 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Few-Shot Continual Learning with Contrastive Mixture of Adapters
Feb 12, 2023The goal of Few-Shot Continual Learning (FSCL) is to incrementally learn novel tasks with limited labeled samples and preserve previous capabilities simultaneously, while current FSCL methods are all for the class-incremental purpose. Moreover, the evaluation of FSCL solutions is only the cumulative performance of all encountered tasks, but there is no work on exploring the domain generalization ability. Domain generalization is a challenging yet practical task that aims to generalize beyond training domains. In this paper, we set up a Generalized FSCL (GFSCL) protocol involving both class- and domain-incremental situations together with the domain generalization assessment. Firstly, two benchmark datasets and protocols are newly arranged, and detailed baselines are provided for this unexplored configuration. We find that common continual learning methods have poor generalization ability on unseen domains and cannot better cope with the catastrophic forgetting issue in cross-incremental tasks. In this way, we further propose a rehearsal-free framework based on Vision Transformer (ViT) named Contrastive Mixture of Adapters (CMoA). Due to different optimization targets of class increment and domain increment, the CMoA contains two parts: (1) For the class-incremental issue, the Mixture of Adapters (MoA) module is incorporated into ViT, then cosine similarity regularization and the dynamic weighting are designed to make each adapter learn specific knowledge and concentrate on particular classes. (2) For the domain-related issues and domain-invariant representation learning, we alleviate the inner-class variation by prototype-calibrated contrastive learning. The codes and protocols are available at https://github.com/yawencui/CMoA.
Rethinking Vision Transformer and Masked Autoencoder in Multimodal Face Anti-Spoofing
Feb 11, 2023Recently, vision transformer (ViT) based multimodal learning methods have been proposed to improve the robustness of face anti-spoofing (FAS) systems. However, there are still no works to explore the fundamental natures (\textit{e.g.}, modality-aware inputs, suitable multimodal pre-training, and efficient finetuning) in vanilla ViT for multimodal FAS. In this paper, we investigate three key factors (i.e., inputs, pre-training, and finetuning) in ViT for multimodal FAS with RGB, Infrared (IR), and Depth. First, in terms of the ViT inputs, we find that leveraging local feature descriptors benefits the ViT on IR modality but not RGB or Depth modalities. Second, in observation of the inefficiency on direct finetuning the whole or partial ViT, we design an adaptive multimodal adapter (AMA), which can efficiently aggregate local multimodal features while freezing majority of ViT parameters. Finally, in consideration of the task (FAS vs. generic object classification) and modality (multimodal vs. unimodal) gaps, ImageNet pre-trained models might be sub-optimal for the multimodal FAS task. To bridge these gaps, we propose the modality-asymmetric masked autoencoder (M$^{2}$A$^{2}$E) for multimodal FAS self-supervised pre-training without costly annotated labels. Compared with the previous modality-symmetric autoencoder, the proposed M$^{2}$A$^{2}$E is able to learn more intrinsic task-aware representation and compatible with modality-agnostic (e.g., unimodal, bimodal, and trimodal) downstream settings. Extensive experiments with both unimodal (RGB, Depth, IR) and multimodal (RGB+Depth, RGB+IR, Depth+IR, RGB+Depth+IR) settings conducted on multimodal FAS benchmarks demonstrate the superior performance of the proposed methods. We hope these findings and solutions can facilitate the future research for ViT-based multimodal FAS.
Toward domain generalized pruning by scoring out-of-distribution importance
Oct 25, 2022Filter pruning has been widely used for compressing convolutional neural networks to reduce computation costs during the deployment stage. Recent studies have shown that filter pruning techniques can achieve lossless compression of deep neural networks, reducing redundant filters (kernels) without sacrificing accuracy performance. However, the evaluation is done when the training and testing data are from similar environmental conditions (independent and identically distributed), and how the filter pruning techniques would affect the cross-domain generalization (out-of-distribution) performance is largely ignored. We conduct extensive empirical experiments and reveal that although the intra-domain performance could be maintained after filter pruning, the cross-domain performance will decay to a large extent. As scoring a filter's importance is one of the central problems for pruning, we design the importance scoring estimation by using the variance of domain-level risks to consider the pruning risk in the unseen distribution. As such, we can remain more domain generalized filters. The experiments show that under the same pruning ratio, our method can achieve significantly better cross-domain generalization performance than the baseline filter pruning method. For the first attempt, our work sheds light on the joint problem of domain generalization and filter pruning research.
Forensicability Assessment of Questioned Images in Recapturing Detection
Sep 05, 2022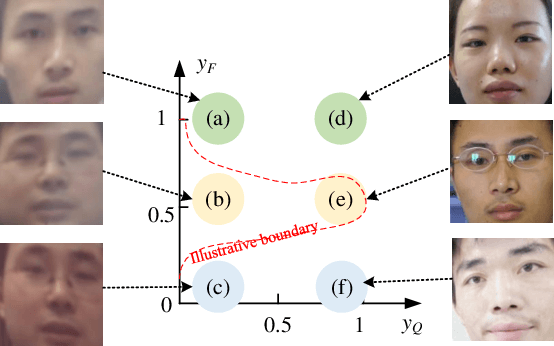

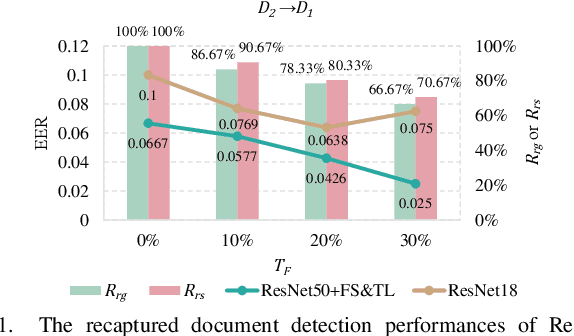
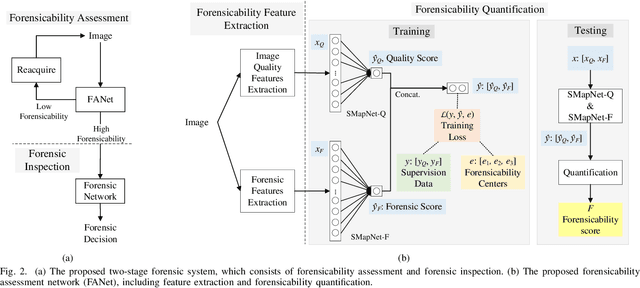
Recapture detection of face and document images is an important forensic task. With deep learning, the performances of face anti-spoofing (FAS) and recaptured document detection have been improved significantly. However, the performances are not yet satisfactory on samples with weak forensic cues. The amount of forensic cues can be quantified to allow a reliable forensic result. In this work, we propose a forensicability assessment network to quantify the forensicability of the questioned samples. The low-forensicability samples are rejected before the actual recapturing detection process to improve the efficiency of recapturing detection systems. We first extract forensicability features related to both image quality assessment and forensic tasks. By exploiting domain knowledge of the forensic application in image quality and forensic features, we define three task-specific forensicability classes and the initialized locations in the feature space. Based on the extracted features and the defined centers, we train the proposed forensic assessment network (FANet) with cross-entropy loss and update the centers with a momentum-based update method. We integrate the trained FANet with practical recapturing detection schemes in face anti-spoofing and recaptured document detection tasks. Experimental results show that, for a generic CNN-based FAS scheme, FANet reduces the EERs from 33.75% to 19.23% under ROSE to IDIAP protocol by rejecting samples with the lowest 30% forensicability scores. The performance of FAS schemes is poor in the rejected samples, with EER as high as 56.48%. Similar performances in rejecting low-forensicability samples have been observed for the state-of-the-art approaches in FAS and recaptured document detection tasks. To the best of our knowledge, this is the first work that assesses the forensicability of recaptured document images and improves the system efficiency.
Benchmarking Joint Face Spoofing and Forgery Detection with Visual and Physiological Cues
Aug 10, 2022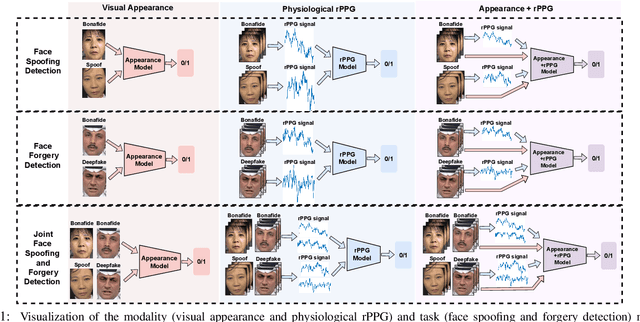
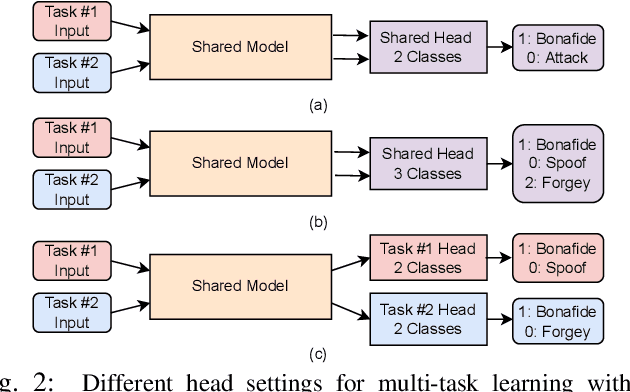
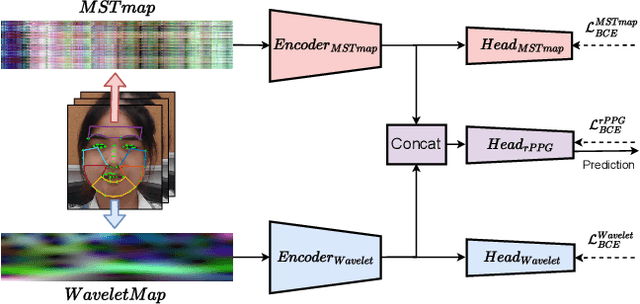
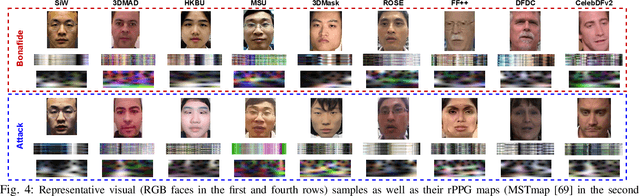
Face anti-spoofing (FAS) and face forgery detection play vital roles in securing face biometric systems from presentation attacks (PAs) and vicious digital manipulation (e.g., deepfakes). Despite promising performance upon large-scale data and powerful deep models, the generalization problem of existing approaches is still an open issue. Most of recent approaches focus on 1) unimodal visual appearance or physiological (i.e., remote photoplethysmography (rPPG)) cues; and 2) separated feature representation for FAS or face forgery detection. On one side, unimodal appearance and rPPG features are respectively vulnerable to high-fidelity face 3D mask and video replay attacks, inspiring us to design reliable multi-modal fusion mechanisms for generalized face attack detection. On the other side, there are rich common features across FAS and face forgery detection tasks (e.g., periodic rPPG rhythms and vanilla appearance for bonafides), providing solid evidence to design a joint FAS and face forgery detection system in a multi-task learning fashion. In this paper, we establish the first joint face spoofing and forgery detection benchmark using both visual appearance and physiological rPPG cues. To enhance the rPPG periodicity discrimination, we design a two-branch physiological network using both facial spatio-temporal rPPG signal map and its continuous wavelet transformed counterpart as inputs. To mitigate the modality bias and improve the fusion efficacy, we conduct a weighted batch and layer normalization for both appearance and rPPG features before multi-modal fusion. We find that the generalization capacities of both unimodal (appearance or rPPG) and multi-modal (appearance+rPPG) models can be obviously improved via joint training on these two tasks. We hope this new benchmark will facilitate the future research of both FAS and deepfake detection communities.
One-Class Knowledge Distillation for Face Presentation Attack Detection
May 08, 2022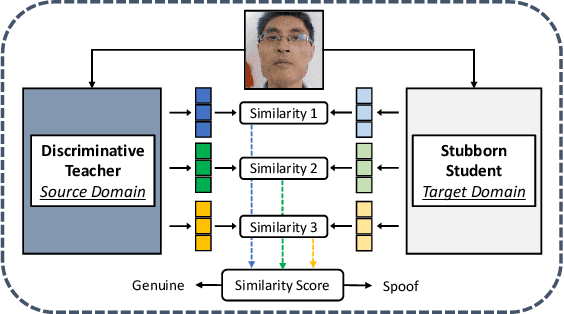
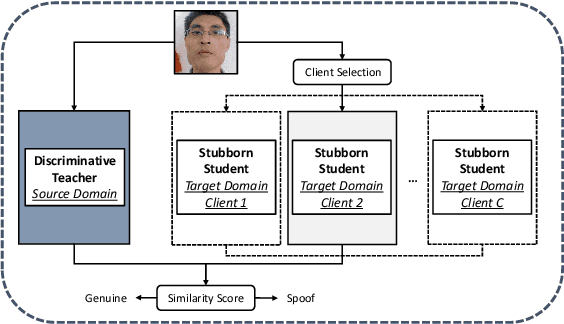
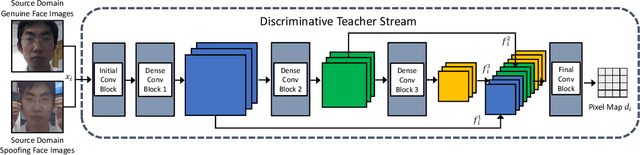
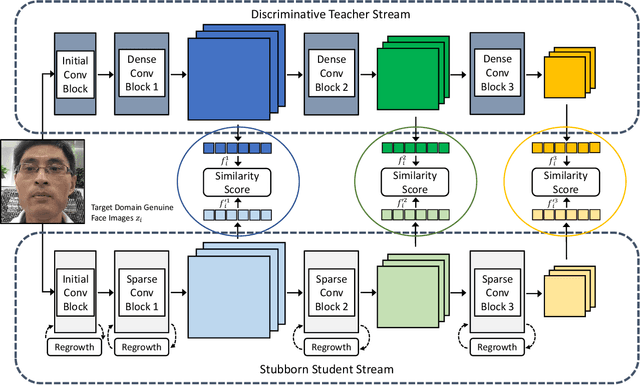
Face presentation attack detection (PAD) has been extensively studied by research communities to enhance the security of face recognition systems. Although existing methods have achieved good performance on testing data with similar distribution as the training data, their performance degrades severely in application scenarios with data of unseen distributions. In situations where the training and testing data are drawn from different domains, a typical approach is to apply domain adaptation techniques to improve face PAD performance with the help of target domain data. However, it has always been a non-trivial challenge to collect sufficient data samples in the target domain, especially for attack samples. This paper introduces a teacher-student framework to improve the cross-domain performance of face PAD with one-class domain adaptation. In addition to the source domain data, the framework utilizes only a few genuine face samples of the target domain. Under this framework, a teacher network is trained with source domain samples to provide discriminative feature representations for face PAD. Student networks are trained to mimic the teacher network and learn similar representations for genuine face samples of the target domain. In the test phase, the similarity score between the representations of the teacher and student networks is used to distinguish attacks from genuine ones. To evaluate the proposed framework under one-class domain adaptation settings, we devised two new protocols and conducted extensive experiments. The experimental results show that our method outperforms baselines under one-class domain adaptation settings and even state-of-the-art methods with unsupervised domain adaptation.
Automatic Facial Skin Feature Detection for Everyone
Mar 30, 2022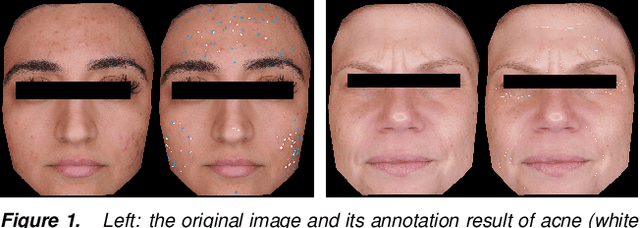
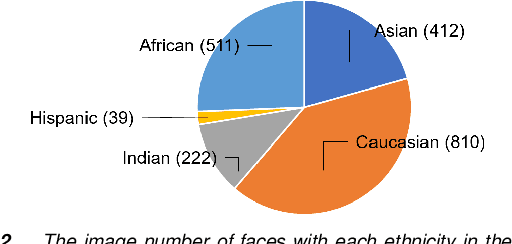
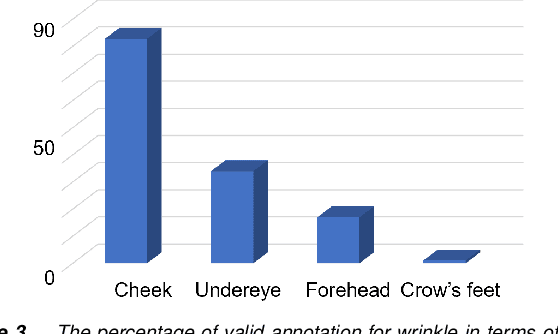
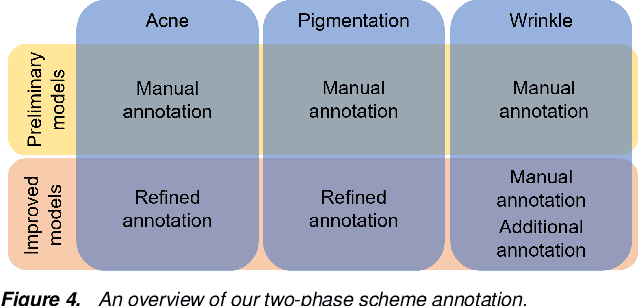
Automatic assessment and understanding of facial skin condition have several applications, including the early detection of underlying health problems, lifestyle and dietary treatment, skin-care product recommendation, etc. Selfies in the wild serve as an excellent data resource to democratize skin quality assessment, but suffer from several data collection challenges.The key to guaranteeing an accurate assessment is accurate detection of different skin features. We present an automatic facial skin feature detection method that works across a variety of skin tones and age groups for selfies in the wild. To be specific, we annotate the locations of acne, pigmentation, and wrinkle for selfie images with different skin tone colors, severity levels, and lighting conditions. The annotation is conducted in a two-phase scheme with the help of a dermatologist to train volunteers for annotation. We employ Unet++ as the network architecture for feature detection. This work shows that the two-phase annotation scheme can robustly detect the accurate locations of acne, pigmentation, and wrinkle for selfie images with different ethnicities, skin tone colors, severity levels, age groups, and lighting conditions.
Learning Meta Pattern for Face Anti-Spoofing
Oct 13, 2021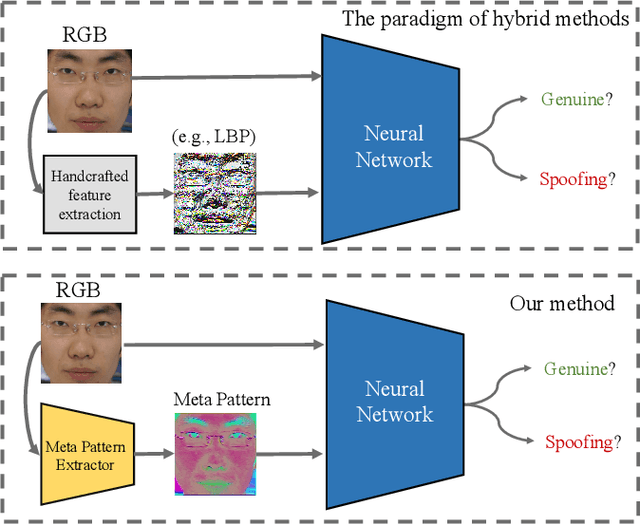
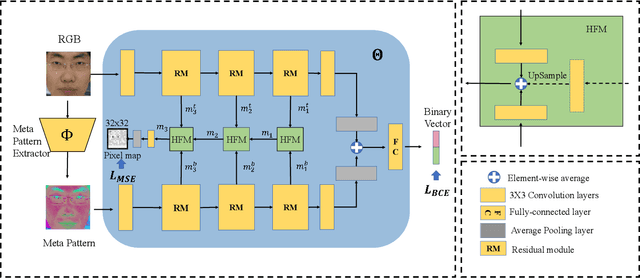
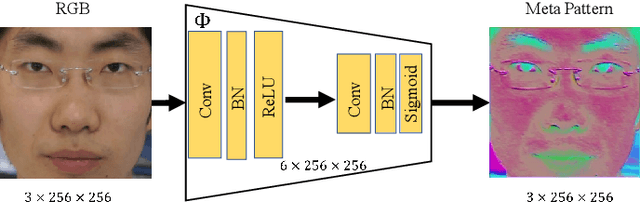

Face Anti-Spoofing (FAS) is essential to secure face recognition systems and has been extensively studied in recent years. Although deep neural networks (DNNs) for the FAS task have achieved promising results in intra-dataset experiments with similar distributions of training and testing data, the DNNs' generalization ability is limited under the cross-domain scenarios with different distributions of training and testing data. To improve the generalization ability, recent hybrid methods have been explored to extract task-aware handcrafted features (e.g., Local Binary Pattern) as discriminative information for the input of DNNs. However, the handcrafted feature extraction relies on experts' domain knowledge, and how to choose appropriate handcrafted features is underexplored. To this end, we propose a learnable network to extract Meta Pattern (MP) in our learning-to-learn framework. By replacing handcrafted features with the MP, the discriminative information from MP is capable of learning a more generalized model. Moreover, we devise a two-stream network to hierarchically fuse the input RGB image and the extracted MP by using our proposed Hierarchical Fusion Module (HFM). We conduct comprehensive experiments and show that our MP outperforms the compared handcrafted features. Also, our proposed method with HFM and the MP can achieve state-of-the-art performance on two different domain generalization evaluation benchmarks.
DRL-FAS: A Novel Framework Based on Deep Reinforcement Learning for Face Anti-Spoofing
Sep 18, 2020
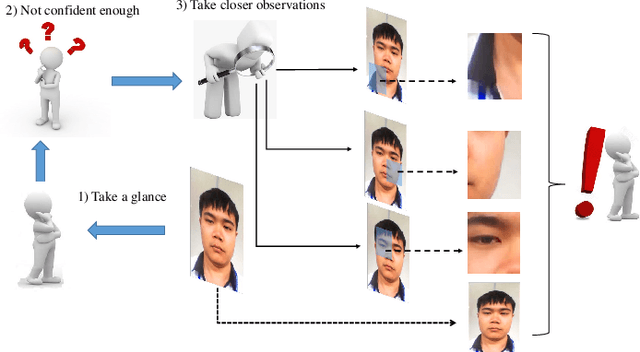
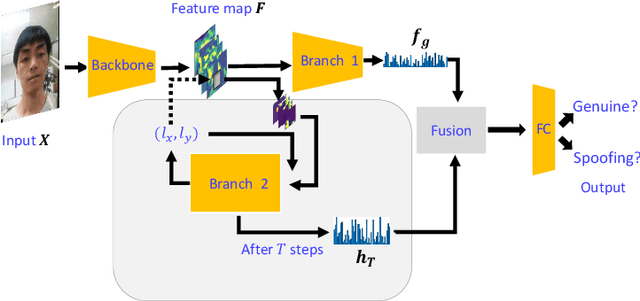
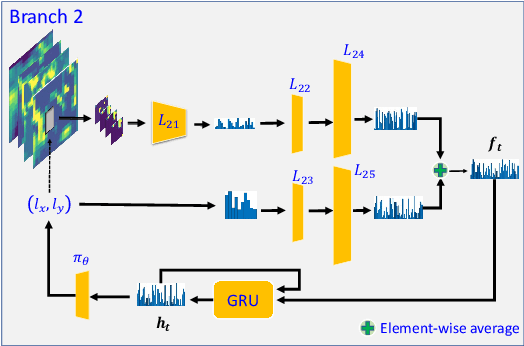
Inspired by the philosophy employed by human beings to determine whether a presented face example is genuine or not, i.e., to glance at the example globally first and then carefully observe the local regions to gain more discriminative information, for the face anti-spoofing problem, we propose a novel framework based on the Convolutional Neural Network (CNN) and the Recurrent Neural Network (RNN). In particular, we model the behavior of exploring face-spoofing-related information from image sub-patches by leveraging deep reinforcement learning. We further introduce a recurrent mechanism to learn representations of local information sequentially from the explored sub-patches with an RNN. Finally, for the classification purpose, we fuse the local information with the global one, which can be learned from the original input image through a CNN. Moreover, we conduct extensive experiments, including ablation study and visualization analysis, to evaluate our proposed framework on various public databases. The experiment results show that our method can generally achieve state-of-the-art performance among all scenarios, demonstrating its effectiveness.
Learning deep forest with multi-scale Local Binary Pattern features for face anti-spoofing
Oct 09, 2019
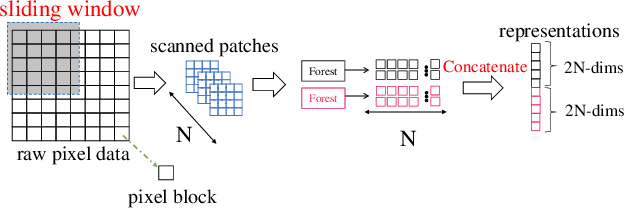
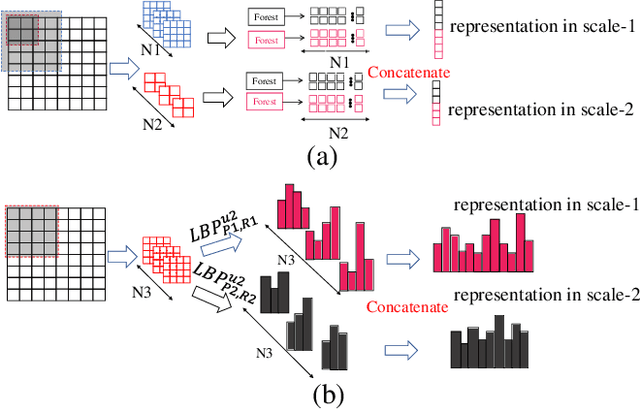
Face Anti-Spoofing (FAS) is significant for the security of face recognition systems. Convolutional Neural Networks (CNNs) have been introduced to the field of the FAS and have achieved competitive performance. However, CNN-based methods are vulnerable to the adversarial attack. Attackers could generate adversarial-spoofing examples to circumvent a CNN-based face liveness detector. Studies about the transferability of the adversarial attack reveal that utilizing handcrafted feature-based methods could improve security in a system-level. Therefore, handcrafted feature-based methods are worth our exploration. In this paper, we introduce the deep forest, which is proposed as an alternative towards CNNs by Zhou et al., in the problem of the FAS. To the best of our knowledge, this is the first attempt at exploiting the deep forest in the problem of FAS. Moreover, we propose to re-devise the representation constructing by using LBP descriptors rather than the Grained-Scanning Mechanism in the original scheme. Our method achieves competitive results. On the benchmark database IDIAP REPLAY-ATTACK, 0\% Equal Error Rate (EER) is achieved. This work provides a competitive option in a fusing scheme for improving system-level security and offers important ideas to those who want to explore methods besides CNNs.