 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLife Cycle-Aware Evaluation of Knowledge Distillation for Machine Translation: Environmental Impact and Translation Quality Trade-offs
Feb 10, 2026Knowledge distillation (KD) is a tool to compress a larger system (teacher) into a smaller one (student). In machine translation, studies typically report only the translation quality of the student and omit the computational complexity of performing KD, making it difficult to select among the many available KD choices under compute-induced constraints. In this study, we evaluate representative KD methods by considering both translation quality and computational cost. We express computational cost as a carbon footprint using the machine learning life cycle assessment (MLCA) tool. This assessment accounts for runtime operational emissions and amortized hardware production costs throughout the KD model life cycle (teacher training, distillation, and inference). We find that (i) distillation overhead dominates the total footprint at small deployment volumes, (ii) inference dominates at scale, making KD beneficial only beyond a task-dependent usage threshold, and (iii) word-level distillation typically offers more favorable footprint-quality trade-offs than sequence-level distillation. Our protocol provides reproducible guidance for selecting KD methods under explicit quality and compute-induced constraints.
Unravelling the Mechanisms of Manipulating Numbers in Language Models
Oct 30, 2025



Recent work has shown that different large language models (LLMs) converge to similar and accurate input embedding representations for numbers. These findings conflict with the documented propensity of LLMs to produce erroneous outputs when dealing with numeric information. In this work, we aim to explain this conflict by exploring how language models manipulate numbers and quantify the lower bounds of accuracy of these mechanisms. We find that despite surfacing errors, different language models learn interchangeable representations of numbers that are systematic, highly accurate and universal across their hidden states and the types of input contexts. This allows us to create universal probes for each LLM and to trace information -- including the causes of output errors -- to specific layers. Our results lay a fundamental understanding of how pre-trained LLMs manipulate numbers and outline the potential of more accurate probing techniques in addressed refinements of LLMs' architectures.
Confabulations from ACL Publications (CAP): A Dataset for Scientific Hallucination Detection
Oct 25, 2025


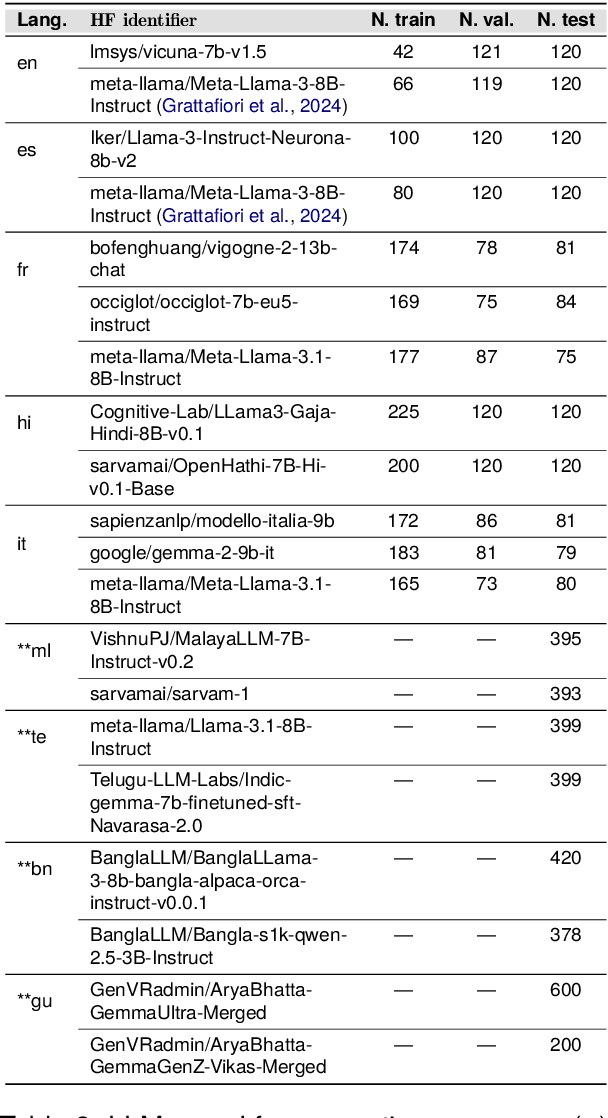
We introduce the CAP (Confabulations from ACL Publications) dataset, a multilingual resource for studying hallucinations in large language models (LLMs) within scientific text generation. CAP focuses on the scientific domain, where hallucinations can distort factual knowledge, as they frequently do. In this domain, however, the presence of specialized terminology, statistical reasoning, and context-dependent interpretations further exacerbates these distortions, particularly given LLMs' lack of true comprehension, limited contextual understanding, and bias toward surface-level generalization. CAP operates in a cross-lingual setting covering five high-resource languages (English, French, Hindi, Italian, and Spanish) and four low-resource languages (Bengali, Gujarati, Malayalam, and Telugu). The dataset comprises 900 curated scientific questions and over 7000 LLM-generated answers from 16 publicly available models, provided as question-answer pairs along with token sequences and corresponding logits. Each instance is annotated with a binary label indicating the presence of a scientific hallucination, denoted as a factuality error, and a fluency label, capturing issues in the linguistic quality or naturalness of the text. CAP is publicly released to facilitate advanced research on hallucination detection, multilingual evaluation of LLMs, and the development of more reliable scientific NLP systems.
Pre-trained Language Models Learn Remarkably Accurate Representations of Numbers
Jun 10, 2025



Pretrained language models (LMs) are prone to arithmetic errors. Existing work showed limited success in probing numeric values from models' representations, indicating that these errors can be attributed to the inherent unreliability of distributionally learned embeddings in representing exact quantities. However, we observe that previous probing methods are inadequate for the emergent structure of learned number embeddings with sinusoidal patterns. In response, we propose a novel probing technique that decodes numeric values from input embeddings with near-perfect accuracy across a range of open-source LMs. This proves that after the sole pre-training, LMs represent numbers with remarkable precision. Finally, we find that the embeddings' preciseness judged by our probe's accuracy explains a large portion of LM's errors in elementary arithmetic, and show that aligning the embeddings with the pattern discovered by our probe can mitigate these errors.
SemEval-2025 Task 3: Mu-SHROOM, the Multilingual Shared Task on Hallucinations and Related Observable Overgeneration Mistakes
Apr 16, 2025We present the Mu-SHROOM shared task which is focused on detecting hallucinations and other overgeneration mistakes in the output of instruction-tuned large language models (LLMs). Mu-SHROOM addresses general-purpose LLMs in 14 languages, and frames the hallucination detection problem as a span-labeling task. We received 2,618 submissions from 43 participating teams employing diverse methodologies. The large number of submissions underscores the interest of the community in hallucination detection. We present the results of the participating systems and conduct an empirical analysis to identify key factors contributing to strong performance in this task. We also emphasize relevant current challenges, notably the varying degree of hallucinations across languages and the high annotator disagreement when labeling hallucination spans.
Your Model is Overconfident, and Other Lies We Tell Ourselves
Mar 03, 2025The difficulty intrinsic to a given example, rooted in its inherent ambiguity, is a key yet often overlooked factor in evaluating neural NLP models. We investigate the interplay and divergence among various metrics for assessing intrinsic difficulty, including annotator dissensus, training dynamics, and model confidence. Through a comprehensive analysis using 29 models on three datasets, we reveal that while correlations exist among these metrics, their relationships are neither linear nor monotonic. By disentangling these dimensions of uncertainty, we aim to refine our understanding of data complexity and its implications for evaluating and improving NLP models.
Two Stacks Are Better Than One: A Comparison of Language Modeling and Translation as Multilingual Pretraining Objectives
Jul 22, 2024



Pretrained language models (PLMs) display impressive performances and have captured the attention of the NLP community. Establishing the best practices in pretraining has therefore become a major point of focus for much of NLP research -- especially since the insights developed for monolingual English models need not carry to more complex multilingual. One significant caveat of the current state of the art is that different works are rarely comparable: they often discuss different parameter counts, training data, and evaluation methodology. This paper proposes a comparison of multilingual pretraining objectives in a controlled methodological environment. We ensure that training data and model architectures are comparable, and discuss the downstream performances across 6 languages that we observe in probing and fine-tuning scenarios. We make two key observations: (1) the architecture dictates which pretraining objective is optimal; (2) multilingual translation is a very effective pre-training objective under the right conditions. We make our code, data, and model weights available at \texttt{\url{https://github.com/Helsinki-NLP/lm-vs-mt}}.
Domain-specific or Uncertainty-aware models: Does it really make a difference for biomedical text classification?
Jul 17, 2024



The success of pretrained language models (PLMs) across a spate of use-cases has led to significant investment from the NLP community towards building domain-specific foundational models. On the other hand, in mission critical settings such as biomedical applications, other aspects also factor in-chief of which is a model's ability to produce reasonable estimates of its own uncertainty. In the present study, we discuss these two desiderata through the lens of how they shape the entropy of a model's output probability distribution. We find that domain specificity and uncertainty awareness can often be successfully combined, but the exact task at hand weighs in much more strongly.
AXOLOTL'24 Shared Task on Multilingual Explainable Semantic Change Modeling
Jul 04, 2024



This paper describes the organization and findings of AXOLOTL'24, the first multilingual explainable semantic change modeling shared task. We present new sense-annotated diachronic semantic change datasets for Finnish and Russian which were employed in the shared task, along with a surprise test-only German dataset borrowed from an existing source. The setup of AXOLOTL'24 is new to the semantic change modeling field, and involves subtasks of identifying unknown (novel) senses and providing dictionary-like definitions to these senses. The methods of the winning teams are described and compared, thus paving a path towards explainability in computational approaches to historical change of meaning.
I Have an Attention Bridge to Sell You: Generalization Capabilities of Modular Translation Architectures
Apr 30, 2024



Modularity is a paradigm of machine translation with the potential of bringing forth models that are large at training time and small during inference. Within this field of study, modular approaches, and in particular attention bridges, have been argued to improve the generalization capabilities of models by fostering language-independent representations. In the present paper, we study whether modularity affects translation quality; as well as how well modular architectures generalize across different evaluation scenarios. For a given computational budget, we find non-modular architectures to be always comparable or preferable to all modular designs we study.