 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Voronoi Cell Formulation for Principled Token Pruning in Late-Interaction Retrieval Models
Mar 11, 2026Late-interaction models like ColBERT offer a competitive performance across various retrieval tasks, but require storing a dense embedding for each document token, leading to a substantial index storage overhead. Past works address this by attempting to prune low-importance token embeddings based on statistical and empirical measures, but they often either lack formal grounding or are ineffective. To address these shortcomings, we introduce a framework grounded in hyperspace geometry and cast token pruning as a Voronoi cell estimation problem in the embedding space. By interpreting each token's influence as a measure of its Voronoi region, our approach enables principled pruning that retains retrieval quality while reducing index size. Through our experiments, we demonstrate that this approach serves not only as a competitive pruning strategy but also as a valuable tool for improving and interpreting token-level behavior within dense retrieval systems.
Confabulations from ACL Publications (CAP): A Dataset for Scientific Hallucination Detection
Oct 25, 2025


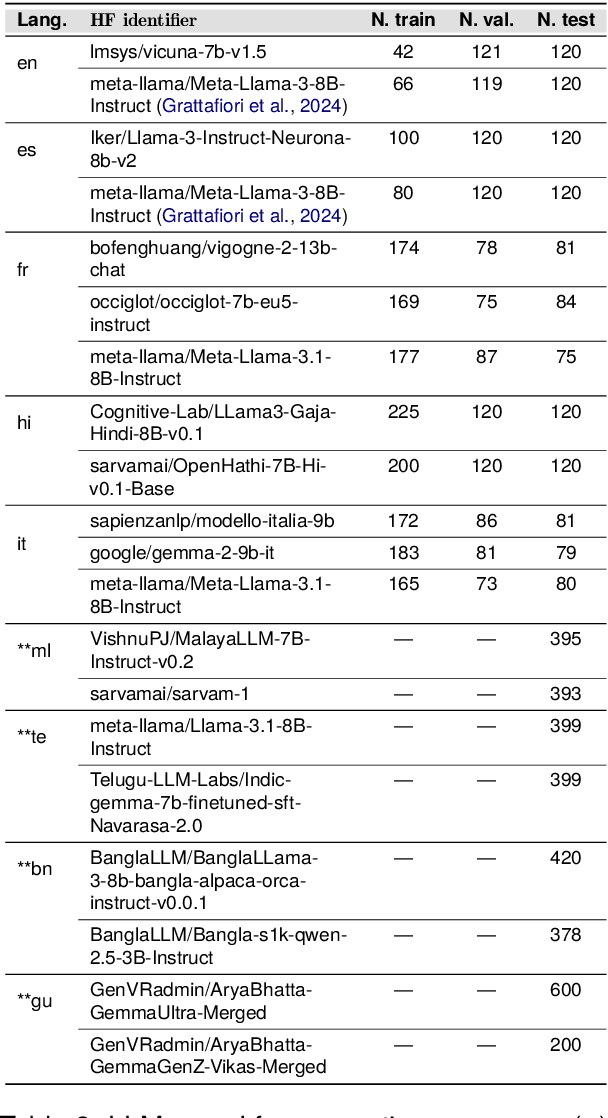
We introduce the CAP (Confabulations from ACL Publications) dataset, a multilingual resource for studying hallucinations in large language models (LLMs) within scientific text generation. CAP focuses on the scientific domain, where hallucinations can distort factual knowledge, as they frequently do. In this domain, however, the presence of specialized terminology, statistical reasoning, and context-dependent interpretations further exacerbates these distortions, particularly given LLMs' lack of true comprehension, limited contextual understanding, and bias toward surface-level generalization. CAP operates in a cross-lingual setting covering five high-resource languages (English, French, Hindi, Italian, and Spanish) and four low-resource languages (Bengali, Gujarati, Malayalam, and Telugu). The dataset comprises 900 curated scientific questions and over 7000 LLM-generated answers from 16 publicly available models, provided as question-answer pairs along with token sequences and corresponding logits. Each instance is annotated with a binary label indicating the presence of a scientific hallucination, denoted as a factuality error, and a fluency label, capturing issues in the linguistic quality or naturalness of the text. CAP is publicly released to facilitate advanced research on hallucination detection, multilingual evaluation of LLMs, and the development of more reliable scientific NLP systems.
Remember what you did so you know what to do next
Oct 30, 2023



We explore using a moderately sized large language model (GPT-J 6B parameters) to create a plan for a simulated robot to achieve 30 classes of goals in ScienceWorld, a text game simulator for elementary science experiments. Previously published empirical work claimed that large language models (LLMs) are a poor fit (Wang et al., 2022) compared to reinforcement learning. Using the Markov assumption (a single previous step), the LLM outperforms the reinforcement learning-based approach by a factor of 1.4. When we fill the LLM's input buffer with as many prior steps as possible, improvement rises to 3.5x. Even when training on only 6.5% of the training data, we observe a 2.2x improvement over the reinforcement-learning-based approach. Our experiments show that performance varies widely across the 30 classes of actions, indicating that averaging over tasks can hide significant performance issues. In work contemporaneous with ours, Lin et al. (2023) demonstrated a two-part approach (SwiftSage) that uses a small LLM (T5-large) complemented by OpenAI's massive LLMs to achieve outstanding results in ScienceWorld. Our 6-B parameter, single-stage GPT-J matches the performance of SwiftSage's two-stage architecture when it incorporates GPT-3.5 turbo which has 29-times more parameters than GPT-J.
Machine-Assisted Script Curation
Jan 14, 2021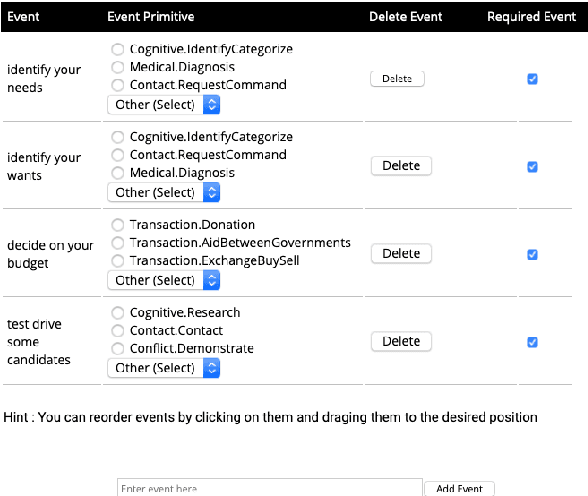
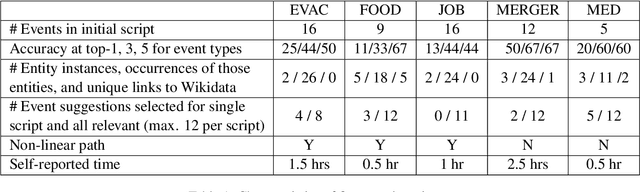
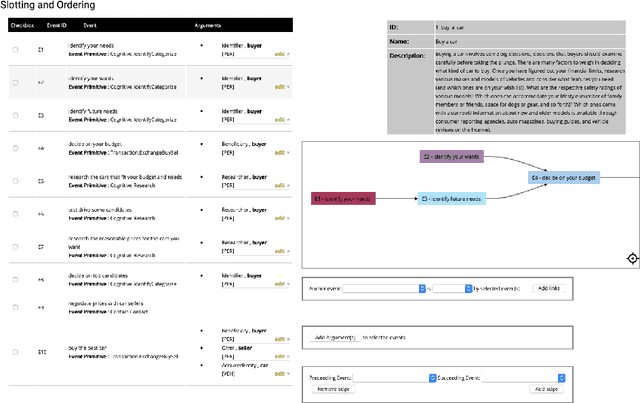
We describe Machine-Aided Script Curator (MASC), a system for human-machine collaborative script authoring. Scripts produced with MASC include (1) English descriptions of sub-events that comprise a larger, complex event; (2) event types for each of those events; (3) a record of entities expected to participate in multiple sub-events; and (4) temporal sequencing between the sub-events. MASC automates portions of the script creation process with suggestions for event types, links to Wikidata, and sub-events that may have been forgotten. We illustrate how these automations are useful to the script writer with a few case-study scripts.