 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentCollab: A Self-Evaluation-Driven Collaboration Paradigm for Efficient LLM Agents
Mar 27, 2026Autonomous agents powered by large language models (LLMs) perform complex tasks through long-horizon reasoning and tool interaction, where a fundamental trade-off arises between execution efficiency and reasoning robustness. Models at different capability-cost levels offer complementary advantages: lower-cost models enable fast execution but may struggle on difficult reasoning segments, while stronger models provide more robust reasoning at higher computational cost. We present AgentCollab, a self-driven collaborative inference framework that dynamically coordinates models with different reasoning capacities during agent execution. Instead of relying on external routing modules, the framework uses the agent's own self-reflection signal to determine whether the current reasoning trajectory is making meaningful progress, and escalates control to a stronger reasoning tier only when necessary. To further stabilize long-horizon execution, we introduce a difficulty-aware cumulative escalation strategy that allocates additional reasoning budget based on recent failure signals. In our experiments, we instantiate this framework using a two-level small-large model setting. Experiments on diverse multi-step agent benchmarks show that AgentCollab consistently improves the accuracy-efficiency Pareto frontier of LLM agents.
DLLM Agent: See Farther, Run Faster
Feb 07, 2026Diffusion large language models (DLLMs) have emerged as an alternative to autoregressive (AR) decoding with appealing efficiency and modeling properties, yet their implications for agentic multi-step decision making remain underexplored. We ask a concrete question: when the generation paradigm is changed but the agent framework and supervision are held fixed, do diffusion backbones induce systematically different planning and tool-use behaviors, and do these differences translate into end-to-end efficiency gains? We study this in a controlled setting by instantiating DLLM and AR backbones within the same agent workflow (DeepDiver) and performing matched agent-oriented fine-tuning on the same trajectory data, yielding diffusion-backed DLLM Agents and directly comparable AR agents. Across benchmarks and case studies, we find that, at comparable accuracy, DLLM Agents are on average over 30% faster end to end than AR agents, with some cases exceeding 8x speedup. Conditioned on correct task completion, DLLM Agents also require fewer interaction rounds and tool invocations, consistent with higher planner hit rates that converge earlier to a correct action path with less backtracking. We further identify two practical considerations for deploying diffusion backbones in tool-using agents. First, naive DLLM policies are more prone to structured tool-call failures, necessitating stronger tool-call-specific training to emit valid schemas and arguments. Second, for multi-turn inputs interleaving context and action spans, diffusion-style span corruption requires aligned attention masking to avoid spurious context-action information flow; without such alignment, performance degrades. Finally, we analyze attention dynamics across workflow stages and observe paradigm-specific coordination patterns, suggesting stronger global planning signals in diffusion-backed agents.
Revisiting Judge Decoding from First Principles via Training-Free Distributional Divergence
Jan 08, 2026Judge Decoding accelerates LLM inference by relaxing the strict verification of Speculative Decoding, yet it typically relies on expensive and noisy supervision. In this work, we revisit this paradigm from first principles, revealing that the ``criticality'' scores learned via costly supervision are intrinsically encoded in the draft-target distributional divergence. We theoretically prove a structural correspondence between learned linear judges and Kullback-Leibler (KL) divergence, demonstrating they rely on the same underlying logit primitives. Guided by this, we propose a simple, training-free verification mechanism based on KL divergence. Extensive experiments across reasoning and coding benchmarks show that our method matches or outperforms complex trained judges (e.g., AutoJudge), offering superior robustness to domain shifts and eliminating the supervision bottleneck entirely.
Towards Efficient Agents: A Co-Design of Inference Architecture and System
Dec 20, 2025The rapid development of large language model (LLM)-based agents has unlocked new possibilities for autonomous multi-turn reasoning and tool-augmented decision-making. However, their real-world deployment is hindered by severe inefficiencies that arise not from isolated model inference, but from the systemic latency accumulated across reasoning loops, context growth, and heterogeneous tool interactions. This paper presents AgentInfer, a unified framework for end-to-end agent acceleration that bridges inference optimization and architectural design. We decompose the problem into four synergistic components: AgentCollab, a hierarchical dual-model reasoning framework that balances large- and small-model usage through dynamic role assignment; AgentSched, a cache-aware hybrid scheduler that minimizes latency under heterogeneous request patterns; AgentSAM, a suffix-automaton-based speculative decoding method that reuses multi-session semantic memory to achieve low-overhead inference acceleration; and AgentCompress, a semantic compression mechanism that asynchronously distills and reorganizes agent memory without disrupting ongoing reasoning. Together, these modules form a Self-Evolution Engine capable of sustaining efficiency and cognitive stability throughout long-horizon reasoning tasks. Experiments on the BrowseComp-zh and DeepDiver benchmarks demonstrate that through the synergistic collaboration of these methods, AgentInfer reduces ineffective token consumption by over 50%, achieving an overall 1.8-2.5 times speedup with preserved accuracy. These results underscore that optimizing for agentic task completion-rather than merely per-token throughput-is the key to building scalable, efficient, and self-improving intelligent systems.
DeePKS+ABACUS as a Bridge between Expensive Quantum Mechanical Models and Machine Learning Potentials
Jun 21, 2022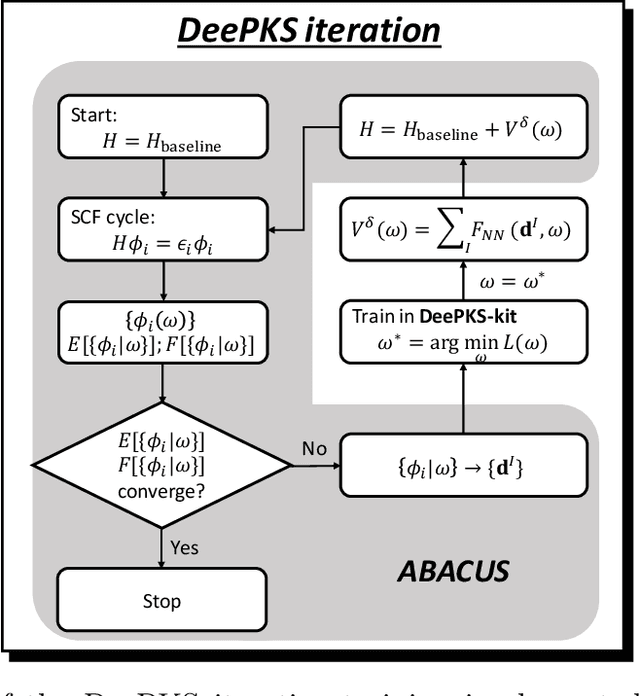
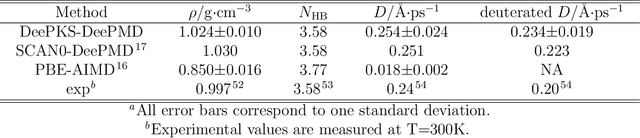
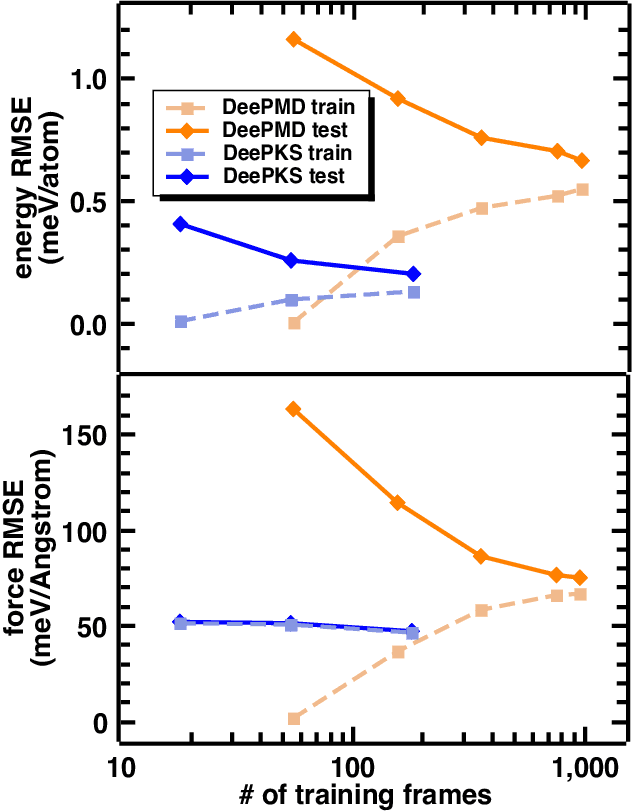
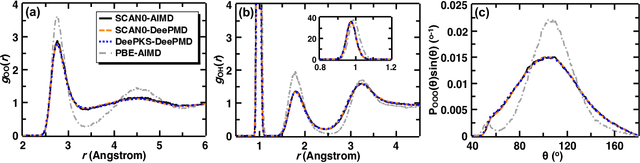
Recently, the development of machine learning (ML) potentials has made it possible to perform large-scale and long-time molecular simulations with the accuracy of quantum mechanical (QM) models. However, for high-level QM methods, such as density functional theory (DFT) at the meta-GGA level and/or with exact exchange, quantum Monte Carlo, etc., generating a sufficient amount of data for training a ML potential has remained computationally challenging due to their high cost. In this work, we demonstrate that this issue can be largely alleviated with Deep Kohn-Sham (DeePKS), a ML-based DFT model. DeePKS employs a computationally efficient neural network-based functional model to construct a correction term added upon a cheap DFT model. Upon training, DeePKS offers closely-matched energies and forces compared with high-level QM method, but the number of training data required is orders of magnitude less than that required for training a reliable ML potential. As such, DeePKS can serve as a bridge between expensive QM models and ML potentials: one can generate a decent amount of high-accuracy QM data to train a DeePKS model, and then use the DeePKS model to label a much larger amount of configurations to train a ML potential. This scheme for periodic systems is implemented in a DFT package ABACUS, which is open-source and ready for use in various applications.