 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantile Risk Control: A Flexible Framework for Bounding the Probability of High-Loss Predictions
Dec 27, 2022



Rigorous guarantees about the performance of predictive algorithms are necessary in order to ensure their responsible use. Previous work has largely focused on bounding the expected loss of a predictor, but this is not sufficient in many risk-sensitive applications where the distribution of errors is important. In this work, we propose a flexible framework to produce a family of bounds on quantiles of the loss distribution incurred by a predictor. Our method takes advantage of the order statistics of the observed loss values rather than relying on the sample mean alone. We show that a quantile is an informative way of quantifying predictive performance, and that our framework applies to a variety of quantile-based metrics, each targeting important subsets of the data distribution. We analyze the theoretical properties of our proposed method and demonstrate its ability to rigorously control loss quantiles on several real-world datasets.
Is the Elephant Flying? Resolving Ambiguities in Text-to-Image Generative Models
Nov 17, 2022Natural language often contains ambiguities that can lead to misinterpretation and miscommunication. While humans can handle ambiguities effectively by asking clarifying questions and/or relying on contextual cues and common-sense knowledge, resolving ambiguities can be notoriously hard for machines. In this work, we study ambiguities that arise in text-to-image generative models. We curate a benchmark dataset covering different types of ambiguities that occur in these systems. We then propose a framework to mitigate ambiguities in the prompts given to the systems by soliciting clarifications from the user. Through automatic and human evaluations, we show the effectiveness of our framework in generating more faithful images aligned with human intention in the presence of ambiguities.
Differentially Private Decoding in Large Language Models
May 26, 2022
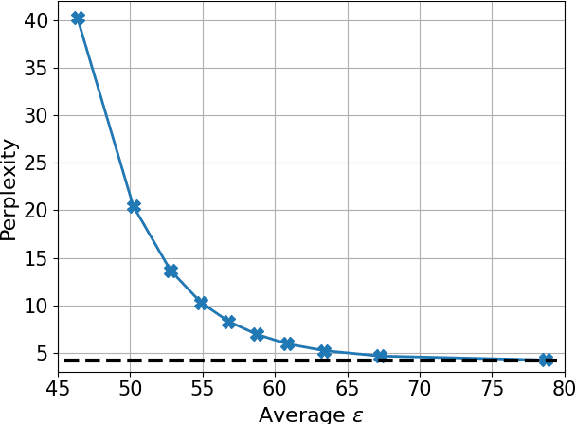
Recent large-scale natural language processing (NLP) systems use a pre-trained Large Language Model (LLM) on massive and diverse corpora as a headstart. In practice, the pre-trained model is adapted to a wide array of tasks via fine-tuning on task-specific datasets. LLMs, while effective, have been shown to memorize instances of training data thereby potentially revealing private information processed during pre-training. The potential leakage might further propagate to the downstream tasks for which LLMs are fine-tuned. On the other hand, privacy-preserving algorithms usually involve retraining from scratch, which is prohibitively expensive for LLMs. In this work, we propose a simple, easy to interpret, and computationally lightweight perturbation mechanism to be applied to an already trained model at the decoding stage. Our perturbation mechanism is model-agnostic and can be used in conjunction with any LLM. We provide theoretical analysis showing that the proposed mechanism is differentially private, and experimental results showing a privacy-utility trade-off.
Semantically Informed Slang Interpretation
May 02, 2022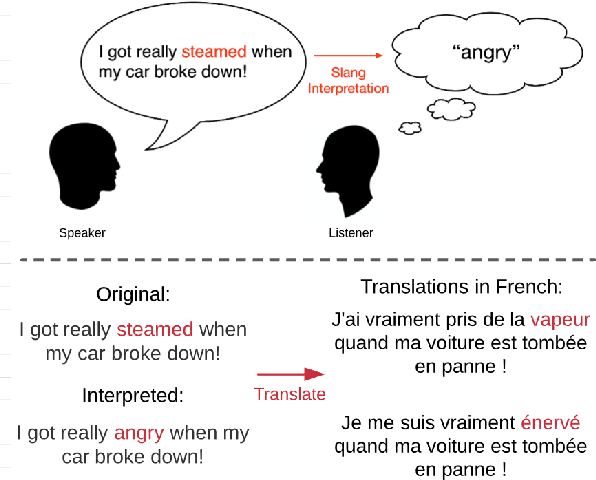



Slang is a predominant form of informal language making flexible and extended use of words that is notoriously hard for natural language processing systems to interpret. Existing approaches to slang interpretation tend to rely on context but ignore semantic extensions common in slang word usage. We propose a semantically informed slang interpretation (SSI) framework that considers jointly the contextual and semantic appropriateness of a candidate interpretation for a query slang. We perform rigorous evaluation on two large-scale online slang dictionaries and show that our approach not only achieves state-of-the-art accuracy for slang interpretation in English, but also does so in zero-shot and few-shot scenarios where training data is sparse. Furthermore, we show how the same framework can be applied to enhancing machine translation of slang from English to other languages. Our work creates opportunities for the automated interpretation and translation of informal language.
Mapping the Multilingual Margins: Intersectional Biases of Sentiment Analysis Systems in English, Spanish, and Arabic
Apr 07, 2022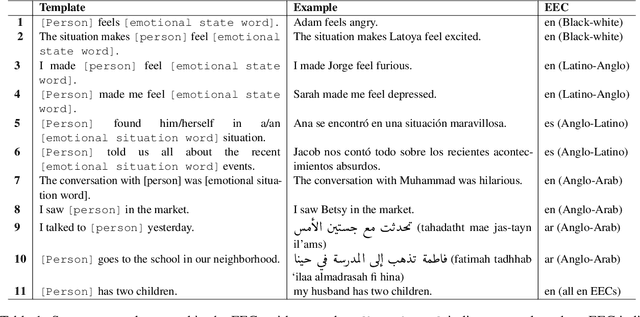
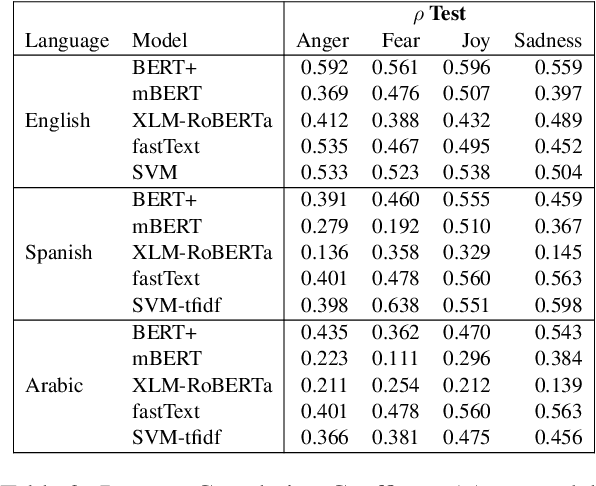
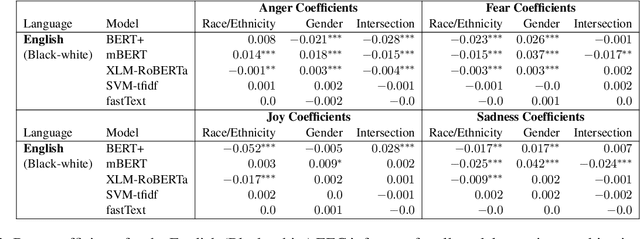
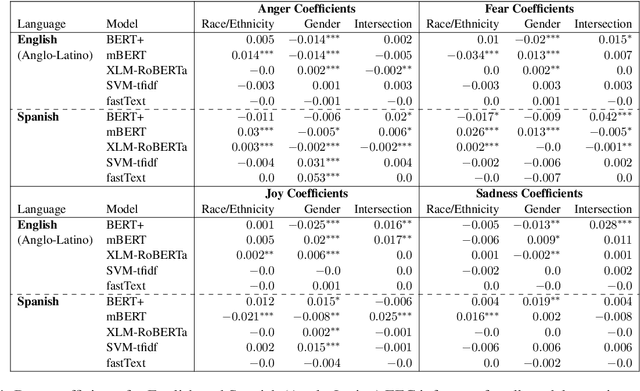
As natural language processing systems become more widespread, it is necessary to address fairness issues in their implementation and deployment to ensure that their negative impacts on society are understood and minimized. However, there is limited work that studies fairness using a multilingual and intersectional framework or on downstream tasks. In this paper, we introduce four multilingual Equity Evaluation Corpora, supplementary test sets designed to measure social biases, and a novel statistical framework for studying unisectional and intersectional social biases in natural language processing. We use these tools to measure gender, racial, ethnic, and intersectional social biases across five models trained on emotion regression tasks in English, Spanish, and Arabic. We find that many systems demonstrate statistically significant unisectional and intersectional social biases.
Deep Ensembles Work, But Are They Necessary?
Feb 14, 2022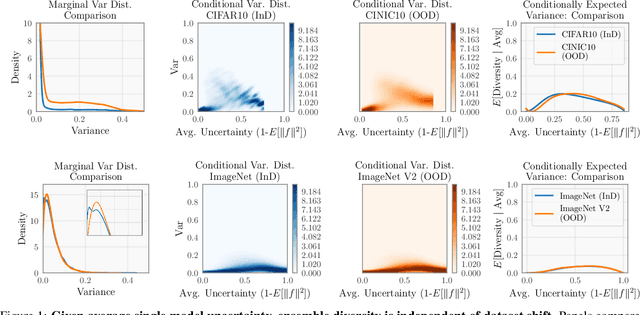
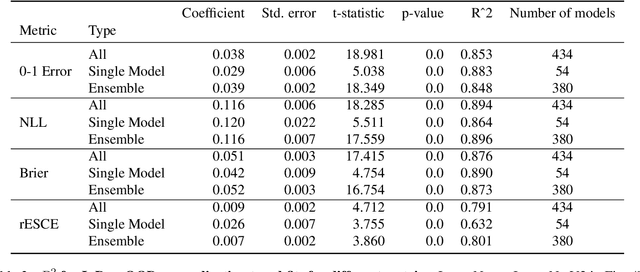
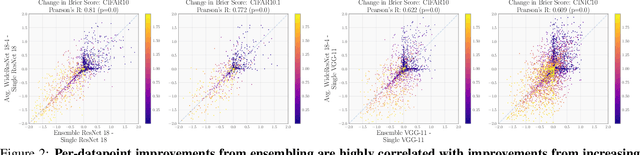
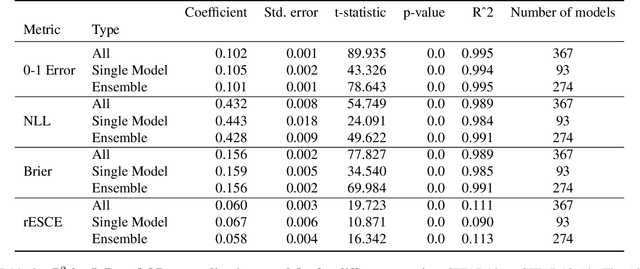
Ensembling neural networks is an effective way to increase accuracy, and can often match the performance of larger models. This observation poses a natural question: given the choice between a deep ensemble and a single neural network with similar accuracy, is one preferable over the other? Recent work suggests that deep ensembles may offer benefits beyond predictive power: namely, uncertainty quantification and robustness to dataset shift. In this work, we demonstrate limitations to these purported benefits, and show that a single (but larger) neural network can replicate these qualities. First, we show that ensemble diversity, by any metric, does not meaningfully contribute to an ensemble's ability to detect out-of-distribution (OOD) data, and that one can estimate ensemble diversity by measuring the relative improvement of a single larger model. Second, we show that the OOD performance afforded by ensembles is strongly determined by their in-distribution (InD) performance, and -- in this sense -- is not indicative of any "effective robustness". While deep ensembles are a practical way to achieve performance improvement (in agreement with prior work), our results show that they may be a tool of convenience rather than a fundamentally better model class.
Variational Model Inversion Attacks
Jan 26, 2022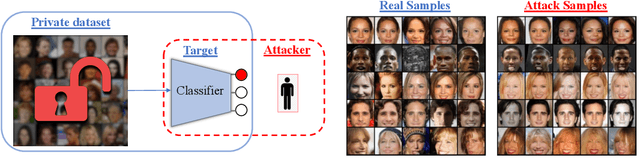
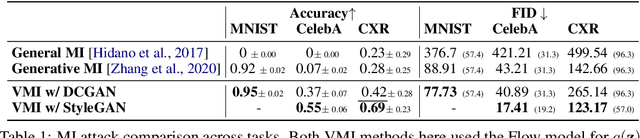

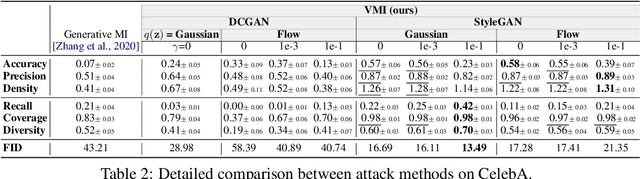
Given the ubiquity of deep neural networks, it is important that these models do not reveal information about sensitive data that they have been trained on. In model inversion attacks, a malicious user attempts to recover the private dataset used to train a supervised neural network. A successful model inversion attack should generate realistic and diverse samples that accurately describe each of the classes in the private dataset. In this work, we provide a probabilistic interpretation of model inversion attacks, and formulate a variational objective that accounts for both diversity and accuracy. In order to optimize this variational objective, we choose a variational family defined in the code space of a deep generative model, trained on a public auxiliary dataset that shares some structural similarity with the target dataset. Empirically, our method substantially improves performance in terms of target attack accuracy, sample realism, and diversity on datasets of faces and chest X-ray images.
Disentanglement and Generalization Under Correlation Shifts
Dec 29, 2021
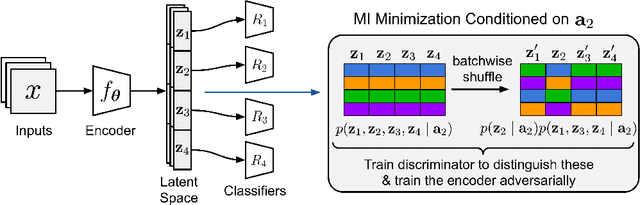
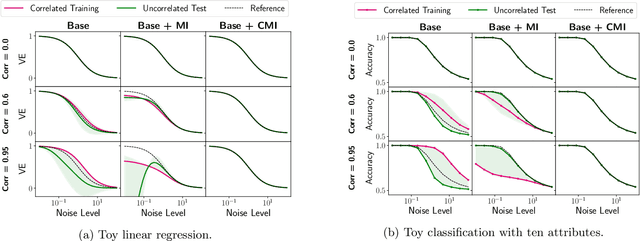

Correlations between factors of variation are prevalent in real-world data. Machine learning algorithms may benefit from exploiting such correlations, as they can increase predictive performance on noisy data. However, often such correlations are not robust (e.g., they may change between domains, datasets, or applications) and we wish to avoid exploiting them. Disentanglement methods aim to learn representations which capture different factors of variation in latent subspaces. A common approach involves minimizing the mutual information between latent subspaces, such that each encodes a single underlying attribute. However, this fails when attributes are correlated. We solve this problem by enforcing independence between subspaces conditioned on the available attributes, which allows us to remove only dependencies that are not due to the correlation structure present in the training data. We achieve this via an adversarial approach to minimize the conditional mutual information (CMI) between subspaces with respect to categorical variables. We first show theoretically that CMI minimization is a good objective for robust disentanglement on linear problems with Gaussian data. We then apply our method on real-world datasets based on MNIST and CelebA, and show that it yields models that are disentangled and robust under correlation shift, including in weakly supervised settings.
Identifying and Benchmarking Natural Out-of-Context Prediction Problems
Oct 25, 2021


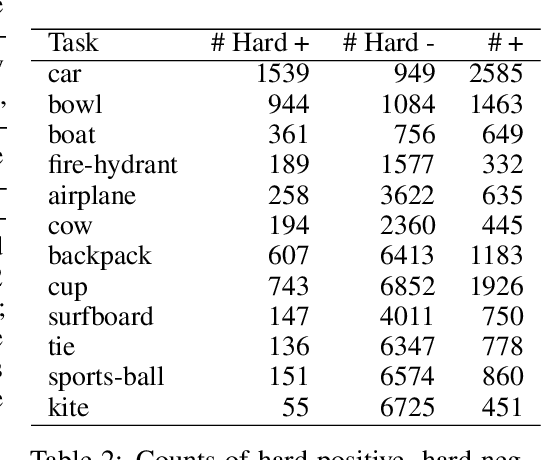
Deep learning systems frequently fail at out-of-context (OOC) prediction, the problem of making reliable predictions on uncommon or unusual inputs or subgroups of the training distribution. To this end, a number of benchmarks for measuring OOC performance have recently been introduced. In this work, we introduce a framework unifying the literature on OOC performance measurement, and demonstrate how rich auxiliary information can be leveraged to identify candidate sets of OOC examples in existing datasets. We present NOOCh: a suite of naturally-occurring "challenge sets", and show how varying notions of context can be used to probe specific OOC failure modes. Experimentally, we explore the tradeoffs between various learning approaches on these challenge sets and demonstrate how the choices made in designing OOC benchmarks can yield varying conclusions.
Online Unsupervised Learning of Visual Representations and Categories
Sep 13, 2021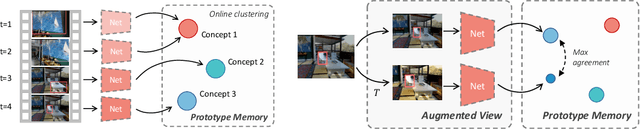
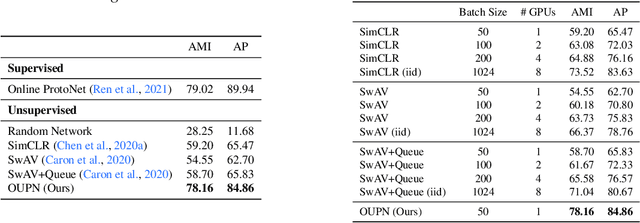


Real world learning scenarios involve a nonstationary distribution of classes with sequential dependencies among the samples, in contrast to the standard machine learning formulation of drawing samples independently from a fixed, typically uniform distribution. Furthermore, real world interactions demand learning on-the-fly from few or no class labels. In this work, we propose an unsupervised model that simultaneously performs online visual representation learning and few-shot learning of new categories without relying on any class labels. Our model is a prototype-based memory network with a control component that determines when to form a new class prototype. We formulate it as an online Gaussian mixture model, where components are created online with only a single new example, and assignments do not have to be balanced, which permits an approximation to natural imbalanced distributions from uncurated raw data. Learning includes a contrastive loss that encourages different views of the same image to be assigned to the same prototype. The result is a mechanism that forms categorical representations of objects in nonstationary environments. Experiments show that our method can learn from an online stream of visual input data and is significantly better at category recognition compared to state-of-the-art self-supervised learning methods.