 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Ranking and Generation in Query Auto-Completion via Retrieval-Augmented Generation and Multi-Objective Alignment
Feb 03, 2026Query Auto-Completion (QAC) suggests query completions as users type, helping them articulate intent and reach results more efficiently. Existing approaches face fundamental challenges: traditional retrieve-and-rank pipelines have limited long-tail coverage and require extensive feature engineering, while recent generative methods suffer from hallucination and safety risks. We present a unified framework that reformulates QAC as end-to-end list generation through Retrieval-Augmented Generation (RAG) and multi-objective Direct Preference Optimization (DPO). Our approach combines three key innovations: (1) reformulating QAC as end-to-end list generation with multi-objective optimization; (2) defining and deploying a suite of rule-based, model-based, and LLM-as-judge verifiers for QAC, and using them in a comprehensive methodology that combines RAG, multi-objective DPO, and iterative critique-revision for high-quality synthetic data; (3) a hybrid serving architecture enabling efficient production deployment under strict latency constraints. Evaluation on a large-scale commercial search platform demonstrates substantial improvements: offline metrics show gains across all dimensions, human evaluation yields +0.40 to +0.69 preference scores, and a controlled online experiment achieves 5.44\% reduction in keystrokes and 3.46\% increase in suggestion adoption, validating that unified generation with RAG and multi-objective alignment provides an effective solution for production QAC. This work represents a paradigm shift to end-to-end generation powered by large language models, RAG, and multi-objective alignment, establishing a production-validated framework that can benefit the broader search and recommendation industry.
Edited Media Understanding: Reasoning About Implications of Manipulated Images
Dec 08, 2020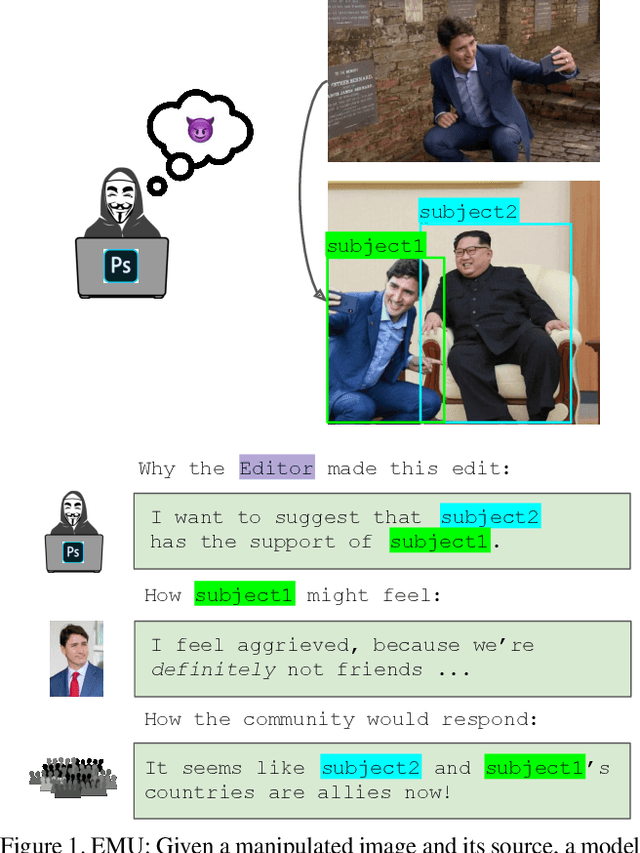

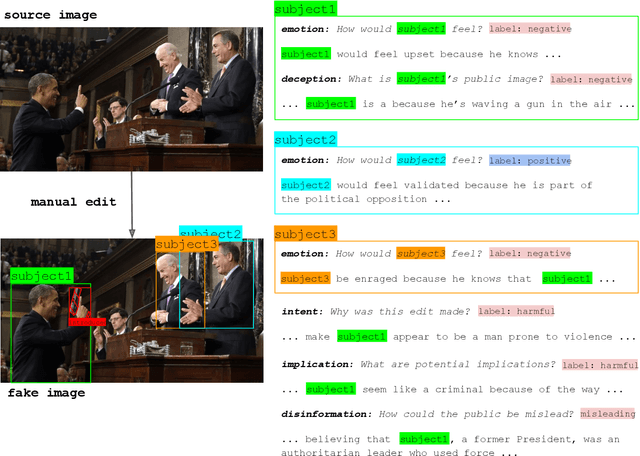
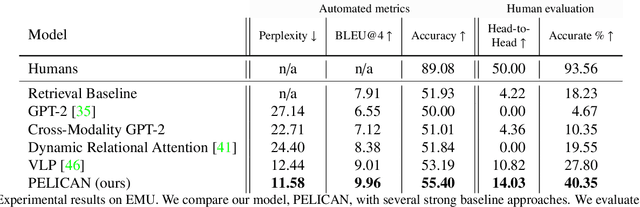
Multimodal disinformation, from `deepfakes' to simple edits that deceive, is an important societal problem. Yet at the same time, the vast majority of media edits are harmless -- such as a filtered vacation photo. The difference between this example, and harmful edits that spread disinformation, is one of intent. Recognizing and describing this intent is a major challenge for today's AI systems. We present the task of Edited Media Understanding, requiring models to answer open-ended questions that capture the intent and implications of an image edit. We introduce a dataset for our task, EMU, with 48k question-answer pairs written in rich natural language. We evaluate a wide variety of vision-and-language models for our task, and introduce a new model PELICAN, which builds upon recent progress in pretrained multimodal representations. Our model obtains promising results on our dataset, with humans rating its answers as accurate 40.35% of the time. At the same time, there is still much work to be done -- humans prefer human-annotated captions 93.56% of the time -- and we provide analysis that highlights areas for further progress.