 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable AI Based Diagnosis of Poisoning Attacks in Evolutionary Swarms
May 02, 2025Swarming systems, such as for example multi-drone networks, excel at cooperative tasks like monitoring, surveillance, or disaster assistance in critical environments, where autonomous agents make decentralized decisions in order to fulfill team-level objectives in a robust and efficient manner. Unfortunately, team-level coordinated strategies in the wild are vulnerable to data poisoning attacks, resulting in either inaccurate coordination or adversarial behavior among the agents. To address this challenge, we contribute a framework that investigates the effects of such data poisoning attacks, using explainable AI methods. We model the interaction among agents using evolutionary intelligence, where an optimal coalition strategically emerges to perform coordinated tasks. Then, through a rigorous evaluation, the swarm model is systematically poisoned using data manipulation attacks. We showcase the applicability of explainable AI methods to quantify the effects of poisoning on the team strategy and extract footprint characterizations that enable diagnosing. Our findings indicate that when the model is poisoned above 10%, non-optimal strategies resulting in inefficient cooperation can be identified.
* To appear in short form in Genetic and Evolutionary Computation Conference (GECCO '25 Companion), 2025
Learning in Multi-Objective Public Goods Games with Non-Linear Utilities
Aug 01, 2024



Addressing the question of how to achieve optimal decision-making under risk and uncertainty is crucial for enhancing the capabilities of artificial agents that collaborate with or support humans. In this work, we address this question in the context of Public Goods Games. We study learning in a novel multi-objective version of the Public Goods Game where agents have different risk preferences, by means of multi-objective reinforcement learning. We introduce a parametric non-linear utility function to model risk preferences at the level of individual agents, over the collective and individual reward components of the game. We study the interplay between such preference modelling and environmental uncertainty on the incentive alignment level in the game. We demonstrate how different combinations of individual preferences and environmental uncertainties sustain the emergence of cooperative patterns in non-cooperative environments (i.e., where competitive strategies are dominant), while others sustain competitive patterns in cooperative environments (i.e., where cooperative strategies are dominant).
MOMAland: A Set of Benchmarks for Multi-Objective Multi-Agent Reinforcement Learning
Jul 23, 2024



Many challenging tasks such as managing traffic systems, electricity grids, or supply chains involve complex decision-making processes that must balance multiple conflicting objectives and coordinate the actions of various independent decision-makers (DMs). One perspective for formalising and addressing such tasks is multi-objective multi-agent reinforcement learning (MOMARL). MOMARL broadens reinforcement learning (RL) to problems with multiple agents each needing to consider multiple objectives in their learning process. In reinforcement learning research, benchmarks are crucial in facilitating progress, evaluation, and reproducibility. The significance of benchmarks is underscored by the existence of numerous benchmark frameworks developed for various RL paradigms, including single-agent RL (e.g., Gymnasium), multi-agent RL (e.g., PettingZoo), and single-agent multi-objective RL (e.g., MO-Gymnasium). To support the advancement of the MOMARL field, we introduce MOMAland, the first collection of standardised environments for multi-objective multi-agent reinforcement learning. MOMAland addresses the need for comprehensive benchmarking in this emerging field, offering over 10 diverse environments that vary in the number of agents, state representations, reward structures, and utility considerations. To provide strong baselines for future research, MOMAland also includes algorithms capable of learning policies in such settings.
Divide and Conquer: Provably Unveiling the Pareto Front with Multi-Objective Reinforcement Learning
Feb 11, 2024A significant challenge in multi-objective reinforcement learning is obtaining a Pareto front of policies that attain optimal performance under different preferences. We introduce Iterated Pareto Referent Optimisation (IPRO), a principled algorithm that decomposes the task of finding the Pareto front into a sequence of single-objective problems for which various solution methods exist. This enables us to establish convergence guarantees while providing an upper bound on the distance to undiscovered Pareto optimal solutions at each step. Empirical evaluations demonstrate that IPRO matches or outperforms methods that require additional domain knowledge. By leveraging problem-specific single-objective solvers, our approach also holds promise for applications beyond multi-objective reinforcement learning, such as in pathfinding and optimisation.
Utility-Based Reinforcement Learning: Unifying Single-objective and Multi-objective Reinforcement Learning
Feb 05, 2024Research in multi-objective reinforcement learning (MORL) has introduced the utility-based paradigm, which makes use of both environmental rewards and a function that defines the utility derived by the user from those rewards. In this paper we extend this paradigm to the context of single-objective reinforcement learning (RL), and outline multiple potential benefits including the ability to perform multi-policy learning across tasks relating to uncertain objectives, risk-aware RL, discounting, and safe RL. We also examine the algorithmic implications of adopting a utility-based approach.
Emergent Cooperation under Uncertain Incentive Alignment
Jan 23, 2024Understanding the emergence of cooperation in systems of computational agents is crucial for the development of effective cooperative AI. Interaction among individuals in real-world settings are often sparse and occur within a broad spectrum of incentives, which often are only partially known. In this work, we explore how cooperation can arise among reinforcement learning agents in scenarios characterised by infrequent encounters, and where agents face uncertainty about the alignment of their incentives with those of others. To do so, we train the agents under a wide spectrum of environments ranging from fully competitive, to fully cooperative, to mixed-motives. Under this type of uncertainty we study the effects of mechanisms, such as reputation and intrinsic rewards, that have been proposed in the literature to foster cooperation in mixed-motives environments. Our findings show that uncertainty substantially lowers the agents' ability to engage in cooperative behaviour, when that would be the best course of action. In this scenario, the use of effective reputation mechanisms and intrinsic rewards boosts the agents' capability to act nearly-optimally in cooperative environments, while greatly enhancing cooperation in mixed-motive environments as well.
Exploring the Pareto front of multi-objective COVID-19 mitigation policies using reinforcement learning
Apr 11, 2022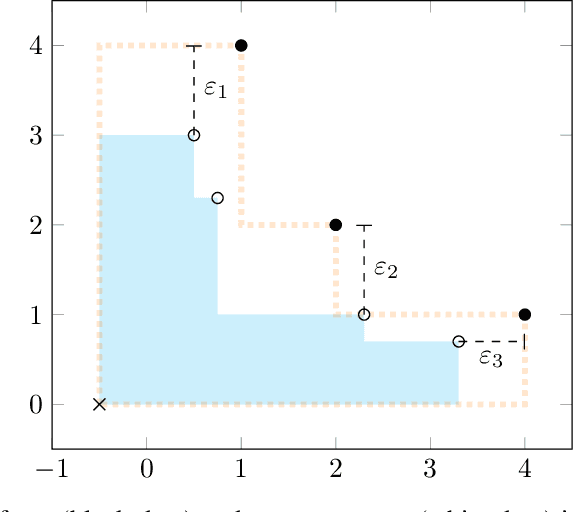

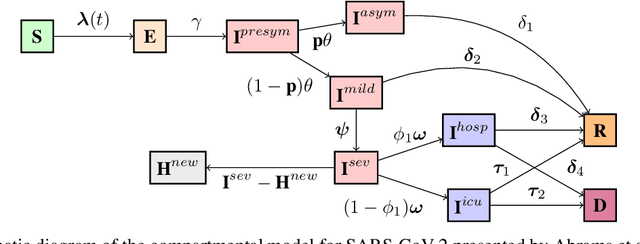
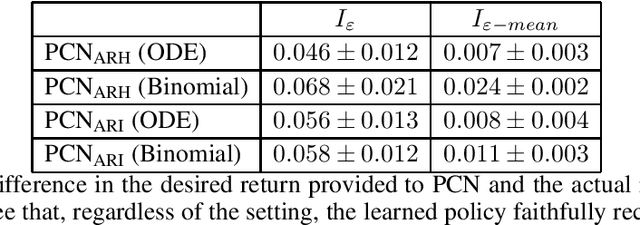
Infectious disease outbreaks can have a disruptive impact on public health and societal processes. As decision making in the context of epidemic mitigation is hard, reinforcement learning provides a methodology to automatically learn prevention strategies in combination with complex epidemic models. Current research focuses on optimizing policies w.r.t. a single objective, such as the pathogen's attack rate. However, as the mitigation of epidemics involves distinct, and possibly conflicting criteria (i.a., prevalence, mortality, morbidity, cost), a multi-objective approach is warranted to learn balanced policies. To lift this decision-making process to real-world epidemic models, we apply deep multi-objective reinforcement learning and build upon a state-of-the-art algorithm, Pareto Conditioned Networks (PCN), to learn a set of solutions that approximates the Pareto front of the decision problem. We consider the first wave of the Belgian COVID-19 epidemic, which was mitigated by a lockdown, and study different deconfinement strategies, aiming to minimize both COVID-19 cases (i.e., infections and hospitalizations) and the societal burden that is induced by the applied mitigation measures. We contribute a multi-objective Markov decision process that encapsulates the stochastic compartment model that was used to inform policy makers during the COVID-19 epidemic. As these social mitigation measures are implemented in a continuous action space that modulates the contact matrix of the age-structured epidemic model, we extend PCN to this setting. We evaluate the solution returned by PCN, and observe that it correctly learns to reduce the social burden whenever the hospitalization rates are sufficiently low. In this work, we thus show that multi-objective reinforcement learning is attainable in complex epidemiological models and provides essential insights to balance complex mitigation policies.
Preference Communication in Multi-Objective Normal-Form Games
Nov 17, 2021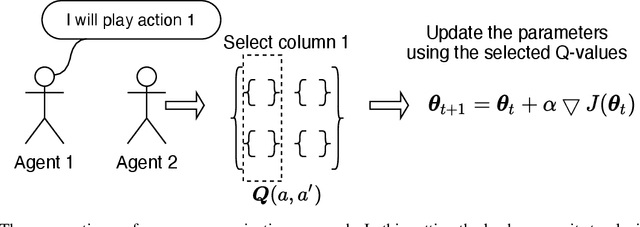
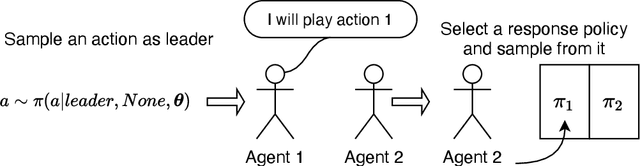

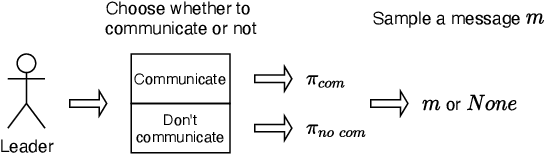
We study the problem of multiple agents learning concurrently in a multi-objective environment. Specifically, we consider two agents that repeatedly play a multi-objective normal-form game. In such games, the payoffs resulting from joint actions are vector valued. Taking a utility-based approach, we assume a utility function exists that maps vectors to scalar utilities and consider agents that aim to maximise the utility of expected payoff vectors. As agents do not necessarily know their opponent's utility function or strategy, they must learn optimal policies to interact with each other. To aid agents in arriving at adequate solutions, we introduce four novel preference communication protocols for both cooperative as well as self-interested communication. Each approach describes a specific protocol for one agent communicating preferences over their actions and how another agent responds. These protocols are subsequently evaluated on a set of five benchmark games against baseline agents that do not communicate. We find that preference communication can drastically alter the learning process and lead to the emergence of cyclic Nash equilibria which had not been previously observed in this setting. Additionally, we introduce a communication scheme where agents must learn when to communicate. For agents in games with Nash equilibria, we find that communication can be beneficial but difficult to learn when agents have different preferred equilibria. When this is not the case, agents become indifferent to communication. In games without Nash equilibria, our results show differences across learning rates. When using faster learners, we observe that explicit communication becomes more prevalent at around 50% of the time, as it helps them in learning a compromise joint policy. Slower learners retain this pattern to a lesser degree, but show increased indifference.
A Practical Guide to Multi-Objective Reinforcement Learning and Planning
Mar 17, 2021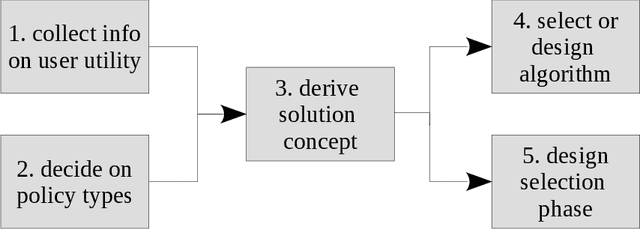

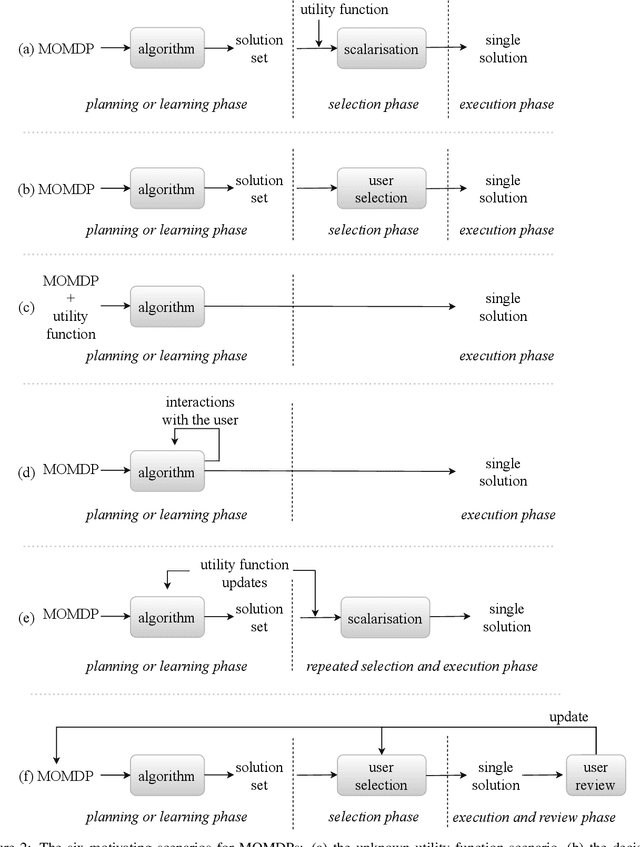
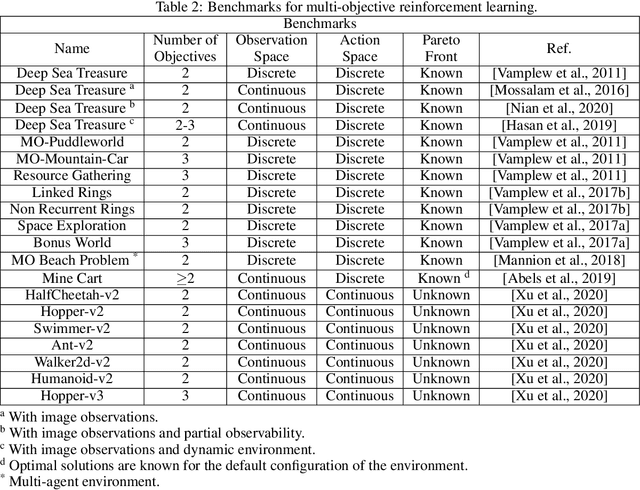
Real-world decision-making tasks are generally complex, requiring trade-offs between multiple, often conflicting, objectives. Despite this, the majority of research in reinforcement learning and decision-theoretic planning either assumes only a single objective, or that multiple objectives can be adequately handled via a simple linear combination. Such approaches may oversimplify the underlying problem and hence produce suboptimal results. This paper serves as a guide to the application of multi-objective methods to difficult problems, and is aimed at researchers who are already familiar with single-objective reinforcement learning and planning methods who wish to adopt a multi-objective perspective on their research, as well as practitioners who encounter multi-objective decision problems in practice. It identifies the factors that may influence the nature of the desired solution, and illustrates by example how these influence the design of multi-objective decision-making systems for complex problems.
Opponent Learning Awareness and Modelling in Multi-Objective Normal Form Games
Nov 14, 2020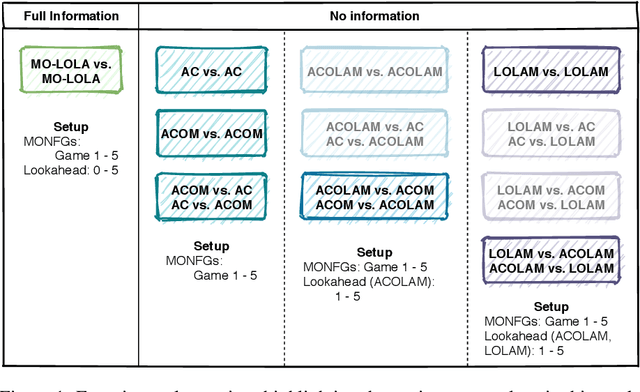
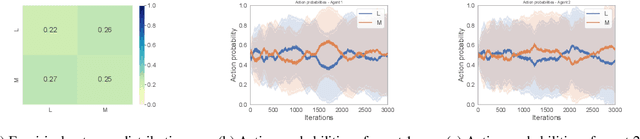
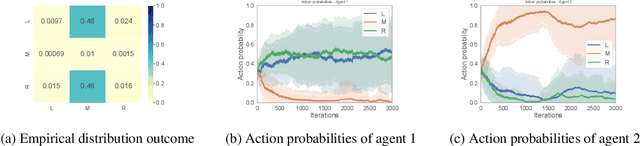
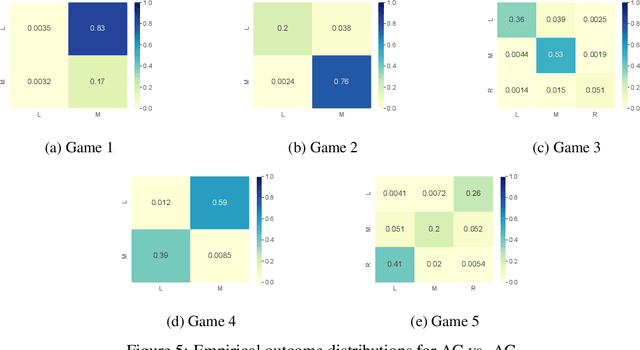
Many real-world multi-agent interactions consider multiple distinct criteria, i.e. the payoffs are multi-objective in nature. However, the same multi-objective payoff vector may lead to different utilities for each participant. Therefore, it is essential for an agent to learn about the behaviour of other agents in the system. In this work, we present the first study of the effects of such opponent modelling on multi-objective multi-agent interactions with non-linear utilities. Specifically, we consider two-player multi-objective normal form games with non-linear utility functions under the scalarised expected returns optimisation criterion. We contribute novel actor-critic and policy gradient formulations to allow reinforcement learning of mixed strategies in this setting, along with extensions that incorporate opponent policy reconstruction and learning with opponent learning awareness (i.e., learning while considering the impact of one's policy when anticipating the opponent's learning step). Empirical results in five different MONFGs demonstrate that opponent learning awareness and modelling can drastically alter the learning dynamics in this setting. When equilibria are present, opponent modelling can confer significant benefits on agents that implement it. When there are no Nash equilibria, opponent learning awareness and modelling allows agents to still converge to meaningful solutions that approximate equilibria.