 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Costs of Reproducibility in Music Separation Research: a Replication of Band-Split RNN
Mar 10, 2026Music source separation is the task of isolating the instrumental tracks from a music song. Despite its spectacular recent progress, the trend towards more complex architectures and training protocols exacerbates reproducibility issues. The band-split recurrent neural networks (BSRNN) model is promising in this regard, since it yields close to state-of-the-art results on public datasets, and requires reasonable resources for training. Unfortunately, it is not straightforward to reproduce since its full code is not available. In this paper, we attempt to replicate BSRNN as closely as possible to the original paper through extensive experiments, which allows us to conduct a critical reflection on this reproducibility issue. Our contributions are three-fold. First, this study yields several insights on the model design and training pipeline, which sheds light on potential future improvements. In particular, since we were unsuccessful in reproducing the original results, we explore additional variants that ultimately yield an optimized BSRNN model, whose performance largely improves that of the original. Second, we discuss reproducibility issues from both methodological and practical perspectives. We notably underline how substantial time and energy costs could have been saved upon availability of the full pipeline. Third, our code and pre-trained models are released publicly to foster reproducible research. We hope that this study will contribute to spread awareness on the importance of reproducible research in the music separation community, and help promoting more transparent and sustainable practices.
Energy Consumption Trends in Sound Event Detection Systems
Sep 13, 2024



Deep learning systems have become increasingly energy- and computation-intensive, raising concerns about their environmental impact. As organizers of the Detection and Classification of Acoustic Scenes and Events (DCASE) challenge, we recognize the importance of addressing this issue. For the past three years, we have integrated energy consumption metrics into the evaluation of sound event detection (SED) systems. In this paper, we analyze the impact of this energy criterion on the challenge results and explore the evolution of system complexity and energy consumption over the years. We highlight a shift towards more energy-efficient approaches during training without compromising performance, while the number of operations and system complexity continue to grow. Through this analysis, we hope to promote more environmentally friendly practices within the SED community.
Normalizing Energy Consumption for Hardware-Independent Evaluation
Sep 09, 2024



The increasing use of machine learning (ML) models in signal processing has raised concerns about their environmental impact, particularly during resource-intensive training phases. In this study, we present a novel methodology for normalizing energy consumption across different hardware platforms to facilitate fair and consistent comparisons. We evaluate different normalization strategies by measuring the energy used to train different ML architectures on different GPUs, focusing on audio tagging tasks. Our approach shows that the number of reference points, the type of regression and the inclusion of computational metrics significantly influences the normalization process. We find that the appropriate selection of two reference points provides robust normalization, while incorporating the number of floating-point operations and parameters improves the accuracy of energy consumption predictions. By supporting more accurate energy consumption evaluation, our methodology promotes the development of environmentally sustainable ML practices.
From Computation to Consumption: Exploring the Compute-Energy Link for Training and Testing Neural Networks for SED Systems
Sep 08, 2024



The massive use of machine learning models, particularly neural networks, has raised serious concerns about their environmental impact. Indeed, over the last few years we have seen an explosion in the computing costs associated with training and deploying these systems. It is, therefore, crucial to understand their energy requirements in order to better integrate them into the evaluation of models, which has so far focused mainly on performance. In this paper, we study several neural network architectures that are key components of sound event detection systems, using an audio tagging task as an example. We measure the energy consumption for training and testing small to large architectures and establish complex relationships between the energy consumption, the number of floating-point operations, the number of parameters, and the GPU/memory utilization.
DCASE 2024 Task 4: Sound Event Detection with Heterogeneous Data and Missing Labels
Jun 12, 2024


The Detection and Classification of Acoustic Scenes and Events Challenge Task 4 aims to advance sound event detection (SED) systems in domestic environments by leveraging training data with different supervision uncertainty. Participants are challenged in exploring how to best use training data from different domains and with varying annotation granularity (strong/weak temporal resolution, soft/hard labels), to obtain a robust SED system that can generalize across different scenarios. Crucially, annotation across available training datasets can be inconsistent and hence sound labels of one dataset may be present but not annotated in the other one and vice-versa. As such, systems will have to cope with potentially missing target labels during training. Moreover, as an additional novelty, systems will also be evaluated on labels with different granularity in order to assess their robustness for different applications. To lower the entry barrier for participants, we developed an updated baseline system with several caveats to address these aforementioned problems. Results with our baseline system indicate that this research direction is promising and is possible to obtain a stronger SED system by using diverse domain training data with missing labels compared to training a SED system for each domain separately.
A Multi-Objective Approach for Sustainable Generative Audio Models
Jul 06, 2021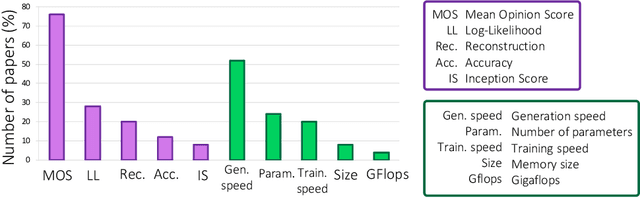


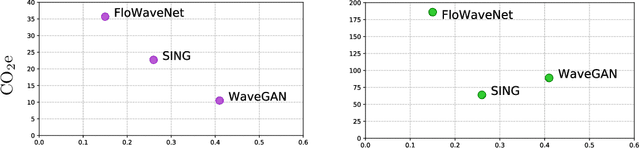
In recent years, the deep learning community has largely focused on the accuracy of deep generative models, resulting in impressive improvements in several research fields. However, this scientific race for quality comes at a tremendous computational cost, which incurs vast energy consumption and greenhouse gas emissions. If the current exponential growth of computational consumption persists, Artificial Intelligence (AI) will sadly become a considerable contributor to global warming. At the heart of this problem are the measures that we use as a scientific community to evaluate our work. Currently, researchers in the field of AI judge scientific works mostly based on the improvement in accuracy, log-likelihood, reconstruction or opinion scores, all of which entirely obliterates the actual computational cost of generative models. In this paper, we introduce the idea of relying on a multi-objective measure based on Pareto optimality, which simultaneously integrates the models accuracy, as well as the environmental impact of their training. By applying this measure on the current state-of-the-art in generative audio models, we show that this measure drastically changes the perceived significance of the results in the field, encouraging optimal training techniques and resource allocation. We hope that this type of measure will be widely adopted, in order to help the community to better evaluate the significance of their work, while bringing computational cost -- and in fine carbon emissions -- in the spotlight of AI research.
Diet deep generative audio models with structured lottery
Jul 31, 2020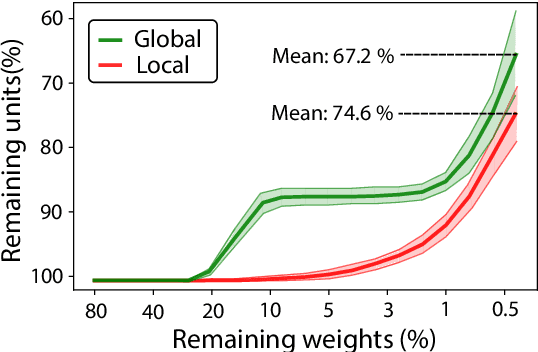
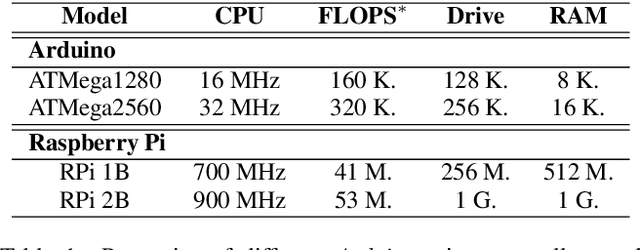
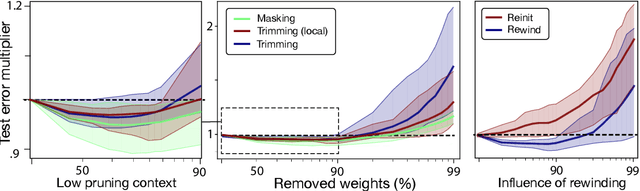
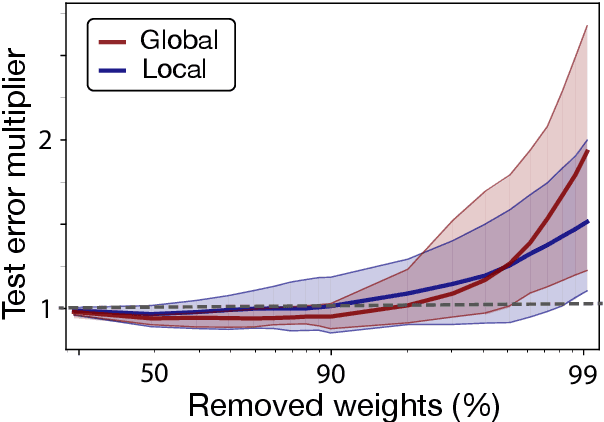
Deep learning models have provided extremely successful solutions in most audio application fields. However, the high accuracy of these models comes at the expense of a tremendous computation cost. This aspect is almost always overlooked in evaluating the quality of proposed models. However, models should not be evaluated without taking into account their complexity. This aspect is especially critical in audio applications, which heavily relies on specialized embedded hardware with real-time constraints. In this paper, we build on recent observations that deep models are highly overparameterized, by studying the lottery ticket hypothesis on deep generative audio models. This hypothesis states that extremely efficient small sub-networks exist in deep models and would provide higher accuracy than larger models if trained in isolation. However, lottery tickets are found by relying on unstructured masking, which means that resulting models do not provide any gain in either disk size or inference time. Instead, we develop here a method aimed at performing structured trimming. We show that this requires to rely on global selection and introduce a specific criterion based on mutual information. First, we confirm the surprising result that smaller models provide higher accuracy than their large counterparts. We further show that we can remove up to 95% of the model weights without significant degradation in accuracy. Hence, we can obtain very light models for generative audio across popular methods such as Wavenet, SING or DDSP, that are up to 100 times smaller with commensurate accuracy. We study the theoretical bounds for embedding these models on Raspberry Pi and Arduino, and show that we can obtain generative models on CPU with equivalent quality as large GPU models. Finally, we discuss the possibility of implementing deep generative audio models on embedded platforms.