 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffuCoder: Understanding and Improving Masked Diffusion Models for Code Generation
Jun 26, 2025Diffusion large language models (dLLMs) are compelling alternatives to autoregressive (AR) models because their denoising models operate over the entire sequence. The global planning and iterative refinement features of dLLMs are particularly useful for code generation. However, current training and inference mechanisms for dLLMs in coding are still under-explored. To demystify the decoding behavior of dLLMs and unlock their potential for coding, we systematically investigate their denoising processes and reinforcement learning (RL) methods. We train a 7B dLLM, \textbf{DiffuCoder}, on 130B tokens of code. Using this model as a testbed, we analyze its decoding behavior, revealing how it differs from that of AR models: (1) dLLMs can decide how causal their generation should be without relying on semi-AR decoding, and (2) increasing the sampling temperature diversifies not only token choices but also their generation order. This diversity creates a rich search space for RL rollouts. For RL training, to reduce the variance of token log-likelihood estimates and maintain training efficiency, we propose \textbf{coupled-GRPO}, a novel sampling scheme that constructs complementary mask noise for completions used in training. In our experiments, coupled-GRPO significantly improves DiffuCoder's performance on code generation benchmarks (+4.4\% on EvalPlus) and reduces reliance on AR bias during decoding. Our work provides deeper insight into the machinery of dLLM generation and offers an effective, diffusion-native RL training framework. https://github.com/apple/ml-diffucoder.
STARFlow: Scaling Latent Normalizing Flows for High-resolution Image Synthesis
Jun 06, 2025
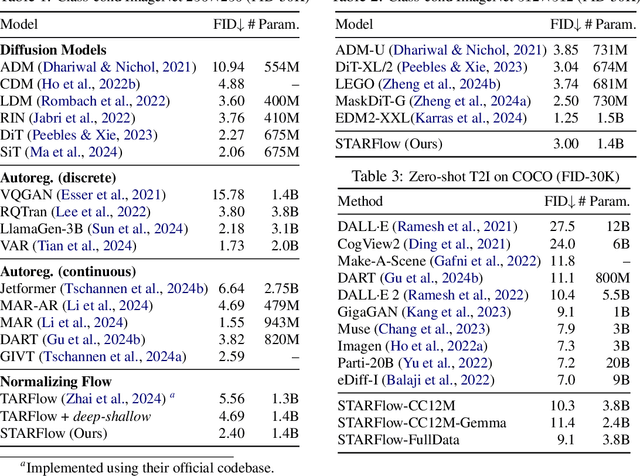
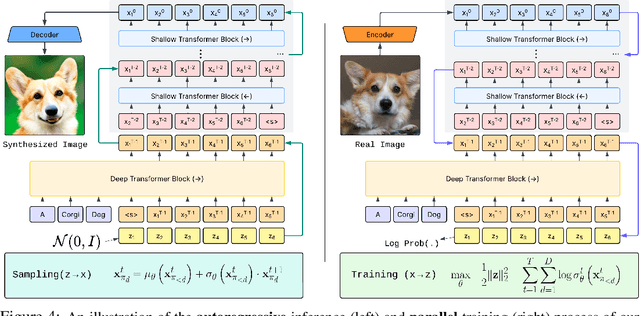
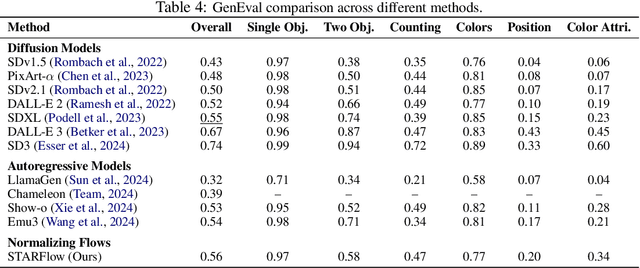
We present STARFlow, a scalable generative model based on normalizing flows that achieves strong performance in high-resolution image synthesis. The core of STARFlow is Transformer Autoregressive Flow (TARFlow), which combines the expressive power of normalizing flows with the structured modeling capabilities of Autoregressive Transformers. We first establish the theoretical universality of TARFlow for modeling continuous distributions. Building on this foundation, we introduce several key architectural and algorithmic innovations to significantly enhance scalability: (1) a deep-shallow design, wherein a deep Transformer block captures most of the model representational capacity, complemented by a few shallow Transformer blocks that are computationally efficient yet substantially beneficial; (2) modeling in the latent space of pretrained autoencoders, which proves more effective than direct pixel-level modeling; and (3) a novel guidance algorithm that significantly boosts sample quality. Crucially, our model remains an end-to-end normalizing flow, enabling exact maximum likelihood training in continuous spaces without discretization. STARFlow achieves competitive performance in both class-conditional and text-conditional image generation tasks, approaching state-of-the-art diffusion models in sample quality. To our knowledge, this work is the first successful demonstration of normalizing flows operating effectively at this scale and resolution.
Discrete Neural Flow Samplers with Locally Equivariant Transformer
May 23, 2025Sampling from unnormalised discrete distributions is a fundamental problem across various domains. While Markov chain Monte Carlo offers a principled approach, it often suffers from slow mixing and poor convergence. In this paper, we propose Discrete Neural Flow Samplers (DNFS), a trainable and efficient framework for discrete sampling. DNFS learns the rate matrix of a continuous-time Markov chain such that the resulting dynamics satisfy the Kolmogorov equation. As this objective involves the intractable partition function, we then employ control variates to reduce the variance of its Monte Carlo estimation, leading to a coordinate descent learning algorithm. To further facilitate computational efficiency, we propose locally equivaraint Transformer, a novel parameterisation of the rate matrix that significantly improves training efficiency while preserving powerful network expressiveness. Empirically, we demonstrate the efficacy of DNFS in a wide range of applications, including sampling from unnormalised distributions, training discrete energy-based models, and solving combinatorial optimisation problems.
Target Concrete Score Matching: A Holistic Framework for Discrete Diffusion
Apr 23, 2025



Discrete diffusion is a promising framework for modeling and generating discrete data. In this work, we present Target Concrete Score Matching (TCSM), a novel and versatile objective for training and fine-tuning discrete diffusion models. TCSM provides a general framework with broad applicability. It supports pre-training discrete diffusion models directly from data samples, and many existing discrete diffusion approaches naturally emerge as special cases of our more general TCSM framework. Furthermore, the same TCSM objective extends to post-training of discrete diffusion models, including fine-tuning using reward functions or preference data, and distillation of knowledge from pre-trained autoregressive models. These new capabilities stem from the core idea of TCSM, estimating the concrete score of the target distribution, which resides in the original (clean) data space. This allows seamless integration with reward functions and pre-trained models, which inherently only operate in the clean data space rather than the noisy intermediate spaces of diffusion processes. Our experiments on language modeling tasks demonstrate that TCSM matches or surpasses current methods. Additionally, TCSM is versatile, applicable to both pre-training and post-training scenarios, offering greater flexibility and sample efficiency.
Reversal Blessing: Thinking Backward May Outpace Thinking Forward in Multi-choice Questions
Feb 25, 2025



Language models usually use left-to-right (L2R) autoregressive factorization. However, L2R factorization may not always be the best inductive bias. Therefore, we investigate whether alternative factorizations of the text distribution could be beneficial in some tasks. We investigate right-to-left (R2L) training as a compelling alternative, focusing on multiple-choice questions (MCQs) as a test bed for knowledge extraction and reasoning. Through extensive experiments across various model sizes (2B-8B parameters) and training datasets, we find that R2L models can significantly outperform L2R models on several MCQ benchmarks, including logical reasoning, commonsense understanding, and truthfulness assessment tasks. Our analysis reveals that this performance difference may be fundamentally linked to multiple factors including calibration, computability and directional conditional entropy. We ablate the impact of these factors through controlled simulation studies using arithmetic tasks, where the impacting factors can be better disentangled. Our work demonstrates that exploring alternative factorizations of the text distribution can lead to improvements in LLM capabilities and provides theoretical insights into optimal factorization towards approximating human language distribution, and when each reasoning order might be more advantageous.
Composition and Control with Distilled Energy Diffusion Models and Sequential Monte Carlo
Feb 18, 2025Diffusion models may be formulated as a time-indexed sequence of energy-based models, where the score corresponds to the negative gradient of an energy function. As opposed to learning the score directly, an energy parameterization is attractive as the energy itself can be used to control generation via Monte Carlo samplers. Architectural constraints and training instability in energy parameterized models have so far yielded inferior performance compared to directly approximating the score or denoiser. We address these deficiencies by introducing a novel training regime for the energy function through distillation of pre-trained diffusion models, resembling a Helmholtz decomposition of the score vector field. We further showcase the synergies between energy and score by casting the diffusion sampling procedure as a Feynman Kac model where sampling is controlled using potentials from the learnt energy functions. The Feynman Kac model formalism enables composition and low temperature sampling through sequential Monte Carlo.
Oriented Tiny Object Detection: A Dataset, Benchmark, and Dynamic Unbiased Learning
Dec 16, 2024Detecting oriented tiny objects, which are limited in appearance information yet prevalent in real-world applications, remains an intricate and under-explored problem. To address this, we systemically introduce a new dataset, benchmark, and a dynamic coarse-to-fine learning scheme in this study. Our proposed dataset, AI-TOD-R, features the smallest object sizes among all oriented object detection datasets. Based on AI-TOD-R, we present a benchmark spanning a broad range of detection paradigms, including both fully-supervised and label-efficient approaches. Through investigation, we identify a learning bias presents across various learning pipelines: confident objects become increasingly confident, while vulnerable oriented tiny objects are further marginalized, hindering their detection performance. To mitigate this issue, we propose a Dynamic Coarse-to-Fine Learning (DCFL) scheme to achieve unbiased learning. DCFL dynamically updates prior positions to better align with the limited areas of oriented tiny objects, and it assigns samples in a way that balances both quantity and quality across different object shapes, thus mitigating biases in prior settings and sample selection. Extensive experiments across eight challenging object detection datasets demonstrate that DCFL achieves state-of-the-art accuracy, high efficiency, and remarkable versatility. The dataset, benchmark, and code are available at https://chasel-tsui.github.io/AI-TOD-R/.
Normalizing Flows are Capable Generative Models
Dec 10, 2024Normalizing Flows (NFs) are likelihood-based models for continuous inputs. They have demonstrated promising results on both density estimation and generative modeling tasks, but have received relatively little attention in recent years. In this work, we demonstrate that NFs are more powerful than previously believed. We present TarFlow: a simple and scalable architecture that enables highly performant NF models. TarFlow can be thought of as a Transformer-based variant of Masked Autoregressive Flows (MAFs): it consists of a stack of autoregressive Transformer blocks on image patches, alternating the autoregression direction between layers. TarFlow is straightforward to train end-to-end, and capable of directly modeling and generating pixels. We also propose three key techniques to improve sample quality: Gaussian noise augmentation during training, a post training denoising procedure, and an effective guidance method for both class-conditional and unconditional settings. Putting these together, TarFlow sets new state-of-the-art results on likelihood estimation for images, beating the previous best methods by a large margin, and generates samples with quality and diversity comparable to diffusion models, for the first time with a stand-alone NF model. We make our code available at https://github.com/apple/ml-tarflow.
Tiny Object Detection with Single Point Supervision
Dec 08, 2024



Tiny objects, with their limited spatial resolution, often resemble point-like distributions. As a result, bounding box prediction using point-level supervision emerges as a natural and cost-effective alternative to traditional box-level supervision. However, the small scale and lack of distinctive features of tiny objects make point annotations prone to noise, posing significant hurdles for model robustness. To tackle these challenges, we propose Point Teacher--the first end-to-end point-supervised method for robust tiny object detection in aerial images. To handle label noise from scale ambiguity and location shifts in point annotations, Point Teacher employs the teacher-student architecture and decouples the learning into a two-phase denoising process. In this framework, the teacher network progressively denoises the pseudo boxes derived from noisy point annotations, guiding the student network's learning. Specifically, in the first phase, random masking of image regions facilitates regression learning, enabling the teacher to transform noisy point annotations into coarse pseudo boxes. In the second phase, these coarse pseudo boxes are refined using dynamic multiple instance learning, which adaptively selects the most reliable instance from dynamically constructed proposal bags around the coarse pseudo boxes. Extensive experiments on three tiny object datasets (i.e., AI-TOD-v2, SODA-A, and TinyPerson) validate the proposed method's effectiveness and robustness against point location shifts. Notably, relying solely on point supervision, our Point Teacher already shows comparable performance with box-supervised learning methods. Codes and models will be made publicly available.
TypeScore: A Text Fidelity Metric for Text-to-Image Generative Models
Nov 02, 2024



Evaluating text-to-image generative models remains a challenge, despite the remarkable progress being made in their overall performances. While existing metrics like CLIPScore work for coarse evaluations, they lack the sensitivity to distinguish finer differences as model performance rapidly improves. In this work, we focus on the text rendering aspect of these models, which provides a lens for evaluating a generative model's fine-grained instruction-following capabilities. To this end, we introduce a new evaluation framework called TypeScore to sensitively assess a model's ability to generate images with high-fidelity embedded text by following precise instructions. We argue that this text generation capability serves as a proxy for general instruction-following ability in image synthesis. TypeScore uses an additional image description model and leverages an ensemble dissimilarity measure between the original and extracted text to evaluate the fidelity of the rendered text. Our proposed metric demonstrates greater resolution than CLIPScore to differentiate popular image generation models across a range of instructions with diverse text styles. Our study also evaluates how well these vision-language models (VLMs) adhere to stylistic instructions, disentangling style evaluation from embedded-text fidelity. Through human evaluation studies, we quantitatively meta-evaluate the effectiveness of the metric. Comprehensive analysis is conducted to explore factors such as text length, captioning models, and current progress towards human parity on this task. The framework provides insights into remaining gaps in instruction-following for image generation with embedded text.