 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapVision: CVPR 2024 Autonomous Grand Challenge Mapless Driving Tech Report
Jun 14, 2024



Autonomous driving without high-definition (HD) maps demands a higher level of active scene understanding. In this competition, the organizers provided the multi-perspective camera images and standard-definition (SD) maps to explore the boundaries of scene reasoning capabilities. We found that most existing algorithms construct Bird's Eye View (BEV) features from these multi-perspective images and use multi-task heads to delineate road centerlines, boundary lines, pedestrian crossings, and other areas. However, these algorithms perform poorly at the far end of roads and struggle when the primary subject in the image is occluded. Therefore, in this competition, we not only used multi-perspective images as input but also incorporated SD maps to address this issue. We employed map encoder pre-training to enhance the network's geometric encoding capabilities and utilized YOLOX to improve traffic element detection precision. Additionally, for area detection, we innovatively introduced LDTR and auxiliary tasks to achieve higher precision. As a result, our final OLUS score is 0.58.
LDTR: Transformer-based Lane Detection with Anchor-chain Representation
Mar 21, 2024Despite recent advances in lane detection methods, scenarios with limited- or no-visual-clue of lanes due to factors such as lighting conditions and occlusion remain challenging and crucial for automated driving. Moreover, current lane representations require complex post-processing and struggle with specific instances. Inspired by the DETR architecture, we propose LDTR, a transformer-based model to address these issues. Lanes are modeled with a novel anchor-chain, regarding a lane as a whole from the beginning, which enables LDTR to handle special lanes inherently. To enhance lane instance perception, LDTR incorporates a novel multi-referenced deformable attention module to distribute attention around the object. Additionally, LDTR incorporates two line IoU algorithms to improve convergence efficiency and employs a Gaussian heatmap auxiliary branch to enhance model representation capability during training. To evaluate lane detection models, we rely on Frechet distance, parameterized F1-score, and additional synthetic metrics. Experimental results demonstrate that LDTR achieves state-of-the-art performance on well-known datasets.
CANet: Curved Guide Line Network with Adaptive Decoder for Lane Detection
Apr 23, 2023



Lane detection is challenging due to the complicated on road scenarios and line deformation from different camera perspectives. Lots of solutions were proposed, but can not deal with corner lanes well. To address this problem, this paper proposes a new top-down deep learning lane detection approach, CANET. A lane instance is first responded by the heat-map on the U-shaped curved guide line at global semantic level, thus the corresponding features of each lane are aggregated at the response point. Then CANET obtains the heat-map response of the entire lane through conditional convolution, and finally decodes the point set to describe lanes via adaptive decoder. The experimental results show that CANET reaches SOTA in different metrics. Our code will be released soon.
S4OD: Semi-Supervised learning for Single-Stage Object Detection
Apr 09, 2022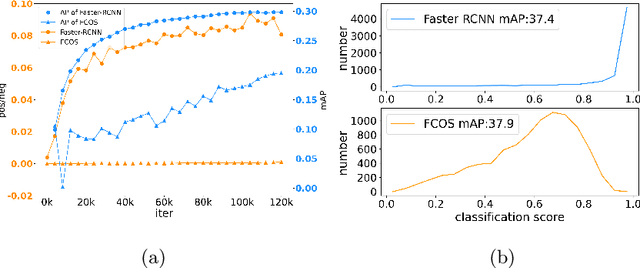
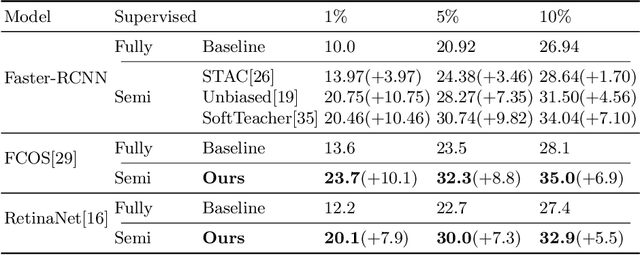
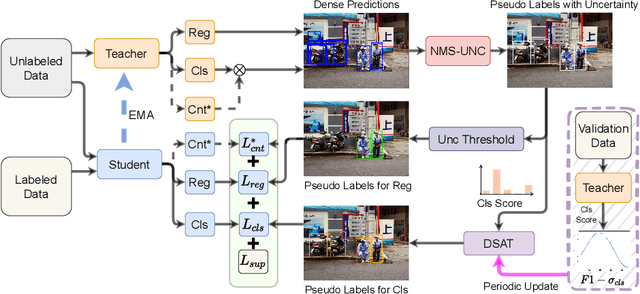

Single-stage detectors suffer from extreme foreground-background class imbalance, while two-stage detectors do not. Therefore, in semi-supervised object detection, two-stage detectors can deliver remarkable performance by only selecting high-quality pseudo labels based on classification scores. However, directly applying this strategy to single-stage detectors would aggravate the class imbalance with fewer positive samples. Thus, single-stage detectors have to consider both quality and quantity of pseudo labels simultaneously. In this paper, we design a dynamic self-adaptive threshold (DSAT) strategy in classification branch, which can automatically select pseudo labels to achieve an optimal trade-off between quality and quantity. Besides, to assess the regression quality of pseudo labels in single-stage detectors, we propose a module to compute the regression uncertainty of boxes based on Non-Maximum Suppression. By leveraging only 10% labeled data from COCO, our method achieves 35.0% AP on anchor-free detector (FCOS) and 32.9% on anchor-based detector (RetinaNet).
An End-to-End Visual-Audio Attention Network for Emotion Recognition in User-Generated Videos
Feb 12, 2020

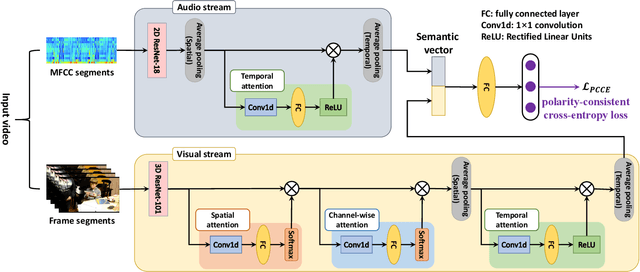

Emotion recognition in user-generated videos plays an important role in human-centered computing. Existing methods mainly employ traditional two-stage shallow pipeline, i.e. extracting visual and/or audio features and training classifiers. In this paper, we propose to recognize video emotions in an end-to-end manner based on convolutional neural networks (CNNs). Specifically, we develop a deep Visual-Audio Attention Network (VAANet), a novel architecture that integrates spatial, channel-wise, and temporal attentions into a visual 3D CNN and temporal attentions into an audio 2D CNN. Further, we design a special classification loss, i.e. polarity-consistent cross-entropy loss, based on the polarity-emotion hierarchy constraint to guide the attention generation. Extensive experiments conducted on the challenging VideoEmotion-8 and Ekman-6 datasets demonstrate that the proposed VAANet outperforms the state-of-the-art approaches for video emotion recognition. Our source code is released at: https://github.com/maysonma/VAANet.
Multi-source Distilling Domain Adaptation
Nov 22, 2019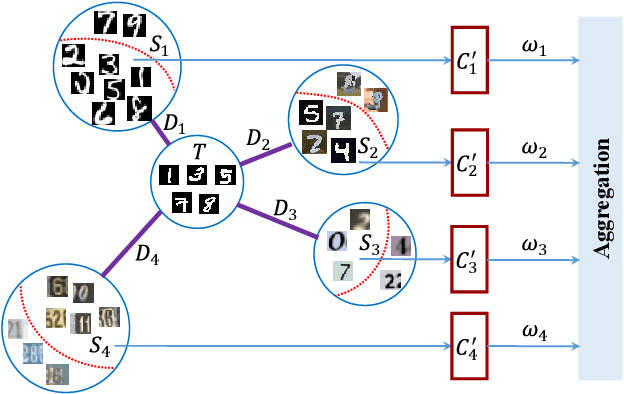
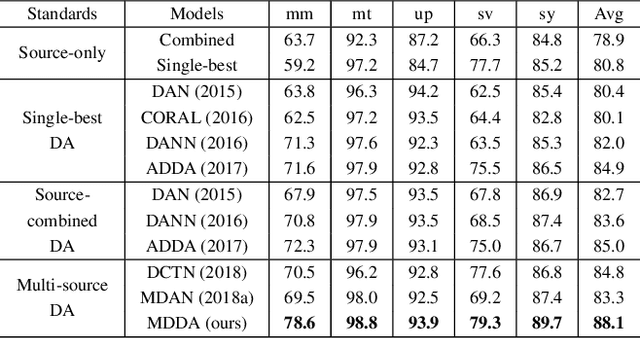
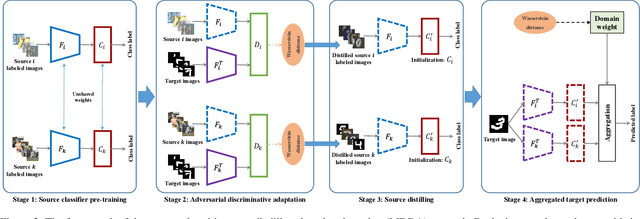
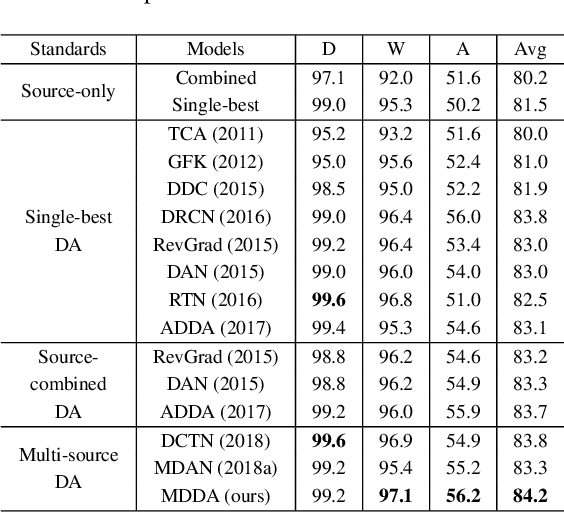
Deep neural networks suffer from performance decay when there is domain shift between the labeled source domain and unlabeled target domain, which motivates the research on domain adaptation (DA). Conventional DA methods usually assume that the labeled data is sampled from a single source distribution. However, in practice, labeled data may be collected from multiple sources, while naive application of the single-source DA algorithms may lead to suboptimal solutions. In this paper, we propose a novel multi-source distilling domain adaptation (MDDA) network, which not only considers the different distances among multiple sources and the target, but also investigates the different similarities of the source samples to the target ones. Specifically, the proposed MDDA includes four stages: (1) pre-train the source classifiers separately using the training data from each source; (2) adversarially map the target into the feature space of each source respectively by minimizing the empirical Wasserstein distance between source and target; (3) select the source training samples that are closer to the target to fine-tune the source classifiers; and (4) classify each encoded target feature by corresponding source classifier, and aggregate different predictions using respective domain weight, which corresponds to the discrepancy between each source and target. Extensive experiments are conducted on public DA benchmarks, and the results demonstrate that the proposed MDDA significantly outperforms the state-of-the-art approaches. Our source code is released at: https://github.com/daoyuan98/MDDA.
Multi-source Domain Adaptation for Semantic Segmentation
Oct 27, 2019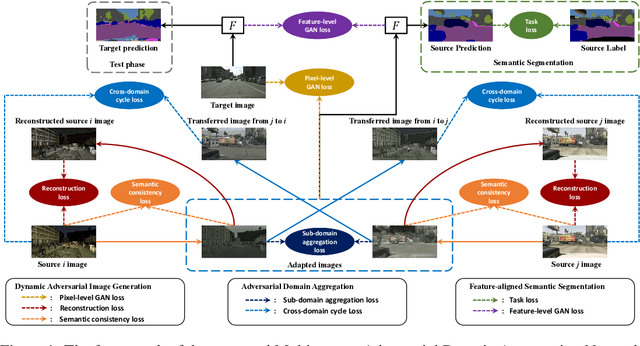

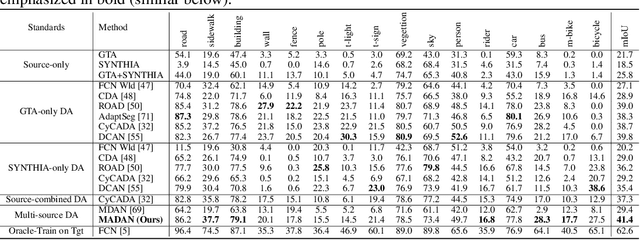

Simulation-to-real domain adaptation for semantic segmentation has been actively studied for various applications such as autonomous driving. Existing methods mainly focus on a single-source setting, which cannot easily handle a more practical scenario of multiple sources with different distributions. In this paper, we propose to investigate multi-source domain adaptation for semantic segmentation. Specifically, we design a novel framework, termed Multi-source Adversarial Domain Aggregation Network (MADAN), which can be trained in an end-to-end manner. First, we generate an adapted domain for each source with dynamic semantic consistency while aligning at the pixel-level cycle-consistently towards the target. Second, we propose sub-domain aggregation discriminator and cross-domain cycle discriminator to make different adapted domains more closely aggregated. Finally, feature-level alignment is performed between the aggregated domain and target domain while training the segmentation network. Extensive experiments from synthetic GTA and SYNTHIA to real Cityscapes and BDDS datasets demonstrate that the proposed MADAN model outperforms state-of-the-art approaches. Our source code is released at: https://github.com/Luodian/MADAN.
ROAM: Recurrently Optimizing Tracking Model
Jul 31, 2019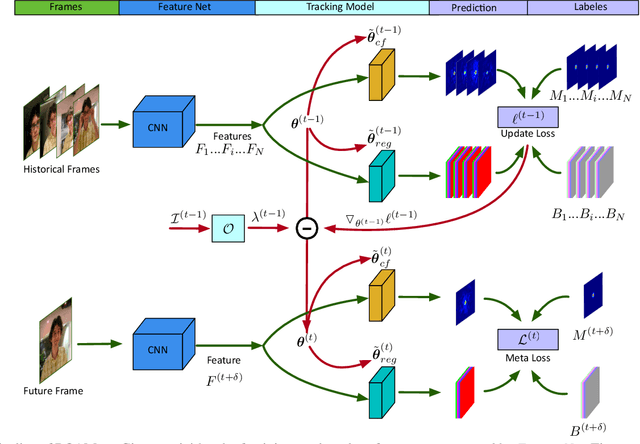
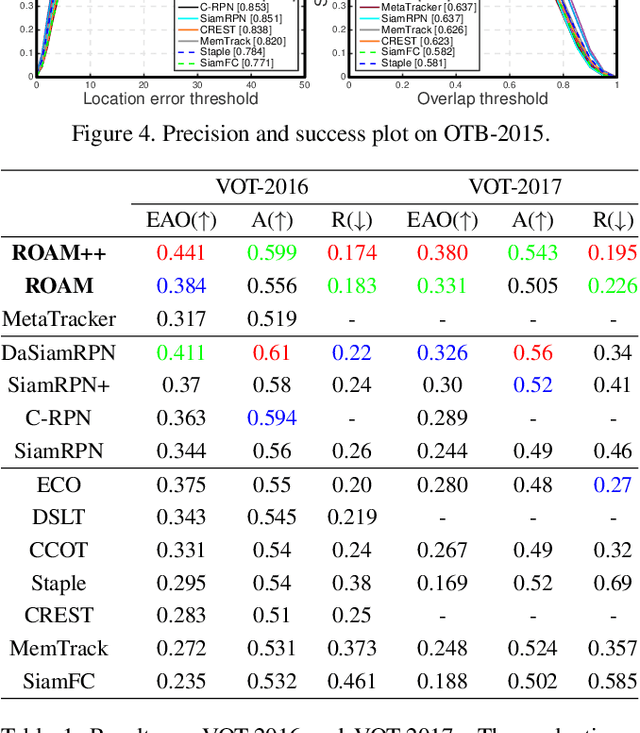
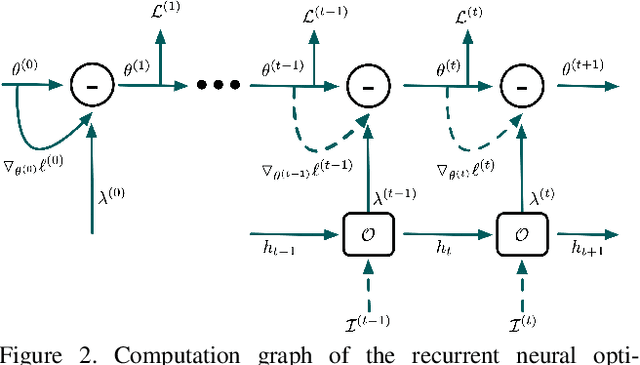
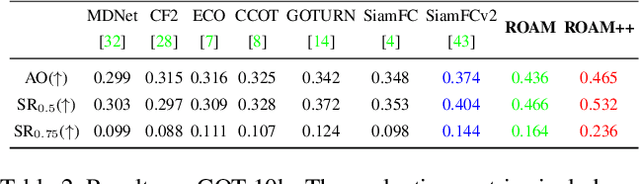
In this paper, we design a tracking model consisting of response generation and bounding box regression, where the first component produces a heat map to indicate the presence of the object at different positions and the second part regresses the relative bounding box shifts to anchors mounted on sliding-window locations. Thanks to the resizable convolutional filters used in both components to adapt to the shape changes of objects, our tracking model does not need to enumerate different sized anchors, thus saving model parameters. To effectively adapt the model to appearance variations, we propose to offline train a recurrent neural optimizer to update tracking model in a meta-learning setting, which can converge the model in a few gradient steps. This improves the convergence speed of updating the tracking model while achieving better performance. Moreover, we also propose a simple yet effective training trick called Random Filter Scaling to prevent overfitting, which boosts the generalization performance greatly. Finally, we extensively evaluate our trackers, ROAM and ROAM++, on the OTB, VOT, LaSOT, GOT-10K and TrackingNet benchmark and our methods perform favorably against state-of-the-art algorithms.