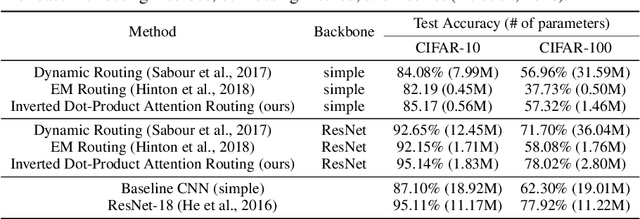
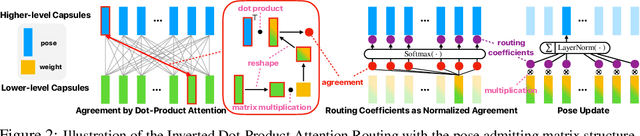
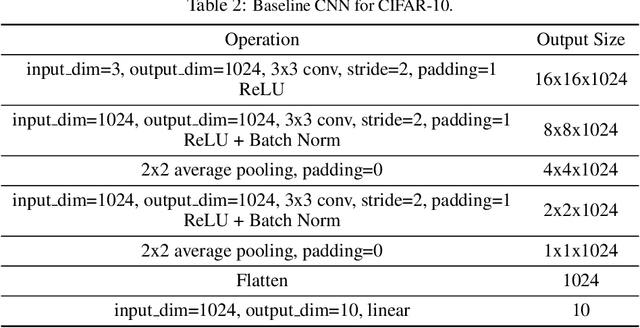
We introduce a new routing algorithm for capsule networks, in which a child capsule is routed to a parent based only on agreement between the parent's state and the child's vote. The new mechanism 1) designs routing via inverted dot-product attention; 2) imposes Layer Normalization as normalization; and 3) replaces sequential iterative routing with concurrent iterative routing. When compared to previously proposed routing algorithms, our method improves performance on benchmark datasets such as CIFAR-10 and CIFAR-100, and it performs at-par with a powerful CNN (ResNet-18) with 4x fewer parameters. On a different task of recognizing digits from overlayed digit images, the proposed capsule model performs favorably against CNNs given the same number of layers and neurons per layer. We believe that our work raises the possibility of applying capsule networks to complex real-world tasks. Our code is publicly available at: https://github.com/apple/ml-capsules-inverted-attention-routing An alternative implementation is available at: https://github.com/yaohungt/Capsules-Inverted-Attention-Routing/blob/master/README.md
Rewriting History with Inverse RL: Hindsight Inference for Policy Improvement
Feb 25, 2020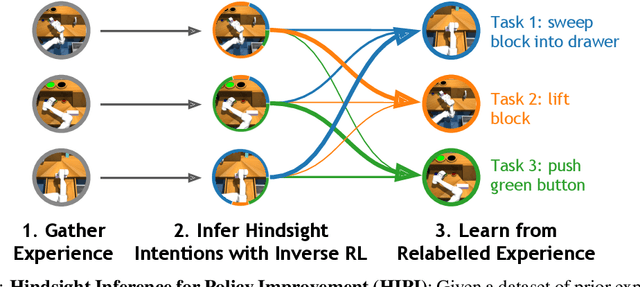
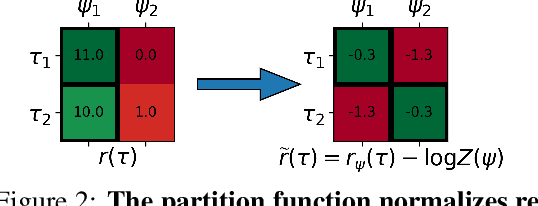

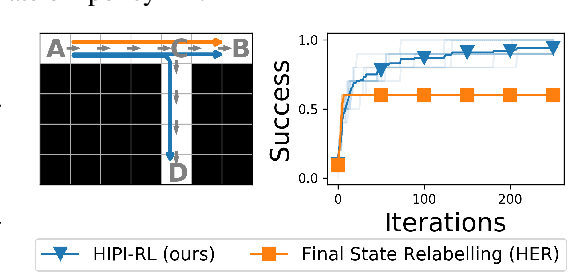
Multi-task reinforcement learning (RL) aims to simultaneously learn policies for solving many tasks. Several prior works have found that relabeling past experience with different reward functions can improve sample efficiency. Relabeling methods typically ask: if, in hindsight, we assume that our experience was optimal for some task, for what task was it optimal? In this paper, we show that hindsight relabeling is inverse RL, an observation that suggests that we can use inverse RL in tandem for RL algorithms to efficiently solve many tasks. We use this idea to generalize goal-relabeling techniques from prior work to arbitrary classes of tasks. Our experiments confirm that relabeling data using inverse RL accelerates learning in general multi-task settings, including goal-reaching, domains with discrete sets of rewards, and those with linear reward functions.
Differentiable Reasoning over a Virtual Knowledge Base
Feb 25, 2020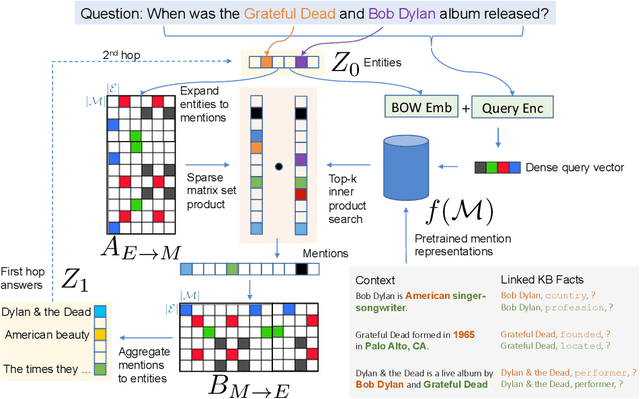
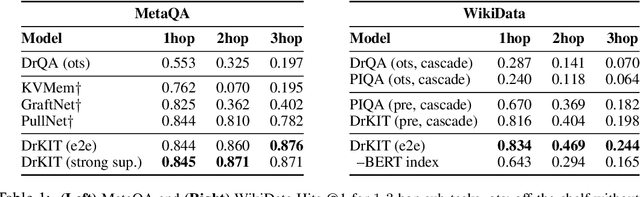
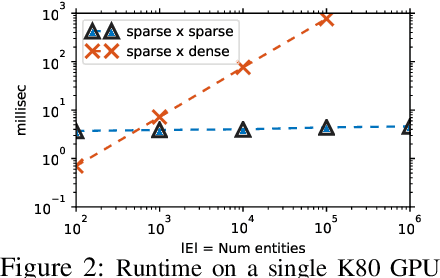
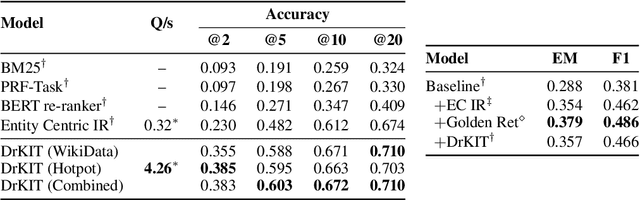
We consider the task of answering complex multi-hop questions using a corpus as a virtual knowledge base (KB). In particular, we describe a neural module, DrKIT, that traverses textual data like a KB, softly following paths of relations between mentions of entities in the corpus. At each step the module uses a combination of sparse-matrix TFIDF indices and a maximum inner product search (MIPS) on a special index of contextual representations of the mentions. This module is differentiable, so the full system can be trained end-to-end using gradient based methods, starting from natural language inputs. We also describe a pretraining scheme for the contextual representation encoder by generating hard negative examples using existing knowledge bases. We show that DrKIT improves accuracy by 9 points on 3-hop questions in the MetaQA dataset, cutting the gap between text-based and KB-based state-of-the-art by 70%. On HotpotQA, DrKIT leads to a 10% improvement over a BERT-based re-ranking approach to retrieving the relevant passages required to answer a question. DrKIT is also very efficient, processing 10-100x more queries per second than existing multi-hop systems.
Learning Not to Learn in the Presence of Noisy Labels
Feb 16, 2020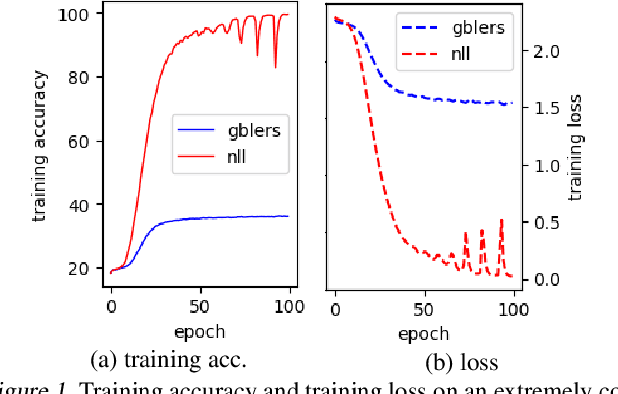

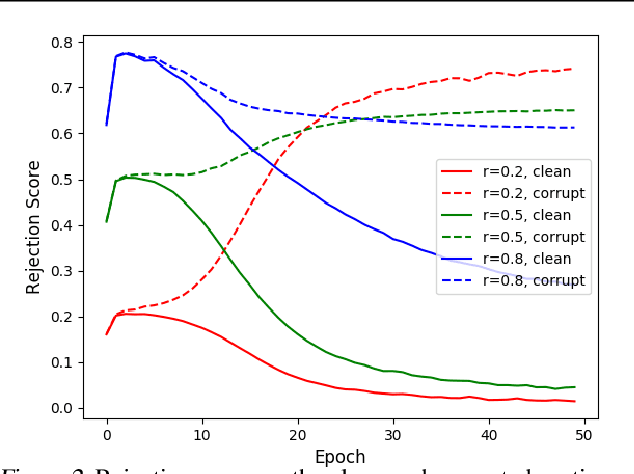
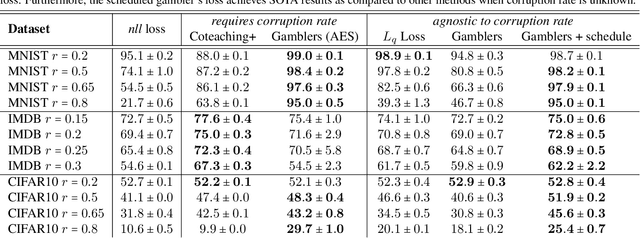
Learning in the presence of label noise is a challenging yet important task: it is crucial to design models that are robust in the presence of mislabeled datasets. In this paper, we discover that a new class of loss functions called the gambler's loss provides strong robustness to label noise across various levels of corruption. We show that training with this loss function encourages the model to "abstain" from learning on the data points with noisy labels, resulting in a simple and effective method to improve robustness and generalization. In addition, we propose two practical extensions of the method: 1) an analytical early stopping criterion to approximately stop training before the memorization of noisy labels, as well as 2) a heuristic for setting hyperparameters which do not require knowledge of the noise corruption rate. We demonstrate the effectiveness of our method by achieving strong results across three image and text classification tasks as compared to existing baselines.
Think Locally, Act Globally: Federated Learning with Local and Global Representations
Jan 06, 2020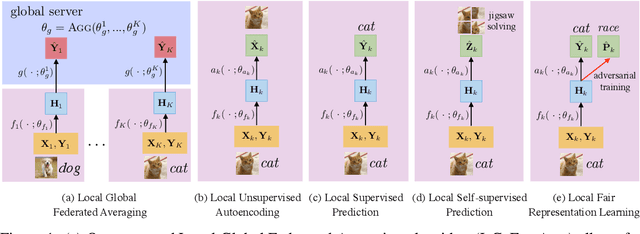

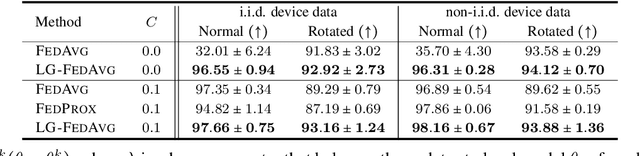
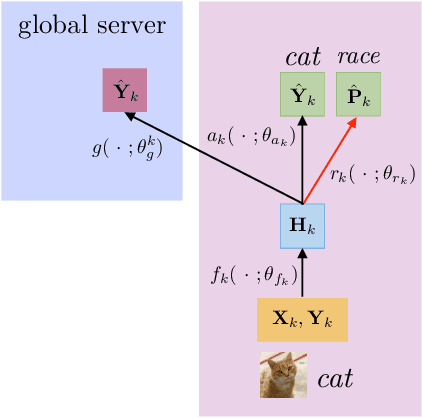
Federated learning is an emerging research paradigm to train models on private data distributed over multiple devices. A key challenge involves keeping private all the data on each device and training a global model only by communicating parameters and updates. Overcoming this problem relies on the global model being sufficiently compact so that the parameters can be efficiently sent over communication channels such as wireless internet. Given the recent trend towards building deeper and larger neural networks, deploying such models in federated settings on real-world tasks is becoming increasingly difficult. To this end, we propose to augment federated learning with local representation learning on each device to learn useful and compact features from raw data. As a result, the global model can be smaller since it only operates on higher-level local representations. We show that our proposed method achieves superior or competitive results when compared to traditional federated approaches on a suite of publicly available real-world datasets spanning image recognition (MNIST, CIFAR) and multimodal learning (VQA). Our choice of local representation learning also reduces the number of parameters and updates that need to be communicated to and from the global model, thereby reducing the bottleneck in terms of communication cost. Finally, we show that our local models provide flexibility in dealing with online heterogeneous data and can be easily modified to learn fair representations that obfuscate protected attributes such as race, age, and gender, a feature crucial to preserving the privacy of on-device data.
Multiple Futures Prediction
Dec 06, 2019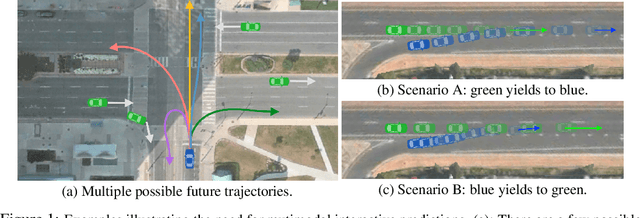
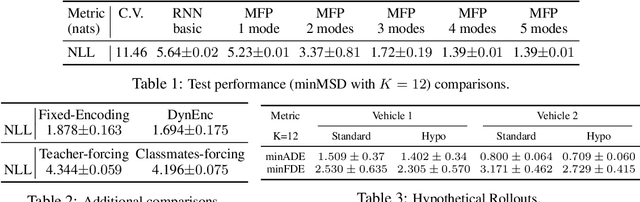
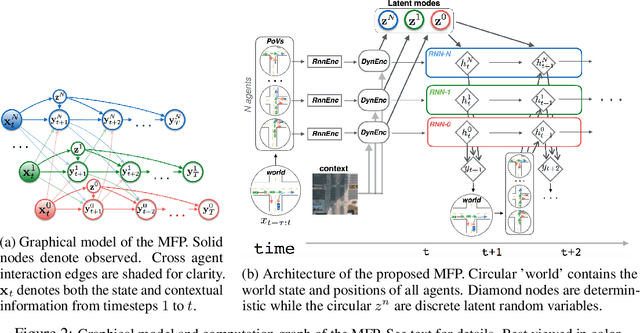
Temporal prediction is critical for making intelligent and robust decisions in complex dynamic environments. Motion prediction needs to model the inherently uncertain future which often contains multiple potential outcomes, due to multi-agent interactions and the latent goals of others. Towards these goals, we introduce a probabilistic framework that efficiently learns latent variables to jointly model the multi-step future motions of agents in a scene. Our framework is data-driven and learns semantically meaningful latent variables to represent the multimodal future, without requiring explicit labels. Using a dynamic attention-based state encoder, we learn to encode the past as well as the future interactions among agents, efficiently scaling to any number of agents. Finally, our model can be used for planning via computing a conditional probability density over the trajectories of other agents given a hypothetical rollout of the 'self' agent. We demonstrate our algorithms by predicting vehicle trajectories of both simulated and real data, demonstrating the state-of-the-art results on several vehicle trajectory datasets.
Geometric Capsule Autoencoders for 3D Point Clouds
Dec 06, 2019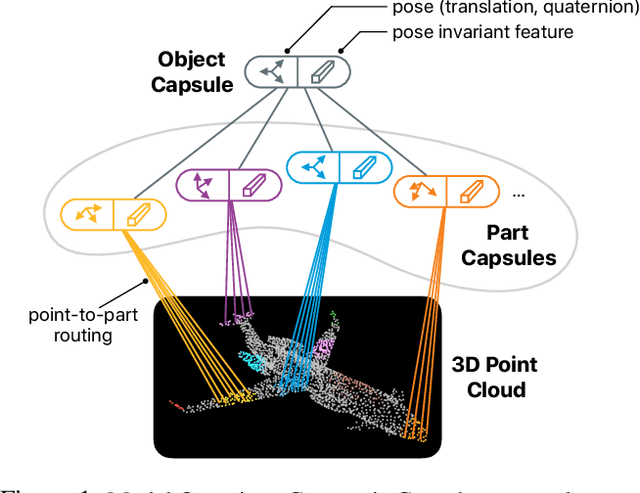

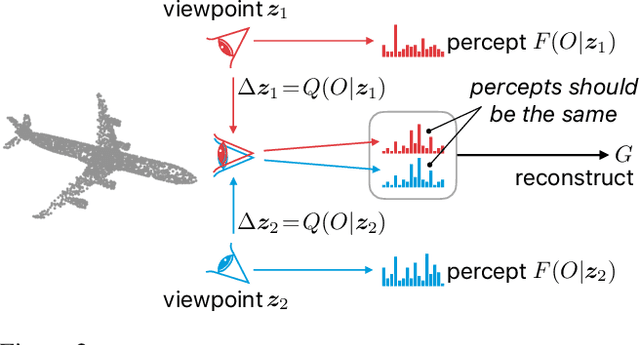
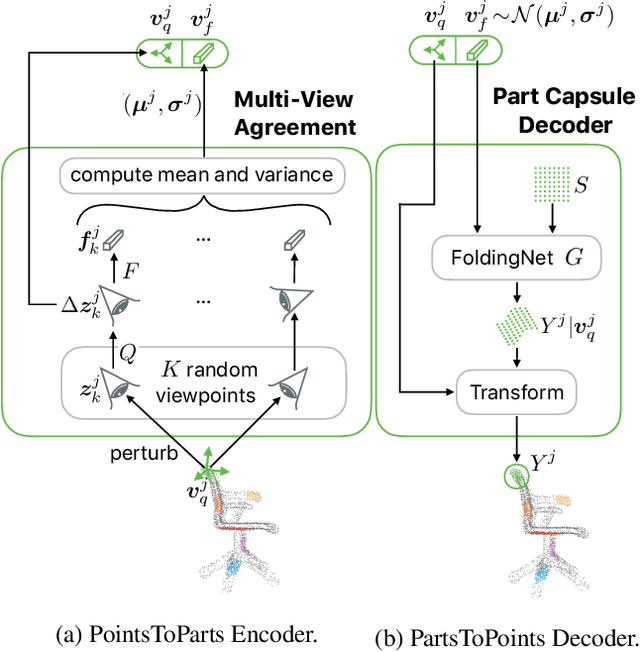
We propose a method to learn object representations from 3D point clouds using bundles of geometrically interpretable hidden units, which we call geometric capsules. Each geometric capsule represents a visual entity, such as an object or a part, and consists of two components: a pose and a feature. The pose encodes where the entity is, while the feature encodes what it is. We use these capsules to construct a Geometric Capsule Autoencoder that learns to group 3D points into parts (small local surfaces), and these parts into the whole object, in an unsupervised manner. Our novel Multi-View Agreement voting mechanism is used to discover an object's canonical pose and its pose-invariant feature vector. Using the ShapeNet and ModelNet40 datasets, we analyze the properties of the learned representations and show the benefits of having multiple votes agree. We perform alignment and retrieval of arbitrarily rotated objects -- tasks that evaluate our model's object identification and canonical pose recovery capabilities -- and obtained insightful results.
Worst Cases Policy Gradients
Nov 09, 2019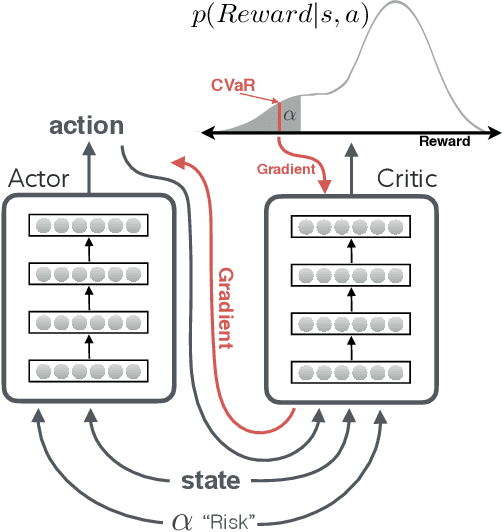
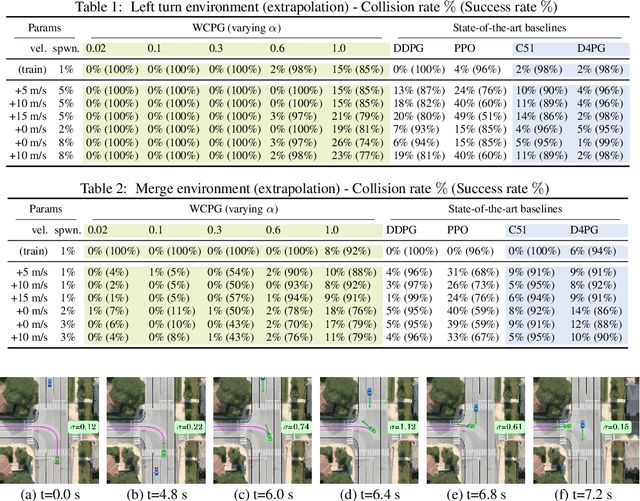
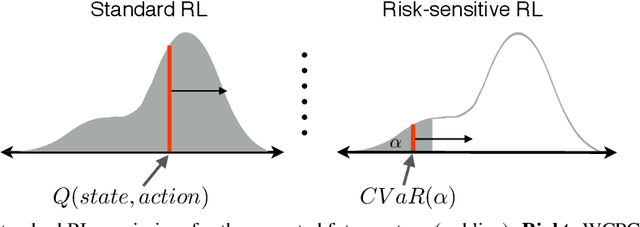

Recent advances in deep reinforcement learning have demonstrated the capability of learning complex control policies from many types of environments. When learning policies for safety-critical applications, it is essential to be sensitive to risks and avoid catastrophic events. Towards this goal, we propose an actor-critic framework that models the uncertainty of the future and simultaneously learns a policy based on that uncertainty model. Specifically, given a distribution of the future return for any state and action, we optimize policies for varying levels of conditional Value-at-Risk. The learned policy can map the same state to different actions depending on the propensity for risk. We demonstrate the effectiveness of our approach in the domain of driving simulations, where we learn maneuvers in two scenarios. Our learned controller can dynamically select actions along a continuous axis, where safe and conservative behaviors are found at one end while riskier behaviors are found at the other. Finally, when testing with very different simulation parameters, our risk-averse policies generalize significantly better compared to other reinforcement learning approaches.
Enhanced Convolutional Neural Tangent Kernels
Nov 03, 2019
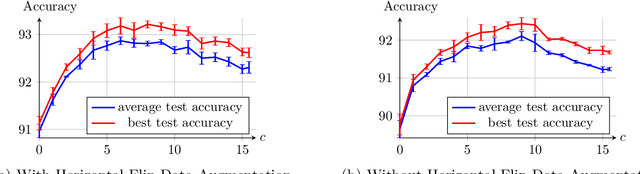
Recent research shows that for training with $\ell_2$ loss, convolutional neural networks (CNNs) whose width (number of channels in convolutional layers) goes to infinity correspond to regression with respect to the CNN Gaussian Process kernel (CNN-GP) if only the last layer is trained, and correspond to regression with respect to the Convolutional Neural Tangent Kernel (CNTK) if all layers are trained. An exact algorithm to compute CNTK (Arora et al., 2019) yielded the finding that classification accuracy of CNTK on CIFAR-10 is within 6-7% of that of that of the corresponding CNN architecture (best figure being around 78%) which is interesting performance for a fixed kernel. Here we show how to significantly enhance the performance of these kernels using two ideas. (1) Modifying the kernel using a new operation called Local Average Pooling (LAP) which preserves efficient computability of the kernel and inherits the spirit of standard data augmentation using pixel shifts. Earlier papers were unable to incorporate naive data augmentation because of the quadratic training cost of kernel regression. This idea is inspired by Global Average Pooling (GAP), which we show for CNN-GP and CNTK is equivalent to full translation data augmentation. (2) Representing the input image using a pre-processing technique proposed by Coates et al. (2011), which uses a single convolutional layer composed of random image patches. On CIFAR-10, the resulting kernel, CNN-GP with LAP and horizontal flip data augmentation, achieves 89% accuracy, matching the performance of AlexNet (Krizhevsky et al., 2012). Note that this is the best such result we know of for a classifier that is not a trained neural network. Similar improvements are obtained for Fashion-MNIST.