 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Game Code World Model Generation into Lightweight Large Language Models
May 23, 2026Large Language Models (LLMs) have shown great ability in generating executable code from natural language, opening the possibility of automatically constructing environments for AI agents. Recent work on Code World Models (CWMs) demonstrates that LLMs can translate game rules into Python implementations compatible with solvers like Monte Carlo Tree Search. We study this problem in game settings, where generated environments must implement rules, legal actions, state transitions, observations, and rewards. We refer to these game-specific executable models as Game Code World Models (GameCWMs). However, current approaches to generating code world models rely on frontier models and inference-time refinement loops, limiting accessibility and scalability. This work investigates whether GameCWM generation capabilities can be distilled into smaller models through post-training. We introduce: (1) a curated dataset of 30 games spanning perfect and imperfect information games, (2) a verification framework that evaluates generated code against structural and semantic game properties, and (3) a post-training pipeline combining Supervised Fine-Tuning (SFT) with Reinforcement Learning with Verifiable Rewards (RLVR). We experiment with Qwen2.5-3B-Instruct and find that SFT can increase syntactic correctness, while RLVR can improve execution-level adherence to game rules, thereby improving Qwen's ability to generate valid GameCWMs in both perfect and imperfect information games. Overall, our pipeline makes Qwen2.5-3B-Instruct more capable of generating valid GameCWMs, thereby offering a scalable path toward automatic environment generation from natural language.
Spectral Collapse Drives Loss of Plasticity in Deep Continual Learning
Sep 26, 2025

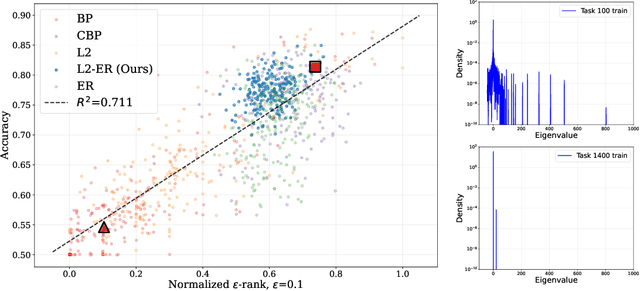

We investigate why deep neural networks suffer from \emph{loss of plasticity} in deep continual learning, failing to learn new tasks without reinitializing parameters. We show that this failure is preceded by Hessian spectral collapse at new-task initialization, where meaningful curvature directions vanish and gradient descent becomes ineffective. To characterize the necessary condition for successful training, we introduce the notion of $\tau$-trainability and show that current plasticity preserving algorithms can be unified under this framework. Targeting spectral collapse directly, we then discuss the Kronecker factored approximation of the Hessian, which motivates two regularization enhancements: maintaining high effective feature rank and applying $L2$ penalties. Experiments on continual supervised and reinforcement learning tasks confirm that combining these two regularizers effectively preserves plasticity.
Bi-Level Policy Optimization with Nyström Hypergradients
May 16, 2025The dependency of the actor on the critic in actor-critic (AC) reinforcement learning means that AC can be characterized as a bilevel optimization (BLO) problem, also called a Stackelberg game. This characterization motivates two modifications to vanilla AC algorithms. First, the critic's update should be nested to learn a best response to the actor's policy. Second, the actor should update according to a hypergradient that takes changes in the critic's behavior into account. Computing this hypergradient involves finding an inverse Hessian vector product, a process that can be numerically unstable. We thus propose a new algorithm, Bilevel Policy Optimization with Nystr\"om Hypergradients (BLPO), which uses nesting to account for the nested structure of BLO, and leverages the Nystr\"om method to compute the hypergradient. Theoretically, we prove BLPO converges to (a point that satisfies the necessary conditions for) a local strong Stackelberg equilibrium in polynomial time with high probability, assuming a linear parametrization of the critic's objective. Empirically, we demonstrate that BLPO performs on par with or better than PPO on a variety of discrete and continuous control tasks.
On the Fairness of 'Fake' Data in Legal AI
Sep 11, 2020The economics of smaller budgets and larger case numbers necessitates the use of AI in legal proceedings. We examine the concept of disparate impact and how biases in the training data lead to the search for fairer AI. This paper seeks to begin the discourse on what such an implementation would actually look like with a criticism of pre-processing methods in a legal context . We outline how pre-processing is used to correct biased data and then examine the legal implications of effectively changing cases in order to achieve a fairer outcome including the black box problem and the slow encroachment on legal precedent. Finally we present recommendations on how to avoid the pitfalls of pre-processed data with methods that either modify the classifier or correct the output in the final step.
Clustering volatility regimes for dynamic trading strategies
Apr 21, 2020
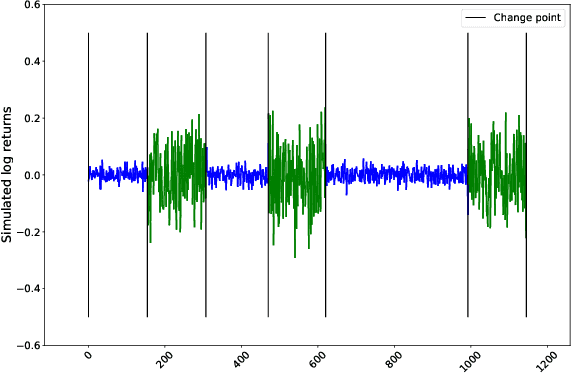
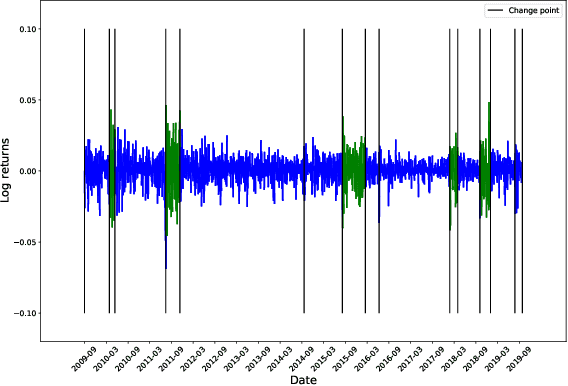
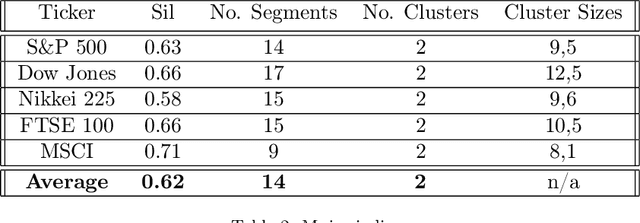
We develop a new method to find the number of volatility regimes in a non-stationary financial time series. We use change point detection to partition a time series into locally stationary segments, then estimate the distributions of each piece. The distributions are clustered into a learned number of discrete volatility regimes via an optimisation routine. Using this method, we investigate and determine a clustering structure for indices, large cap equities and exchange-traded funds. Finally, we create and validate a dynamic portfolio allocation strategy that learns the optimal match between the current distribution of a time series with its past regimes, thereby making online risk-avoidance decisions in the present.