 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalizing Flows with Iterative Denoising
Apr 21, 2026Normalizing Flows (NFs) are a classical family of likelihood-based methods that have received revived attention. Recent efforts such as TARFlow have shown that NFs are capable of achieving promising performance on image modeling tasks, making them viable alternatives to other methods such as diffusion models. In this work, we further advance the state of Normalizing Flow generative models by introducing iterative TARFlow (iTARFlow). Unlike diffusion models, iTARFlow maintains a fully end-to-end, likelihood-based objective during training. During sampling, it performs autoregressive generation followed by an iterative denoising procedure inspired by diffusion-style methods. Through extensive experiments, we show that iTARFlow achieves competitive performance across ImageNet resolutions of 64, 128, and 256 pixels, demonstrating its potential as a strong generative model and advancing the frontier of Normalizing Flows. In addition, we analyze the characteristic artifacts produced by iTARFlow, offering insights that may shed light on future improvements. Code is available at https://github.com/apple/ml-itarflow.
Target Concrete Score Matching: A Holistic Framework for Discrete Diffusion
Apr 23, 2025



Discrete diffusion is a promising framework for modeling and generating discrete data. In this work, we present Target Concrete Score Matching (TCSM), a novel and versatile objective for training and fine-tuning discrete diffusion models. TCSM provides a general framework with broad applicability. It supports pre-training discrete diffusion models directly from data samples, and many existing discrete diffusion approaches naturally emerge as special cases of our more general TCSM framework. Furthermore, the same TCSM objective extends to post-training of discrete diffusion models, including fine-tuning using reward functions or preference data, and distillation of knowledge from pre-trained autoregressive models. These new capabilities stem from the core idea of TCSM, estimating the concrete score of the target distribution, which resides in the original (clean) data space. This allows seamless integration with reward functions and pre-trained models, which inherently only operate in the clean data space rather than the noisy intermediate spaces of diffusion processes. Our experiments on language modeling tasks demonstrate that TCSM matches or surpasses current methods. Additionally, TCSM is versatile, applicable to both pre-training and post-training scenarios, offering greater flexibility and sample efficiency.
Scaling Laws for Native Multimodal Models Scaling Laws for Native Multimodal Models
Apr 10, 2025



Building general-purpose models that can effectively perceive the world through multimodal signals has been a long-standing goal. Current approaches involve integrating separately pre-trained components, such as connecting vision encoders to LLMs and continuing multimodal training. While such approaches exhibit remarkable sample efficiency, it remains an open question whether such late-fusion architectures are inherently superior. In this work, we revisit the architectural design of native multimodal models (NMMs)--those trained from the ground up on all modalities--and conduct an extensive scaling laws study, spanning 457 trained models with different architectures and training mixtures. Our investigation reveals no inherent advantage to late-fusion architectures over early-fusion ones, which do not rely on image encoders. On the contrary, early-fusion exhibits stronger performance at lower parameter counts, is more efficient to train, and is easier to deploy. Motivated by the strong performance of the early-fusion architectures, we show that incorporating Mixture of Experts (MoEs) allows for models that learn modality-specific weights, significantly enhancing performance.
World-consistent Video Diffusion with Explicit 3D Modeling
Dec 02, 2024



Recent advancements in diffusion models have set new benchmarks in image and video generation, enabling realistic visual synthesis across single- and multi-frame contexts. However, these models still struggle with efficiently and explicitly generating 3D-consistent content. To address this, we propose World-consistent Video Diffusion (WVD), a novel framework that incorporates explicit 3D supervision using XYZ images, which encode global 3D coordinates for each image pixel. More specifically, we train a diffusion transformer to learn the joint distribution of RGB and XYZ frames. This approach supports multi-task adaptability via a flexible inpainting strategy. For example, WVD can estimate XYZ frames from ground-truth RGB or generate novel RGB frames using XYZ projections along a specified camera trajectory. In doing so, WVD unifies tasks like single-image-to-3D generation, multi-view stereo, and camera-controlled video generation. Our approach demonstrates competitive performance across multiple benchmarks, providing a scalable solution for 3D-consistent video and image generation with a single pretrained model.
How JEPA Avoids Noisy Features: The Implicit Bias of Deep Linear Self Distillation Networks
Jul 03, 2024



Two competing paradigms exist for self-supervised learning of data representations. Joint Embedding Predictive Architecture (JEPA) is a class of architectures in which semantically similar inputs are encoded into representations that are predictive of each other. A recent successful approach that falls under the JEPA framework is self-distillation, where an online encoder is trained to predict the output of the target encoder, sometimes using a lightweight predictor network. This is contrasted with the Masked AutoEncoder (MAE) paradigm, where an encoder and decoder are trained to reconstruct missing parts of the input in the data space rather, than its latent representation. A common motivation for using the JEPA approach over MAE is that the JEPA objective prioritizes abstract features over fine-grained pixel information (which can be unpredictable and uninformative). In this work, we seek to understand the mechanism behind this empirical observation by analyzing the training dynamics of deep linear models. We uncover a surprising mechanism: in a simplified linear setting where both approaches learn similar representations, JEPAs are biased to learn high-influence features, i.e., features characterized by having high regression coefficients. Our results point to a distinct implicit bias of predicting in latent space that may shed light on its success in practice.
Vanishing Gradients in Reinforcement Finetuning of Language Models
Oct 31, 2023



Pretrained language models are commonly aligned with human preferences and downstream tasks via reinforcement finetuning (RFT), which entails maximizing a (possibly learned) reward function using policy gradient algorithms. This work highlights a fundamental optimization obstacle in RFT: we prove that the expected gradient for an input vanishes when its reward standard deviation under the model is small, even if the expected reward is far from optimal. Through experiments on an RFT benchmark and controlled environments, as well as a theoretical analysis, we then demonstrate that vanishing gradients due to small reward standard deviation are prevalent and detrimental, leading to extremely slow reward maximization. Lastly, we explore ways to overcome vanishing gradients in RFT. We find the common practice of an initial supervised finetuning (SFT) phase to be the most promising candidate, which sheds light on its importance in an RFT pipeline. Moreover, we show that a relatively small number of SFT optimization steps on as few as 1% of the input samples can suffice, indicating that the initial SFT phase need not be expensive in terms of compute and data labeling efforts. Overall, our results emphasize that being mindful for inputs whose expected gradient vanishes, as measured by the reward standard deviation, is crucial for successful execution of RFT.
When can transformers reason with abstract symbols?
Oct 15, 2023



We investigate the capabilities of transformer large language models (LLMs) on relational reasoning tasks involving abstract symbols. Such tasks have long been studied in the neuroscience literature as fundamental building blocks for more complex abilities in programming, mathematics, and verbal reasoning. For (i) regression tasks, we prove that transformers generalize when trained, but require astonishingly large quantities of training data. For (ii) next-token-prediction tasks with symbolic labels, we show an "inverse scaling law": transformers fail to generalize as their embedding dimension increases. For both settings (i) and (ii), we propose subtle transformer modifications which can reduce the amount of data needed by adding two trainable parameters per head.
Transformers learn through gradual rank increase
Jun 12, 2023



We identify incremental learning dynamics in transformers, where the difference between trained and initial weights progressively increases in rank. We rigorously prove this occurs under the simplifying assumptions of diagonal weight matrices and small initialization. Our experiments support the theory and also show that phenomenon can occur in practice without the simplifying assumptions.
Position Prediction as an Effective Pretraining Strategy
Jul 15, 2022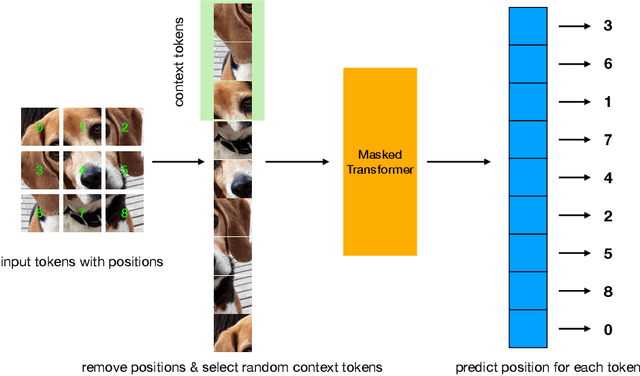


Transformers have gained increasing popularity in a wide range of applications, including Natural Language Processing (NLP), Computer Vision and Speech Recognition, because of their powerful representational capacity. However, harnessing this representational capacity effectively requires a large amount of data, strong regularization, or both, to mitigate overfitting. Recently, the power of the Transformer has been unlocked by self-supervised pretraining strategies based on masked autoencoders which rely on reconstructing masked inputs, directly, or contrastively from unmasked content. This pretraining strategy which has been used in BERT models in NLP, Wav2Vec models in Speech and, recently, in MAE models in Vision, forces the model to learn about relationships between the content in different parts of the input using autoencoding related objectives. In this paper, we propose a novel, but surprisingly simple alternative to content reconstruction~-- that of predicting locations from content, without providing positional information for it. Doing so requires the Transformer to understand the positional relationships between different parts of the input, from their content alone. This amounts to an efficient implementation where the pretext task is a classification problem among all possible positions for each input token. We experiment on both Vision and Speech benchmarks, where our approach brings improvements over strong supervised training baselines and is comparable to modern unsupervised/self-supervised pretraining methods. Our method also enables Transformers trained without position embeddings to outperform ones trained with full position information.
The Slingshot Mechanism: An Empirical Study of Adaptive Optimizers and the Grokking Phenomenon
Jun 13, 2022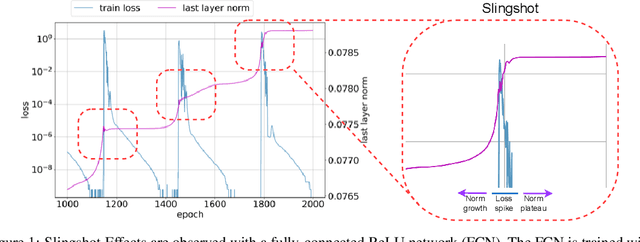
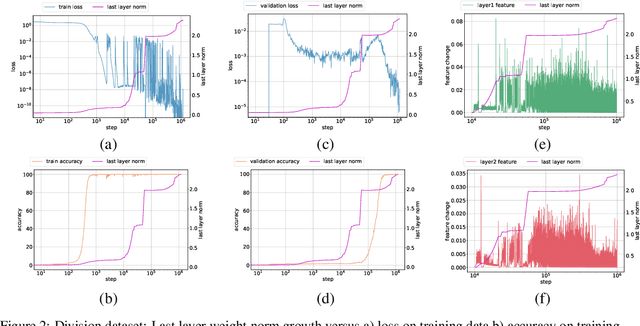
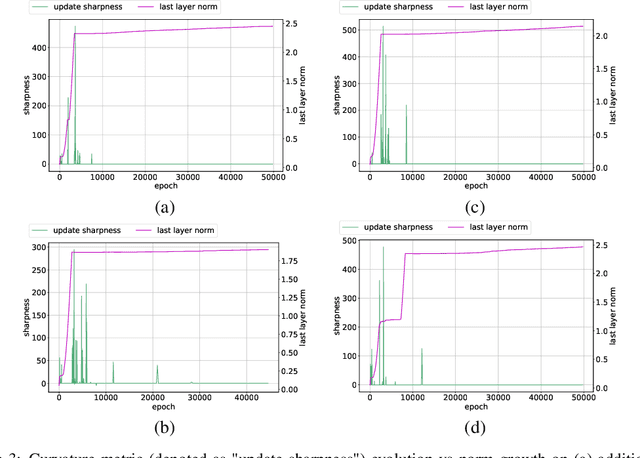
The grokking phenomenon as reported by Power et al. ( arXiv:2201.02177 ) refers to a regime where a long period of overfitting is followed by a seemingly sudden transition to perfect generalization. In this paper, we attempt to reveal the underpinnings of Grokking via a series of empirical studies. Specifically, we uncover an optimization anomaly plaguing adaptive optimizers at extremely late stages of training, referred to as the Slingshot Mechanism. A prominent artifact of the Slingshot Mechanism can be measured by the cyclic phase transitions between stable and unstable training regimes, and can be easily monitored by the cyclic behavior of the norm of the last layers weights. We empirically observe that without explicit regularization, Grokking as reported in ( arXiv:2201.02177 ) almost exclusively happens at the onset of Slingshots, and is absent without it. While common and easily reproduced in more general settings, the Slingshot Mechanism does not follow from any known optimization theories that we are aware of, and can be easily overlooked without an in depth examination. Our work points to a surprising and useful inductive bias of adaptive gradient optimizers at late stages of training, calling for a revised theoretical analysis of their origin.