 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlateau in Monotonic Linear Interpolation -- A "Biased" View of Loss Landscape for Deep Networks
Oct 03, 2022
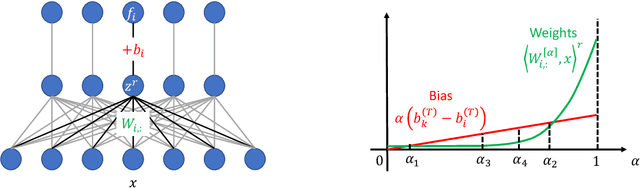
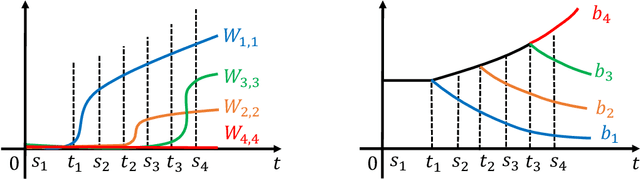

Monotonic linear interpolation (MLI) - on the line connecting a random initialization with the minimizer it converges to, the loss and accuracy are monotonic - is a phenomenon that is commonly observed in the training of neural networks. Such a phenomenon may seem to suggest that optimization of neural networks is easy. In this paper, we show that the MLI property is not necessarily related to the hardness of optimization problems, and empirical observations on MLI for deep neural networks depend heavily on biases. In particular, we show that interpolating both weights and biases linearly leads to very different influences on the final output, and when different classes have different last-layer biases on a deep network, there will be a long plateau in both the loss and accuracy interpolation (which existing theory of MLI cannot explain). We also show how the last-layer biases for different classes can be different even on a perfectly balanced dataset using a simple model. Empirically we demonstrate that similar intuitions hold on practical networks and realistic datasets.
A Regression Approach to Learning-Augmented Online Algorithms
May 25, 2022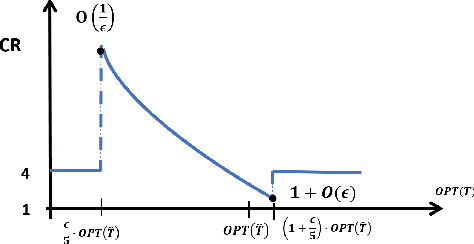
The emerging field of learning-augmented online algorithms uses ML techniques to predict future input parameters and thereby improve the performance of online algorithms. Since these parameters are, in general, real-valued functions, a natural approach is to use regression techniques to make these predictions. We introduce this approach in this paper, and explore it in the context of a general online search framework that captures classic problems like (generalized) ski rental, bin packing, minimum makespan scheduling, etc. We show nearly tight bounds on the sample complexity of this regression problem, and extend our results to the agnostic setting. From a technical standpoint, we show that the key is to incorporate online optimization benchmarks in the design of the loss function for the regression problem, thereby diverging from the use of off-the-shelf regression tools with standard bounds on statistical error.
Customizing ML Predictions for Online Algorithms
May 18, 2022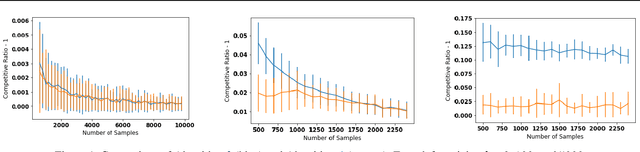
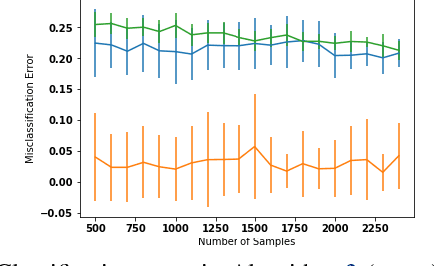
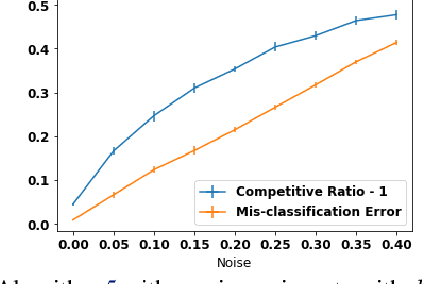
A popular line of recent research incorporates ML advice in the design of online algorithms to improve their performance in typical instances. These papers treat the ML algorithm as a black-box, and redesign online algorithms to take advantage of ML predictions. In this paper, we ask the complementary question: can we redesign ML algorithms to provide better predictions for online algorithms? We explore this question in the context of the classic rent-or-buy problem, and show that incorporating optimization benchmarks in ML loss functions leads to significantly better performance, while maintaining a worst-case adversarial result when the advice is completely wrong. We support this finding both through theoretical bounds and numerical simulations.
Online Algorithms with Multiple Predictions
May 08, 2022This paper studies online algorithms augmented with multiple machine-learned predictions. While online algorithms augmented with a single prediction have been extensively studied in recent years, the literature for the multiple predictions setting is sparse. In this paper, we give a generic algorithmic framework for online covering problems with multiple predictions that obtains an online solution that is competitive against the performance of the best predictor. Our algorithm incorporates the use of predictions in the classic potential-based analysis of online algorithms. We apply our algorithmic framework to solve classical problems such as online set cover, (weighted) caching, and online facility location in the multiple predictions setting. Our algorithm can also be robustified, i.e., the algorithm can be simultaneously made competitive against the best prediction and the performance of the best online algorithm (without prediction).
Towards Understanding the Data Dependency of Mixup-style Training
Oct 14, 2021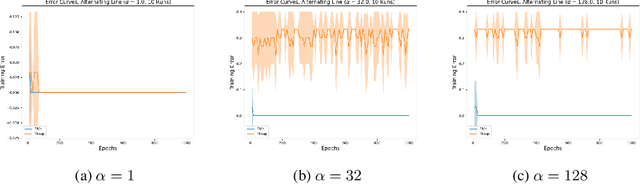
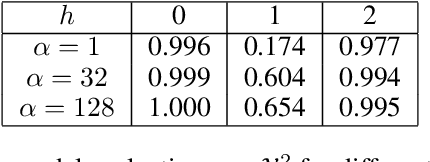
In the Mixup training paradigm, a model is trained using convex combinations of data points and their associated labels. Despite seeing very few true data points during training, models trained using Mixup seem to still minimize the original empirical risk and exhibit better generalization and robustness on various tasks when compared to standard training. In this paper, we investigate how these benefits of Mixup training rely on properties of the data in the context of classification. For minimizing the original empirical risk, we compute a closed form for the Mixup-optimal classification, which allows us to construct a simple dataset on which minimizing the Mixup loss can provably lead to learning a classifier that does not minimize the empirical loss on the data. On the other hand, we also give sufficient conditions for Mixup training to also minimize the original empirical risk. For generalization, we characterize the margin of a Mixup classifier, and use this to understand why the decision boundary of a Mixup classifier can adapt better to the full structure of the training data when compared to standard training. In contrast, we also show that, for a large class of linear models and linearly separable datasets, Mixup training leads to learning the same classifier as standard training.
Outlier-Robust Sparse Estimation via Non-Convex Optimization
Sep 23, 2021
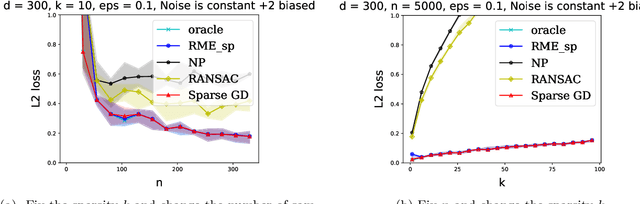
We explore the connection between outlier-robust high-dimensional statistics and non-convex optimization in the presence of sparsity constraints, with a focus on the fundamental tasks of robust sparse mean estimation and robust sparse PCA. We develop novel and simple optimization formulations for these problems such that any approximate stationary point of the associated optimization problem yields a near-optimal solution for the underlying robust estimation task. As a corollary, we obtain that any first-order method that efficiently converges to stationarity yields an efficient algorithm for these tasks. The obtained algorithms are simple, practical, and succeed under broader distributional assumptions compared to prior work.
Understanding Deflation Process in Over-parametrized Tensor Decomposition
Jun 11, 2021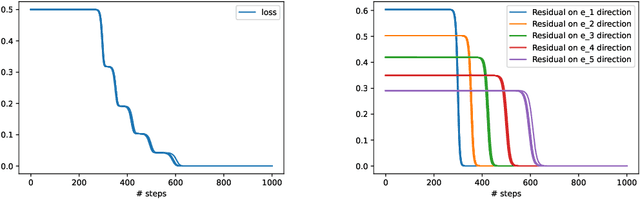
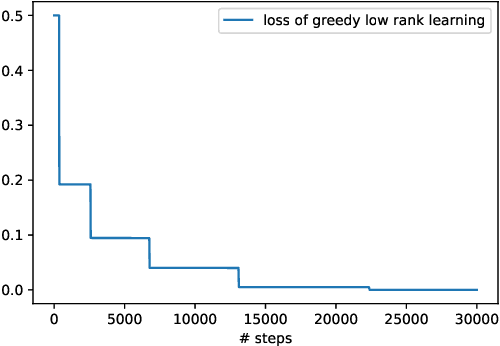

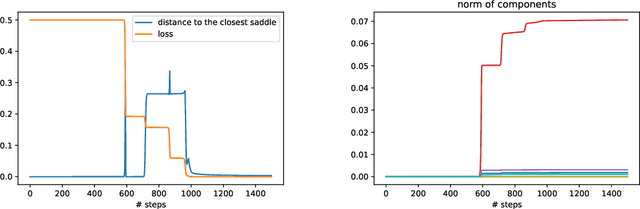
In this paper we study the training dynamics for gradient flow on over-parametrized tensor decomposition problems. Empirically, such training process often first fits larger components and then discovers smaller components, which is similar to a tensor deflation process that is commonly used in tensor decomposition algorithms. We prove that for orthogonally decomposable tensor, a slightly modified version of gradient flow would follow a tensor deflation process and recover all the tensor components. Our proof suggests that for orthogonal tensors, gradient flow dynamics works similarly as greedy low-rank learning in the matrix setting, which is a first step towards understanding the implicit regularization effect of over-parametrized models for low-rank tensors.
A Local Convergence Theory for Mildly Over-Parameterized Two-Layer Neural Network
Feb 04, 2021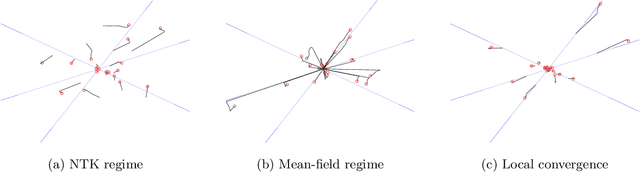
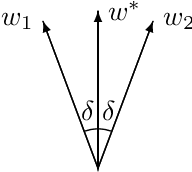
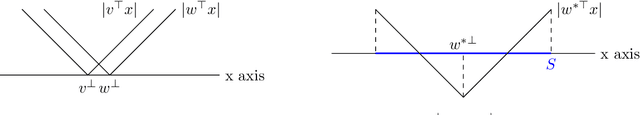
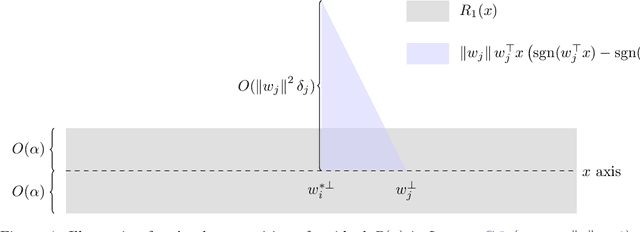
While over-parameterization is widely believed to be crucial for the success of optimization for the neural networks, most existing theories on over-parameterization do not fully explain the reason -- they either work in the Neural Tangent Kernel regime where neurons don't move much, or require an enormous number of neurons. In practice, when the data is generated using a teacher neural network, even mildly over-parameterized neural networks can achieve 0 loss and recover the directions of teacher neurons. In this paper we develop a local convergence theory for mildly over-parameterized two-layer neural net. We show that as long as the loss is already lower than a threshold (polynomial in relevant parameters), all student neurons in an over-parameterized two-layer neural network will converge to one of teacher neurons, and the loss will go to 0. Our result holds for any number of student neurons as long as it is at least as large as the number of teacher neurons, and our convergence rate is independent of the number of student neurons. A key component of our analysis is the new characterization of local optimization landscape -- we show the gradient satisfies a special case of Lojasiewicz property which is different from local strong convexity or PL conditions used in previous work.
Beyond Lazy Training for Over-parameterized Tensor Decomposition
Oct 22, 2020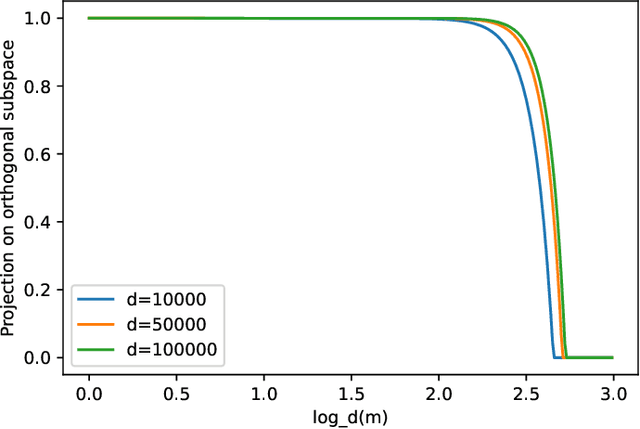
Over-parametrization is an important technique in training neural networks. In both theory and practice, training a larger network allows the optimization algorithm to avoid bad local optimal solutions. In this paper we study a closely related tensor decomposition problem: given an $l$-th order tensor in $(R^d)^{\otimes l}$ of rank $r$ (where $r\ll d$), can variants of gradient descent find a rank $m$ decomposition where $m > r$? We show that in a lazy training regime (similar to the NTK regime for neural networks) one needs at least $m = \Omega(d^{l-1})$, while a variant of gradient descent can find an approximate tensor when $m = O^*(r^{2.5l}\log d)$. Our results show that gradient descent on over-parametrized objective could go beyond the lazy training regime and utilize certain low-rank structure in the data.
Dissecting Hessian: Understanding Common Structure of Hessian in Neural Networks
Oct 08, 2020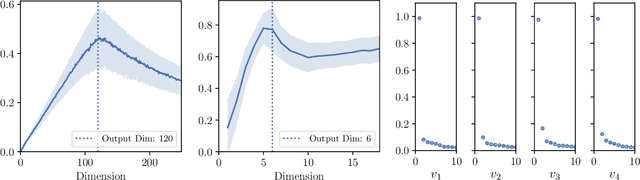
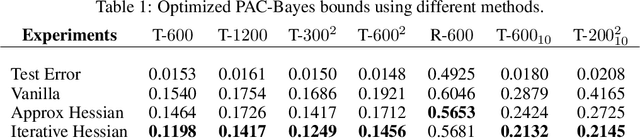
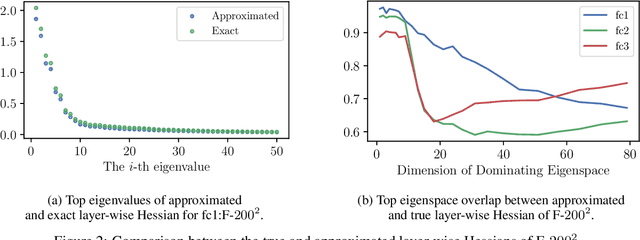
Hessian captures important properties of the deep neural network loss landscape. We observe that eigenvectors and eigenspaces of the layer-wise Hessian for neural network objective have several interesting structures -- top eigenspaces for different models have high overlap, and top eigenvectors form low rank matrices when they are reshaped into the same shape as the corresponding weight matrix. These structures, as well as the low rank structure of the Hessian observed in previous studies, can be explained by approximating the Hessian using Kronecker factorization. Our new understanding can also explain why some of these structures become weaker when the network is trained with batch normalization. Finally, we show that the Kronecker factorization can be combined with PAC-Bayes techniques to get better explicit generalization bounds.