 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePathologies of Predictive Diversity in Deep Ensembles
Feb 03, 2023



Classical results establish that ensembles of small models benefit when predictive diversity is encouraged, through bagging, boosting, and similar. Here we demonstrate that this intuition does not carry over to ensembles of deep neural networks used for classification, and in fact the opposite can be true. Unlike regression models or small (unconfident) classifiers, predictions from large (confident) neural networks concentrate in vertices of the probability simplex. Thus, decorrelating these points necessarily moves the ensemble prediction away from vertices, harming confidence and moving points across decision boundaries. Through large scale experiments, we demonstrate that diversity-encouraging regularizers hurt the performance of high-capacity deep ensembles used for classification. Even more surprisingly, discouraging predictive diversity can be beneficial. Together this work strongly suggests that the best strategy for deep ensembles is utilizing more accurate, but likely less diverse, component models.
Deep Ensembles Work, But Are They Necessary?
Feb 14, 2022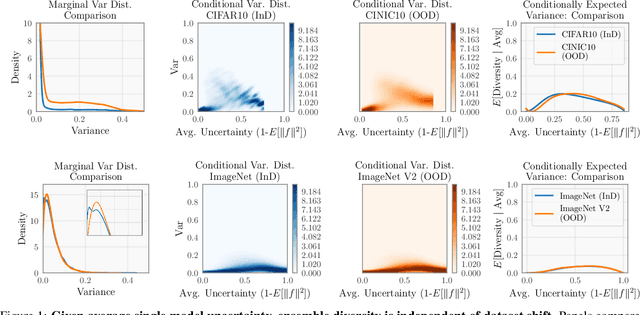
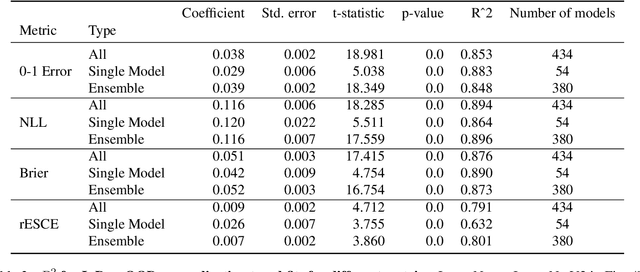
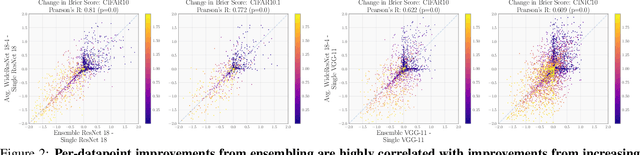
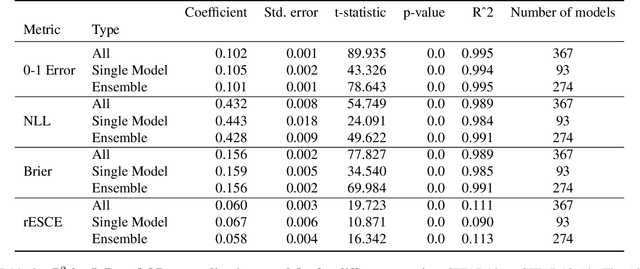
Ensembling neural networks is an effective way to increase accuracy, and can often match the performance of larger models. This observation poses a natural question: given the choice between a deep ensemble and a single neural network with similar accuracy, is one preferable over the other? Recent work suggests that deep ensembles may offer benefits beyond predictive power: namely, uncertainty quantification and robustness to dataset shift. In this work, we demonstrate limitations to these purported benefits, and show that a single (but larger) neural network can replicate these qualities. First, we show that ensemble diversity, by any metric, does not meaningfully contribute to an ensemble's ability to detect out-of-distribution (OOD) data, and that one can estimate ensemble diversity by measuring the relative improvement of a single larger model. Second, we show that the OOD performance afforded by ensembles is strongly determined by their in-distribution (InD) performance, and -- in this sense -- is not indicative of any "effective robustness". While deep ensembles are a practical way to achieve performance improvement (in agreement with prior work), our results show that they may be a tool of convenience rather than a fundamentally better model class.
Markerless tracking of user-defined features with deep learning
Apr 09, 2018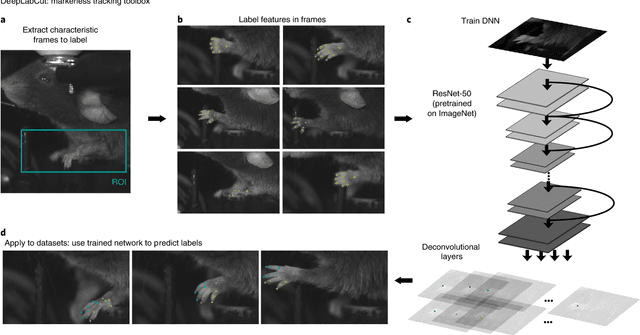
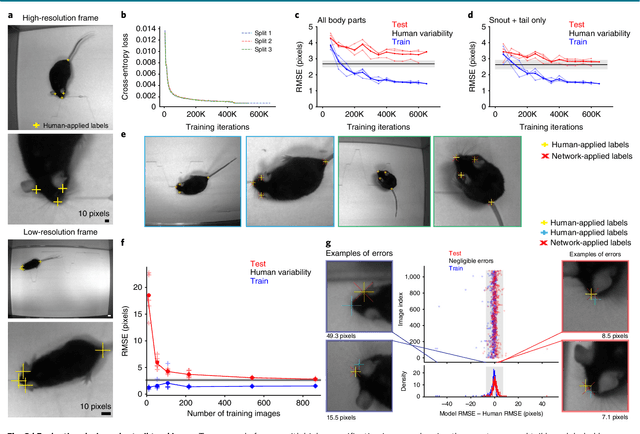

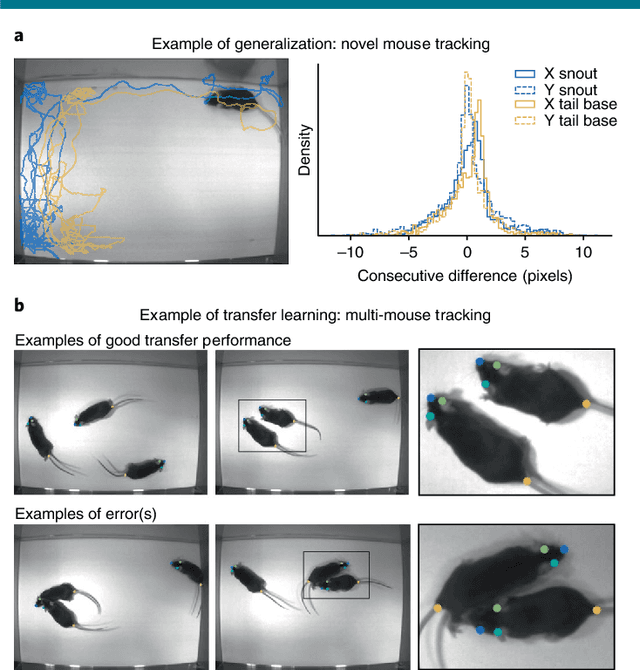
Quantifying behavior is crucial for many applications in neuroscience. Videography provides easy methods for the observation and recording of animal behavior in diverse settings, yet extracting particular aspects of a behavior for further analysis can be highly time consuming. In motor control studies, humans or other animals are often marked with reflective markers to assist with computer-based tracking, yet markers are intrusive (especially for smaller animals), and the number and location of the markers must be determined a priori. Here, we present a highly efficient method for markerless tracking based on transfer learning with deep neural networks that achieves excellent results with minimal training data. We demonstrate the versatility of this framework by tracking various body parts in a broad collection of experimental settings: mice odor trail-tracking, egg-laying behavior in drosophila, and mouse hand articulation in a skilled forelimb task. For example, during the skilled reaching behavior, individual joints can be automatically tracked (and a confidence score is reported). Remarkably, even when a small number of frames are labeled ($\approx 200$), the algorithm achieves excellent tracking performance on test frames that is comparable to human accuracy.
* Videos at http://www.mousemotorlab.org/deeplabcut