 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient minimum word error rate training of RNN-Transducer for end-to-end speech recognition
Jul 27, 2020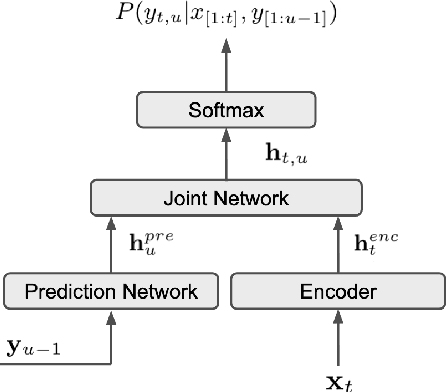
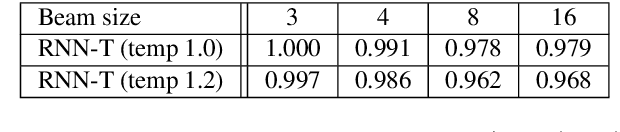
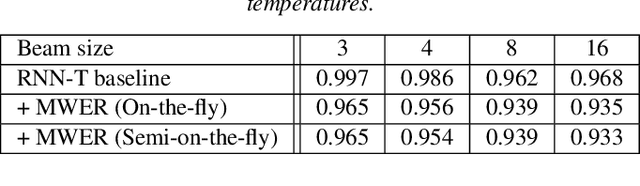
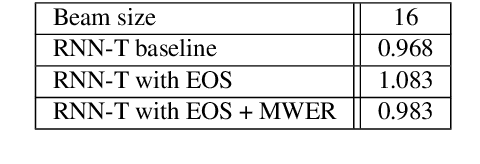
In this work, we propose a novel and efficient minimum word error rate (MWER) training method for RNN-Transducer (RNN-T). Unlike previous work on this topic, which performs on-the-fly limited-size beam-search decoding and generates alignment scores for expected edit-distance computation, in our proposed method, we re-calculate and sum scores of all the possible alignments for each hypothesis in N-best lists. The hypothesis probability scores and back-propagated gradients are calculated efficiently using the forward-backward algorithm. Moreover, the proposed method allows us to decouple the decoding and training processes, and thus we can perform offline parallel-decoding and MWER training for each subset iteratively. Experimental results show that this proposed semi-on-the-fly method can speed up the on-the-fly method by 6 times and result in a similar WER improvement (3.6%) over a baseline RNN-T model. The proposed MWER training can also effectively reduce high-deletion errors (9.2% WER-reduction) introduced by RNN-T models when EOS is added for endpointer. Further improvement can be achieved if we use a proposed RNN-T rescoring method to re-rank hypotheses and use external RNN-LM to perform additional rescoring. The best system achieves a 5% relative improvement on an English test-set of real far-field recordings and a 11.6% WER reduction on music-domain utterances.
Streaming End-to-End Bilingual ASR Systems with Joint Language Identification
Jul 08, 2020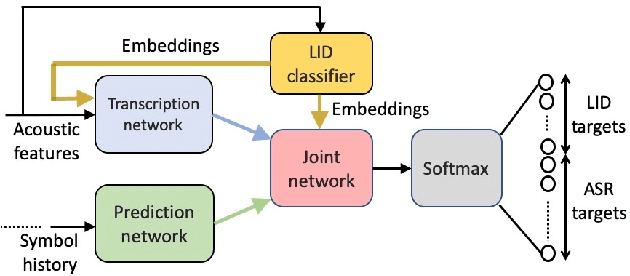
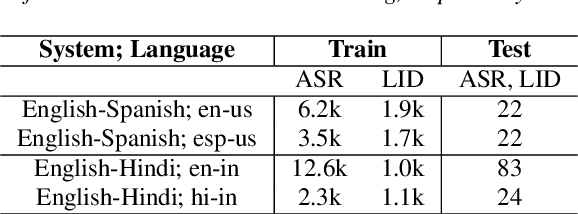
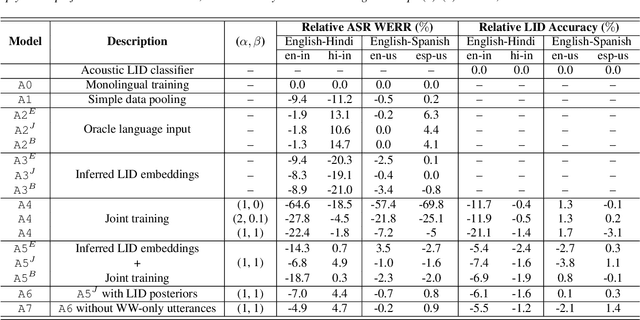
Multilingual ASR technology simplifies model training and deployment, but its accuracy is known to depend on the availability of language information at runtime. Since language identity is seldom known beforehand in real-world scenarios, it must be inferred on-the-fly with minimum latency. Furthermore, in voice-activated smart assistant systems, language identity is also required for downstream processing of ASR output. In this paper, we introduce streaming, end-to-end, bilingual systems that perform both ASR and language identification (LID) using the recurrent neural network transducer (RNN-T) architecture. On the input side, embeddings from pretrained acoustic-only LID classifiers are used to guide RNN-T training and inference, while on the output side, language targets are jointly modeled with ASR targets. The proposed method is applied to two language pairs: English-Spanish as spoken in the United States, and English-Hindi as spoken in India. Experiments show that for English-Spanish, the bilingual joint ASR-LID architecture matches monolingual ASR and acoustic-only LID accuracies. For the more challenging (owing to within-utterance code switching) case of English-Hindi, English ASR and LID metrics show degradation. Overall, in scenarios where users switch dynamically between languages, the proposed architecture offers a promising simplification over running multiple monolingual ASR models and an LID classifier in parallel.
Multi-view Frequency LSTM: An Efficient Frontend for Automatic Speech Recognition
Jun 30, 2020Acoustic models in real-time speech recognition systems typically stack multiple unidirectional LSTM layers to process the acoustic frames over time. Performance improvements over vanilla LSTM architectures have been reported by prepending a stack of frequency-LSTM (FLSTM) layers to the time LSTM. These FLSTM layers can learn a more robust input feature to the time LSTM layers by modeling time-frequency correlations in the acoustic input signals. A drawback of FLSTM based architectures however is that they operate at a predefined, and tuned, window size and stride, referred to as 'view' in this paper. We present a simple and efficient modification by combining the outputs of multiple FLSTM stacks with different views, into a dimensionality reduced feature representation. The proposed multi-view FLSTM architecture allows to model a wider range of time-frequency correlations compared to an FLSTM model with single view. When trained on 50K hours of English far-field speech data with CTC loss followed by sMBR sequence training, we show that the multi-view FLSTM acoustic model provides relative Word Error Rate (WER) improvements of 3-7% for different speaker and acoustic environment scenarios over an optimized single FLSTM model, while retaining a similar computational footprint.
Streaming Language Identification using Combination of Acoustic Representations and ASR Hypotheses
Jun 01, 2020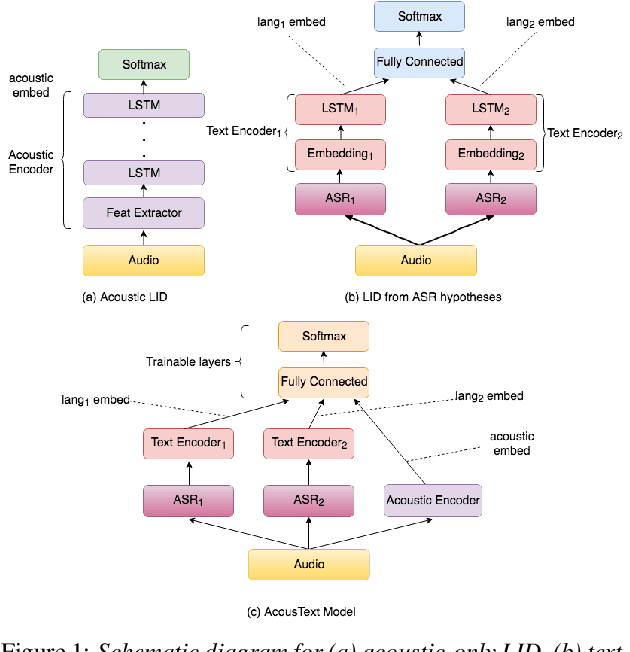
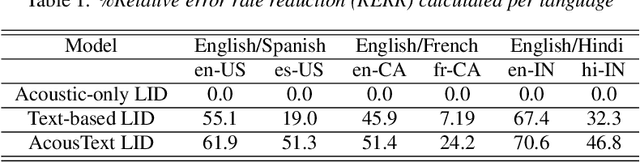
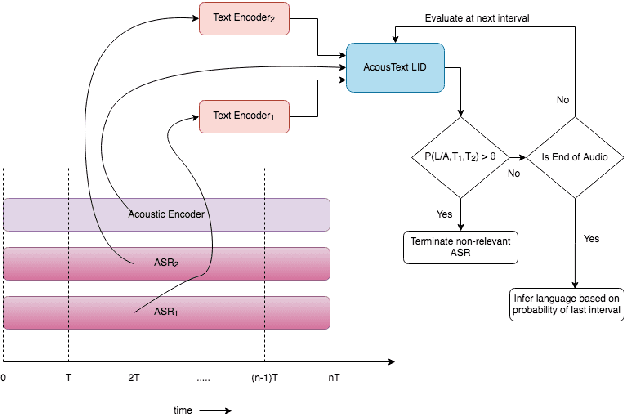

This paper presents our modeling and architecture approaches for building a highly accurate low-latency language identification system to support multilingual spoken queries for voice assistants. A common approach to solve multilingual speech recognition is to run multiple monolingual ASR systems in parallel and rely on a language identification (LID) component that detects the input language. Conventionally, LID relies on acoustic only information to detect input language. We propose an approach that learns and combines acoustic level representations with embeddings estimated on ASR hypotheses resulting in up to 50% relative reduction of identification error rate, compared to a model that uses acoustic only features. Furthermore, to reduce the processing cost and latency, we exploit a streaming architecture to identify the spoken language early when the system reaches a predetermined confidence level, alleviating the need to run multiple ASR systems until the end of input query. The combined acoustic and text LID, coupled with our proposed streaming runtime architecture, results in an average of 1500ms early identification for more than 50% of utterances, with almost no degradation in accuracy. We also show improved results by adopting a semi-supervised learning (SSL) technique using the newly proposed model architecture as a teacher model.
DiPCo -- Dinner Party Corpus
Sep 30, 2019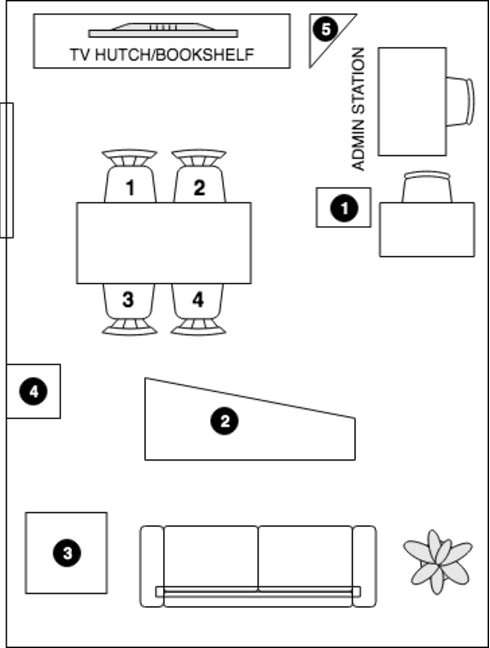
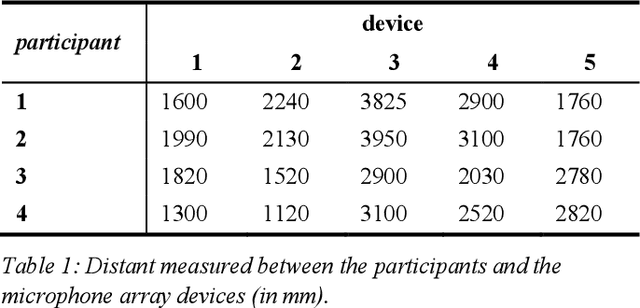
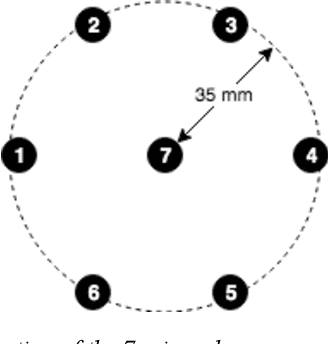

We present a speech data corpus that simulates a "dinner party" scenario taking place in an everyday home environment. The corpus was created by recording multiple groups of four Amazon employee volunteers having a natural conversation in English around a dining table. The participants were recorded by a single-channel close-talk microphone and by five far-field 7-microphone array devices positioned at different locations in the recording room. The dataset contains the audio recordings and human labeled transcripts of a total of 10 sessions with a duration between 15 and 45 minutes. The corpus was created to advance in the field of noise robust and distant speech processing and is intended to serve as a public research and benchmarking data set.
Improving noise robustness of automatic speech recognition via parallel data and teacher-student learning
Jan 11, 2019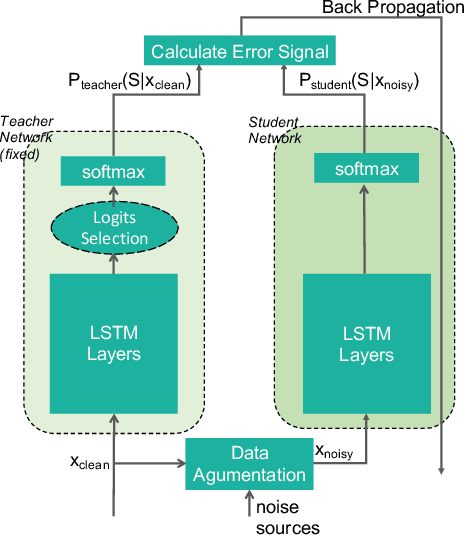
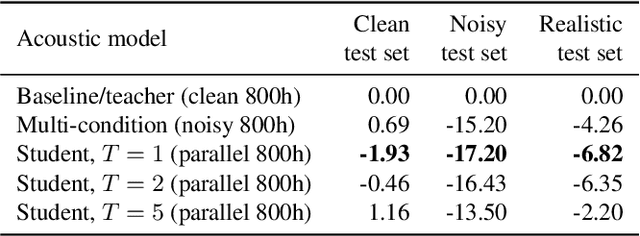
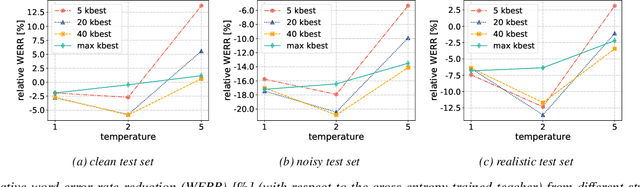
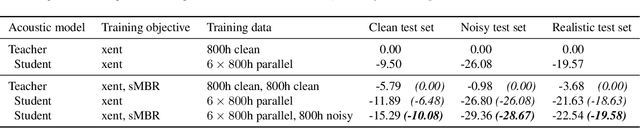
For real-world speech recognition applications, noise robustness is still a challenge. In this work, we adopt the teacher-student (T/S) learning technique using a parallel clean and noisy corpus for improving automatic speech recognition (ASR) performance under multimedia noise. On top of that, we apply a logits selection method which only preserves the k highest values to prevent wrong emphasis of knowledge from the teacher and to reduce bandwidth needed for transferring data. We incorporate up to 8000 hours of untranscribed data for training and present our results on sequence trained models apart from cross entropy trained ones. The best sequence trained student model yields relative word error rate (WER) reductions of approximately 10.1%, 28.7% and 19.6% on our clean, simulated noisy and real test sets respectively comparing to a sequence trained teacher.
LSTM-based Whisper Detection
Sep 20, 2018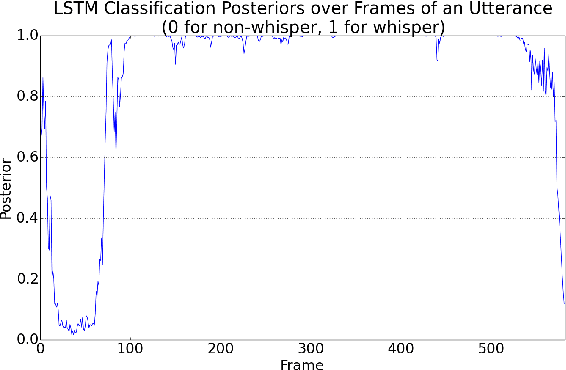

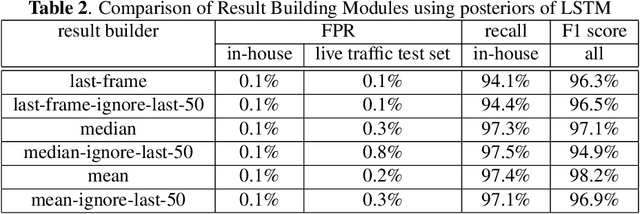
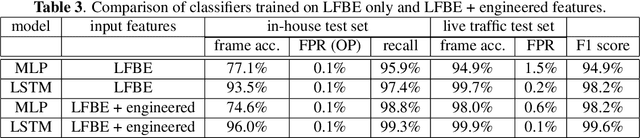
This article presents a whisper speech detector in the far-field domain. The proposed system consists of a long-short term memory (LSTM) neural network trained on log-filterbank energy (LFBE) acoustic features. This model is trained and evaluated on recordings of human interactions with voice-controlled, far-field devices in whisper and normal phonation modes. We compare multiple inference approaches for utterance-level classification by examining trajectories of the LSTM posteriors. In addition, we engineer a set of features based on the signal characteristics inherent to whisper speech, and evaluate their effectiveness in further separating whisper from normal speech. A benchmarking of these features using multilayer perceptrons (MLP) and LSTMs suggests that the proposed features, in combination with LFBE features, can help us further improve our classifiers. We prove that, with enough data, the LSTM model is indeed as capable of learning whisper characteristics from LFBE features alone com- pared to a simpler MLP model that uses both LFBE and features engineered for separating whisper and normal speech. In addition, we prove that the LSTM classifiers accuracy can be further improved with the incorporation of the proposed engineered features.
Device-directed Utterance Detection
Aug 07, 2018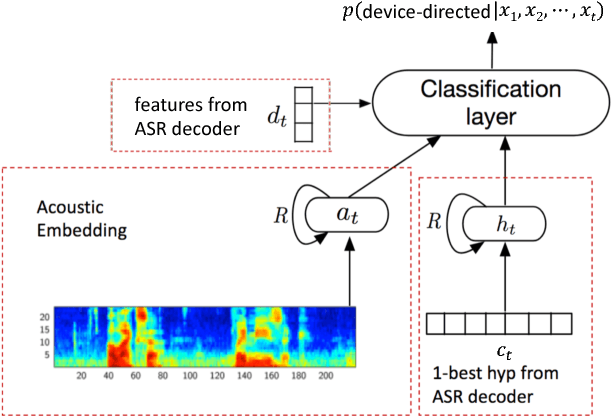
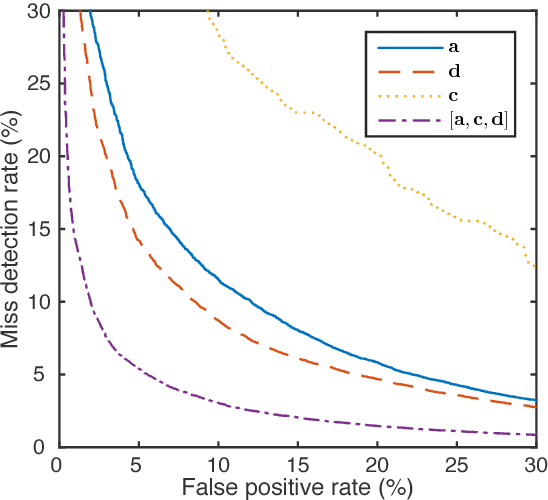
In this work, we propose a classifier for distinguishing device-directed queries from background speech in the context of interactions with voice assistants. Applications include rejection of false wake-ups or unintended interactions as well as enabling wake-word free follow-up queries. Consider the example interaction: $"Computer,~play~music", "Computer,~reduce~the~volume"$. In this interaction, the user needs to repeat the wake-word ($Computer$) for the second query. To allow for more natural interactions, the device could immediately re-enter listening state after the first query (without wake-word repetition) and accept or reject a potential follow-up as device-directed or background speech. The proposed model consists of two long short-term memory (LSTM) neural networks trained on acoustic features and automatic speech recognition (ASR) 1-best hypotheses, respectively. A feed-forward deep neural network (DNN) is then trained to combine the acoustic and 1-best embeddings, derived from the LSTMs, with features from the ASR decoder. Experimental results show that ASR decoder, acoustic embeddings, and 1-best embeddings yield an equal-error-rate (EER) of $9.3~\%$, $10.9~\%$ and $20.1~\%$, respectively. Combination of the features resulted in a $44~\%$ relative improvement and a final EER of $5.2~\%$.
Estimating parameters of nonlinear systems using the elitist particle filter based on evolutionary strategies
May 25, 2016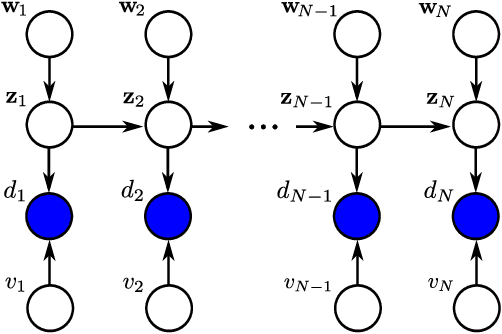
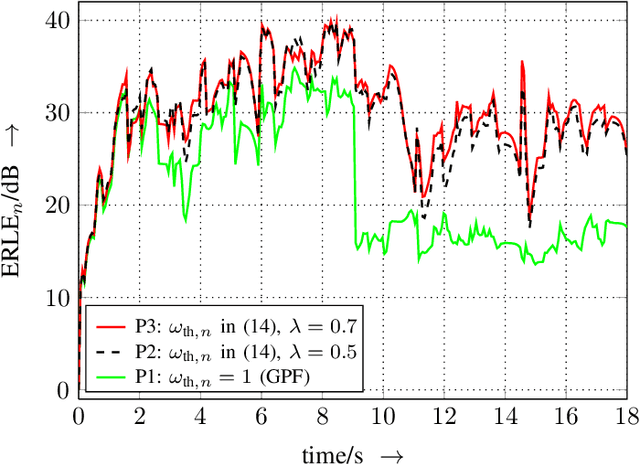
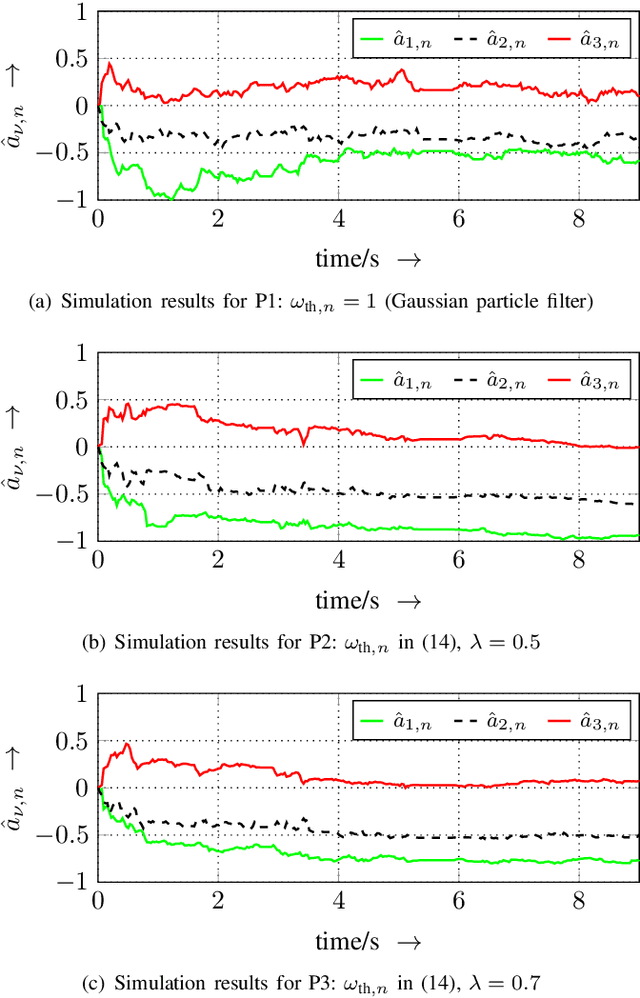
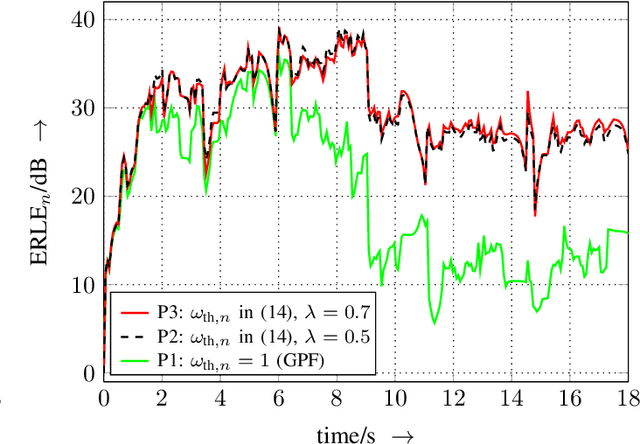
In this article, we present the elitist particle filter based on evolutionary strategies (EPFES) as an efficient approach for nonlinear system identification. The EPFES is derived from the frequently-employed state-space model, where the relevant information of the nonlinear system is captured by an unknown state vector. Similar to classical particle filtering, the EPFES consists of a set of particles and respective weights which represent different realizations of the latent state vector and their likelihood of being the solution of the optimization problem. As main innovation, the EPFES includes an evolutionary elitist-particle selection which combines long-term information with instantaneous sampling from an approximated continuous posterior distribution. In this article, we propose two advancements of the previously-published elitist-particle selection process. Further, the EPFES is shown to be a generalization of the widely-used Gaussian particle filter and thus evaluated with respect to the latter for two completely different scenarios: First, we consider the so-called univariate nonstationary growth model with time-variant latent state variable, where the evolutionary selection of elitist particles is evaluated for non-recursively calculated particle weights. Second, the problem of nonlinear acoustic echo cancellation is addressed in a simulated scenario with speech as input signal: By using long-term fitness measures, we highlight the efficacy of the well-generalizing EPFES in estimating the nonlinear system even for large search spaces. Finally, we illustrate similarities between the EPFES and evolutionary algorithms to outline future improvements by fusing the achievements of both fields of research.
Spatial Diffuseness Features for DNN-Based Speech Recognition in Noisy and Reverberant Environments
Feb 16, 2015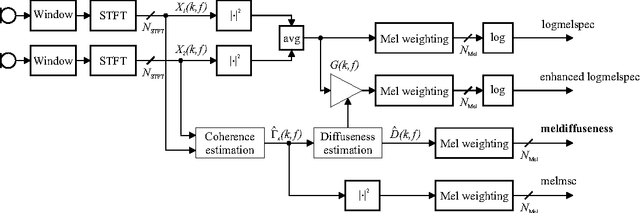

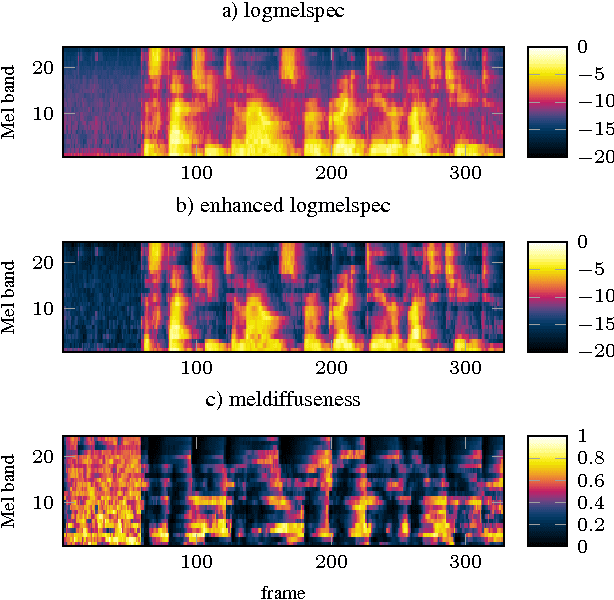
We propose a spatial diffuseness feature for deep neural network (DNN)-based automatic speech recognition to improve recognition accuracy in reverberant and noisy environments. The feature is computed in real-time from multiple microphone signals without requiring knowledge or estimation of the direction of arrival, and represents the relative amount of diffuse noise in each time and frequency bin. It is shown that using the diffuseness feature as an additional input to a DNN-based acoustic model leads to a reduced word error rate for the REVERB challenge corpus, both compared to logmelspec features extracted from noisy signals, and features enhanced by spectral subtraction.