 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeG2LoRA: Gradient Orthogonal Low-Rank Adaptation Framework for Graph Continual Learning on Text-Attributed Graphs
Jun 01, 2026LLM-as-Aligner has emerged as a prevalent pre-training paradigm for Text-Attributed Graphs(TAGS), aligning graph and text modalities into a shared embedding space via CLIP-style contrastive learning. While effective on individual downstream tasks, we observe severe catastrophic forgetting when such models are sequentially fine-tuned on streaming tasks. Although parameter-efficient fine-tuning alleviates forgetting to some extent, it remains insufficient to resolve task interference and ineffective knowledge transfer. In this work, we study graph continual learning for LLM-as-Aligner models on TAGs, with the goal of mitigating interference while promoting positive transfer across tasks. This setting introduces two fundamental challenges: (1) heterogeneous downstream tasks induce shifting optimization objectives, hindering unified fine-tuning; and (2) graph and text encoders exhibit different sensitivities to adaptation, making uncoordinated updates prone to misalignment. To address these challenges, we propose G2LoRA, a continual learning framework for TAGs. G2LoRA unifies node-, link-, and graph-level tasks under a single graph--text alignment objective, and enables consistent optimization across domain/class/task incremental modes. To reduce task interference while encouraging positive transfer, G2LoRA performs category-aware gradient projection in structured subspaces, resolving conflicting updates and enabling conditional backward transfer to balance forward and backward knowledge flow. To further prevent cross-modal drift, G2LoRA introduces gradient magnitude modulation to coordinate update rates between graph and text encoders. Extensive experiments on benchmark datasets demonstrate that G2LoRA consistently outperforms strong baselines across different backbone architectures, achieving superior continual performance and transferability.
OA-Bug: An Olfactory-Auditory Augmented Bug Algorithm for Swarm Robots in a Denied Environment
Sep 28, 2022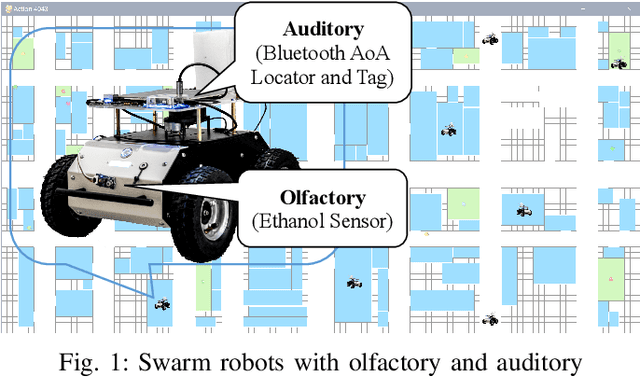
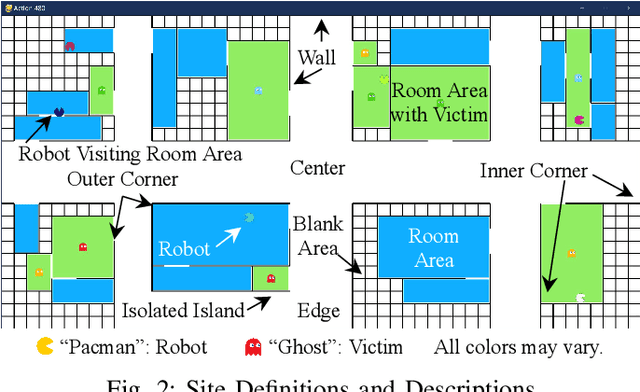
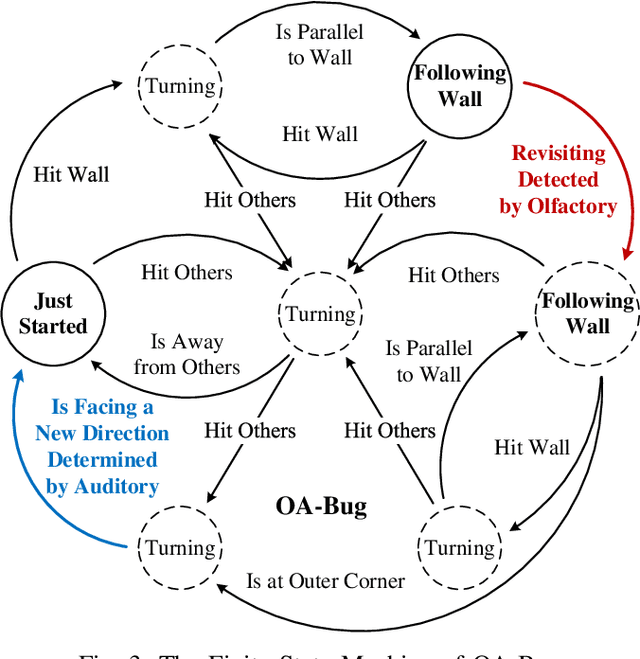
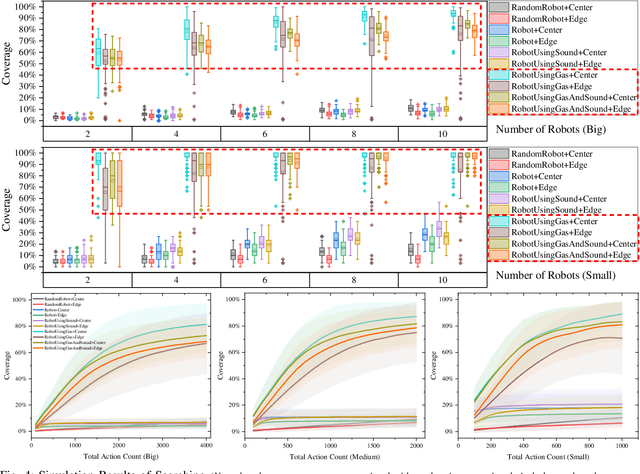
Searching in a denied environment is challenging for swarm robots as no assistance from GNSS, mapping, data sharing, and central processing are allowed. However, using olfactory and auditory to cooperate like animals could be an important way to improve the collaboration of swarm robots. In this paper, an Olfactory-Auditory augmented Bug algorithm (OA-Bug) is proposed for a swarm of autonomous robots to explore a denied environment. A simulation environment is built to measure the performance of OA-Bug. The coverage of the search task using OA-Bug can reach 96.93%, with the most significant improvement of 40.55% compared with a similar algorithm, SGBA. Furthermore, experiments are conducted on real swarm robots to prove the validity of OA-Bug. Results show that OA-Bug can improve the performance of swarm robots in a denied environment.