 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble Elastic DQN: A novel multi-step ensemble approach to address overestimation in deep value-based reinforcement learning
Jun 06, 2025While many algorithmic extensions to Deep Q-Networks (DQN) have been proposed, there remains limited understanding of how different improvements interact. In particular, multi-step and ensemble style extensions have shown promise in reducing overestimation bias, thereby improving sample efficiency and algorithmic stability. In this paper, we introduce a novel algorithm called Ensemble Elastic Step DQN (EEDQN), which unifies ensembles with elastic step updates to stabilise algorithmic performance. EEDQN is designed to address two major challenges in deep reinforcement learning: overestimation bias and sample efficiency. We evaluated EEDQN against standard and ensemble DQN variants across the MinAtar benchmark, a set of environments that emphasise behavioral learning while reducing representational complexity. Our results show that EEDQN achieves consistently robust performance across all tested environments, outperforming baseline DQN methods and matching or exceeding state-of-the-art ensemble DQNs in final returns on most of the MinAtar environments. These findings highlight the potential of systematically combining algorithmic improvements and provide evidence that ensemble and multi-step methods, when carefully integrated, can yield substantial gains.
Elastic Step DQN: A novel multi-step algorithm to alleviate overestimation in Deep QNetworks
Oct 07, 2022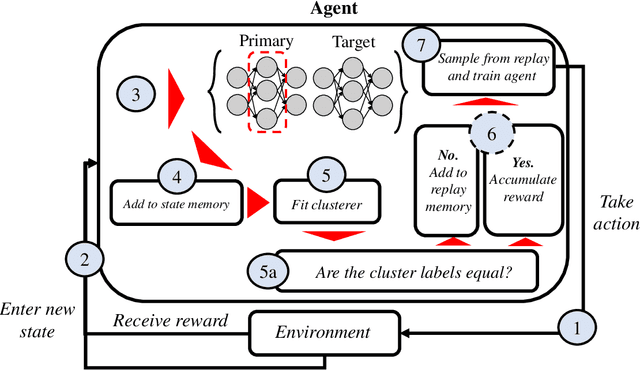
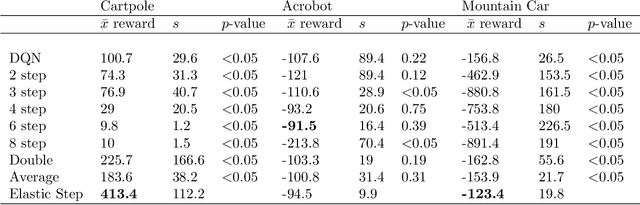
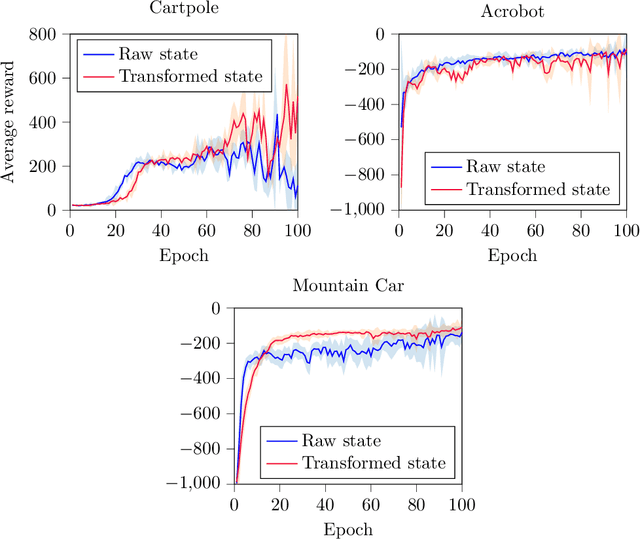
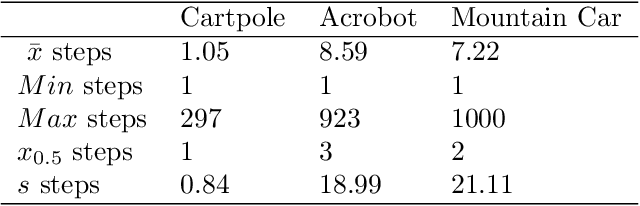
Deep Q-Networks algorithm (DQN) was the first reinforcement learning algorithm using deep neural network to successfully surpass human level performance in a number of Atari learning environments. However, divergent and unstable behaviour have been long standing issues in DQNs. The unstable behaviour is often characterised by overestimation in the $Q$-values, commonly referred to as the overestimation bias. To address the overestimation bias and the divergent behaviour, a number of heuristic extensions have been proposed. Notably, multi-step updates have been shown to drastically reduce unstable behaviour while improving agent's training performance. However, agents are often highly sensitive to the selection of the multi-step update horizon ($n$), and our empirical experiments show that a poorly chosen static value for $n$ can in many cases lead to worse performance than single-step DQN. Inspired by the success of $n$-step DQN and the effects that multi-step updates have on overestimation bias, this paper proposes a new algorithm that we call `Elastic Step DQN' (ES-DQN). It dynamically varies the step size horizon in multi-step updates based on the similarity of states visited. Our empirical evaluation shows that ES-DQN out-performs $n$-step with fixed $n$ updates, Double DQN and Average DQN in several OpenAI Gym environments while at the same time alleviating the overestimation bias.