 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemonstrating Cloth Folding to Robots: Design and Evaluation of a 2D and a 3D User Interface
Apr 07, 2021
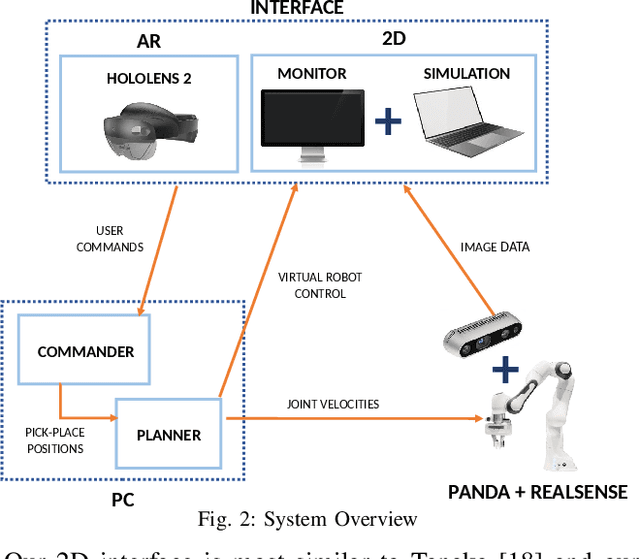
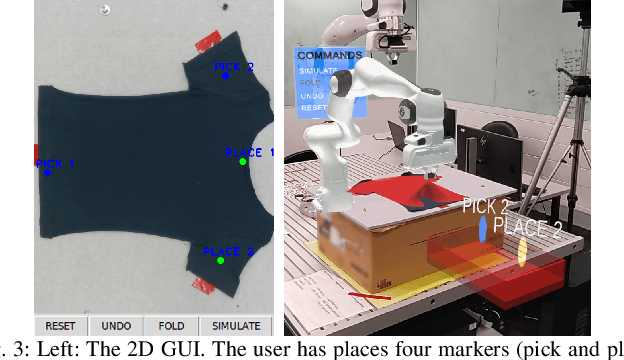
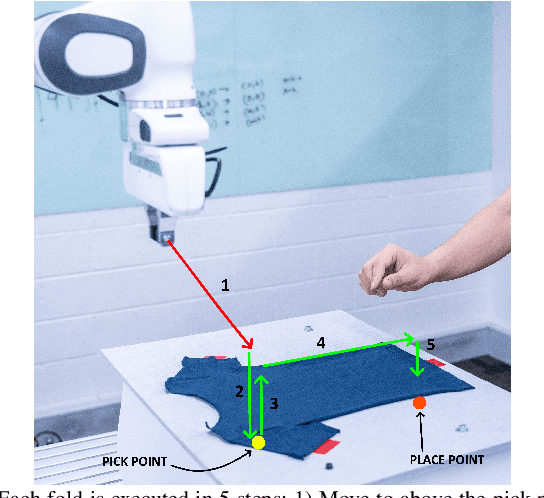
An appropriate user interface to collect human demonstration data for deformable object manipulation has been mostly overlooked in the literature. We present an interaction design for demonstrating cloth folding to robots. Users choose pick and place points on the cloth and can preview a visualization of a simulated cloth before real-robot execution. Two interfaces are proposed: A 2D display-and-mouse interface where points are placed by clicking on an image of the cloth, and a 3D Augmented Reality interface where the chosen points are placed by hand gestures. We conduct a user study with 18 participants, in which each user completed two sequential folds to achieve a cloth goal shape. Results show that while both interfaces were acceptable, the 3D interface was found to be more suitable for understanding the task, and the 2D interface suitable for repetition. Results also found that fold previews improve three key metrics: task efficiency, the ability to predict the final shape of the cloth and overall user satisfaction.
Visualizing Robot Intent for Object Handovers with Augmented Reality
Mar 06, 2021
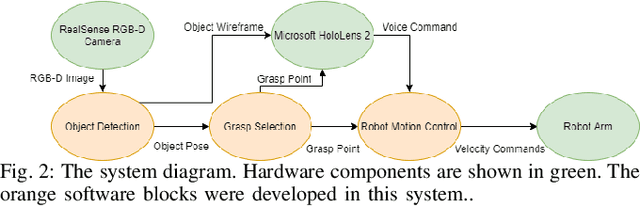

Humans are very skillful in communicating their intent for when and where a handover would occur. On the other hand, even the state-of-the-art robotic implementations for handovers display a general lack of communication skills. We propose visualizing the internal state and intent of robots for Human-to-Robot Handovers using Augmented Reality. Specifically, we visualize 3D models of the object and the robotic gripper to communicate the robot's estimation of where the object is and the pose that the robot intends to grasp the object. We conduct a user study with 16 participants, in which each participant handed over a cube-shaped object to the robot 12 times. Results show that visualizing robot intent using augmented reality substantially improves the subjective experience of the users for handovers and decreases the time to transfer the object. Results also indicate that the benefits of augmented reality are still present even when the robot makes errors in localizing the object.
Automated Iterative Training of Convolutional Neural Networks for Tree Skeleton Segmentation
Oct 16, 2020
Training of convolutional neural networks for semantic segmentation requires accurate pixel-wise labeling. Depending on the application this can require large amounts of human effort. The human-in-the-loop method reduces labeling effort but still requires human intervention for a selection of images. This paper describes a new iterative training method: Automating-the-loop. Automating-the-loop aims to replicate the human adjustment in human-in-the-loop, with an automated process. Thereby, removing human intervention during the iterative process and drastically reducing labeling effort. Using the application of segmented apple tree detection, we compare human-in-the-loop, Self Training Loop, Filtered-Self Training Loop (semi-supervised learning) and our proposed method automating-the-loop. These methods are used to train U-Net, a deep learning based convolutional neural network. The results are presented and analyzed on both traditional performance metrics and a new metric, Horizontal Scan. It is shown that the new method of automating-the-loop greatly reduces the labeling effort while generating a network with comparable performance to both human-in-the-loop and completely manual labeling.
Semantic Segmentation for Partially Occluded Apple Trees Based on Deep Learning
Oct 14, 2020
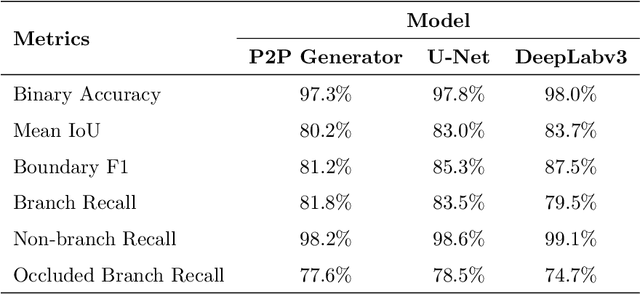


Fruit tree pruning and fruit thinning require a powerful vision system that can provide high resolution segmentation of the fruit trees and their branches. However, recent works only consider the dormant season, where there are minimal occlusions on the branches or fit a polynomial curve to reconstruct branch shape and hence, losing information about branch thickness. In this work, we apply two state-of-the-art supervised learning models U-Net and DeepLabv3, and a conditional Generative Adversarial Network Pix2Pix (with and without the discriminator) to segment partially occluded 2D-open-V apple trees. Binary accuracy, Mean IoU, Boundary F1 score and Occluded branch recall were used to evaluate the performances of the models. DeepLabv3 outperforms the other models at Binary accuracy, Mean IoU and Boundary F1 score, but is surpassed by Pix2Pix (without discriminator) and U-Net in Occluded branch recall. We define two difficulty indices to quantify the difficulty of the task: (1) Occlusion Difficulty Index and (2) Depth Difficulty Index. We analyze the worst 10 images in both difficulty indices by means of Branch Recall and Occluded Branch Recall. U-Net outperforms the other two models in the current metrics. On the other hand, Pix2Pix (without discriminator) provides more information on branch paths, which are not reflected by the metrics. This highlights the need for more specific metrics on recovering occluded information. Furthermore, this shows the usefulness of image-transfer networks for hallucination behind occlusions. Future work is required to further enhance the models to recover more information from occlusions such that this technology can be applied to automating agricultural tasks in a commercial environment.
Object-Independent Human-to-Robot Handovers using Real Time Robotic Vision
Jun 02, 2020
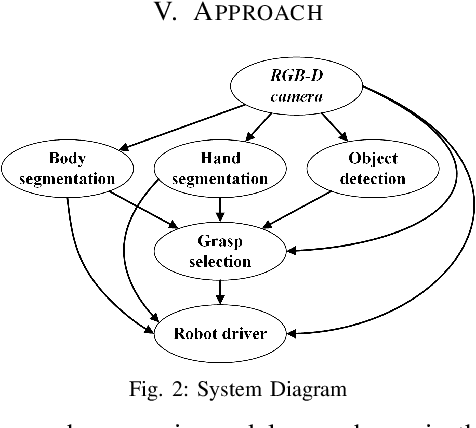
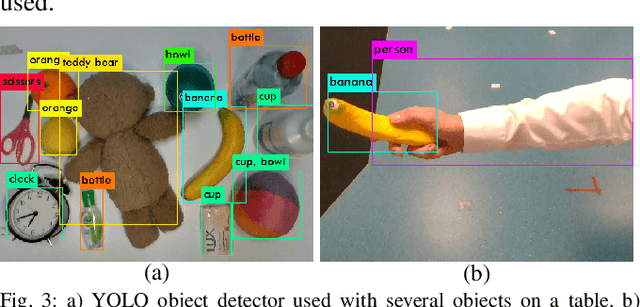

We present an approach for safe and object-independent human-to-robot handovers using real time robotic vision and manipulation. We aim for general applicability with a generic object detector, a fast grasp selection algorithm and by using a single gripper-mounted RGB-D camera, hence not relying on external sensors. The robot is controlled via visual servoing towards the object of interest. Putting a high emphasis on safety, we use two perception modules: human body part segmentation and hand/finger segmentation. Pixels that are deemed to belong to the human are filtered out from candidate grasp poses, hence ensuring that the robot safely picks the object without colliding with the human partner. The grasp selection and perception modules run concurrently in real-time, which allows monitoring of the progress. In experiments with 13 objects, the robot was able to successfully take the object from the human in 81.9% of the trials.
Supportive Actions for Manipulation in Human-Robot Coworker Teams
May 02, 2020
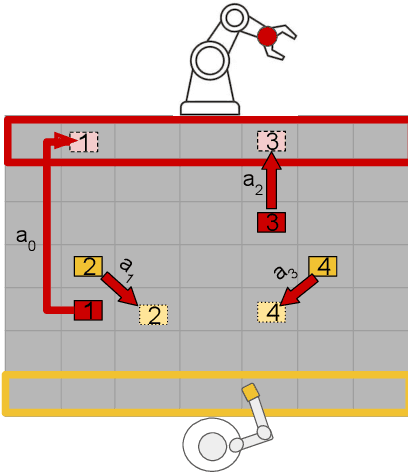
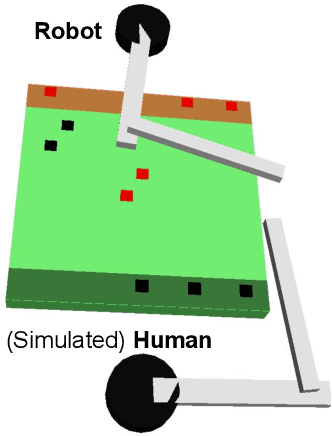

The increasing presence of robots alongside humans, such as in human-robot teams in manufacturing, gives rise to research questions about the kind of behaviors people prefer in their robot counterparts. We term actions that support interaction by reducing future interference with others as supportive robot actions and investigate their utility in a co-located manipulation scenario. We compare two robot modes in a shared table pick-and-place task: (1) Task-oriented: the robot only takes actions to further its own task objective and (2) Supportive: the robot sometimes prefers supportive actions to task-oriented ones when they reduce future goal-conflicts. Our experiments in simulation, using a simplified human model, reveal that supportive actions reduce the interference between agents, especially in more difficult tasks, but also cause the robot to take longer to complete the task. We implemented these modes on a physical robot in a user study where a human and a robot perform object placement on a shared table. Our results show that a supportive robot was perceived as a more favorable coworker by the human and also reduced interference with the human in the more difficult of two scenarios. However, it also took longer to complete the task highlighting an interesting trade-off between task-efficiency and human-preference that needs to be considered before designing robot behavior for close-proximity manipulation scenarios.
Learning to Place Objects onto Flat Surfaces in Human-Preferred Orientations
Apr 01, 2020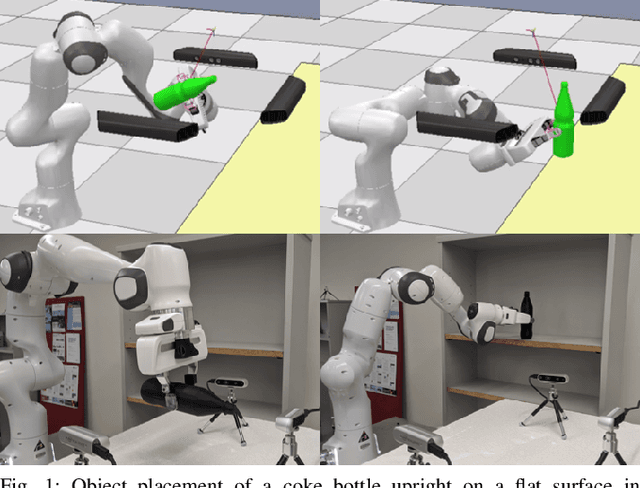
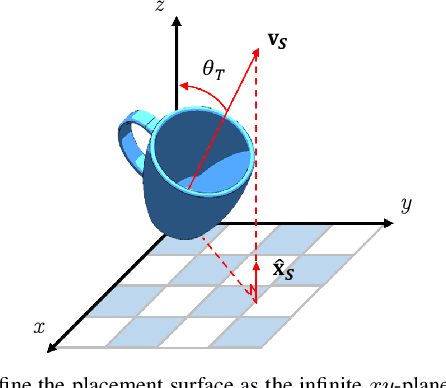
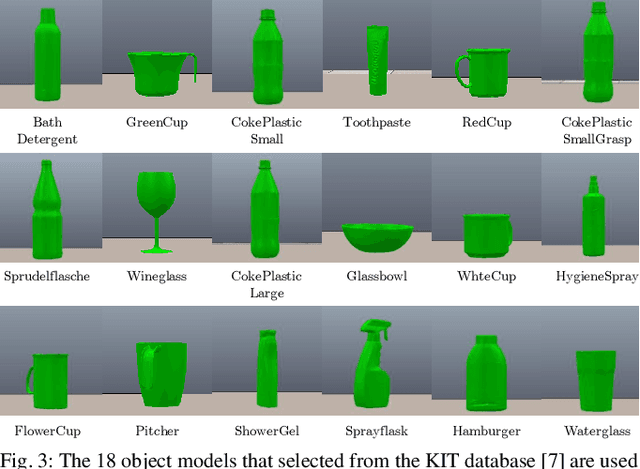
We study the problem of placing a grasped object on an empty flat surface in a human-preferred orientation, such as placing a cup on its bottom rather than on its side. We aim to find the required object rotation such that when the gripper is opened after the object makes a contact with the surface, the object would be stably placed in the desired orientation. We use two neural networks in an iterative fashion. At every iteration, Placement Rotation CNN (PR-CNN) estimates the required object rotation which is executed by the robot, and then Placement Stability CNN (PS-CNN) estimates if the object would be stable if it is placed in its current orientation. In simulation experiments, our approach places objects in human-preferred orientations with a success rate of 86.1% using a dataset of 18 everyday objects. A real-world implementation is presented, which serves as a proof-of-concept for direct sim-to-real transfer. We observe that sometimes it is impossible to place a grasped object in a desired orientation without re-grasping, which motivates future research for grasping with intention to place objects.
Learning to Take Good Pictures of People with a Robot Photographer
Apr 11, 2019

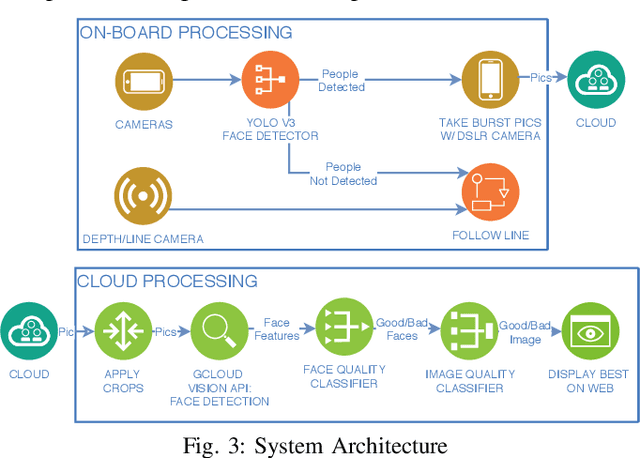

We present a robotic system capable of navigating autonomously by following a line and taking good quality pictures of people. When a group of people are detected, the robot rotates towards them and then back to line while continuously taking pictures from different angles. Each picture is processed in the cloud where its quality is estimated in a two-stage algorithm. First, features such as the face orientation and likelihood of facial emotions are input to a fully connected neural network to assign a quality score to each face. Second, a representation is extracted by abstracting faces from the image and it is input to a to Convolutional Neural Network (CNN) to classify the quality of the overall picture. We collected a dataset in which a picture was labeled as good quality if subjects are well-positioned in the image and oriented towards the camera with a pleasant expression. Our approach detected the quality of pictures with 78.4% accuracy in this dataset and received a better mean user rating (3.71/5) than a heuristic method that uses photographic composition procedures in a study where 97 human judges rated each picture. A statistical analysis against the state-of-the-art verified the quality of the resulting pictures.