 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulticalibration Boosting: Theory, Convergence, and Transferability
May 23, 2026Multicalibration extends classical calibration by requiring predictions to be unbiased over a rich collection of functions, encompassing both prediction slices and subpopulations. It has emerged as a powerful framework for fairness, robustness, and reliable prediction, yet the theoretical understanding of multicalibration boosting (MCBoost) remains fragmented and often relies on restrictive assumptions. In this work, we develop a unified and refined perspective on MCBoost that subsumes existing variants, including multiaccuracy, BatchGCP, and BatchMVP. We uncover several phenomena that provide new insights into its practical behavior: even highly accurate and flexible predictors can remain substantially miscalibrated; enforcing multicalibration introduces a calibration-risk trade-off; and early stopping plays a central role in controlling this trade-off. On the theoretical side, we establish a general framework for MCBoost under weaker and more realistic conditions. We show that the boosting iterates converge to a Bregman projection of the population-optimal predictor onto the cumulative span generated by the audit class, thereby explicitly characterizing the function space on which multicalibration is achieved. We further derive convergence rates under different smoothness assumptions, finite-sample guarantees, and principled stopping rules that ensure multicalibration at termination. Finally, we extend the theory of universal adaptability under covariate shift, providing more general transfer guarantees and clarifying when multicalibrated predictors generalize across domains. These results provide a more complete theoretical foundation and practical guidance for multicalibration boosting, positioning it as both a unifying framework and a reliable post-processing approach for modern predictive models.
Recent advances in deep learning and language models for studying the microbiome
Sep 15, 2024



Recent advancements in deep learning, particularly large language models (LLMs), made a significant impact on how researchers study microbiome and metagenomics data. Microbial protein and genomic sequences, like natural languages, form a language of life, enabling the adoption of LLMs to extract useful insights from complex microbial ecologies. In this paper, we review applications of deep learning and language models in analyzing microbiome and metagenomics data. We focus on problem formulations, necessary datasets, and the integration of language modeling techniques. We provide an extensive overview of protein/genomic language modeling and their contributions to microbiome studies. We also discuss applications such as novel viromics language modeling, biosynthetic gene cluster prediction, and knowledge integration for metagenomics studies.
Wasserstein F-tests for Fréchet regression on Bures-Wasserstein manifolds
Apr 05, 2024This paper considers the problem of regression analysis with random covariance matrix as outcome and Euclidean covariates in the framework of Fr\'echet regression on the Bures-Wasserstein manifold. Such regression problems have many applications in single cell genomics and neuroscience, where we have covariance matrix measured over a large set of samples. Fr\'echet regression on the Bures-Wasserstein manifold is formulated as estimating the conditional Fr\'echet mean given covariates $x$. A non-asymptotic $\sqrt{n}$-rate of convergence (up to $\log n$ factors) is obtained for our estimator $\hat{Q}_n(x)$ uniformly for $\left\|x\right\| \lesssim \sqrt{\log n}$, which is crucial for deriving the asymptotic null distribution and power of our proposed statistical test for the null hypothesis of no association. In addition, a central limit theorem for the point estimate $\hat{Q}_n(x)$ is obtained, giving insights to a test for covariate effects. The null distribution of the test statistic is shown to converge to a weighted sum of independent chi-squares, which implies that the proposed test has the desired significance level asymptotically. Also, the power performance of the test is demonstrated against a sequence of contiguous alternatives. Simulation results show the accuracy of the asymptotic distributions. The proposed methods are applied to a single cell gene expression data set that shows the change of gene co-expression network as people age.
Transfer Learning with Random Coefficient Ridge Regression
Jun 28, 2023



Ridge regression with random coefficients provides an important alternative to fixed coefficients regression in high dimensional setting when the effects are expected to be small but not zeros. This paper considers estimation and prediction of random coefficient ridge regression in the setting of transfer learning, where in addition to observations from the target model, source samples from different but possibly related regression models are available. The informativeness of the source model to the target model can be quantified by the correlation between the regression coefficients. This paper proposes two estimators of regression coefficients of the target model as the weighted sum of the ridge estimates of both target and source models, where the weights can be determined by minimizing the empirical estimation risk or prediction risk. Using random matrix theory, the limiting values of the optimal weights are derived under the setting when $p/n \rightarrow \gamma$, where $p$ is the number of the predictors and $n$ is the sample size, which leads to an explicit expression of the estimation or prediction risks. Simulations show that these limiting risks agree very well with the empirical risks. An application to predicting the polygenic risk scores for lipid traits shows such transfer learning methods lead to smaller prediction errors than the single sample ridge regression or Lasso-based transfer learning.
Transfer Learning for Contextual Multi-armed Bandits
Nov 22, 2022


Motivated by a range of applications, we study in this paper the problem of transfer learning for nonparametric contextual multi-armed bandits under the covariate shift model, where we have data collected on source bandits before the start of the target bandit learning. The minimax rate of convergence for the cumulative regret is established and a novel transfer learning algorithm that attains the minimax regret is proposed. The results quantify the contribution of the data from the source domains for learning in the target domain in the context of nonparametric contextual multi-armed bandits. In view of the general impossibility of adaptation to unknown smoothness, we develop a data-driven algorithm that achieves near-optimal statistical guarantees (up to a logarithmic factor) while automatically adapting to the unknown parameters over a large collection of parameter spaces under an additional self-similarity assumption. A simulation study is carried out to illustrate the benefits of utilizing the data from the auxiliary source domains for learning in the target domain.
Semi-Supervised Statistical Inference for High-Dimensional Linear Regression with Blockwise Missing Data
Jun 07, 2021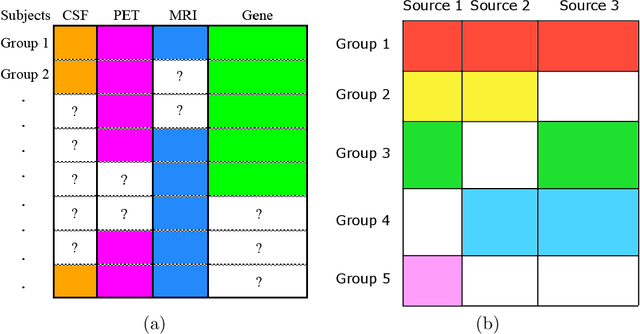
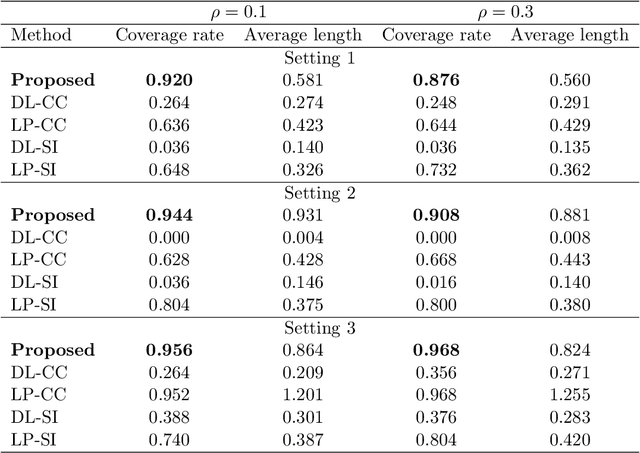
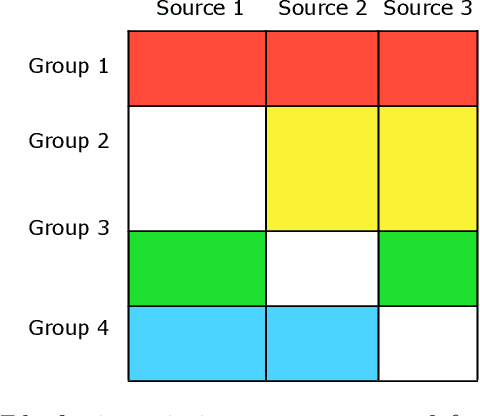
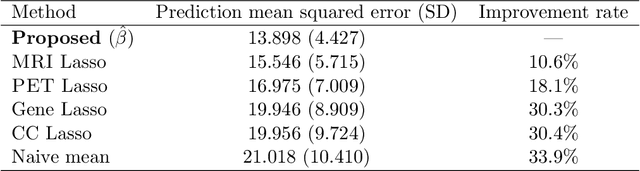
Blockwise missing data occurs frequently when we integrate multisource or multimodality data where different sources or modalities contain complementary information. In this paper, we consider a high-dimensional linear regression model with blockwise missing covariates and a partially observed response variable. Under this semi-supervised framework, we propose a computationally efficient estimator for the regression coefficient vector based on carefully constructed unbiased estimating equations and a multiple blockwise imputation procedure, and obtain its rates of convergence. Furthermore, building upon an innovative semi-supervised projected estimating equation technique that intrinsically achieves bias-correction of the initial estimator, we propose nearly unbiased estimators for the individual regression coefficients that are asymptotically normally distributed under mild conditions. By carefully analyzing these debiased estimators, asymptotically valid confidence intervals and statistical tests about each regression coefficient are constructed. Numerical studies and application analysis of the Alzheimer's Disease Neuroimaging Initiative data show that the proposed method performs better and benefits more from unsupervised samples than existing methods.
Estimation, Confidence Intervals, and Large-Scale Hypotheses Testing for High-Dimensional Mixed Linear Regression
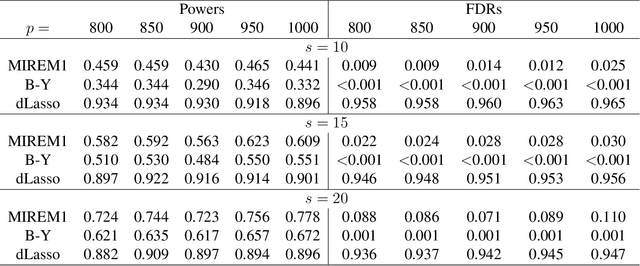
Nov 06, 2020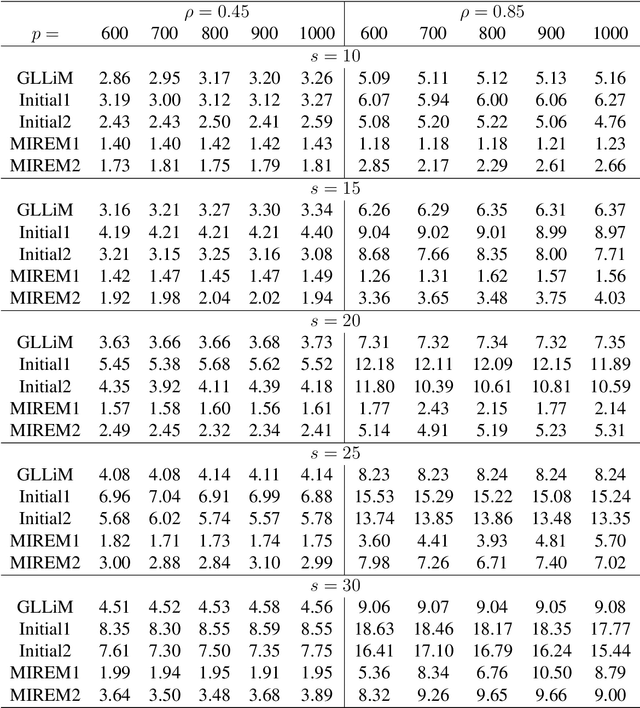
This paper studies the high-dimensional mixed linear regression (MLR) where the output variable comes from one of the two linear regression models with an unknown mixing proportion and an unknown covariance structure of the random covariates. Building upon a high-dimensional EM algorithm, we propose an iterative procedure for estimating the two regression vectors and establish their rates of convergence. Based on the iterative estimators, we further construct debiased estimators and establish their asymptotic normality. For individual coordinates, confidence intervals centered at the debiased estimators are constructed. Furthermore, a large-scale multiple testing procedure is proposed for testing the regression coefficients and is shown to control the false discovery rate (FDR) asymptotically. Simulation studies are carried out to examine the numerical performance of the proposed methods and their superiority over existing methods. The proposed methods are further illustrated through an analysis of a dataset of multiplex image cytometry, which investigates the interaction networks among the cellular phenotypes that include the expression levels of 20 epitopes or combinations of markers.
Transfer Learning in Large-scale Gaussian Graphical Models with False Discovery Rate Control
Oct 21, 2020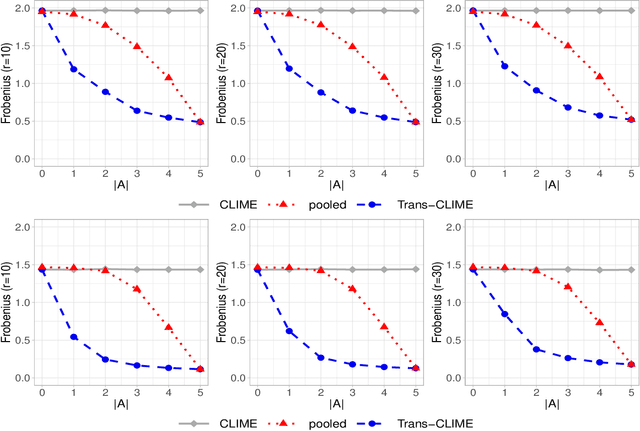
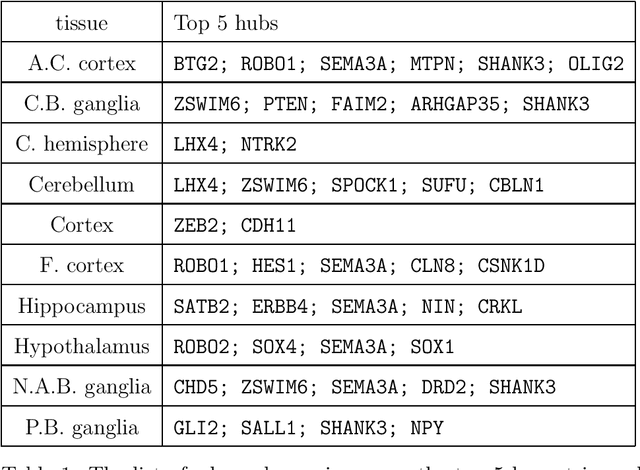
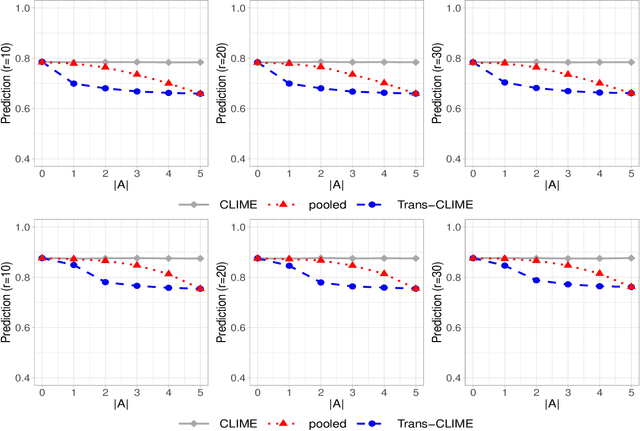
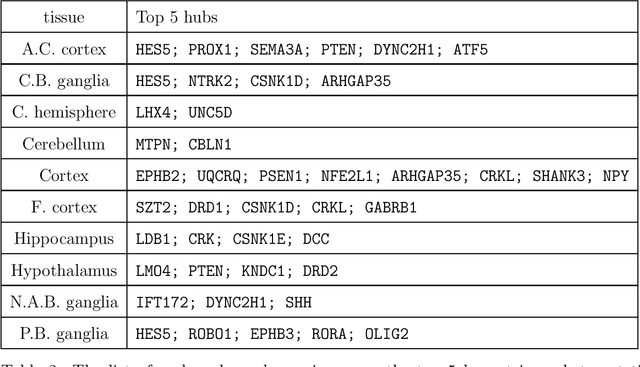
Transfer learning for high-dimensional Gaussian graphical models (GGMs) is studied with the goal of estimating the target GGM by utilizing the data from similar and related auxiliary studies. The similarity between the target graph and each auxiliary graph is characterized by the sparsity of a divergence matrix. An estimation algorithm, Trans-CLIME, is proposed and shown to attain a faster convergence rate than the minimax rate in the single study setting. Furthermore, a debiased Trans-CLIME estimator is introduced and shown to be element-wise asymptotically normal. It is used to construct a multiple testing procedure for edge detection with false discovery rate control. The proposed estimation and multiple testing procedures demonstrate superior numerical performance in simulations and are applied to infer the gene networks in a target brain tissue by leveraging the gene expressions from multiple other brain tissues. A significant decrease in prediction errors and a significant increase in power for link detection are observed.
Transfer Learning for High-dimensional Linear Regression: Prediction, Estimation, and Minimax Optimality
Jun 18, 2020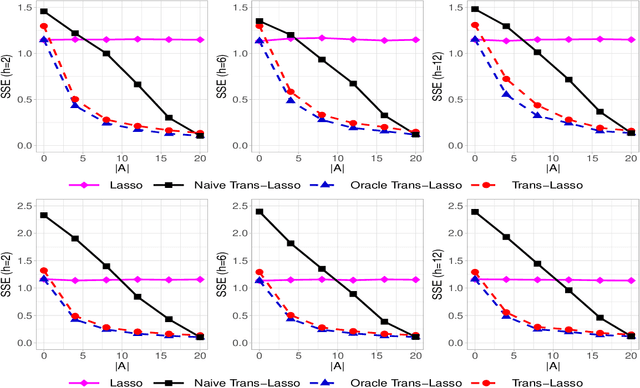
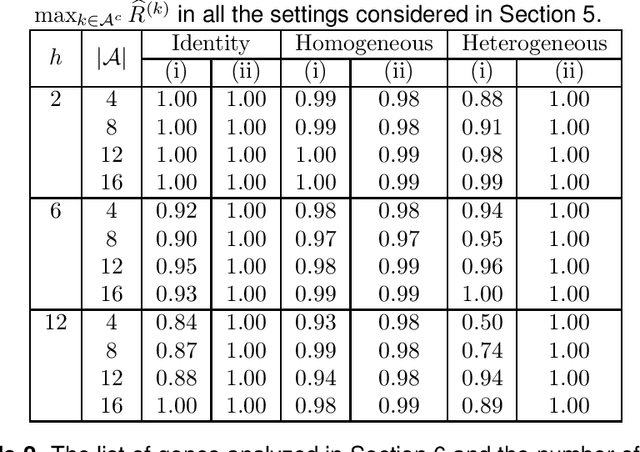
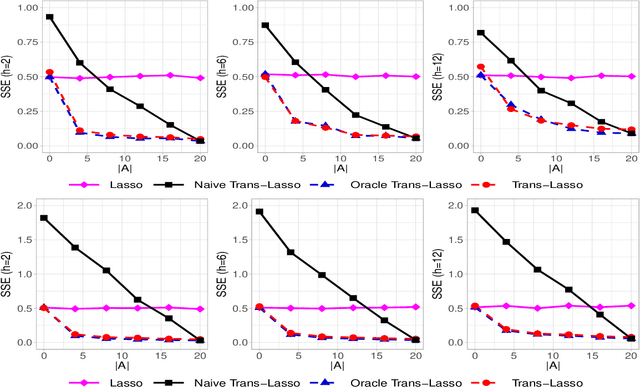
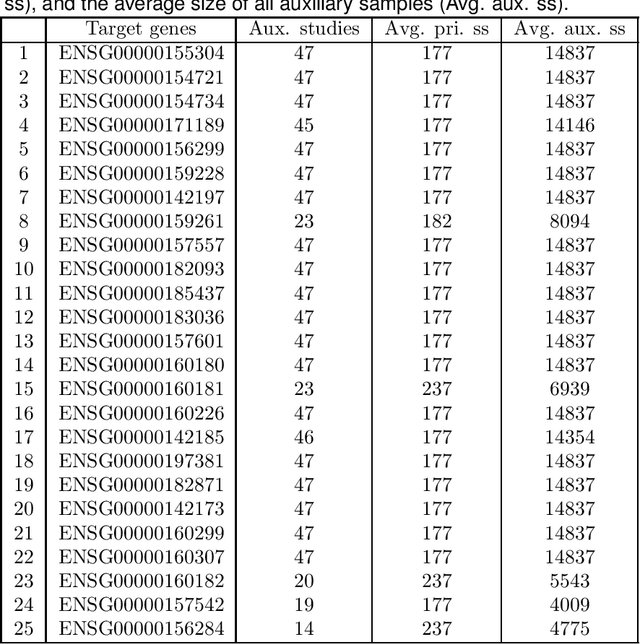
This paper considers the estimation and prediction of a high-dimensional linear regression in the setting of transfer learning, using samples from the target model as well as auxiliary samples from different but possibly related regression models. When the set of "informative" auxiliary samples is known, an estimator and a predictor are proposed and their optimality is established. The optimal rates of convergence for prediction and estimation are faster than the corresponding rates without using the auxiliary samples. This implies that knowledge from the informative auxiliary samples can be transferred to improve the learning performance of the target problem. In the case that the set of informative auxiliary samples is unknown, we propose a data-driven procedure for transfer learning, called Trans-Lasso, and reveal its robustness to non-informative auxiliary samples and its efficiency in knowledge transfer. The proposed procedures are demonstrated in numerical studies and are applied to a dataset concerning the associations among gene expressions. It is shown that Trans-Lasso leads to improved performance in gene expression prediction in a target tissue by incorporating the data from multiple different tissues as auxiliary samples.
Optimal Structured Principal Subspace Estimation: Metric Entropy and Minimax Rates
Feb 23, 2020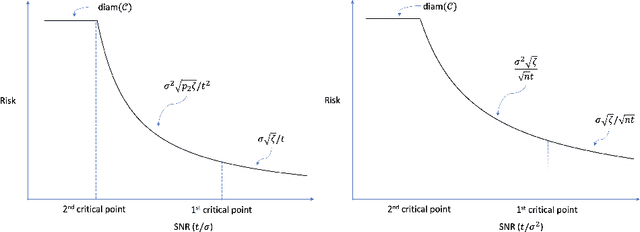
Driven by a wide range of applications, many principal subspace estimation problems have been studied individually under different structural constraints. This paper presents a unified framework for the statistical analysis of a general structured principal subspace estimation problem which includes as special cases non-negative PCA/SVD, sparse PCA/SVD, subspace constrained PCA/SVD, and spectral clustering. General minimax lower and upper bounds are established to characterize the interplay between the information-geometric complexity of the structural set for the principal subspaces, the signal-to-noise ratio (SNR), and the dimensionality. The results yield interesting phase transition phenomena concerning the rates of convergence as a function of the SNRs and the fundamental limit for consistent estimation. Applying the general results to the specific settings yields the minimax rates of convergence for those problems, including the previous unknown optimal rates for non-negative PCA/SVD, sparse SVD and subspace constrained PCA/SVD.