 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysFlow: Skin tone transfer for remote heart rate estimation through conditional normalizing flows
Jul 31, 2024In recent years, deep learning methods have shown impressive results for camera-based remote physiological signal estimation, clearly surpassing traditional methods. However, the performance and generalization ability of Deep Neural Networks heavily depends on rich training data truly representing different factors of variation encountered in real applications. Unfortunately, many current remote photoplethysmography (rPPG) datasets lack diversity, particularly in darker skin tones, leading to biased performance of existing rPPG approaches. To mitigate this bias, we introduce PhysFlow, a novel method for augmenting skin diversity in remote heart rate estimation using conditional normalizing flows. PhysFlow adopts end-to-end training optimization, enabling simultaneous training of supervised rPPG approaches on both original and generated data. Additionally, we condition our model using CIELAB color space skin features directly extracted from the facial videos without the need for skin-tone labels. We validate PhysFlow on publicly available datasets, UCLA-rPPG and MMPD, demonstrating reduced heart rate error, particularly in dark skin tones. Furthermore, we demonstrate its versatility and adaptability across different data-driven rPPG methods.
Deep Pulse-Signal Magnification for remote Heart Rate Estimation in Compressed Videos
May 04, 2024



Recent advancements in remote heart rate measurement (rPPG), motivated by data-driven approaches, have significantly improved accuracy. However, certain challenges, such as video compression, still remain: recovering the rPPG signal from highly compressed videos is particularly complex. Although several studies have highlighted the difficulties and impact of video compression for this, effective solutions remain limited. In this paper, we present a novel approach to address the impact of video compression on rPPG estimation, which leverages a pulse-signal magnification transformation to adapt compressed videos to an uncompressed data domain in which the rPPG signal is magnified. We validate the effectiveness of our model by exhaustive evaluations on two publicly available datasets, UCLA-rPPG and UBFC-rPPG, employing both intra- and cross-database performance at several compression rates. Additionally, we assess the robustness of our approach on two additional highly compressed and widely-used datasets, MAHNOB-HCI and COHFACE, which reveal outstanding heart rate estimation results.
Deep adaptative spectral zoom for improved remote heart rate estimation
Mar 11, 2024



Recent advances in remote heart rate measurement, motivated by data-driven approaches, have notably enhanced accuracy. However, these improvements primarily focus on recovering the rPPG signal, overlooking the implicit challenges of estimating the heart rate (HR) from the derived signal. While many methods employ the Fast Fourier Transform (FFT) for HR estimation, the performance of the FFT is inherently affected by a limited frequency resolution. In contrast, the Chirp-Z Transform (CZT), a generalization form of FFT, can refine the spectrum to the narrow-band range of interest for heart rate, providing improved frequential resolution and, consequently, more accurate estimation. This paper presents the advantages of employing the CZT for remote HR estimation and introduces a novel data-driven adaptive CZT estimator. The objective of our proposed model is to tailor the CZT to match the characteristics of each specific dataset sensor, facilitating a more optimal and accurate estimation of HR from the rPPG signal without compromising generalization across diverse datasets. This is achieved through a Sparse Matrix Optimization (SMO). We validate the effectiveness of our model through exhaustive evaluations on three publicly available datasets UCLA-rPPG, PURE, and UBFC-rPPG employing both intra- and cross-database performance metrics. The results reveal outstanding heart rate estimation capabilities, establishing the proposed approach as a robust and versatile estimator for any rPPG method.
Estimating 3D Uncertainty Field: Quantifying Uncertainty for Neural Radiance Fields
Nov 03, 2023Current methods based on Neural Radiance Fields (NeRF) significantly lack the capacity to quantify uncertainty in their predictions, particularly on the unseen space including the occluded and outside scene content. This limitation hinders their extensive applications in robotics, where the reliability of model predictions has to be considered for tasks such as robotic exploration and planning in unknown environments. To address this, we propose a novel approach to estimate a 3D Uncertainty Field based on the learned incomplete scene geometry, which explicitly identifies these unseen regions. By considering the accumulated transmittance along each camera ray, our Uncertainty Field infers 2D pixel-wise uncertainty, exhibiting high values for rays directly casting towards occluded or outside the scene content. To quantify the uncertainty on the learned surface, we model a stochastic radiance field. Our experiments demonstrate that our approach is the only one that can explicitly reason about high uncertainty both on 3D unseen regions and its involved 2D rendered pixels, compared with recent methods. Furthermore, we illustrate that our designed uncertainty field is ideally suited for real-world robotics tasks, such as next-best-view selection.
Permutation-Invariant Relational Network for Multi-person 3D Pose Estimation
Apr 11, 2022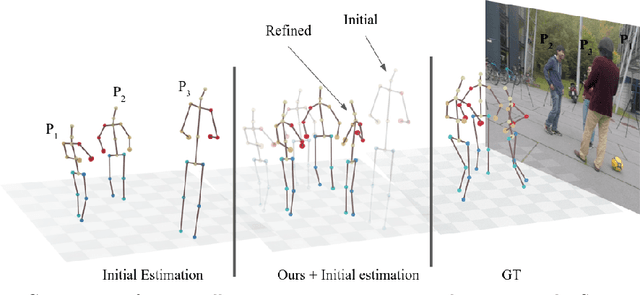
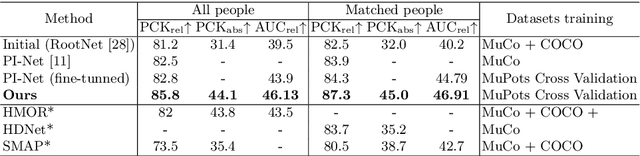
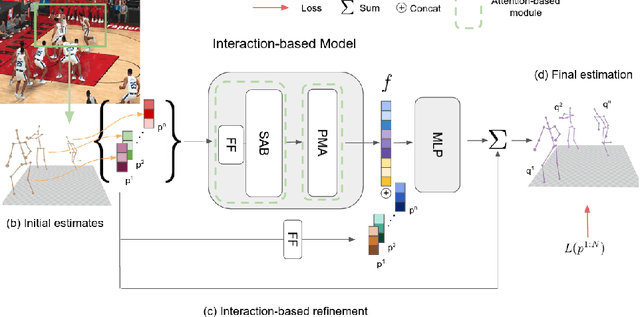
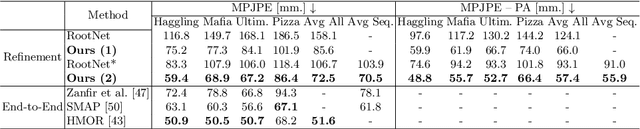
Recovering multi-person 3D poses from a single RGB image is a severely ill-conditioned problem due not only to the inherent 2D-3D depth ambiguity but also because of inter-person occlusions and body truncations. Recent works have shown promising results by simultaneously reasoning for different people but in all cases within a local neighborhood. An interesting exception is PI-Net, which introduces a self-attention block to reason for all people in the image at the same time and refine potentially noisy initial 3D poses. However, the proposed methodology requires defining one of the individuals as a reference, and the outcome of the algorithm is sensitive to this choice. In this paper, we model people interactions at a whole, independently of their number, and in a permutation-invariant manner building upon the Set Transformer. We leverage on this representation to refine the initial 3D poses estimated by off-the-shelf detectors. A thorough evaluation demonstrates that our approach is able to boost the performance of the initially estimated 3D poses by large margins, achieving state-of-the-art results on MuPoTS-3D, CMU Panoptic and NBA2K datasets. Additionally, the proposed module is computationally efficient and can be used as a drop-in complement for any 3D pose detector in multi-people scenes.
Efficient Remote Photoplethysmography with Temporal Derivative Modules and Time-Shift Invariant Loss
Mar 21, 2022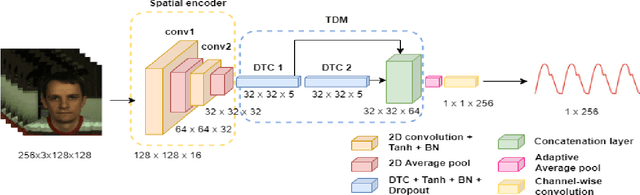
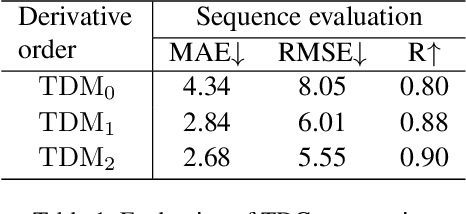
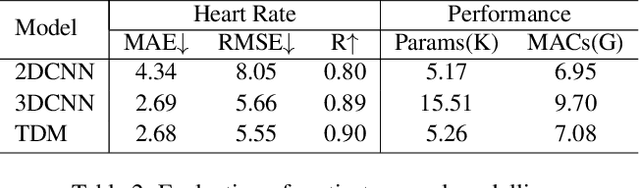
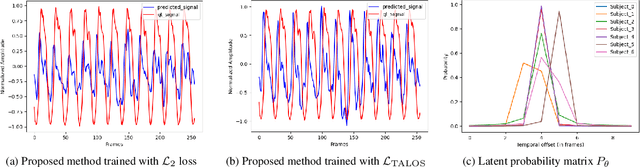
We present a lightweight neural model for remote heart rate estimation focused on the efficient spatio-temporal learning of facial photoplethysmography (PPG) based on i) modelling of PPG dynamics by combinations of multiple convolutional derivatives, and ii) increased flexibility of the model to learn possible offsets between the video facial PPG and the ground truth. PPG dynamics are modelled by a Temporal Derivative Module (TDM) constructed by the incremental aggregation of multiple convolutional derivatives, emulating a Taylor series expansion up to the desired order. Robustness to ground truth offsets is handled by the introduction of TALOS (Temporal Adaptive LOcation Shift), a new temporal loss to train learning-based models. We verify the effectiveness of our model by reporting accuracy and efficiency metrics on the public PURE and UBFC-rPPG datasets. Compared to existing models, our approach shows competitive heart rate estimation accuracy with a much lower number of parameters and lower computational cost.
Conditional-Flow NeRF: Accurate 3D Modelling with Reliable Uncertainty Quantification
Mar 18, 2022
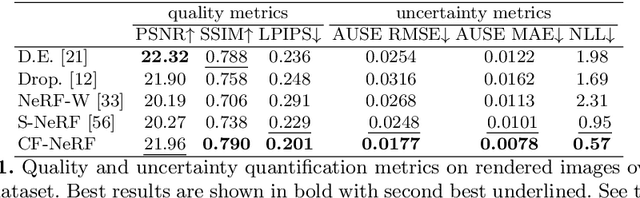

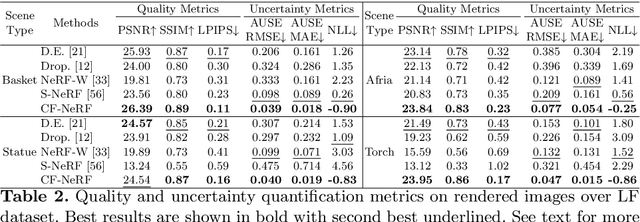
A critical limitation of current methods based on Neural Radiance Fields (NeRF) is that they are unable to quantify the uncertainty associated with the learned appearance and geometry of the scene. This information is paramount in real applications such as medical diagnosis or autonomous driving where, to reduce potentially catastrophic failures, the confidence on the model outputs must be included into the decision-making process. In this context, we introduce Conditional-Flow NeRF (CF-NeRF), a novel probabilistic framework to incorporate uncertainty quantification into NeRF-based approaches. For this purpose, our method learns a distribution over all possible radiance fields modelling which is used to quantify the uncertainty associated with the modelled scene. In contrast to previous approaches enforcing strong constraints over the radiance field distribution, CF-NeRF learns it in a flexible and fully data-driven manner by coupling Latent Variable Modelling and Conditional Normalizing Flows. This strategy allows to obtain reliable uncertainty estimation while preserving model expressivity. Compared to previous state-of-the-art methods proposed for uncertainty quantification in NeRF, our experiments show that the proposed method achieves significantly lower prediction errors and more reliable uncertainty values for synthetic novel view and depth-map estimation.
Body Size and Depth Disambiguation in Multi-Person Reconstruction from Single Images
Nov 02, 2021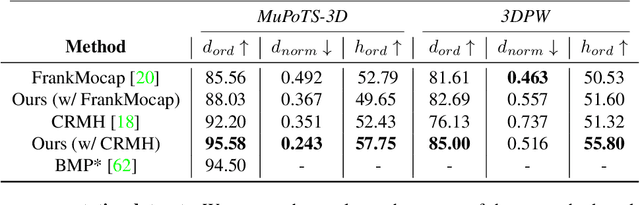
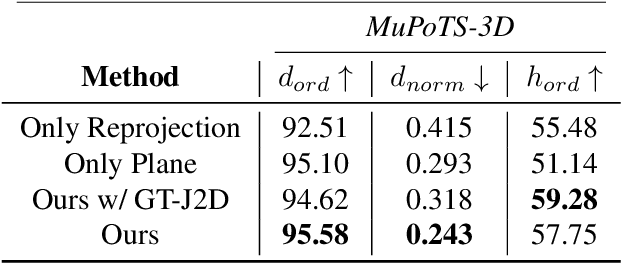
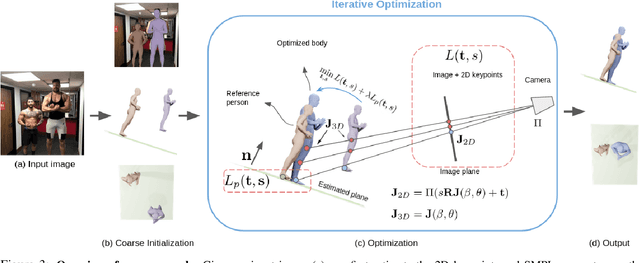
We address the problem of multi-person 3D body pose and shape estimation from a single image. While this problem can be addressed by applying single-person approaches multiple times for the same scene, recent works have shown the advantages of building upon deep architectures that simultaneously reason about all people in the scene in a holistic manner by enforcing, e.g., depth order constraints or minimizing interpenetration among reconstructed bodies. However, existing approaches are still unable to capture the size variability of people caused by the inherent body scale and depth ambiguity. In this work, we tackle this challenge by devising a novel optimization scheme that learns the appropriate body scale and relative camera pose, by enforcing the feet of all people to remain on the ground floor. A thorough evaluation on MuPoTS-3D and 3DPW datasets demonstrates that our approach is able to robustly estimate the body translation and shape of multiple people while retrieving their spatial arrangement, consistently improving current state-of-the-art, especially in scenes with people of very different heights
Stochastic Neural Radiance Fields: Quantifying Uncertainty in Implicit 3D Representations
Sep 28, 2021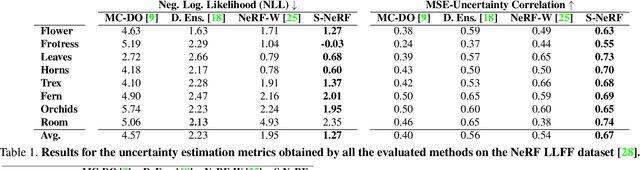
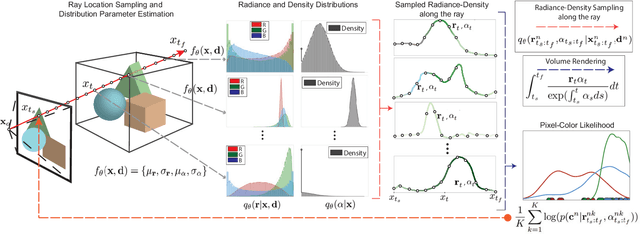
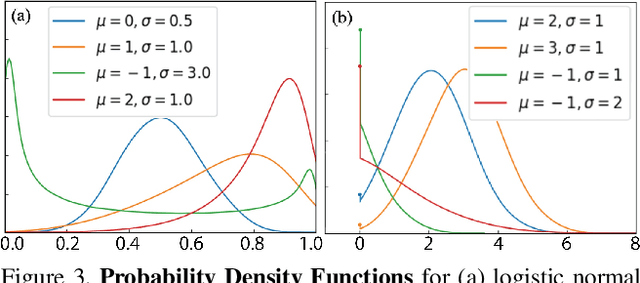
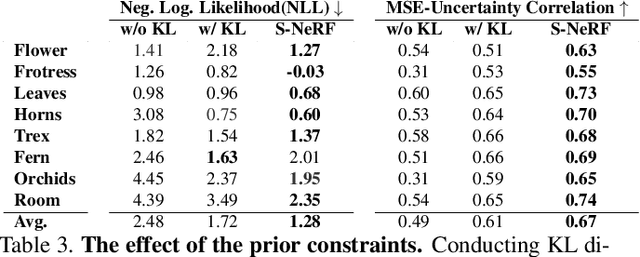
Neural Radiance Fields (NeRF) has become a popular framework for learning implicit 3D representations and addressing different tasks such as novel-view synthesis or depth-map estimation. However, in downstream applications where decisions need to be made based on automatic predictions, it is critical to leverage the confidence associated with the model estimations. Whereas uncertainty quantification is a long-standing problem in Machine Learning, it has been largely overlooked in the recent NeRF literature. In this context, we propose Stochastic Neural Radiance Fields (S-NeRF), a generalization of standard NeRF that learns a probability distribution over all the possible radiance fields modeling the scene. This distribution allows to quantify the uncertainty associated with the scene information provided by the model. S-NeRF optimization is posed as a Bayesian learning problem which is efficiently addressed using the Variational Inference framework. Exhaustive experiments over benchmark datasets demonstrate that S-NeRF is able to provide more reliable predictions and confidence values than generic approaches previously proposed for uncertainty estimation in other domains.
Generating Attribution Maps with Disentangled Masked Backpropagation
Jan 17, 2021
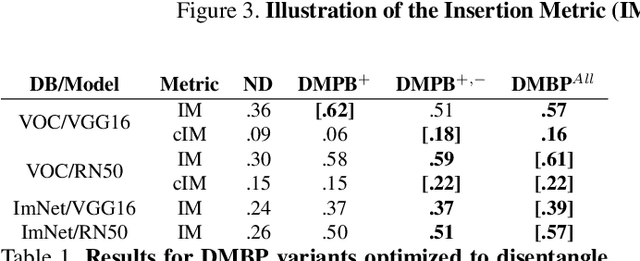
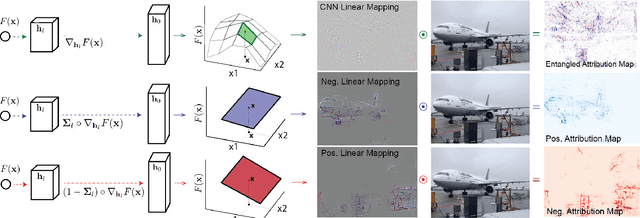

Attribution map visualization has arisen as one of the most effective techniques to understand the underlying inference process of Convolutional Neural Networks. In this task, the goal is to compute an score for each image pixel related with its contribution to the final network output. In this paper, we introduce Disentangled Masked Backpropagation (DMBP), a novel gradient-based method that leverages on the piecewise linear nature of ReLU networks to decompose the model function into different linear mappings. This decomposition aims to disentangle the positive, negative and nuisance factors from the attribution maps by learning a set of variables masking the contribution of each filter during back-propagation. A thorough evaluation over standard architectures (ResNet50 and VGG16) and benchmark datasets (PASCAL VOC and ImageNet) demonstrates that DMBP generates more visually interpretable attribution maps than previous approaches. Additionally, we quantitatively show that the maps produced by our method are more consistent with the true contribution of each pixel to the final network output.