 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimits of Detecting Text Generated by Large-Scale Language Models
Feb 09, 2020Some consider large-scale language models that can generate long and coherent pieces of text as dangerous, since they may be used in misinformation campaigns. Here we formulate large-scale language model output detection as a hypothesis testing problem to classify text as genuine or generated. We show that error exponents for particular language models are bounded in terms of their perplexity, a standard measure of language generation performance. Under the assumption that human language is stationary and ergodic, the formulation is extended from considering specific language models to considering maximum likelihood language models, among the class of k-order Markov approximations; error probabilities are characterized. Some discussion of incorporating semantic side information is also given.
Learning from Noisy Anchors for One-stage Object Detection
Dec 11, 2019
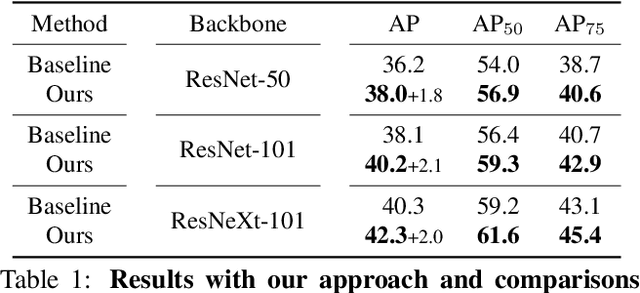
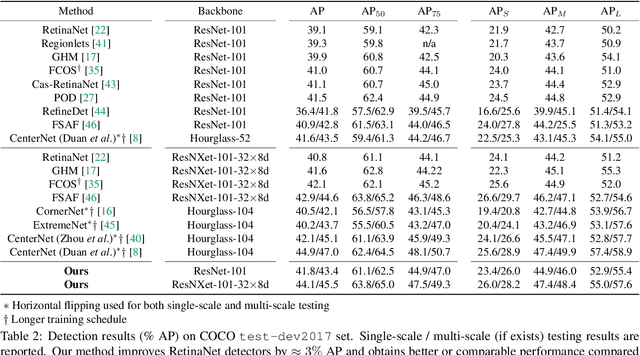
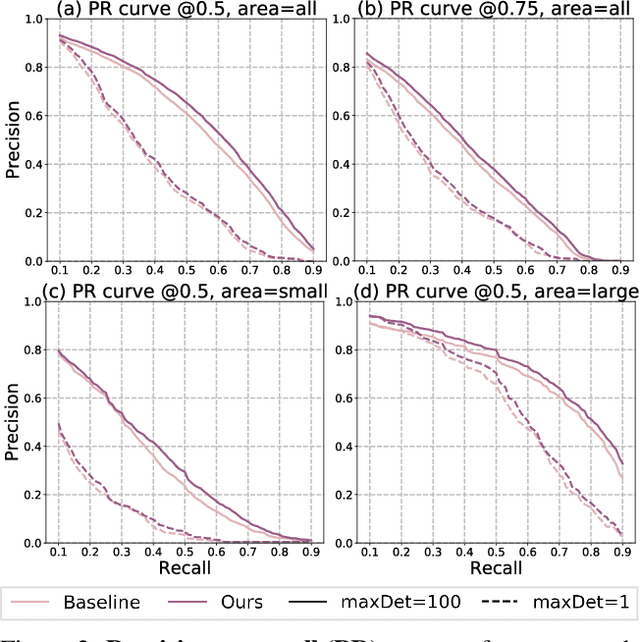
State-of-the-art object detectors rely on regressing and classifying an extensive list of possible anchors, which are divided into positive and negative samples based on their intersection-over-union (IoU) with corresponding groundtruth objects. Such a harsh split conditioned on IoU results in binary labels that are potentially noisy and challenging for training. In this paper, we propose to mitigate noise incurred by imperfect label assignment such that the contributions of anchors are dynamically determined by a carefully constructed cleanliness score associated with each anchor. Exploring outputs from both regression and classification branches, the cleanliness scores, estimated without incurring any additional computational overhead, are used not only as soft labels to supervise the training of the classification branch but also sample re-weighting factors for improved localization and classification accuracy. We conduct extensive experiments on COCO, and demonstrate, among other things, the proposed approach steadily improves RetinaNet by ~2% with various backbones.
Learning to Retrieve Reasoning Paths over Wikipedia Graph for Question Answering
Nov 24, 2019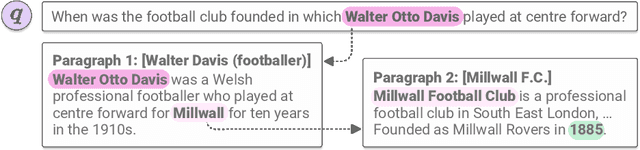
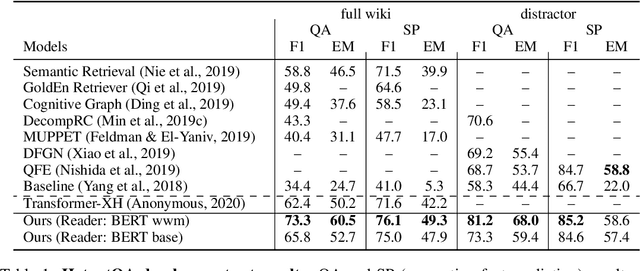
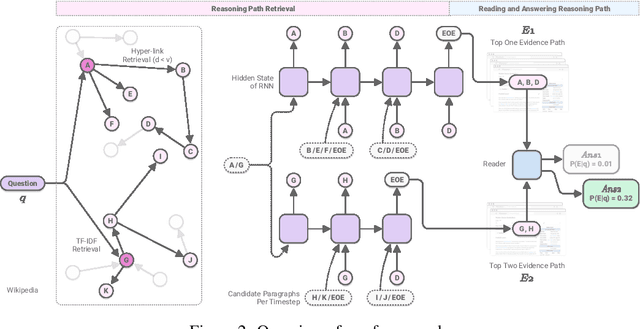
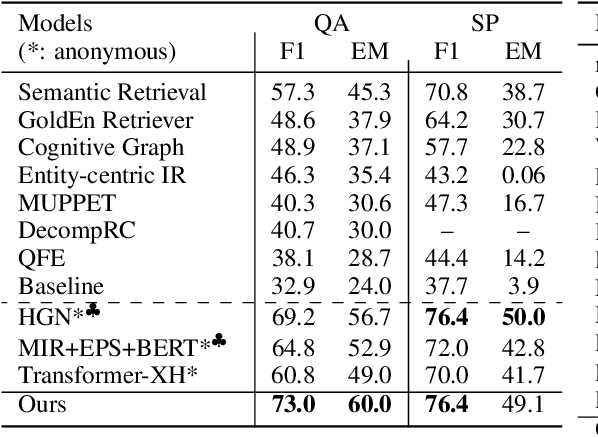
Answering questions that require multi-hop reasoning at web-scale necessitates retrieving multiple evidence documents, one of which often has little lexical or semantic relationship to the question. This paper introduces a new graph-based recurrent retrieval approach that learns to retrieve reasoning paths over the Wikipedia graph to answer multi-hop open-domain questions. Our retriever model trains a recurrent neural network that learns to sequentially retrieve evidence paragraphs in the reasoning path by conditioning on the previously retrieved documents. Our reader model ranks the reasoning paths and extracts the answer span included in the best reasoning path. Experimental results show state-of-the-art results in three open-domain QA datasets, showcasing the effectiveness and robustness of our method. Notably, our method achieves significant improvement in HotpotQA, outperforming the previous best model by more than 14 points.
Attentive Student Meets Multi-Task Teacher: Improved Knowledge Distillation for Pretrained Models
Nov 09, 2019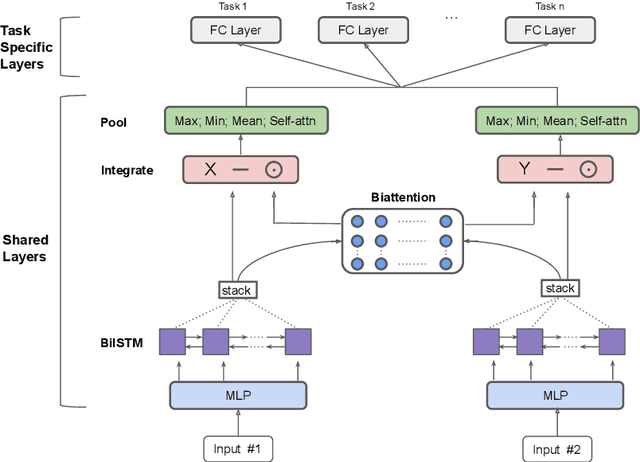
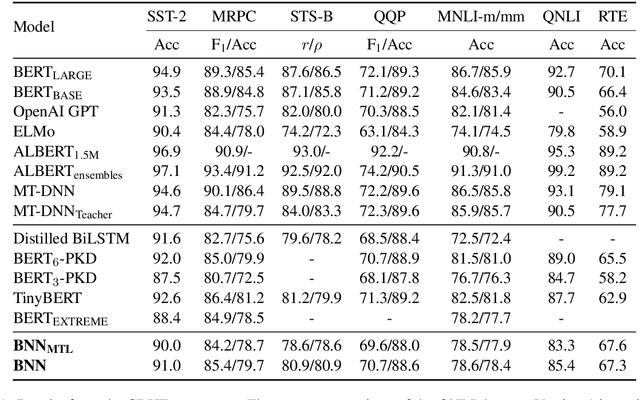
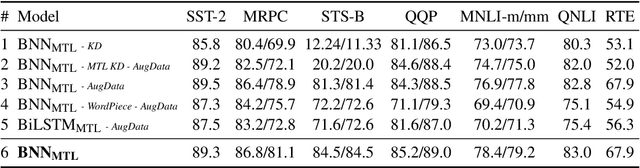
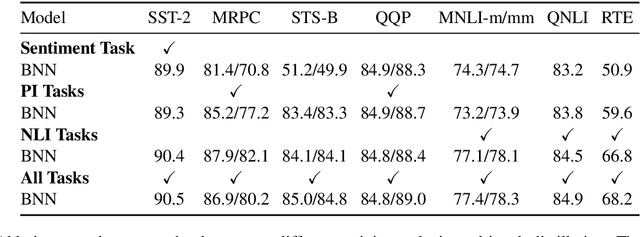
In this paper, we explore the knowledge distillation approach under the multi-task learning setting. We distill the BERT model refined by multi-task learning on seven datasets of the GLUE benchmark into a bidirectional LSTM with attention mechanism. Unlike other BERT distillation methods which specifically designed for Transformer-based architectures, we provide a general learning framework. Our approach is model agnostic and can be easily applied on different future teacher models. Compared to a strong, similarly BiLSTM-based approach, we achieve better quality under the same computational constraints. Compared to the present state of the art, we reach comparable results with much faster inference speed.
ERASER: A Benchmark to Evaluate Rationalized NLP Models
Nov 08, 2019
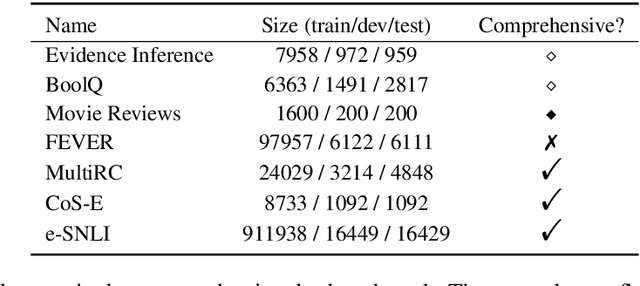
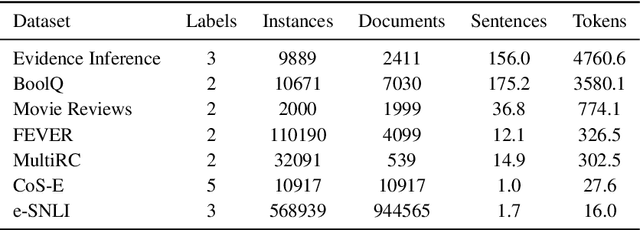
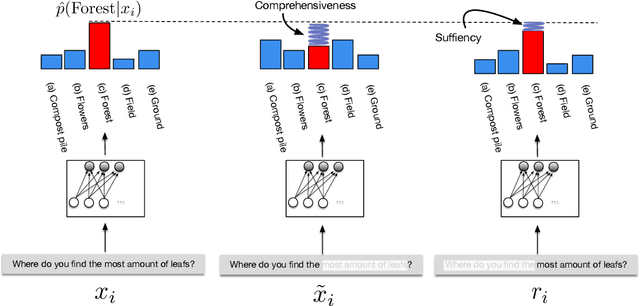
State-of-the-art models in NLP are now predominantly based on deep neural networks that are generally opaque in terms of how they come to specific predictions. This limitation has led to increased interest in designing more interpretable deep models for NLP that can reveal the `reasoning' underlying model outputs. But work in this direction has been conducted on different datasets and tasks with correspondingly unique aims and metrics; this makes it difficult to track progress. We propose the Evaluating Rationales And Simple English Reasoning (ERASER) benchmark to advance research on interpretable models in NLP. This benchmark comprises multiple datasets and tasks for which human annotations of "rationales" (supporting evidence) have been collected. We propose several metrics that aim to capture how well the rationales provided by models align with human rationales, and also how faithful these rationales are (i.e., the degree to which provided rationales influenced the corresponding predictions). Our hope is that releasing this benchmark facilitates progress on designing more interpretable NLP systems. The benchmark, code, and documentation are available at: www.eraserbenchmark.com .
Keeping Your Distance: Solving Sparse Reward Tasks Using Self-Balancing Shaped Rewards
Nov 04, 2019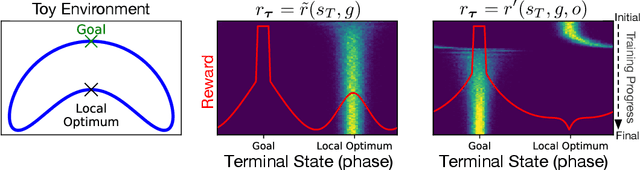
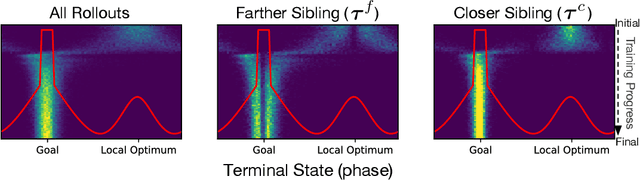
While using shaped rewards can be beneficial when solving sparse reward tasks, their successful application often requires careful engineering and is problem specific. For instance, in tasks where the agent must achieve some goal state, simple distance-to-goal reward shaping often fails, as it renders learning vulnerable to local optima. We introduce a simple and effective model-free method to learn from shaped distance-to-goal rewards on tasks where success depends on reaching a goal state. Our method introduces an auxiliary distance-based reward based on pairs of rollouts to encourage diverse exploration. This approach effectively prevents learning dynamics from stabilizing around local optima induced by the naive distance-to-goal reward shaping and enables policies to efficiently solve sparse reward tasks. Our augmented objective does not require any additional reward engineering or domain expertise to implement and converges to the original sparse objective as the agent learns to solve the task. We demonstrate that our method successfully solves a variety of hard-exploration tasks (including maze navigation and 3D construction in a Minecraft environment), where naive distance-based reward shaping otherwise fails, and intrinsic curiosity and reward relabeling strategies exhibit poor performance.
Sketch-Fill-A-R: A Persona-Grounded Chit-Chat Generation Framework
Oct 28, 2019

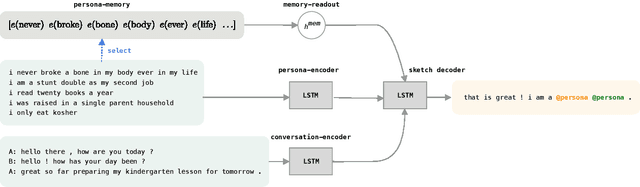

Human-like chit-chat conversation requires agents to generate responses that are fluent, engaging and consistent. We propose Sketch-Fill-A-R, a framework that uses a persona-memory to generate chit-chat responses in three phases. First, it generates dynamic sketch responses with open slots. Second, it generates candidate responses by filling slots with parts of its stored persona traits. Lastly, it ranks and selects the final response via a language model score. Sketch-Fill-A-R outperforms a state-of-the-art baseline both quantitatively (10-point lower perplexity) and qualitatively (preferred by 55% heads-up in single-turn and 20% higher in consistency in multi-turn user studies) on the Persona-Chat dataset. Finally, we extensively analyze Sketch-Fill-A-R's responses and human feedback, and show it is more consistent and engaging by using more relevant responses and questions.
Evaluating the Factual Consistency of Abstractive Text Summarization
Oct 28, 2019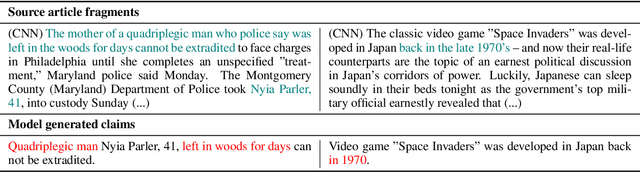


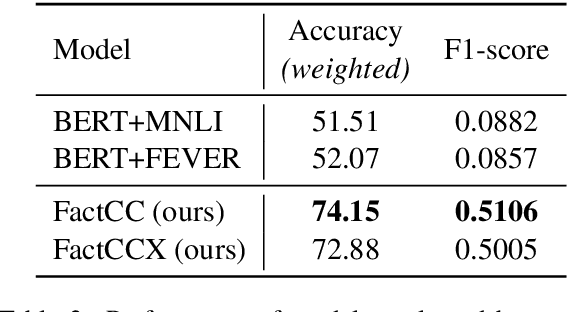
Currently used metrics for assessing summarization algorithms do not account for whether summaries are factually consistent with source documents. We propose a weakly-supervised, model-based approach for verifying factual consistency and identifying conflicts between source documents and a generated summary. Training data is generated by applying a series of rule-based transformations to the sentences of source documents. The factual consistency model is then trained jointly for three tasks: 1) identify whether sentences remain factually consistent after transformation, 2) extract a span in the source documents to support the consistency prediction, 3) extract a span in the summary sentence that is inconsistent if one exists. Transferring this model to summaries generated by several state-of-the art models reveals that this highly scalable approach substantially outperforms previous models, including those trained with strong supervision using standard datasets for natural language inference and fact checking. Additionally, human evaluation shows that the auxiliary span extraction tasks provide useful assistance in the process of verifying factual consistency.
Global Capacity Measures for Deep ReLU Networks via Path Sampling
Oct 22, 2019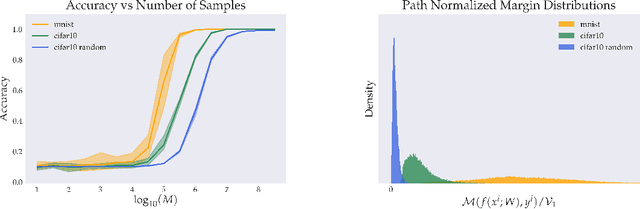
Classical results on the statistical complexity of linear models have commonly identified the norm of the weights $\|w\|$ as a fundamental capacity measure. Generalizations of this measure to the setting of deep networks have been varied, though a frequently identified quantity is the product of weight norms of each layer. In this work, we show that for a large class of networks possessing a positive homogeneity property, similar bounds may be obtained instead in terms of the norm of the product of weights. Our proof technique generalizes a recently proposed sampling argument, which allows us to demonstrate the existence of sparse approximants of positive homogeneous networks. This yields covering number bounds, which can be converted to generalization bounds for multi-class classification that are comparable to, and in certain cases improve upon, existing results in the literature. Finally, we investigate our sampling procedure empirically, which yields results consistent with our theory.
Find or Classify? Dual Strategy for Slot-Value Predictions on Multi-Domain Dialog State Tracking
Oct 10, 2019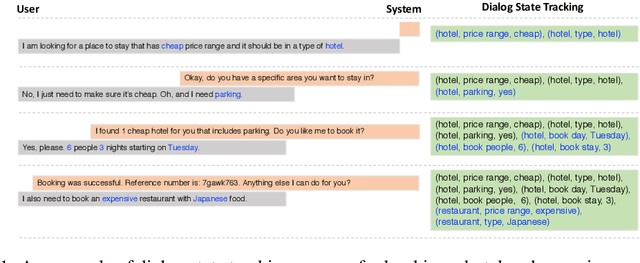
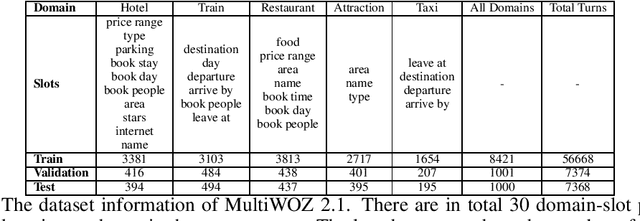
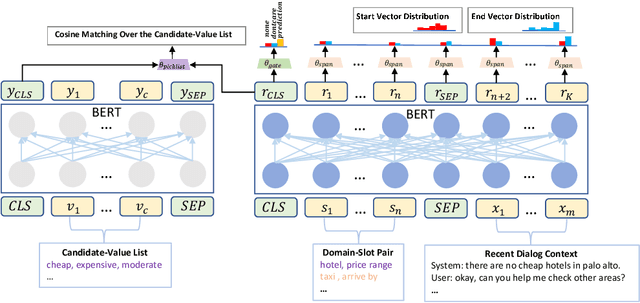

Dialog State Tracking (DST) is a core component in task-oriented dialog systems. Existing approaches for DST usually fall into two categories, i.e, the picklist-based and span-based. From one hand, the picklist-based methods perform classifications for each slot over a candidate-value list, under the condition that a pre-defined ontology is accessible. However, it is impractical in industry since it is hard to get full access to the ontology. On the other hand, the span-based methods track values for each slot through finding text spans in the dialog context. However, due to the diversity of value descriptions, it is hard to find a particular string in the dialog context. To mitigate these issues, this paper proposes a Dual Strategy for DST (DS-DST) to borrow advantages from both the picklist-based and span-based methods, by classifying over a picklist or finding values from a slot span. Empirical results show that DS-DST achieves the state-of-the-art scores in terms of joint accuracy, i.e., 51.2% on the MultiWOZ 2.1 dataset, and 53.3% when the full ontology is accessible.