 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning-Augmented Algorithms for $k$-median via Online Learning
Mar 18, 2026The field of learning-augmented algorithms seeks to use ML techniques on past instances of a problem to inform an algorithm designed for a future instance. In this paper, we introduce a novel model for learning-augmented algorithms inspired by online learning. In this model, we are given a sequence of instances of a problem and the goal of the learning-augmented algorithm is to use prior instances to propose a solution to a future instance of the problem. The performance of the algorithm is measured by its average performance across all the instances, where the performance on a single instance is the ratio between the cost of the algorithm's solution and that of an optimal solution for that instance. We apply this framework to the classic $k$-median clustering problem, and give an efficient learning algorithm that can approximately match the average performance of the best fixed $k$-median solution in hindsight across all the instances. We also experimentally evaluate our algorithm and show that its empirical performance is close to optimal, and also that it automatically adapts the solution to a dynamically changing sequence.
A Regression Approach to Learning-Augmented Online Algorithms
May 25, 2022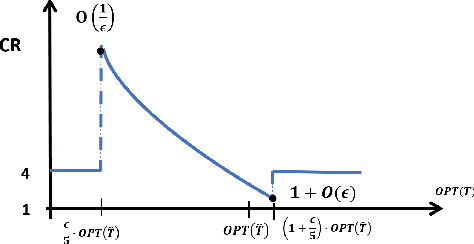
The emerging field of learning-augmented online algorithms uses ML techniques to predict future input parameters and thereby improve the performance of online algorithms. Since these parameters are, in general, real-valued functions, a natural approach is to use regression techniques to make these predictions. We introduce this approach in this paper, and explore it in the context of a general online search framework that captures classic problems like (generalized) ski rental, bin packing, minimum makespan scheduling, etc. We show nearly tight bounds on the sample complexity of this regression problem, and extend our results to the agnostic setting. From a technical standpoint, we show that the key is to incorporate online optimization benchmarks in the design of the loss function for the regression problem, thereby diverging from the use of off-the-shelf regression tools with standard bounds on statistical error.
Customizing ML Predictions for Online Algorithms
May 18, 2022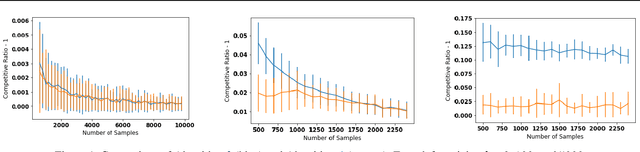
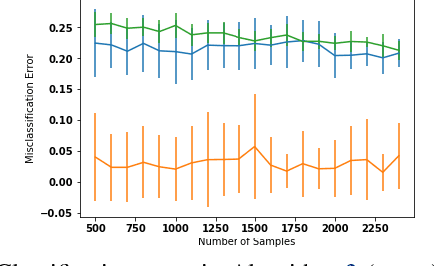
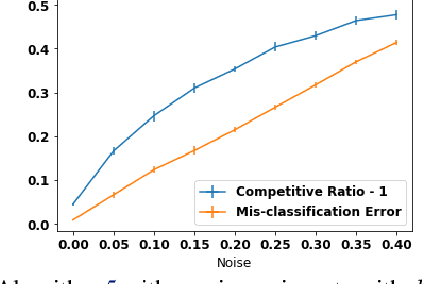
A popular line of recent research incorporates ML advice in the design of online algorithms to improve their performance in typical instances. These papers treat the ML algorithm as a black-box, and redesign online algorithms to take advantage of ML predictions. In this paper, we ask the complementary question: can we redesign ML algorithms to provide better predictions for online algorithms? We explore this question in the context of the classic rent-or-buy problem, and show that incorporating optimization benchmarks in ML loss functions leads to significantly better performance, while maintaining a worst-case adversarial result when the advice is completely wrong. We support this finding both through theoretical bounds and numerical simulations.
Online Algorithms with Multiple Predictions
May 08, 2022This paper studies online algorithms augmented with multiple machine-learned predictions. While online algorithms augmented with a single prediction have been extensively studied in recent years, the literature for the multiple predictions setting is sparse. In this paper, we give a generic algorithmic framework for online covering problems with multiple predictions that obtains an online solution that is competitive against the performance of the best predictor. Our algorithm incorporates the use of predictions in the classic potential-based analysis of online algorithms. We apply our algorithmic framework to solve classical problems such as online set cover, (weighted) caching, and online facility location in the multiple predictions setting. Our algorithm can also be robustified, i.e., the algorithm can be simultaneously made competitive against the best prediction and the performance of the best online algorithm (without prediction).