 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of the CAIL 2023 Argument Mining Track
Jun 20, 2024



We give a detailed overview of the CAIL 2023 Argument Mining Track, one of the Chinese AI and Law Challenge (CAIL) 2023 tracks. The main goal of the track is to identify and extract interacting argument pairs in trial dialogs. It mainly uses summarized judgment documents but can also refer to trial recordings. The track consists of two stages, and we introduce the tasks designed for each stage; we also extend the data from previous events into a new dataset -- CAIL2023-ArgMine -- with annotated new cases from various causes of action. We outline several submissions that achieve the best results, including their methods for different stages. While all submissions rely on language models, they have incorporated strategies that may benefit future work in this field.
Scale Up Event Extraction Learning via Automatic Training Data Generation
Dec 11, 2017

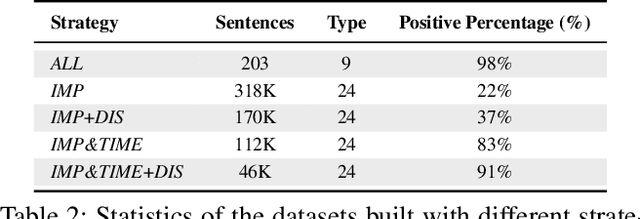
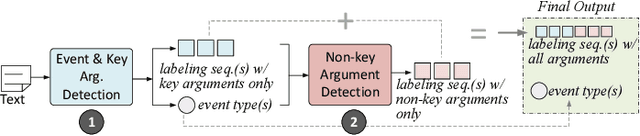
The task of event extraction has long been investigated in a supervised learning paradigm, which is bound by the number and the quality of the training instances. Existing training data must be manually generated through a combination of expert domain knowledge and extensive human involvement. However, due to drastic efforts required in annotating text, the resultant datasets are usually small, which severally affects the quality of the learned model, making it hard to generalize. Our work develops an automatic approach for generating training data for event extraction. Our approach allows us to scale up event extraction training instances from thousands to hundreds of thousands, and it does this at a much lower cost than a manual approach. We achieve this by employing distant supervision to automatically create event annotations from unlabelled text using existing structured knowledge bases or tables.We then develop a neural network model with post inference to transfer the knowledge extracted from structured knowledge bases to automatically annotate typed events with corresponding arguments in text.We evaluate our approach by using the knowledge extracted from Freebase to label texts from Wikipedia articles. Experimental results show that our approach can generate a large number of high quality training instances. We show that this large volume of training data not only leads to a better event extractor, but also allows us to detect multiple typed events.