 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Detection of COVID-19 from Chest X-ray Images Using Deep Learning Model
Aug 27, 2024The infectious disease caused by novel corona virus (2019-nCoV) has been widely spreading since last year and has shaken the entire world. It has caused an unprecedented effect on daily life, global economy and public health. Hence this disease detection has life-saving importance for both patients as well as doctors. Due to limited test kits, it is also a daunting task to test every patient with severe respiratory problems using conventional techniques (RT-PCR). Thus implementing an automatic diagnosis system is urgently required to overcome the scarcity problem of Covid-19 test kits at hospital, health care systems. The diagnostic approach is mainly classified into two categories-laboratory based and Chest radiography approach. In this paper, a novel approach for computerized corona virus (2019-nCoV) detection from lung x-ray images is presented. Here, we propose models using deep learning to show the effectiveness of diagnostic systems. In the experimental result, we evaluate proposed models on publicly available data-set which exhibit satisfactory performance and promising results compared with other previous existing methods.
Learning Non-myopic Power Allocation in Constrained Scenarios
Jan 18, 2024

We propose a learning-based framework for efficient power allocation in ad hoc interference networks under episodic constraints. The problem of optimal power allocation -- for maximizing a given network utility metric -- under instantaneous constraints has recently gained significant popularity. Several learnable algorithms have been proposed to obtain fast, effective, and near-optimal performance. However, a more realistic scenario arises when the utility metric has to be optimized for an entire episode under time-coupled constraints. In this case, the instantaneous power needs to be regulated so that the given utility can be optimized over an entire sequence of wireless network realizations while satisfying the constraint at all times. Solving each instance independently will be myopic as the long-term constraint cannot modulate such a solution. Instead, we frame this as a constrained and sequential decision-making problem, and employ an actor-critic algorithm to obtain the constraint-aware power allocation at each step. We present experimental analyses to illustrate the effectiveness of our method in terms of superior episodic network-utility performance and its efficiency in terms of time and computational complexity.
Deep Graph Unfolding for Beamforming in MU-MIMO Interference Networks
Apr 02, 2023



We develop an efficient and near-optimal solution for beamforming in multi-user multiple-input-multiple-output single-hop wireless ad-hoc interference networks. Inspired by the weighted minimum mean squared error (WMMSE) method, a classical approach to solving this problem, and the principle of algorithm unfolding, we present unfolded WMMSE (UWMMSE) for MU-MIMO. This method learns a parameterized functional transformation of key WMMSE parameters using graph neural networks (GNNs), where the channel and interference components of a wireless network constitute the underlying graph. These GNNs are trained through gradient descent on a network utility metric using multiple instances of the beamforming problem. Comprehensive experimental analyses illustrate the superiority of UWMMSE over the classical WMMSE and state-of-the-art learning-based methods in terms of performance, generalizability, and robustness.
Stability Analysis of Unfolded WMMSE for Power Allocation
Oct 14, 2021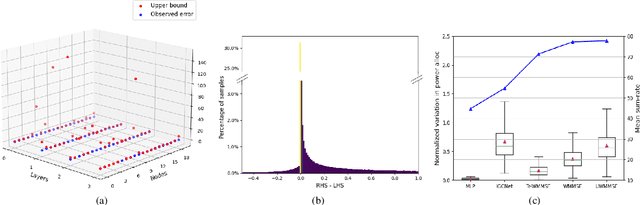
Power allocation is one of the fundamental problems in wireless networks and a wide variety of algorithms address this problem from different perspectives. A common element among these algorithms is that they rely on an estimation of the channel state, which may be inaccurate on account of hardware defects, noisy feedback systems, and environmental and adversarial disturbances. Therefore, it is essential that the output power allocation of these algorithms is stable with respect to input perturbations, to the extent that the variations in the output are bounded for bounded variations in the input. In this paper, we focus on UWMMSE -- a modern algorithm leveraging graph neural networks --, and illustrate its stability to additive input perturbations of bounded energy through both theoretical analysis and empirical validation.
Label Propagation across Graphs: Node Classification using Graph Neural Tangent Kernels
Oct 07, 2021
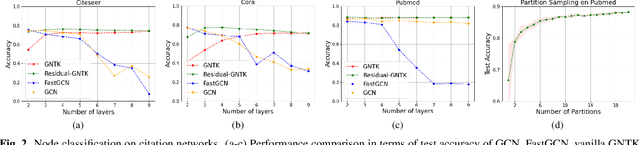
Graph neural networks (GNNs) have achieved superior performance on node classification tasks in the last few years. Commonly, this is framed in a transductive semi-supervised learning setup wherein the entire graph, including the target nodes to be labeled, is available for training. Driven in part by scalability, recent works have focused on the inductive case where only the labeled portion of a graph is available for training. In this context, our current work considers a challenging inductive setting where a set of labeled graphs are available for training while the unlabeled target graph is completely separate, i.e., there are no connections between labeled and unlabeled nodes. Under the implicit assumption that the testing and training graphs come from similar distributions, our goal is to develop a labeling function that generalizes to unobserved connectivity structures. To that end, we employ a graph neural tangent kernel (GNTK) that corresponds to infinitely wide GNNs to find correspondences between nodes in different graphs based on both the topology and the node features. We augment the capabilities of the GNTK with residual connections and empirically illustrate its performance gains on standard benchmarks.
ML-aided power allocation for Tactical MIMO
Sep 14, 2021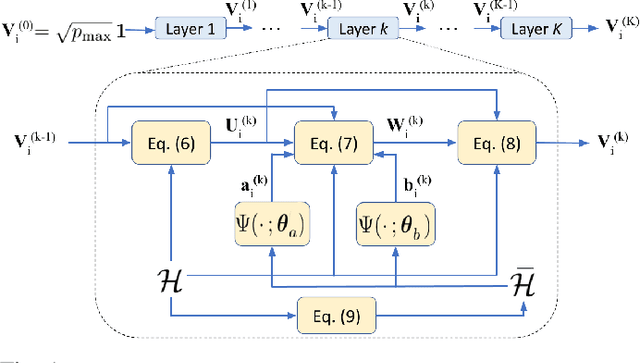
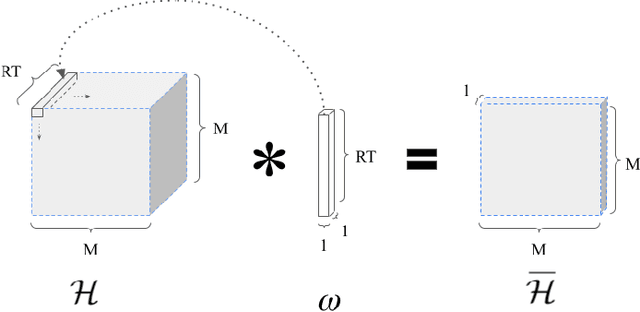
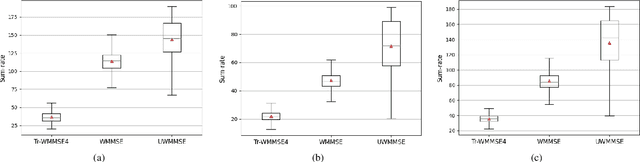
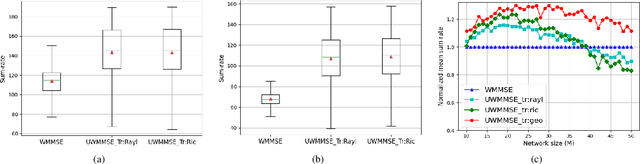
We study the problem of optimal power allocation in single-hop multi-antenna ad-hoc wireless networks. A standard technique to solve this problem involves optimizing a tri-convex function under power constraints using a block-coordinate-descent (BCD) based iterative algorithm. This approach, termed WMMSE, tends to be computationally complex and time consuming. Several learning-based approaches have been proposed to speed up the power allocation process. A recent work, UWMMSE, learns an affine transformation of a WMMSE parameter in an unfolded structure to accelerate convergence. In spite of achieving promising results, its application is limited to single-antenna wireless networks. In this work, we present a UWMMSE framework for power allocation in (multiple-input multiple-output) MIMO interference networks. Through an empirical study, we illustrate the superiority of our approach in comparison to WMMSE and also analyze its robustness to changes in channel conditions and network size.
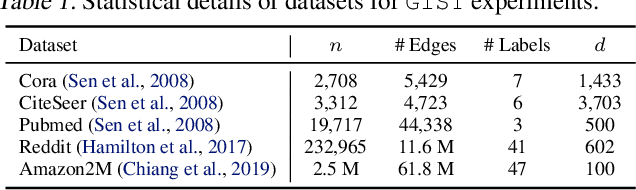
GIST: Distributed Training for Large-Scale Graph Convolutional Networks
Feb 20, 2021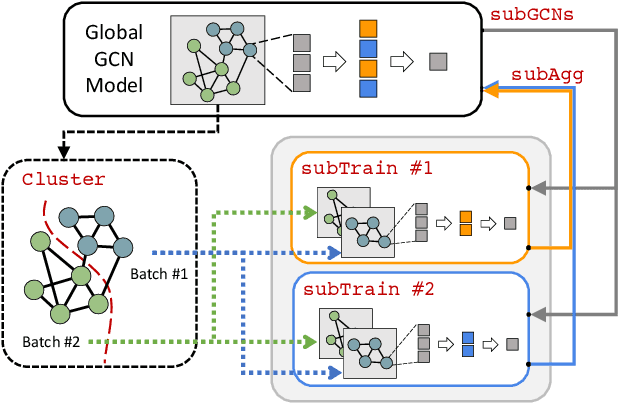
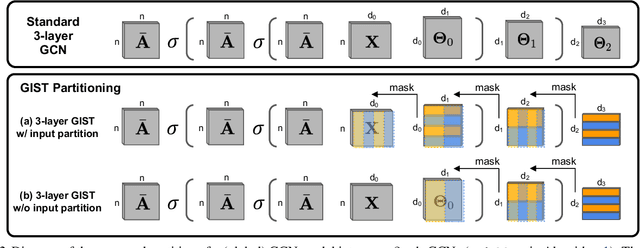
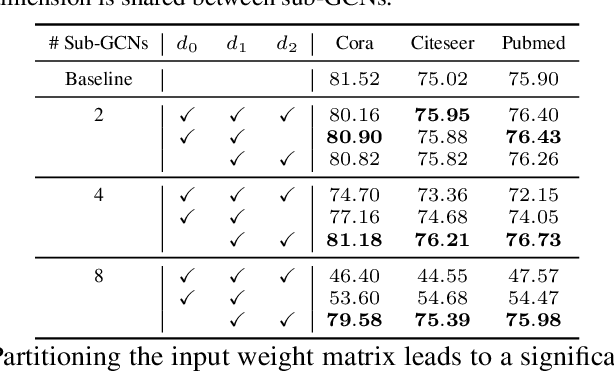
The graph convolutional network (GCN) is a go-to solution for machine learning on graphs, but its training is notoriously difficult to scale in terms of both the size of the graph and the number of model parameters. These limitations are in stark contrast to the increasing scale (in data size and model size) of experiments in deep learning research. In this work, we propose GIST, a novel distributed approach that enables efficient training of wide (overparameterized) GCNs on large graphs. GIST is a hybrid layer and graph sampling method, which disjointly partitions the global model into several, smaller sub-GCNs that are independently trained across multiple GPUs in parallel. This distributed framework improves model performance and significantly decreases wall-clock training time. GIST seeks to enable large-scale GCN experimentation with the goal of bridging the existing gap in scale between graph machine learning and deep learning.
Efficient power allocation using graph neural networks and deep algorithm unfolding
Nov 18, 2020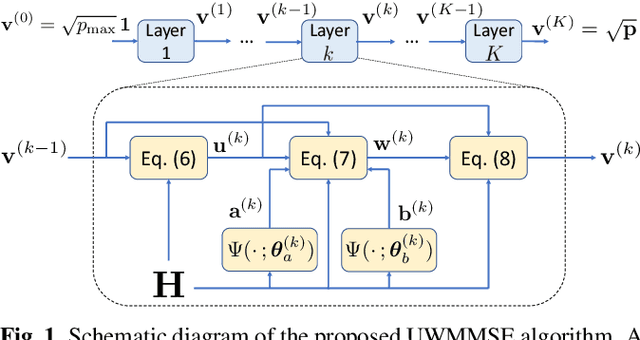
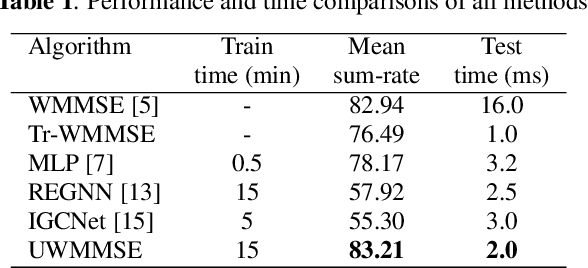
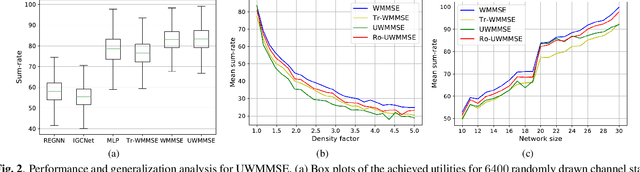
We study the problem of optimal power allocation in a single-hop ad hoc wireless network. In solving this problem, we propose a hybrid neural architecture inspired by the algorithmic unfolding of the iterative weighted minimum mean squared error (WMMSE) method, that we denote as unfolded WMMSE (UWMMSE). The learnable weights within UWMMSE are parameterized using graph neural networks (GNNs), where the time-varying underlying graphs are given by the fading interference coefficients in the wireless network. These GNNs are trained through a gradient descent approach based on multiple instances of the power allocation problem. Once trained, UWMMSE achieves performance comparable to that of WMMSE while significantly reducing the computational complexity. This phenomenon is illustrated through numerical experiments along with the robustness and generalization to wireless networks of different densities and sizes.
ChartNet: Visual Reasoning over Statistical Charts using MAC-Networks
Nov 21, 2019



Despite the improvements in perception accuracies brought about via deep learning, developing systems combining accurate visual perception with the ability to reason over the visual percepts remains extremely challenging. A particular application area of interest from an accessibility perspective is that of reasoning over statistical charts such as bar and pie charts. To this end, we formulate the problem of reasoning over statistical charts as a classification task using MAC-Networks to give answers from a predefined vocabulary of generic answers. Additionally, we enhance the capabilities of MAC-Networks to give chart-specific answers to open-ended questions by replacing the classification layer by a regression layer to localize the textual answers present over the images. We call our network ChartNet, and demonstrate its efficacy on predicting both in vocabulary and out of vocabulary answers. To test our methods, we generated our own dataset of statistical chart images and corresponding question answer pairs. Results show that ChartNet consistently outperform other state-of-the-art methods on reasoning over these questions and may be a viable candidate for applications containing images of statistical charts.
Deep Reader: Information extraction from Document images via relation extraction and Natural Language
Dec 14, 2018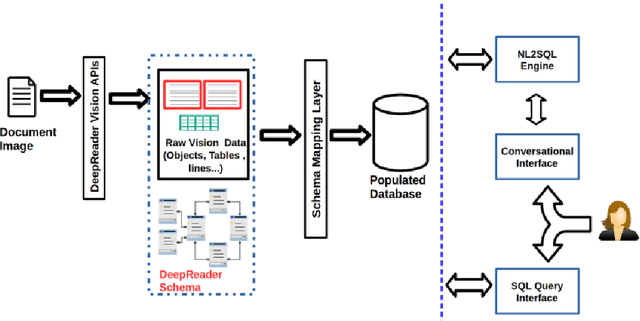

Recent advancements in the area of Computer Vision with state-of-art Neural Networks has given a boost to Optical Character Recognition (OCR) accuracies. However, extracting characters/text alone is often insufficient for relevant information extraction as documents also have a visual structure that is not captured by OCR. Extracting information from tables, charts, footnotes, boxes, headings and retrieving the corresponding structured representation for the document remains a challenge and finds application in a large number of real-world use cases. In this paper, we propose a novel enterprise based end-to-end framework called DeepReader which facilitates information extraction from document images via identification of visual entities and populating a meta relational model across different entities in the document image. The model schema allows for an easy to understand abstraction of the entities detected by the deep vision models and the relationships between them. DeepReader has a suite of state-of-the-art vision algorithms which are applied to recognize handwritten and printed text, eliminate noisy effects, identify the type of documents and detect visual entities like tables, lines and boxes. Deep Reader maps the extracted entities into a rich relational schema so as to capture all the relevant relationships between entities (words, textboxes, lines etc) detected in the document. Relevant information and fields can then be extracted from the document by writing SQL queries on top of the relationship tables. A natural language based interface is added on top of the relationship schema so that a non-technical user, specifying the queries in natural language, can fetch the information with minimal effort. In this paper, we also demonstrate many different capabilities of Deep Reader and report results on a real-world use case.