 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIGLeT: Language Grounding Through Neuro-Symbolic Interaction in a 3D World
Jun 01, 2021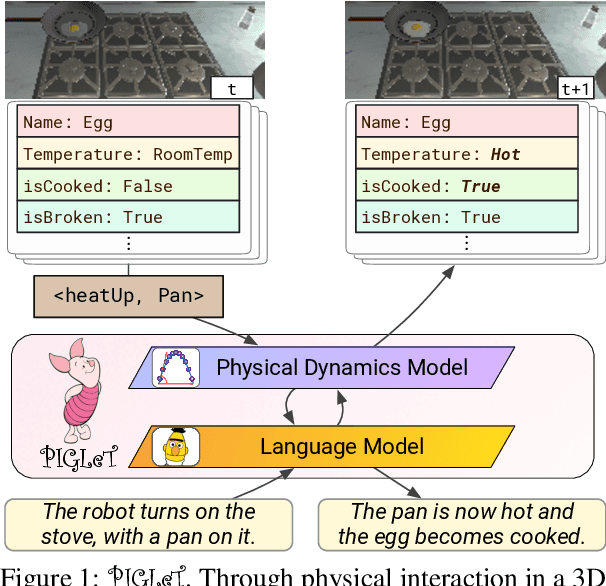
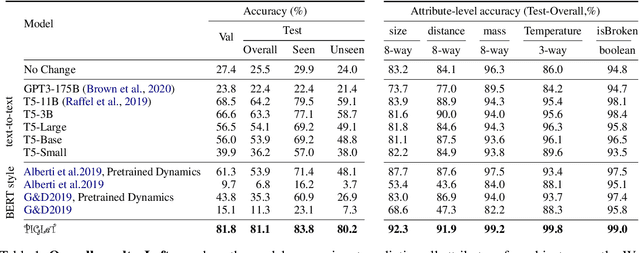

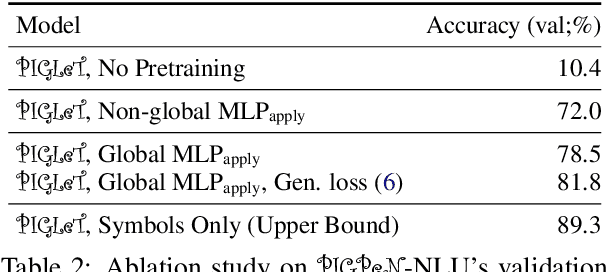
We propose PIGLeT: a model that learns physical commonsense knowledge through interaction, and then uses this knowledge to ground language. We factorize PIGLeT into a physical dynamics model, and a separate language model. Our dynamics model learns not just what objects are but also what they do: glass cups break when thrown, plastic ones don't. We then use it as the interface to our language model, giving us a unified model of linguistic form and grounded meaning. PIGLeT can read a sentence, simulate neurally what might happen next, and then communicate that result through a literal symbolic representation, or natural language. Experimental results show that our model effectively learns world dynamics, along with how to communicate them. It is able to correctly forecast "what happens next" given an English sentence over 80% of the time, outperforming a 100x larger, text-to-text approach by over 10%. Likewise, its natural language summaries of physical interactions are also judged by humans as more accurate than LM alternatives. We present comprehensive analysis showing room for future work.
MAUVE: Human-Machine Divergence Curves for Evaluating Open-Ended Text Generation
Feb 02, 2021
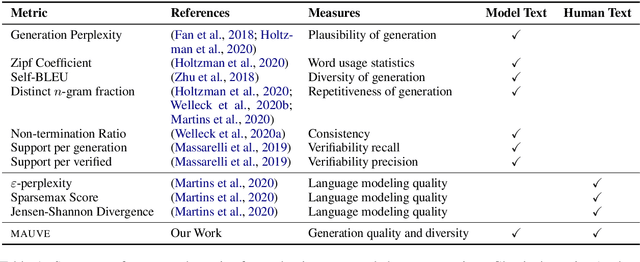
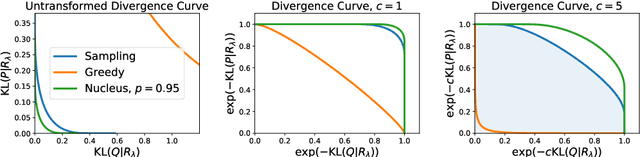
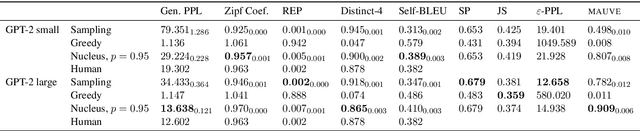
Despite major advances in open-ended text generation, there has been limited progress in designing evaluation metrics for this task. We propose MAUVE -- a metric for open-ended text generation, which directly compares the distribution of machine-generated text to that of human language. MAUVE measures the mean area under the divergence curve for the two distributions, exploring the trade-off between two types of errors: those arising from parts of the human distribution that the model distribution approximates well, and those it does not. We present experiments across two open-ended generation tasks in the web text domain and the story domain, and a variety of decoding algorithms and model sizes. Our results show that evaluation under MAUVE indeed reflects the more natural behavior with respect to model size, compared to prior metrics. MAUVE's ordering of the decoding algorithms also agrees with that of generation perplexity, the most widely used metric in open-ended text generation; however, MAUVE presents a more principled evaluation metric for the task as it considers both model and human text.
Edited Media Understanding: Reasoning About Implications of Manipulated Images
Dec 08, 2020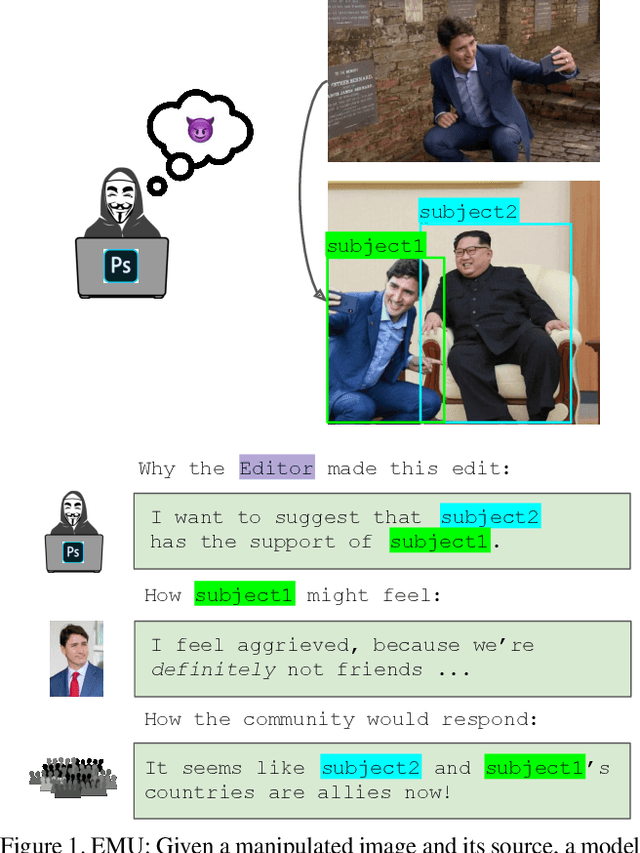

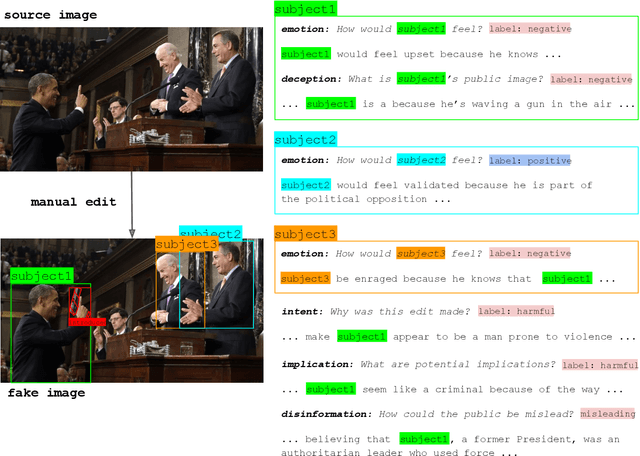
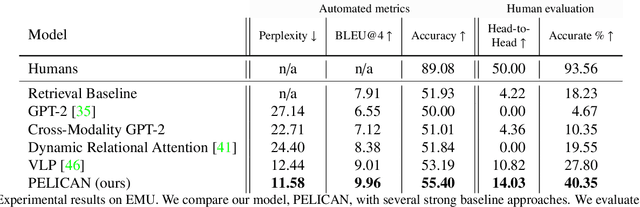
Multimodal disinformation, from `deepfakes' to simple edits that deceive, is an important societal problem. Yet at the same time, the vast majority of media edits are harmless -- such as a filtered vacation photo. The difference between this example, and harmful edits that spread disinformation, is one of intent. Recognizing and describing this intent is a major challenge for today's AI systems. We present the task of Edited Media Understanding, requiring models to answer open-ended questions that capture the intent and implications of an image edit. We introduce a dataset for our task, EMU, with 48k question-answer pairs written in rich natural language. We evaluate a wide variety of vision-and-language models for our task, and introduce a new model PELICAN, which builds upon recent progress in pretrained multimodal representations. Our model obtains promising results on our dataset, with humans rating its answers as accurate 40.35% of the time. At the same time, there is still much work to be done -- humans prefer human-annotated captions 93.56% of the time -- and we provide analysis that highlights areas for further progress.
NeuroLogic Decoding: (Un)supervised Neural Text Generation with Predicate Logic Constraints
Oct 24, 2020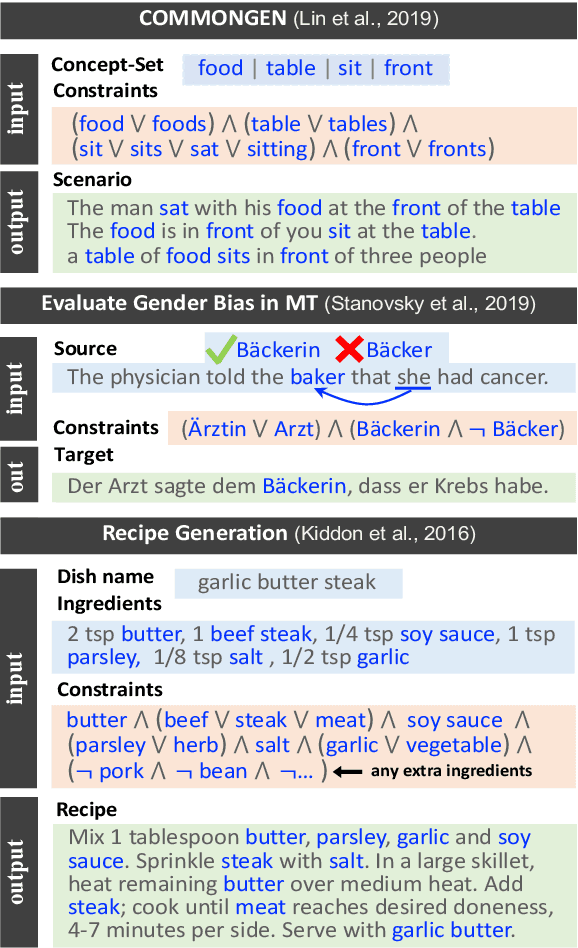
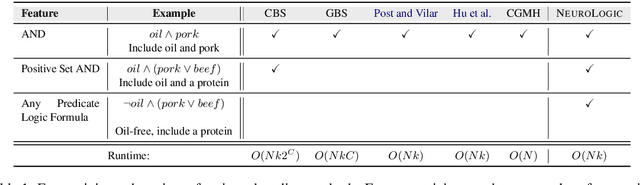
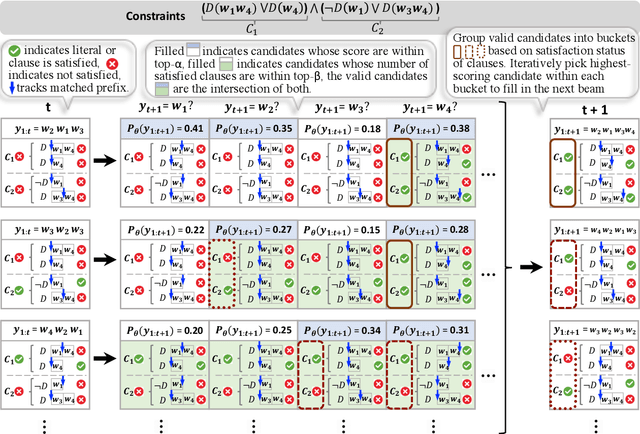
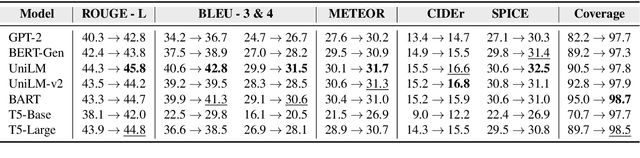
Conditional text generation often requires lexical constraints, i.e., which words should or shouldn't be included in the output text. While the dominant recipe for conditional text generation has been large-scale pretrained language models that are finetuned on the task-specific training data, such models do not learn to follow the underlying constraints reliably, even when supervised with large amounts of task-specific examples. We propose NeuroLogic Decoding, a simple yet effective algorithm that enables neural language models -- supervised or not -- to generate fluent text while satisfying complex lexical constraints. Our approach is powerful yet efficient. It handles any set of lexical constraints that is expressible under predicate logic, while its asymptotic runtime is equivalent to conventional beam search. Empirical results on four benchmarks show that NeuroLogic Decoding outperforms previous approaches, including algorithms that handle a subset of our constraints. Moreover, we find that unsupervised models with NeuroLogic Decoding often outperform supervised models with conventional decoding, even when the latter is based on considerably larger networks. Our results suggest the limit of large-scale neural networks for fine-grained controllable generation and the promise of inference-time algorithms.
Probing Text Models for Common Ground with Visual Representations
May 01, 2020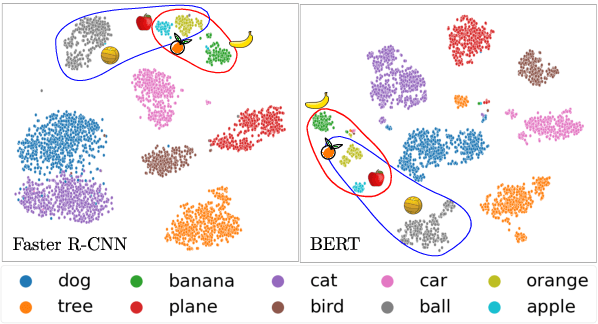
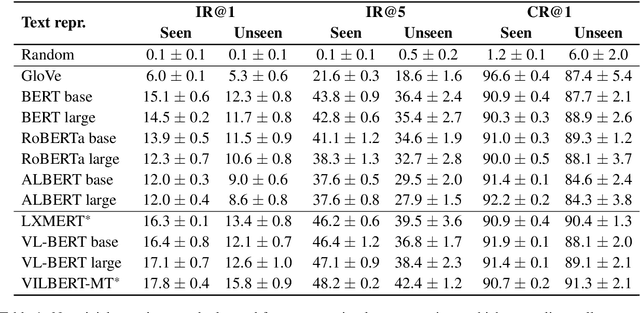


Vision, as a central component of human perception, plays a fundamental role in shaping natural language. To better understand how text models are connected to our visual perceptions, we propose a method for examining the similarities between neural representations extracted from words in text and objects in images. Our approach uses a lightweight probing model that learns to map language representations of concrete words to the visual domain. We find that representations from models trained on purely textual data, such as BERT, can be nontrivially mapped to those of a vision model. Such mappings generalize to object categories that were never seen by the probe during training, unlike mappings learned from permuted or random representations. Moreover, we find that the context surrounding objects in sentences greatly impacts performance. Finally, we show that humans significantly outperform all examined models, suggesting considerable room for improvement in representation learning and grounding.
Evaluating Machines by their Real-World Language Use
Apr 07, 2020
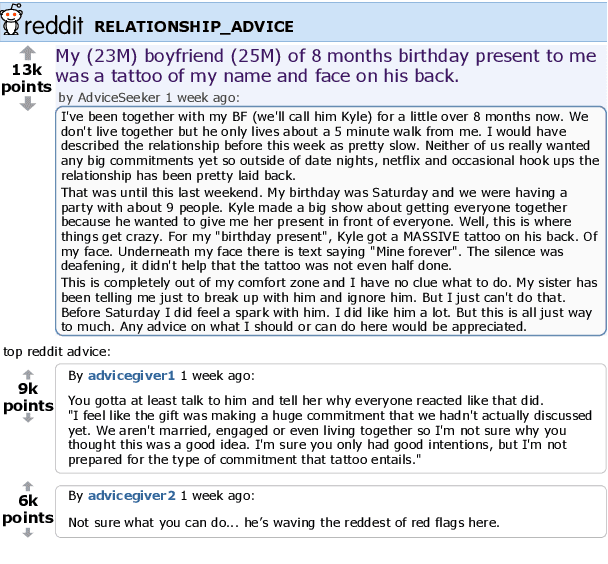
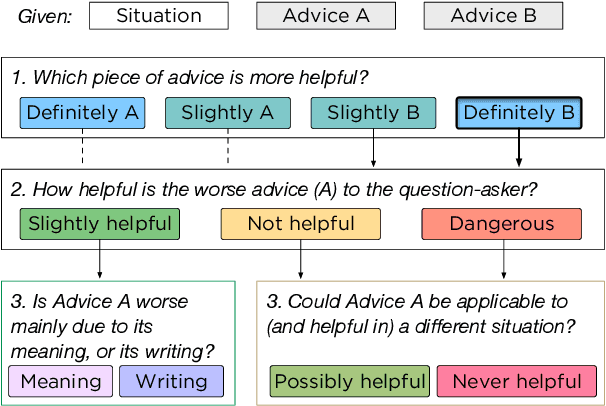
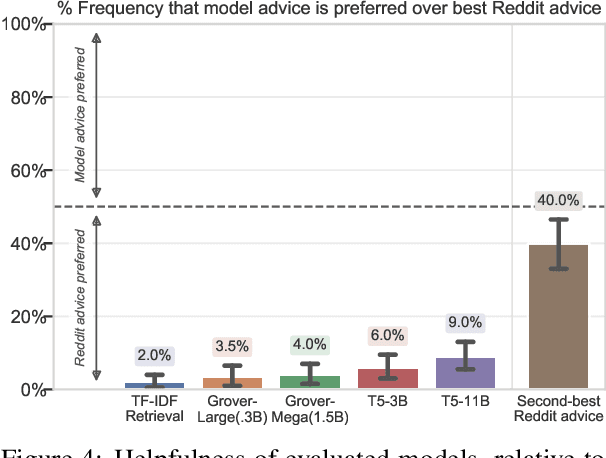
There is a fundamental gap between how humans understand and use language -- in open-ended, real-world situations -- and today's NLP benchmarks for language understanding. To narrow this gap, we propose to evaluate machines by their success at real-world language use -- which greatly expands the scope of language tasks that can be measured and studied. We introduce TuringAdvice, a new challenge for language understanding systems. Given a complex situation faced by a real person, a machine must generate helpful advice. We make our challenge concrete by introducing RedditAdvice, a dataset and leaderboard for measuring progress. Though we release a training set with 600k examples, our evaluation is dynamic, continually evolving with the language people use: models must generate helpful advice for recently-written situations. Empirical results show that today's models struggle at our task, even those with billions of parameters. The best model, a finetuned T5, writes advice that is at least as helpful as human-written advice in only 9% of cases. This low performance reveals language understanding errors that are hard to spot outside of a generative setting, showing much room for progress.
Adversarial Filters of Dataset Biases
Feb 20, 2020
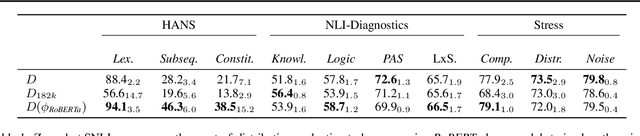
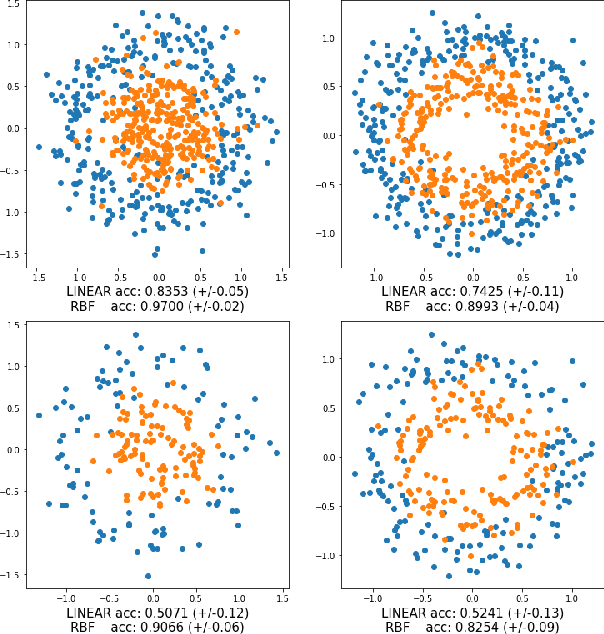

Large neural models have demonstrated human-level performance on language and vision benchmarks such as ImageNet and Stanford Natural Language Inference (SNLI). Yet, their performance degrades considerably when tested on adversarial or out-of-distribution samples. This raises the question of whether these models have learned to solve a dataset rather than the underlying task by overfitting on spurious dataset biases. We investigate one recently proposed approach, AFLite, which adversarially filters such dataset biases, as a means to mitigate the prevalent overestimation of machine performance. We provide a theoretical understanding for AFLite, by situating it in the generalized framework for optimum bias reduction. Our experiments show that as a result of the substantial reduction of these biases, models trained on the filtered datasets yield better generalization to out-of-distribution tasks, especially when the benchmarks used for training are over-populated with biased samples. We show that AFLite is broadly applicable to a variety of both real and synthetic datasets for reduction of measurable dataset biases and provide extensive supporting analyses. Finally, filtering results in a large drop in model performance (e.g., from 92% to 63% for SNLI), while human performance still remains high. Our work thus shows that such filtered datasets can pose new research challenges for robust generalization by serving as upgraded benchmarks.
PIQA: Reasoning about Physical Commonsense in Natural Language
Nov 26, 2019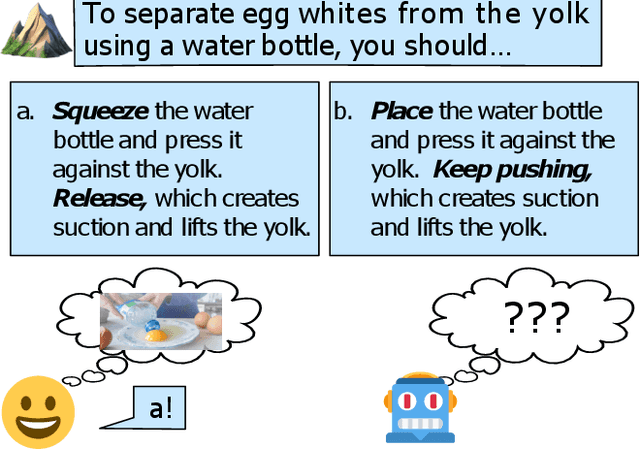
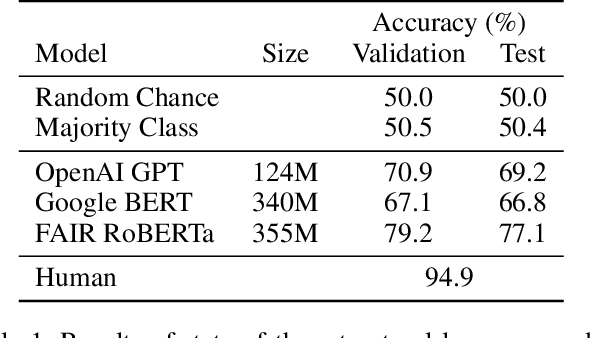
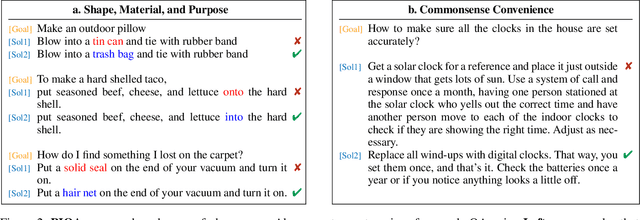
To apply eyeshadow without a brush, should I use a cotton swab or a toothpick? Questions requiring this kind of physical commonsense pose a challenge to today's natural language understanding systems. While recent pretrained models (such as BERT) have made progress on question answering over more abstract domains - such as news articles and encyclopedia entries, where text is plentiful - in more physical domains, text is inherently limited due to reporting bias. Can AI systems learn to reliably answer physical common-sense questions without experiencing the physical world? In this paper, we introduce the task of physical commonsense reasoning and a corresponding benchmark dataset Physical Interaction: Question Answering or PIQA. Though humans find the dataset easy (95% accuracy), large pretrained models struggle (77%). We provide analysis about the dimensions of knowledge that existing models lack, which offers significant opportunities for future research.
Defending Against Neural Fake News
May 29, 2019
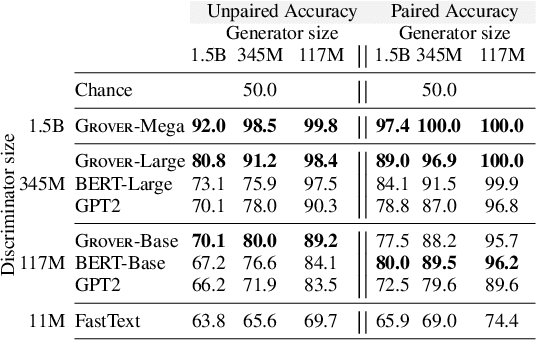
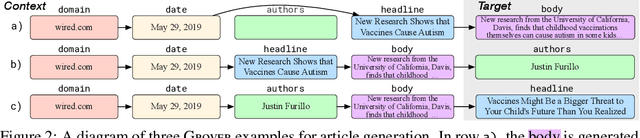
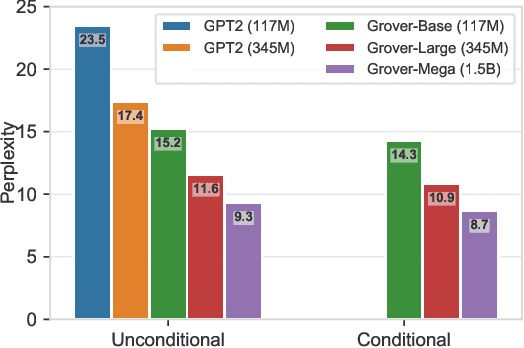
Recent progress in natural language generation has raised dual-use concerns. While applications like summarization and translation are positive, the underlying technology also might enable adversaries to generate neural fake news: targeted propaganda that closely mimics the style of real news. Modern computer security relies on careful threat modeling: identifying potential threats and vulnerabilities from an adversary's point of view, and exploring potential mitigations to these threats. Likewise, developing robust defenses against neural fake news requires us first to carefully investigate and characterize the risks of these models. We thus present a model for controllable text generation called Grover. Given a headline like `Link Found Between Vaccines and Autism,' Grover can generate the rest of the article; humans find these generations to be more trustworthy than human-written disinformation. Developing robust verification techniques against generators like Grover is critical. We find that best current discriminators can classify neural fake news from real, human-written, news with 73% accuracy, assuming access to a moderate level of training data. Counterintuitively, the best defense against Grover turns out to be Grover itself, with 92% accuracy, demonstrating the importance of public release of strong generators. We investigate these results further, showing that exposure bias -- and sampling strategies that alleviate its effects -- both leave artifacts that similar discriminators can pick up on. We conclude by discussing ethical issues regarding the technology, and plan to release Grover publicly, helping pave the way for better detection of neural fake news.
HellaSwag: Can a Machine Really Finish Your Sentence?
May 19, 2019
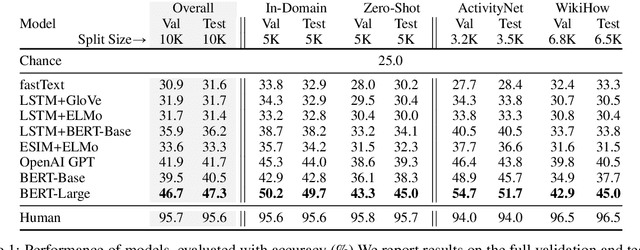
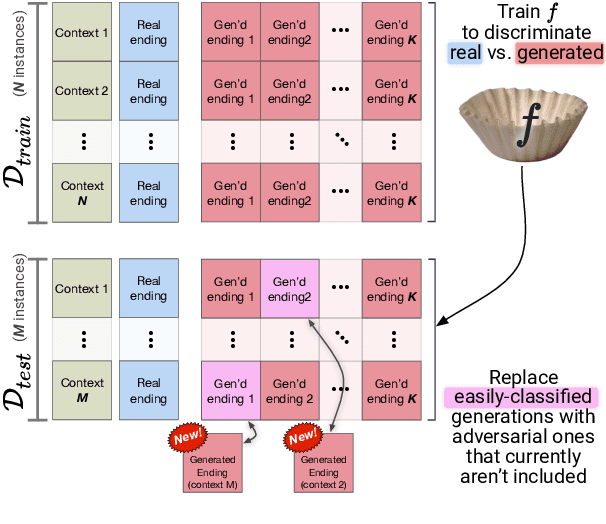
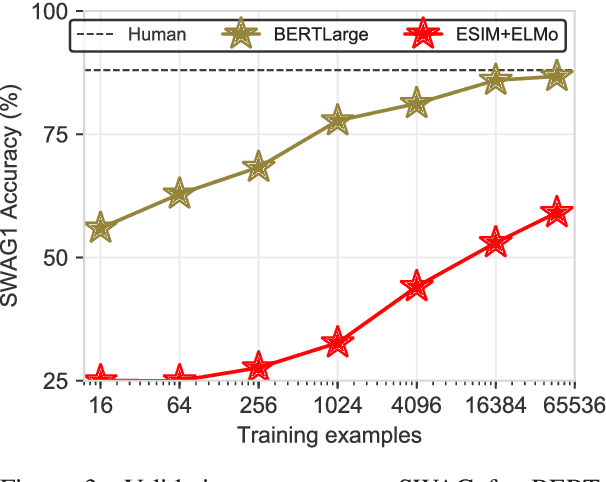
Recent work by Zellers et al. (2018) introduced a new task of commonsense natural language inference: given an event description such as "A woman sits at a piano," a machine must select the most likely followup: "She sets her fingers on the keys." With the introduction of BERT, near human-level performance was reached. Does this mean that machines can perform human level commonsense inference? In this paper, we show that commonsense inference still proves difficult for even state-of-the-art models, by presenting HellaSwag, a new challenge dataset. Though its questions are trivial for humans (>95% accuracy), state-of-the-art models struggle (<48%). We achieve this via Adversarial Filtering (AF), a data collection paradigm wherein a series of discriminators iteratively select an adversarial set of machine-generated wrong answers. AF proves to be surprisingly robust. The key insight is to scale up the length and complexity of the dataset examples towards a critical 'Goldilocks' zone wherein generated text is ridiculous to humans, yet often misclassified by state-of-the-art models. Our construction of HellaSwag, and its resulting difficulty, sheds light on the inner workings of deep pretrained models. More broadly, it suggests a new path forward for NLP research, in which benchmarks co-evolve with the evolving state-of-the-art in an adversarial way, so as to present ever-harder challenges.