 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMV-LIO: An Efficient Multiple Vision aided LiDAR-Inertial Odometry
Feb 15, 2023To deal with the degeneration caused by the incomplete constraints of single sensor, multi-sensor fusion strategies especially in LiDAR-vision-inertial fusion area have attracted much interest from both the industry and the research community in recent years. Considering that a monocular camera is vulnerable to the influence of ambient light from a certain direction and fails, which makes the system degrade into a LiDAR-inertial system, multiple cameras are introduced to expand the visual observation so as to improve the accuracy and robustness of the system. Besides, removing LiDAR's noise via range image, setting condition for nearest neighbor search, and replacing kd-Tree with ikd-Tree are also introduced to enhance the efficiency. Based on the above, we propose an Efficient Multiple vision aided LiDAR-inertial odometry system (EMV-LIO), and evaluate its performance on both open datasets and our custom datasets. Experiments show that the algorithm is helpful to improve the accuracy, robustness and efficiency of the whole system compared with LVI-SAM. Our implementation will be available upon acceptance.
DAMS-LIO: A Degeneration-Aware and Modular Sensor-Fusion LiDAR-inertial Odometry
Feb 08, 2023



The fusion scheme is crucial to the multi-sensor fusion method that is the promising solution to the state estimation in complex and extreme environments like underground mines and planetary surfaces. In this work, a light-weight iEKF-based LiDAR-inertial odometry system is presented, which utilizes a degeneration-aware and modular sensor-fusion pipeline that takes both LiDAR points and relative pose from another odometry as the measurement in the update process only when degeneration is detected. Both the CRLB theory and simulation test are used to demonstrate the higher accuracy of our method compared to methods using a single observation. Furthermore, the proposed system is evaluated in perceptually challenging datasets against various state-of-the-art sensor-fusion methods. The results show that the proposed system achieves real-time and high estimation accuracy performance despite the challenging environment and poor observations.
Open-Set Object Detection Using Classification-free Object Proposal and Instance-level Contrastive Learning with Appendix
Nov 21, 2022



Detecting both known and unknown objects is a fundamental skill for robot manipulation in unstructured environments. Open-set object detection (OSOD) is a promising direction to handle the problem consisting of two subtasks: objects and background separation, and open-set object classification. In this paper, we present Openset RCNN to address the challenging OSOD. To disambiguate unknown objects and background in the first subtask, we propose to use classification-free region proposal network (CF-RPN) which estimates the objectness score of each region purely using cues from object's location and shape preventing overfitting to the training categories. To identify unknown objects in the second subtask, we propose to represent them using the complementary region of known categories in a latent space which is accomplished by a prototype learning network (PLN). PLN performs instance-level contrastive learning to encode proposals to a latent space and builds a compact region centering with a prototype for each known category. Further, we note that the detection performance of unknown objects can not be unbiasedly evaluated on the situation that commonly used object detection datasets are not fully annotated. Thus, a new benchmark is introduced by reorganizing GraspNet-1billion, a robotic grasp pose detection dataset with complete annotation. Extensive experiments demonstrate the merits of our method. We finally show that our Openset RCNN can endow the robot with an open-set perception ability to support robotic rearrangement tasks in cluttered environments. More details can be found in https://sites.google.com/view/openest-rcnn/
RING++: Roto-translation Invariant Gram for Global Localization on a Sparse Scan Map
Oct 12, 2022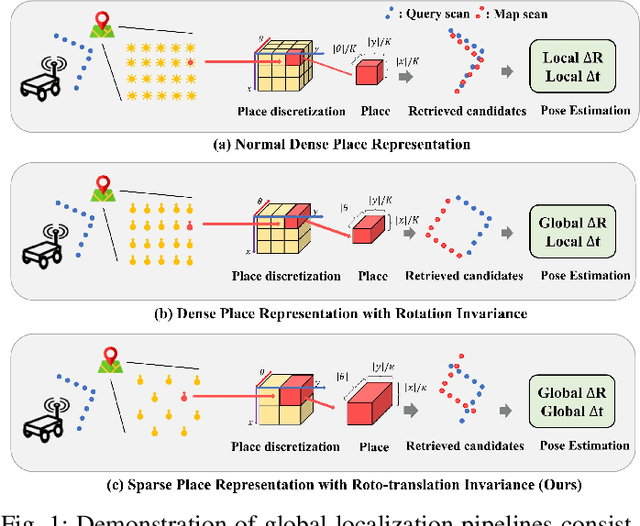
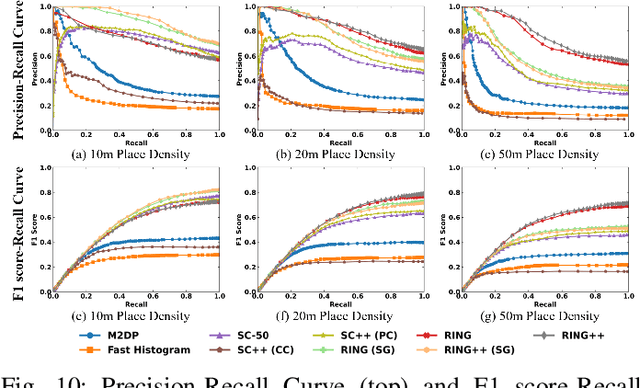
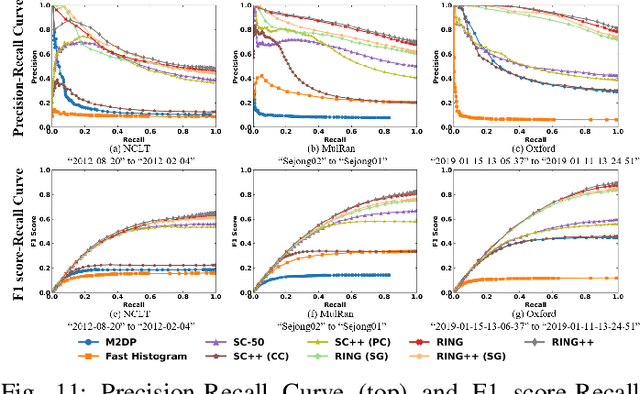
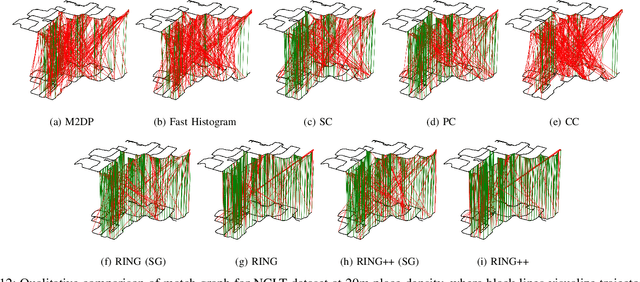
Global localization plays a critical role in many robot applications. LiDAR-based global localization draws the community's focus with its robustness against illumination and seasonal changes. To further improve the localization under large viewpoint differences, we propose RING++ which has roto-translation invariant representation for place recognition, and global convergence for both rotation and translation estimation. With the theoretical guarantee, RING++ is able to address the large viewpoint difference using a lightweight map with sparse scans. In addition, we derive sufficient conditions of feature extractors for the representation preserving the roto-translation invariance, making RING++ a framework applicable to generic multi-channel features. To the best of our knowledge, this is the first learning-free framework to address all subtasks of global localization in the sparse scan map. Validations on real-world datasets show that our approach demonstrates better performance than state-of-the-art learning-free methods, and competitive performance with learning-based methods. Finally, we integrate RING++ into a multi-robot/session SLAM system, performing its effectiveness in collaborative applications.
C^2:Co-design of Robots via Concurrent Networks Coupling Online and Offline Reinforcement Learning
Sep 14, 2022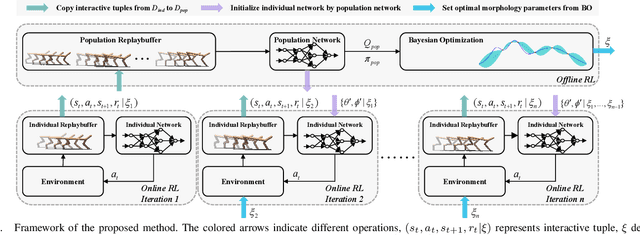
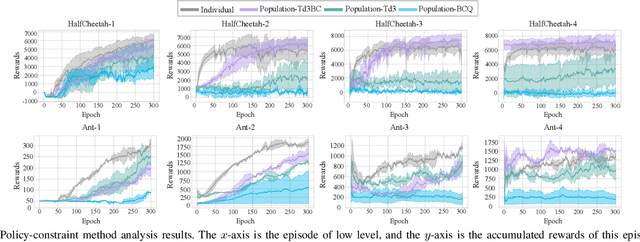
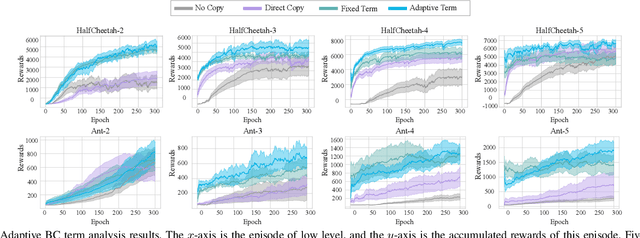
With the rise of computing power, using data-driven approaches for co-designing robots' morphology and controller has become a feasible way. Nevertheless, evaluating the fitness of the controller under each morphology is time-consuming. As a pioneering data-driven method, Co-adaptation utilizes a double-network mechanism with the aim of learning a Q function conditioned on morphology parameters to replace the traditional evaluation of a diverse set of candidates, thereby speeding up optimization. In this paper, we find that Co-adaptation ignores the existence of exploration error during training and state-action distribution shift during parameter transmitting, which hurt the performance. We propose the framework of the concurrent network that couples online and offline RL methods. By leveraging the behavior cloning term flexibly, we mitigate the impact of the above issues on the results. Simulation and physical experiments are performed to demonstrate that our proposed method outperforms baseline algorithms, which illustrates that the proposed method is an effective way of discovering the optimal combination of morphology and controller.
Efficient Distance-Optimal Tethered Path Planning in Planar Environments: The Workspace Convexity
Aug 08, 2022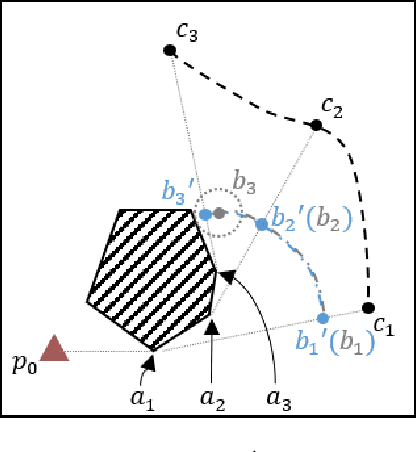
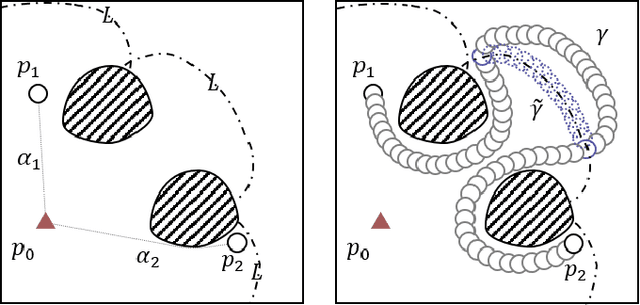
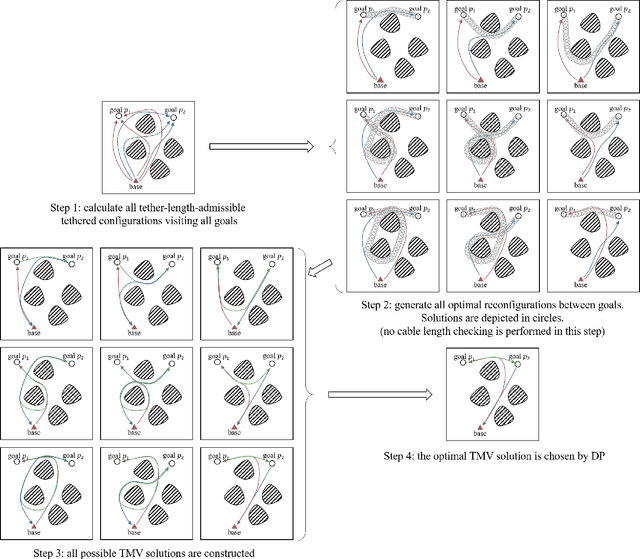
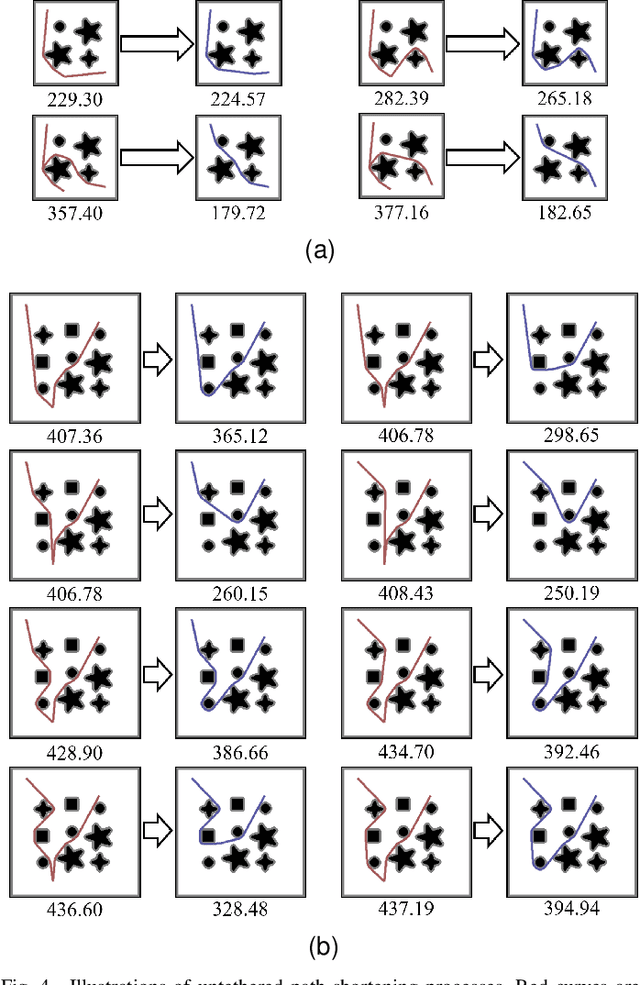
The main contribution of this paper is the proof of the convexity of the omni-directional tethered robot workspace (namely, the set of all tether-length-admissible robot configurations), as well as a set of distance-optimal tethered path planning algorithms that leverage the workspace convexity. The workspace is proven to be topologically a simply-connected subset and geometrically a convex subset of the set of all configurations. As a direct result, the tether-length-admissible optimal path between two configurations is proven exactly the untethered collision-free locally shortest path in the homotopy specified by the concatenation of the tether curve of the given configurations, which can be simply constructed by performing an untethered path shortening process in the 2D environment instead of a path searching process in the pre-calculated workspace. The convexity is an intrinsic property to the tethered robot kinematics, thus has universal impacts on all high-level distance-optimal tethered path planning tasks: The most time-consuming workspace pre-calculation (WP) process is replaced with a goal configuration pre-calculation (GCP) process, and the homotopy-aware path searching process is replaced with untethered path shortening processes. Motivated by the workspace convexity, efficient algorithms to solve the following problems are naturally proposed: (a) The optimal tethered reconfiguration (TR) planning problem is solved by a locally untethered path shortening (UPS) process, (b) The classic optimal tethered path (TP) planning problem (from a starting configuration to a goal location whereby the target tether state is not assigned) is solved by a GCP process and $n$ UPS processes, where $n$ is the number of tether-length-admissible configurations that visit the goal location, (c) The optimal tethered motion to visit a sequence of multiple goal locations, referred to as
Efficient Search of the k Shortest Non-Homotopic Paths by Eliminating Non-k-Optimal Topologies
Jul 27, 2022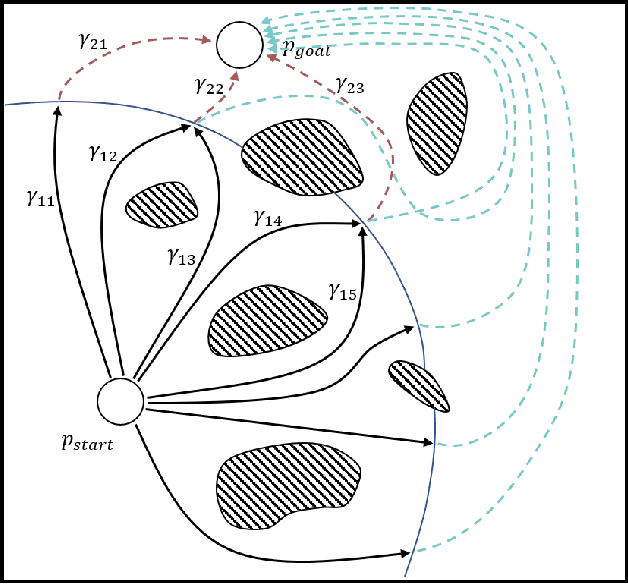
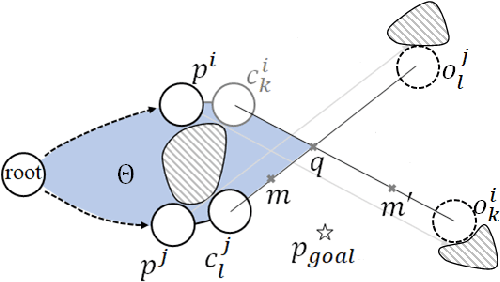
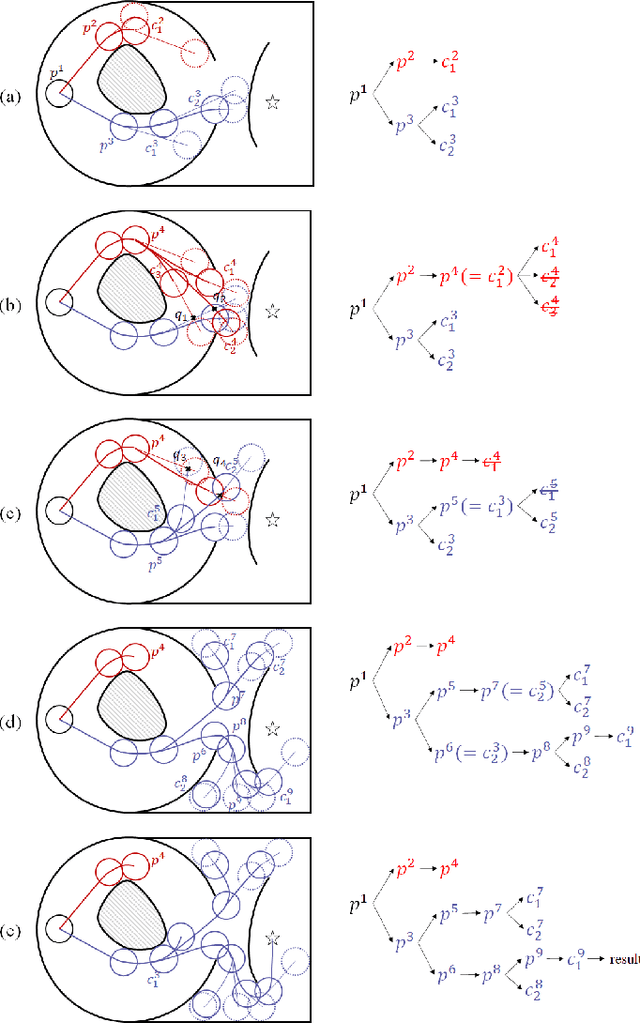
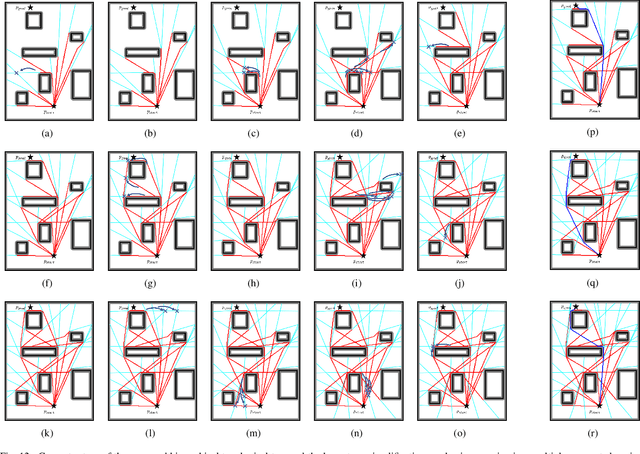
An efficient algorithm to solve the $k$ shortest non-homotopic path planning ($k$-SNPP) problem in a 2D environment is proposed in this paper. Motivated by accelerating the inefficient exploration of the homotopy-augmented space of the 2D environment, our fundamental idea is to identify the non-$k$-optimal path topologies as early as possible and terminate the pathfinding along them. This is a non-trivial practice because it has to be done at an intermediate state of the path planning process when locally shortest paths have not been fully constructed. In other words, the paths to be compared have not rendezvoused at the goal location, which makes the homotopy theory, modelling the spatial relationship among the paths having the same endpoint, not applicable. This paper is the first work that develops a systematic distance-based topology simplification mechanism to solve the $k$-SNPP task, whose core contribution is to assert the distance-based order of non-homotopic locally shortest paths before constructing them. If the order can be predicted, then those path topologies having more than $k$ better topologies are proven free of the desired $k$ paths and thus can be safely discarded during the path planning process. To this end, a hierarchical topological tree is proposed as an implementation of the mechanism, whose nodes are proven to expand in non-homotopic directions and edges (collision-free path segments) are proven locally shortest. With efficient criteria that observe the order relations between partly constructed locally shortest paths being imparted into the tree, the tree nodes that expand in non-$k$-optimal topologies will not be expanded. As a result, the computational time for solving the $k$-SNPP problem is reduced by near two orders of magnitude.
FEJ-VIRO: A Consistent First-Estimate Jacobian Visual-Inertial-Ranging Odometry
Jul 17, 2022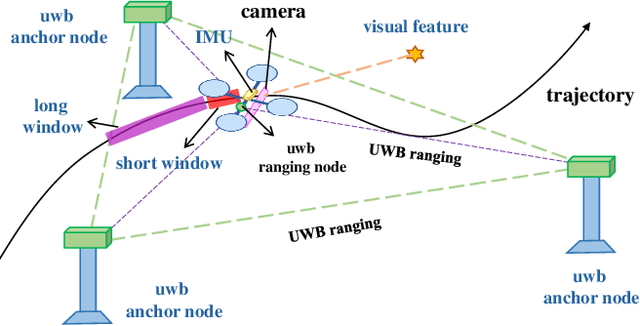
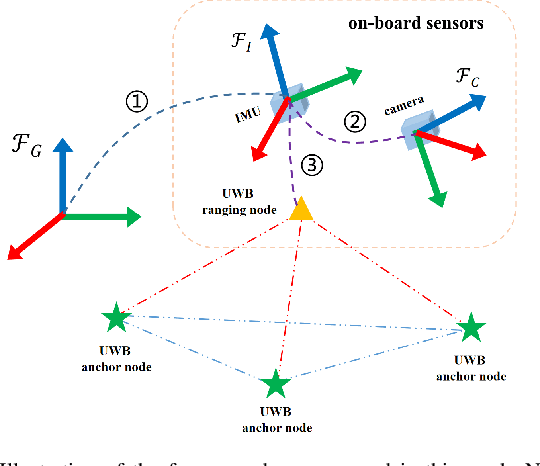
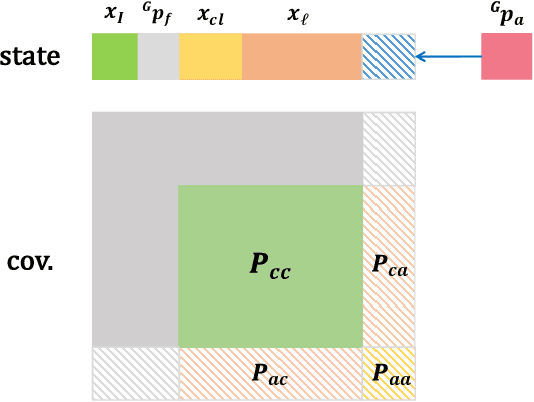
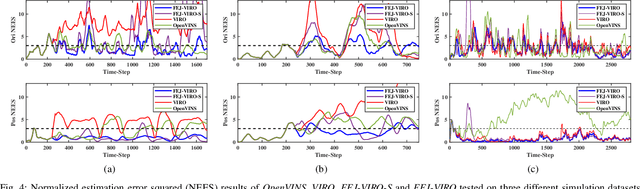
In recent years, Visual-Inertial Odometry (VIO) has achieved many significant progresses. However, VIO methods suffer from localization drift over long trajectories. In this paper, we propose a First-Estimates Jacobian Visual-Inertial-Ranging Odometry (FEJ-VIRO) to reduce the localization drifts of VIO by incorporating ultra-wideband (UWB) ranging measurements into the VIO framework \textit{consistently}. Considering that the initial positions of UWB anchors are usually unavailable, we propose a long-short window structure to initialize the UWB anchors' positions as well as the covariance for state augmentation. After initialization, the FEJ-VIRO estimates the UWB anchors' positions simultaneously along with the robot poses. We further analyze the observability of the visual-inertial-ranging estimators and proved that there are \textit{four} unobservable directions in the ideal case, while one of them vanishes in the actual case due to the gain of spurious information. Based on these analyses, we leverage the FEJ technique to enforce the unobservable directions, hence reducing inconsistency of the estimator. Finally, we validate our analysis and evaluate the proposed FEJ-VIRO with both simulation and real-world experiments.
Towards Two-view 6D Object Pose Estimation: A Comparative Study on Fusion Strategy
Jul 01, 2022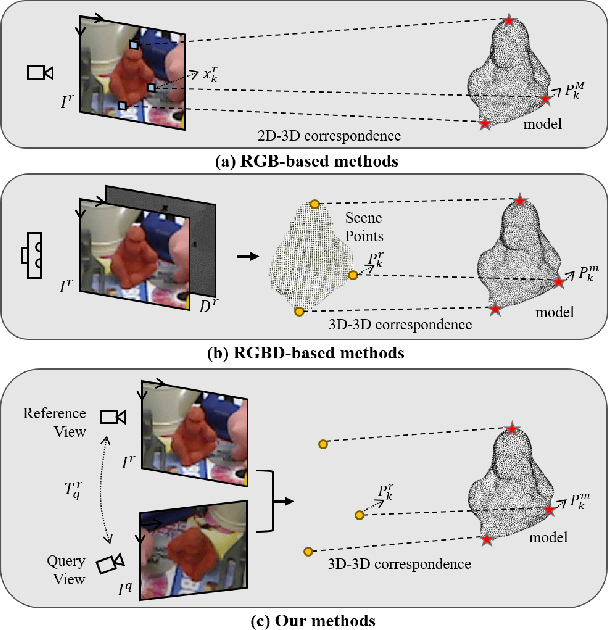
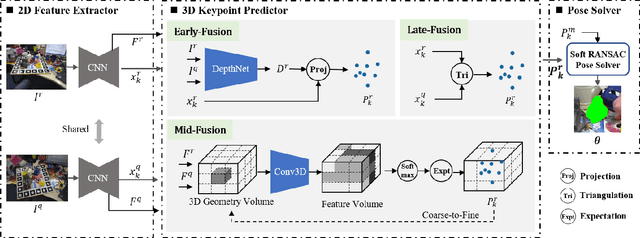

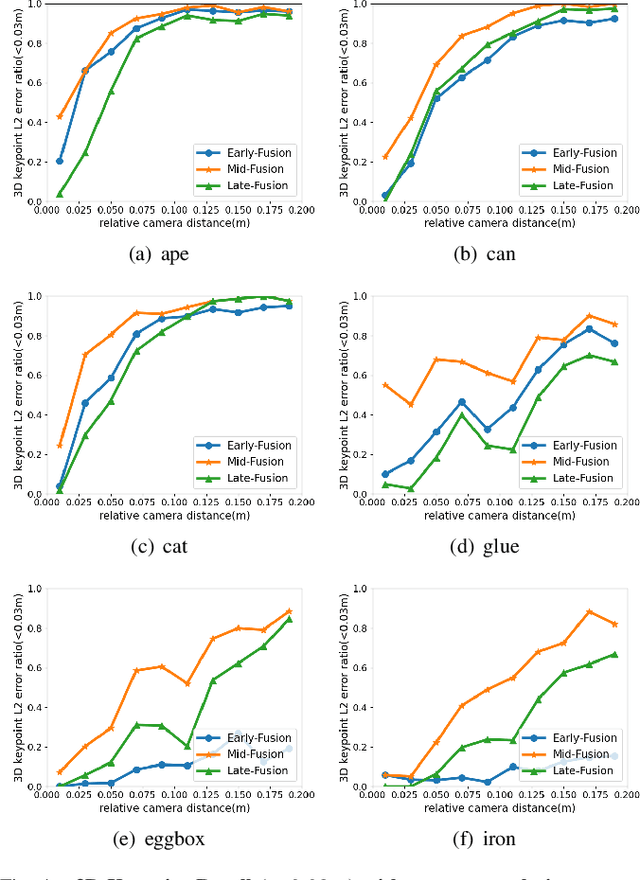
Current RGB-based 6D object pose estimation methods have achieved noticeable performance on datasets and real world applications. However, predicting 6D pose from single 2D image features is susceptible to disturbance from changing of environment and textureless or resemblant object surfaces. Hence, RGB-based methods generally achieve less competitive results than RGBD-based methods, which deploy both image features and 3D structure features. To narrow down this performance gap, this paper proposes a framework for 6D object pose estimation that learns implicit 3D information from 2 RGB images. Combining the learned 3D information and 2D image features, we establish more stable correspondence between the scene and the object models. To seek for the methods best utilizing 3D information from RGB inputs, we conduct an investigation on three different approaches, including Early- Fusion, Mid-Fusion, and Late-Fusion. We ascertain the Mid- Fusion approach is the best approach to restore the most precise 3D keypoints useful for object pose estimation. The experiments show that our method outperforms state-of-the-art RGB-based methods, and achieves comparable results with RGBD-based methods.
DPCN++: Differentiable Phase Correlation Network for Versatile Pose Registration
Jun 12, 2022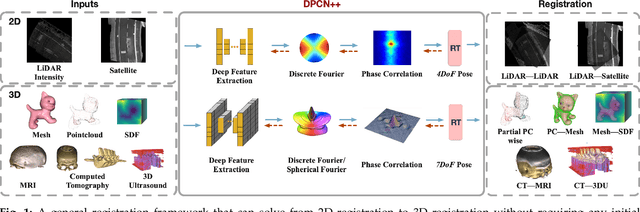
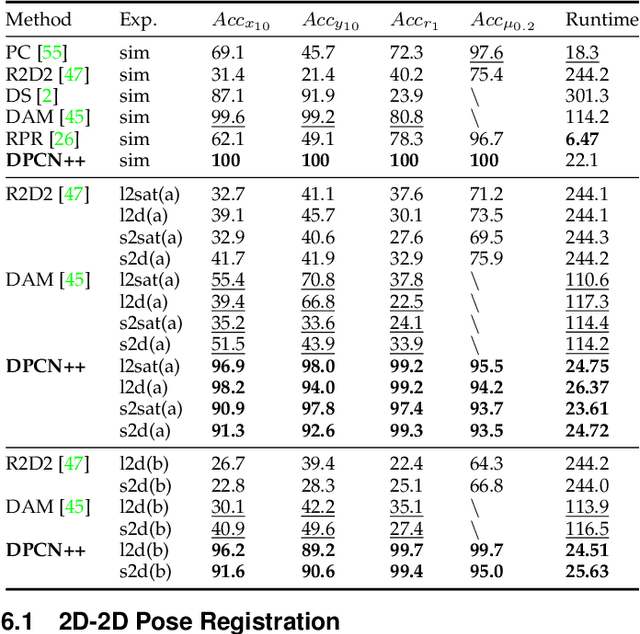
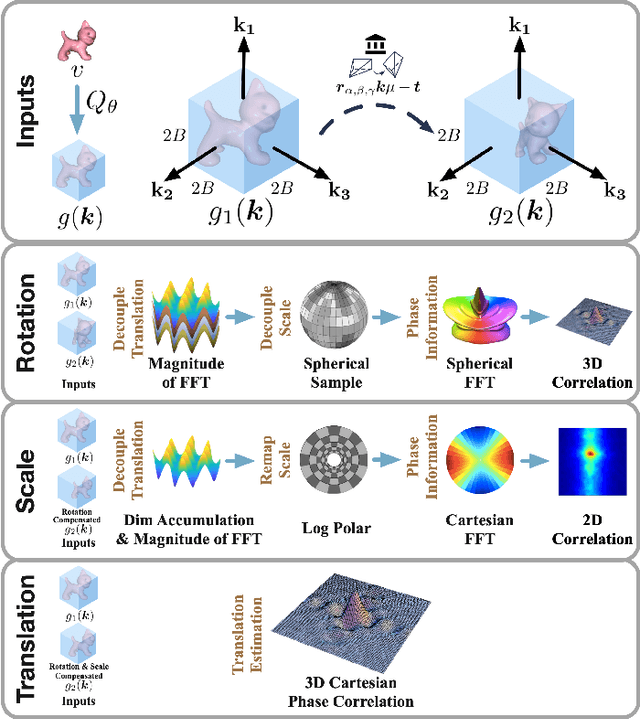

Pose registration is critical in vision and robotics. This paper focuses on the challenging task of initialization-free pose registration up to 7DoF for homogeneous and heterogeneous measurements. While recent learning-based methods show promise using differentiable solvers, they either rely on heuristically defined correspondences or are prone to local minima. We present a differentiable phase correlation (DPC) solver that is globally convergent and correspondence-free. When combined with simple feature extraction networks, our general framework DPCN++ allows for versatile pose registration with arbitrary initialization. Specifically, the feature extraction networks first learn dense feature grids from a pair of homogeneous/heterogeneous measurements. These feature grids are then transformed into a translation and scale invariant spectrum representation based on Fourier transform and spherical radial aggregation, decoupling translation and scale from rotation. Next, the rotation, scale, and translation are independently and efficiently estimated in the spectrum step-by-step using the DPC solver. The entire pipeline is differentiable and trained end-to-end. We evaluate DCPN++ on a wide range of registration tasks taking different input modalities, including 2D bird's-eye view images, 3D object and scene measurements, and medical images. Experimental results demonstrate that DCPN++ outperforms both classical and learning-based baselines, especially on partially observed and heterogeneous measurements.