 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBARS: Towards Open Benchmarking for Recommender Systems
Jun 01, 2022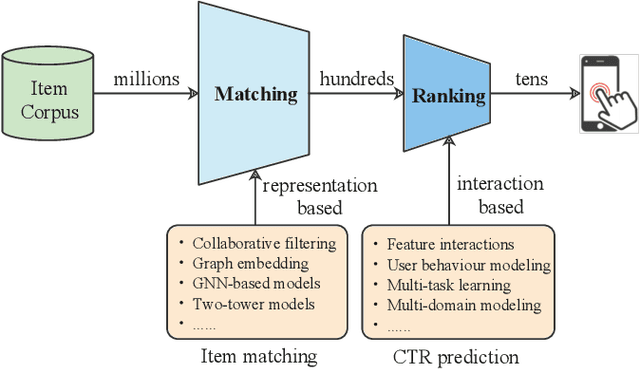
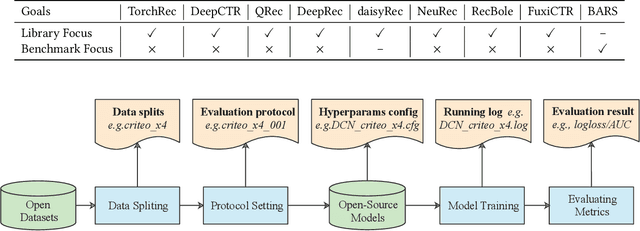
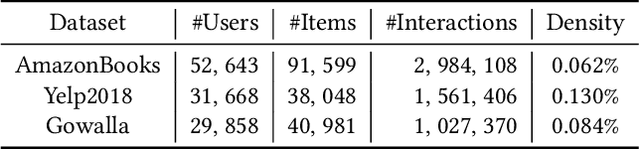
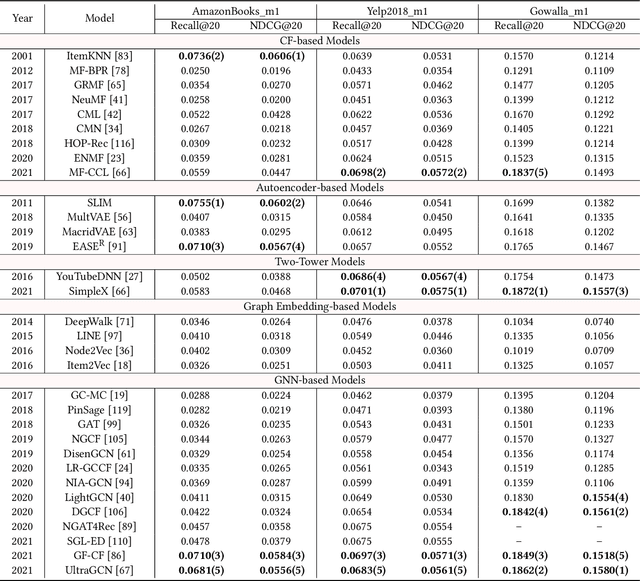
The past two decades have witnessed the rapid development of personalized recommendation techniques. Despite the significant progress made in both research and practice of recommender systems, to date, there is a lack of a widely-recognized benchmarking standard in this field. Many of the existing studies perform model evaluations and comparisons in an ad-hoc manner, for example, by employing their own private data splits or using a different experimental setting. However, such conventions not only increase the difficulty in reproducing existing studies, but also lead to inconsistent experimental results among them. This largely limits the credibility and practical value of research results in this field. To tackle these issues, we present an initiative project aimed for open benchmarking for recommender systems. In contrast to some earlier attempts towards this goal, we take one further step by setting up a standardized benchmarking pipeline for reproducible research, which integrates all the details about datasets, source code, hyper-parameter settings, running logs, and evaluation results. The benchmark is designed with comprehensiveness and sustainability in mind. It spans both matching and ranking tasks, and also allows anyone to easily follow and contribute. We believe that our benchmark could not only reduce the redundant efforts of researchers to re-implement or re-run existing baselines, but also drive more solid and reproducible research on recommender systems.
Learning Low-Dimensional Nonlinear Structures from High-Dimensional Noisy Data: An Integral Operator Approach
Feb 28, 2022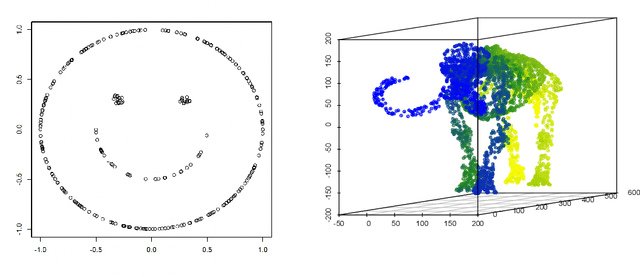
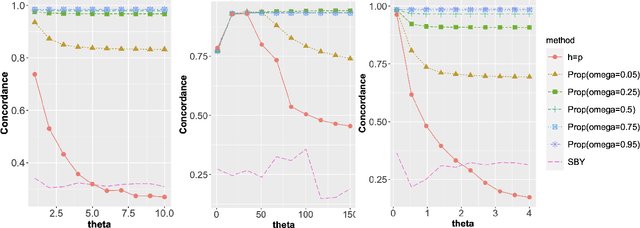
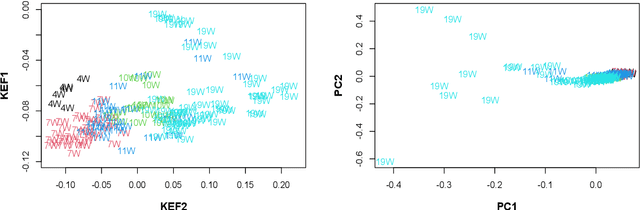
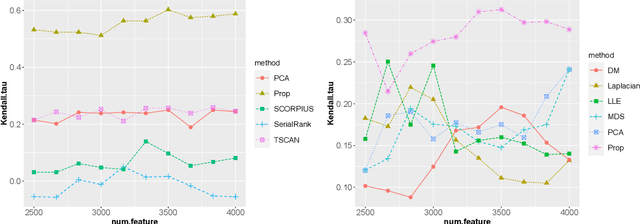
We propose a kernel-spectral embedding algorithm for learning low-dimensional nonlinear structures from high-dimensional and noisy observations, where the datasets are assumed to be sampled from an intrinsically low-dimensional manifold and corrupted by high-dimensional noise. The algorithm employs an adaptive bandwidth selection procedure which does not rely on prior knowledge of the underlying manifold. The obtained low-dimensional embeddings can be further utilized for downstream purposes such as data visualization, clustering and prediction. Our method is theoretically justified and practically interpretable. Specifically, we establish the convergence of the final embeddings to their noiseless counterparts when the dimension and size of the samples are comparably large, and characterize the effect of the signal-to-noise ratio on the rate of convergence and phase transition. We also prove convergence of the embeddings to the eigenfunctions of an integral operator defined by the kernel map of some reproducing kernel Hilbert space capturing the underlying nonlinear structures. Numerical simulations and analysis of three real datasets show the superior empirical performance of the proposed method, compared to many existing methods, on learning various manifolds in diverse applications.
Matrix Reordering for Noisy Disordered Matrices: Optimality and Computationally Efficient Algorithms
Jan 17, 2022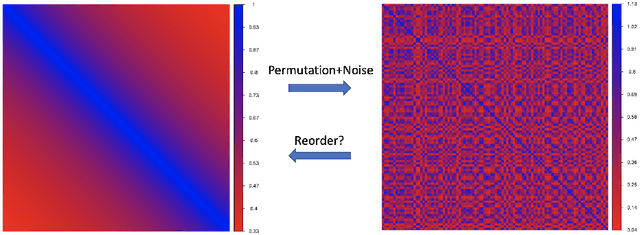
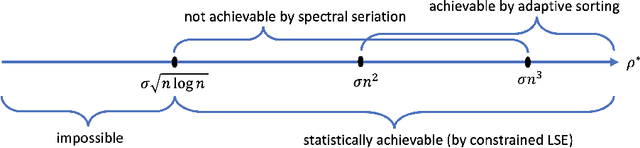
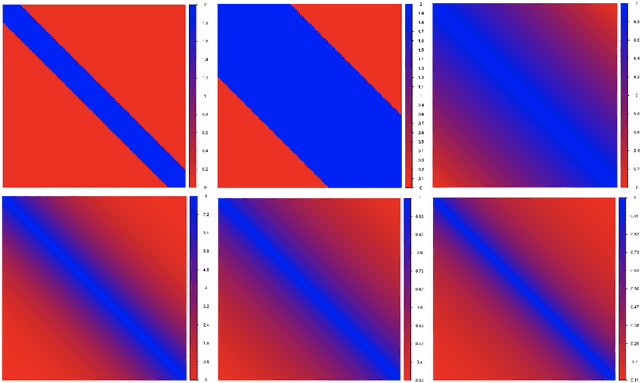
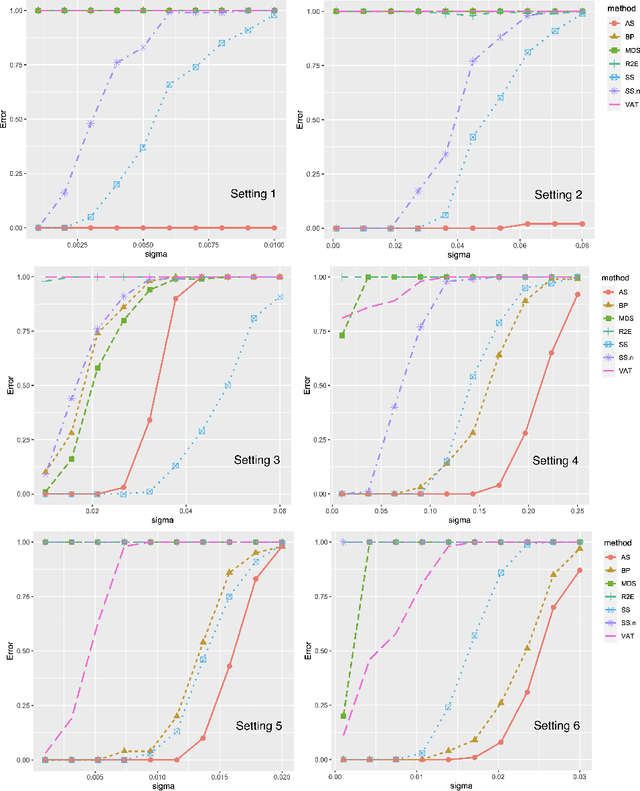
Motivated by applications in single-cell biology and metagenomics, we consider matrix reordering based on the noisy disordered matrix model. We first establish the fundamental statistical limit for the matrix reordering problem in a decision-theoretic framework and show that a constrained least square estimator is rate-optimal. Given the computational hardness of the optimal procedure, we analyze a popular polynomial-time algorithm, spectral seriation, and show that it is suboptimal. We then propose a novel polynomial-time adaptive sorting algorithm with guaranteed improvement on the performance. The superiority of the adaptive sorting algorithm over the existing methods is demonstrated in simulation studies and in the analysis of two real single-cell RNA sequencing datasets.
Semi-Supervised Statistical Inference for High-Dimensional Linear Regression with Blockwise Missing Data
Jun 07, 2021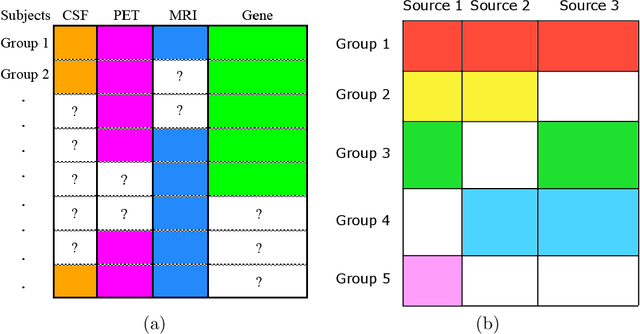
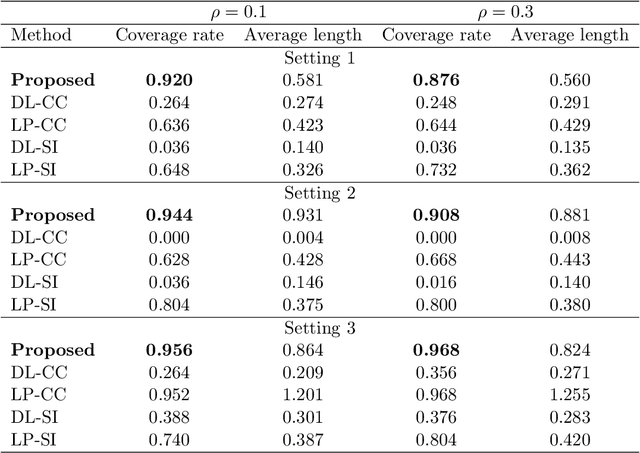
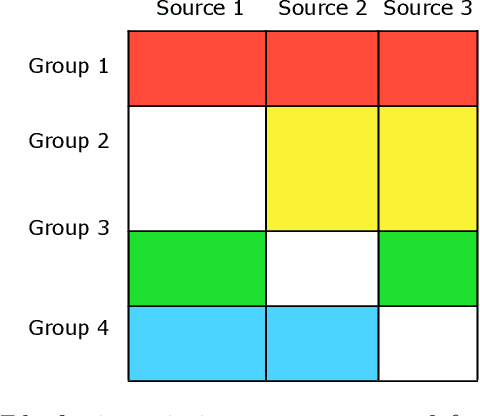
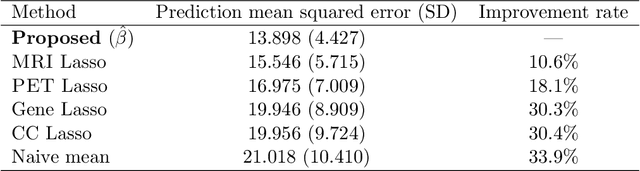
Blockwise missing data occurs frequently when we integrate multisource or multimodality data where different sources or modalities contain complementary information. In this paper, we consider a high-dimensional linear regression model with blockwise missing covariates and a partially observed response variable. Under this semi-supervised framework, we propose a computationally efficient estimator for the regression coefficient vector based on carefully constructed unbiased estimating equations and a multiple blockwise imputation procedure, and obtain its rates of convergence. Furthermore, building upon an innovative semi-supervised projected estimating equation technique that intrinsically achieves bias-correction of the initial estimator, we propose nearly unbiased estimators for the individual regression coefficients that are asymptotically normally distributed under mild conditions. By carefully analyzing these debiased estimators, asymptotically valid confidence intervals and statistical tests about each regression coefficient are constructed. Numerical studies and application analysis of the Alzheimer's Disease Neuroimaging Initiative data show that the proposed method performs better and benefits more from unsupervised samples than existing methods.
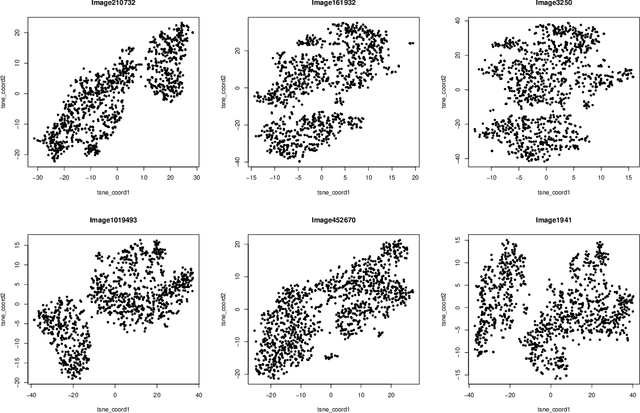
Theoretical Foundations of t-SNE for Visualizing High-Dimensional Clustered Data
May 18, 2021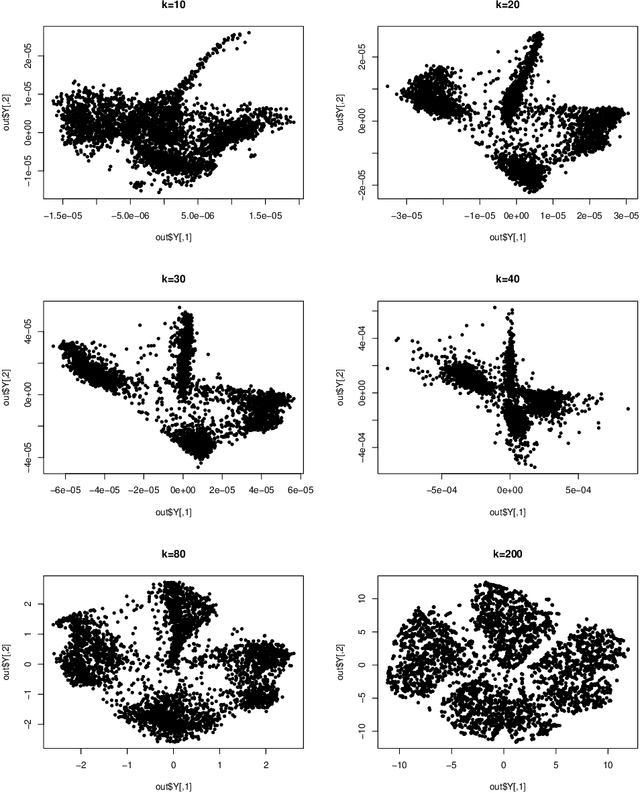
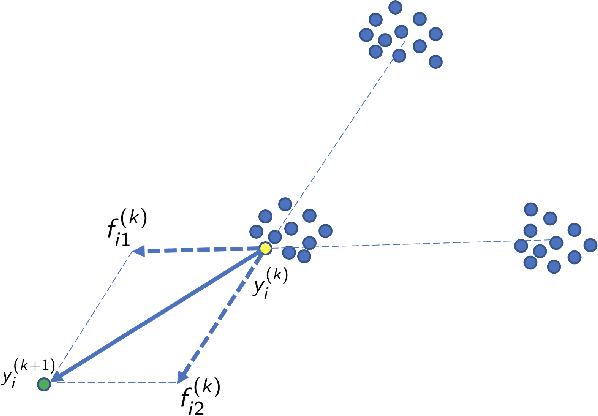
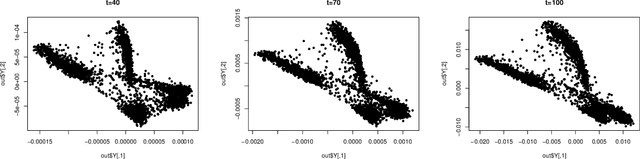
This study investigates the theoretical foundations of t-distributed stochastic neighbor embedding (t-SNE), a popular nonlinear dimension reduction and data visualization method. A novel theoretical framework for the analysis of t-SNE based on the gradient descent approach is presented. For the early exaggeration stage of t-SNE, we show its asymptotic equivalence to a power iteration based on the underlying graph Laplacian, characterize its limiting behavior, and uncover its deep connection to Laplacian spectral clustering, and fundamental principles including early stopping as implicit regularization. The results explain the intrinsic mechanism and the empirical benefits of such a computational strategy. For the embedding stage of t-SNE, we characterize the kinematics of the low-dimensional map throughout the iterations, and identify an amplification phase, featuring the intercluster repulsion and the expansive behavior of the low-dimensional map. The general theory explains the fast convergence rate and the exceptional empirical performance of t-SNE for visualizing clustered data, brings forth the interpretations of the t-SNE output, and provides theoretical guidance for selecting tuning parameters in various applications.
Estimation, Confidence Intervals, and Large-Scale Hypotheses Testing for High-Dimensional Mixed Linear Regression
Nov 06, 2020
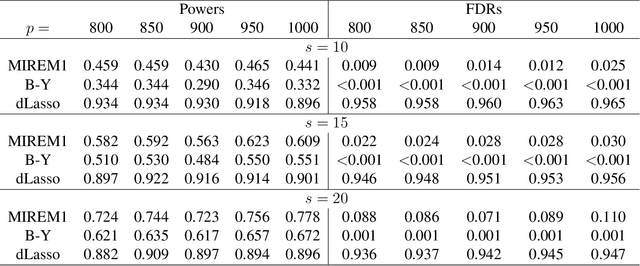
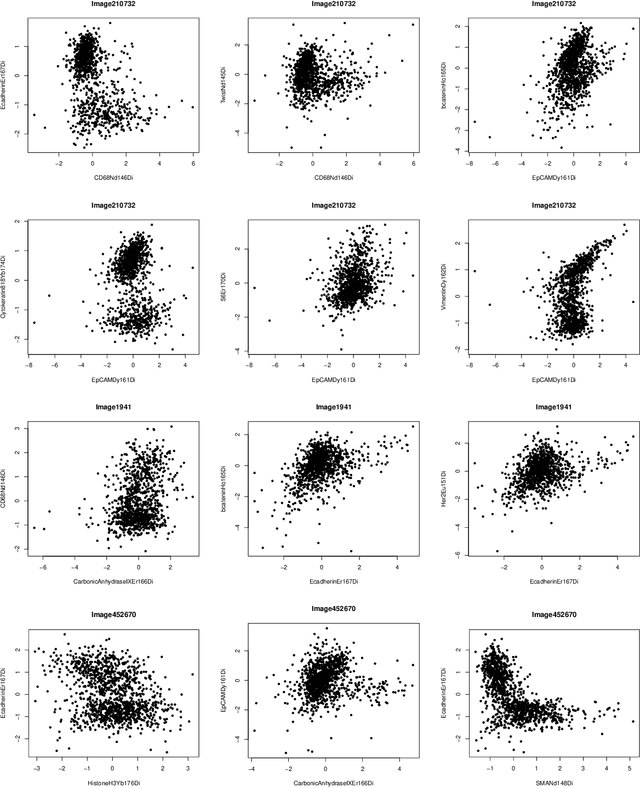
This paper studies the high-dimensional mixed linear regression (MLR) where the output variable comes from one of the two linear regression models with an unknown mixing proportion and an unknown covariance structure of the random covariates. Building upon a high-dimensional EM algorithm, we propose an iterative procedure for estimating the two regression vectors and establish their rates of convergence. Based on the iterative estimators, we further construct debiased estimators and establish their asymptotic normality. For individual coordinates, confidence intervals centered at the debiased estimators are constructed. Furthermore, a large-scale multiple testing procedure is proposed for testing the regression coefficients and is shown to control the false discovery rate (FDR) asymptotically. Simulation studies are carried out to examine the numerical performance of the proposed methods and their superiority over existing methods. The proposed methods are further illustrated through an analysis of a dataset of multiplex image cytometry, which investigates the interaction networks among the cellular phenotypes that include the expression levels of 20 epitopes or combinations of markers.
MODMA dataset: a Multi-modal Open Dataset for Mental-disorder Analysis
Mar 05, 2020
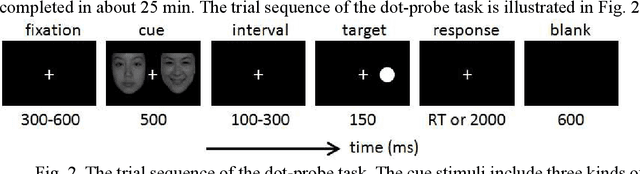

According to the World Health Organization, the number of mental disorder patients, especially depression patients, has grown rapidly and become a leading contributor to the global burden of disease. However, the present common practice of depression diagnosis is based on interviews and clinical scales carried out by doctors, which is not only labor-consuming but also time-consuming. One important reason is due to the lack of physiological indicators for mental disorders. With the rising of tools such as data mining and artificial intelligence, using physiological data to explore new possible physiological indicators of mental disorder and creating new applications for mental disorder diagnosis has become a new research hot topic. However, good quality physiological data for mental disorder patients are hard to acquire. We present a multi-modal open dataset for mental-disorder analysis. The dataset includes EEG and audio data from clinically depressed patients and matching normal controls. All our patients were carefully diagnosed and selected by professional psychiatrists in hospitals. The EEG dataset includes not only data collected using traditional 128-electrodes mounted elastic cap, but also a novel wearable 3-electrode EEG collector for pervasive applications. The 128-electrodes EEG signals of 53 subjects were recorded as both in resting state and under stimulation; the 3-electrode EEG signals of 55 subjects were recorded in resting state; the audio data of 52 subjects were recorded during interviewing, reading, and picture description. We encourage other researchers in the field to use it for testing their methods of mental-disorder analysis.
Optimal Structured Principal Subspace Estimation: Metric Entropy and Minimax Rates
Feb 23, 2020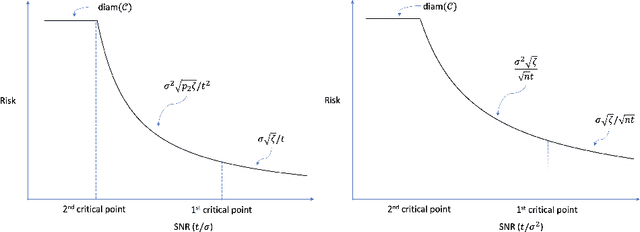
Driven by a wide range of applications, many principal subspace estimation problems have been studied individually under different structural constraints. This paper presents a unified framework for the statistical analysis of a general structured principal subspace estimation problem which includes as special cases non-negative PCA/SVD, sparse PCA/SVD, subspace constrained PCA/SVD, and spectral clustering. General minimax lower and upper bounds are established to characterize the interplay between the information-geometric complexity of the structural set for the principal subspaces, the signal-to-noise ratio (SNR), and the dimensionality. The results yield interesting phase transition phenomena concerning the rates of convergence as a function of the SNRs and the fundamental limit for consistent estimation. Applying the general results to the specific settings yields the minimax rates of convergence for those problems, including the previous unknown optimal rates for non-negative PCA/SVD, sparse SVD and subspace constrained PCA/SVD.
Scale Up Event Extraction Learning via Automatic Training Data Generation
Dec 11, 2017

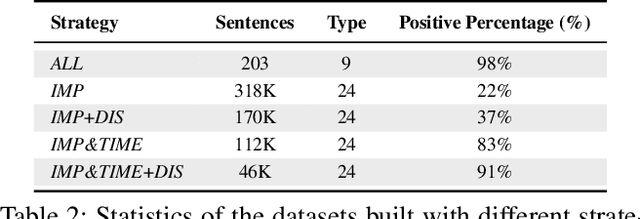
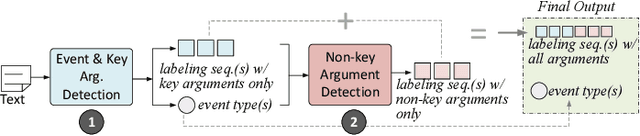
The task of event extraction has long been investigated in a supervised learning paradigm, which is bound by the number and the quality of the training instances. Existing training data must be manually generated through a combination of expert domain knowledge and extensive human involvement. However, due to drastic efforts required in annotating text, the resultant datasets are usually small, which severally affects the quality of the learned model, making it hard to generalize. Our work develops an automatic approach for generating training data for event extraction. Our approach allows us to scale up event extraction training instances from thousands to hundreds of thousands, and it does this at a much lower cost than a manual approach. We achieve this by employing distant supervision to automatically create event annotations from unlabelled text using existing structured knowledge bases or tables.We then develop a neural network model with post inference to transfer the knowledge extracted from structured knowledge bases to automatically annotate typed events with corresponding arguments in text.We evaluate our approach by using the knowledge extracted from Freebase to label texts from Wikipedia articles. Experimental results show that our approach can generate a large number of high quality training instances. We show that this large volume of training data not only leads to a better event extractor, but also allows us to detect multiple typed events.