 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical SAM Adapter: Adapting Segment Anything Model for Medical Image Segmentation
May 11, 2023


The Segment Anything Model (SAM) has recently gained popularity in the field of image segmentation. Thanks to its impressive capabilities in all-round segmentation tasks and its prompt-based interface, SAM has sparked intensive discussion within the community. It is even said by many prestigious experts that image segmentation task has been "finished" by SAM. However, medical image segmentation, although an important branch of the image segmentation family, seems not to be included in the scope of Segmenting "Anything". Many individual experiments and recent studies have shown that SAM performs subpar in medical image segmentation. A natural question is how to find the missing piece of the puzzle to extend the strong segmentation capability of SAM to medical image segmentation. In this paper, instead of fine-tuning the SAM model, we propose Med SAM Adapter, which integrates the medical specific domain knowledge to the segmentation model, by a simple yet effective adaptation technique. Although this work is still one of a few to transfer the popular NLP technique Adapter to computer vision cases, this simple implementation shows surprisingly good performance on medical image segmentation. A medical image adapted SAM, which we have dubbed Medical SAM Adapter (MSA), shows superior performance on 19 medical image segmentation tasks with various image modalities including CT, MRI, ultrasound image, fundus image, and dermoscopic images. MSA outperforms a wide range of state-of-the-art (SOTA) medical image segmentation methods, such as nnUNet, TransUNet, UNetr, MedSegDiff, and also outperforms the fully fine-turned MedSAM with a considerable performance gap. Code will be released at: https://github.com/WuJunde/Medical-SAM-Adapter.
Optimal Virtual Tube Planning and Control for Swarm Robotics
Apr 22, 2023This paper presents a novel method for efficiently solving trajectory planning problems for swarm robotics in cluttered environments. While recent research has demonstrated high success rates in real-time local trajectory planning for swarm robotics in cluttered environments, optimizing every trajectory for each robot is computationally expensive, with a computational complexity of $O\left(n^2\right)$ to $ O\left(n^3\right)$. To address this issue, we first propose the concept of the \emph{optimal virtual tube}, which includes infinite optimal trajectories. Under certain conditions, any optimal trajectory in the optimal virtual tube can be expressed as a convex combination of a finite number of optimal trajectories, with a computational complexity of $O\left(1\right)$. Afterward, a planning method of \emph{the optimal virtual tube} is proposed. In simulations and experiments, we show that the proposed method efficiently reduces calculation and is validated by comparison with traditional methods.
TextCraft: Zero-Shot Generation of High-Fidelity and Diverse Shapes from Text
Nov 04, 2022



Language is one of the primary means by which we describe the 3D world around us. While rapid progress has been made in text-to-2D-image synthesis, similar progress in text-to-3D-shape synthesis has been hindered by the lack of paired (text, shape) data. Moreover, extant methods for text-to-shape generation have limited shape diversity and fidelity. We introduce TextCraft, a method to address these limitations by producing high-fidelity and diverse 3D shapes without the need for (text, shape) pairs for training. TextCraft achieves this by using CLIP and using a multi-resolution approach by first generating in a low-dimensional latent space and then upscaling to a higher resolution, improving the fidelity of the generated shape. To improve shape diversity, we use a discrete latent space which is modelled using a bidirectional transformer conditioned on the interchangeable image-text embedding space induced by CLIP. Moreover, we present a novel variant of classifier-free guidance, which further improves the accuracy-diversity trade-off. Finally, we perform extensive experiments that demonstrate that TextCraft outperforms state-of-the-art baselines.
An Efficient Person Clustering Algorithm for Open Checkout-free Groceries
Aug 05, 2022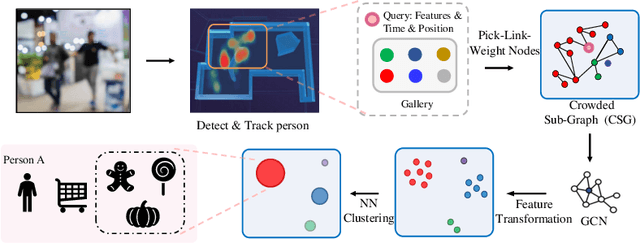

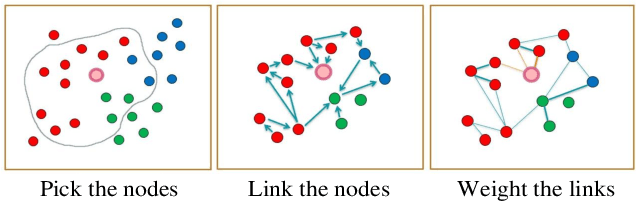
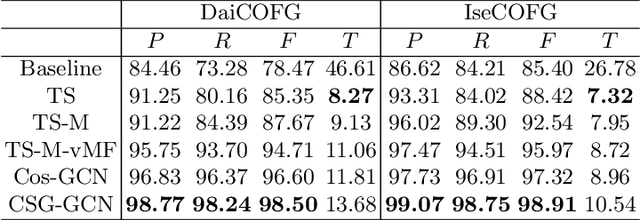
Open checkout-free grocery is the grocery store where the customers never have to wait in line to check out. Developing a system like this is not trivial since it faces challenges of recognizing the dynamic and massive flow of people. In particular, a clustering method that can efficiently assign each snapshot to the corresponding customer is essential for the system. In order to address the unique challenges in the open checkout-free grocery, we propose an efficient and effective person clustering method. Specifically, we first propose a Crowded Sub-Graph (CSG) to localize the relationship among massive and continuous data streams. CSG is constructed by the proposed Pick-Link-Weight (PLW) strategy, which \textbf{picks} the nodes based on time-space information, \textbf{links} the nodes via trajectory information, and \textbf{weighs} the links by the proposed von Mises-Fisher (vMF) similarity metric. Then, to ensure that the method adapts to the dynamic and unseen person flow, we propose Graph Convolutional Network (GCN) with a simple Nearest Neighbor (NN) strategy to accurately cluster the instances of CSG. GCN is adopted to project the features into low-dimensional separable space, and NN is able to quickly produce a result in this space upon dynamic person flow. The experimental results show that the proposed method outperforms other alternative algorithms in this scenario. In practice, the whole system has been implemented and deployed in several real-world open checkout-free groceries.
ShapeCrafter: A Recursive Text-Conditioned 3D Shape Generation Model
Jul 19, 2022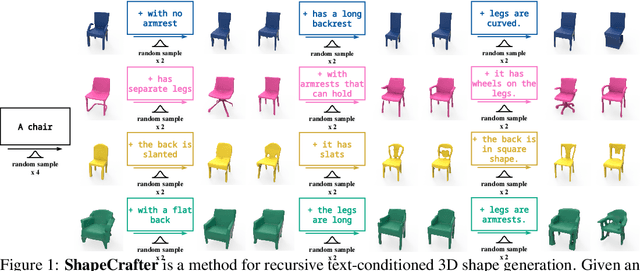

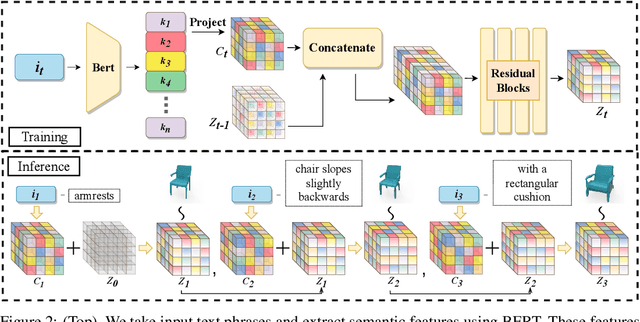

We present ShapeCrafter, a neural network for recursive text-conditioned 3D shape generation. Existing methods to generate text-conditioned 3D shapes consume an entire text prompt to generate a 3D shape in a single step. However, humans tend to describe shapes recursively-we may start with an initial description and progressively add details based on intermediate results. To capture this recursive process, we introduce a method to generate a 3D shape distribution, conditioned on an initial phrase, that gradually evolves as more phrases are added. Since existing datasets are insufficient for training this approach, we present Text2Shape++, a large dataset of 369K shape-text pairs that supports recursive shape generation. To capture local details that are often used to refine shape descriptions, we build on top of vector-quantized deep implicit functions that generate a distribution of high-quality shapes. Results show that our method can generate shapes consistent with text descriptions, and shapes evolve gradually as more phrases are added. Our method supports shape editing, extrapolation, and can enable new applications in human-machine collaboration for creative design.
NeuralODF: Learning Omnidirectional Distance Fields for 3D Shape Representation
Jun 12, 2022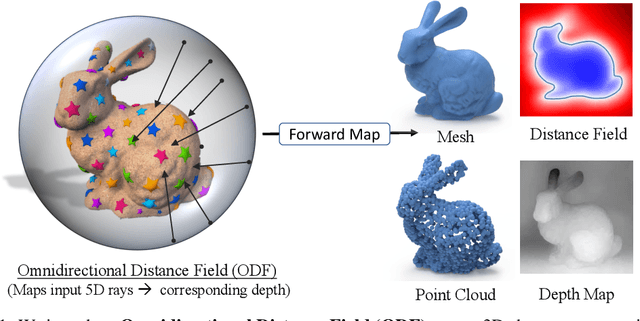

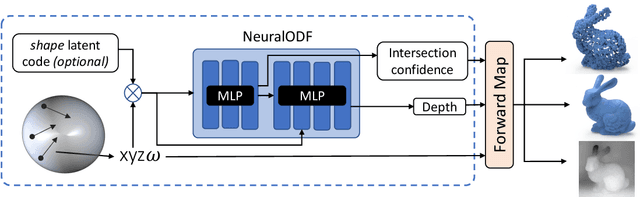
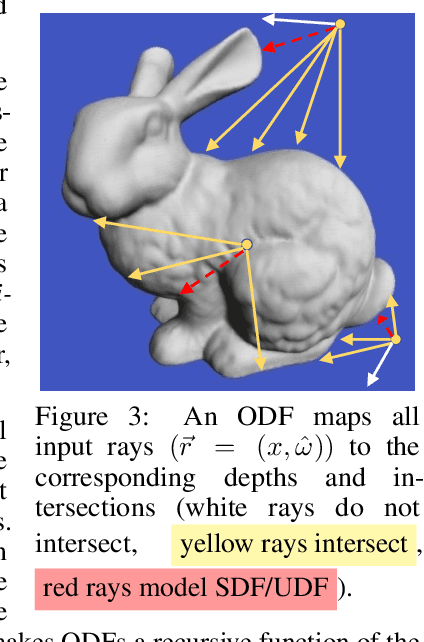
In visual computing, 3D geometry is represented in many different forms including meshes, point clouds, voxel grids, level sets, and depth images. Each representation is suited for different tasks thus making the transformation of one representation into another (forward map) an important and common problem. We propose Omnidirectional Distance Fields (ODFs), a new 3D shape representation that encodes geometry by storing the depth to the object's surface from any 3D position in any viewing direction. Since rays are the fundamental unit of an ODF, it can be used to easily transform to and from common 3D representations like meshes or point clouds. Different from level set methods that are limited to representing closed surfaces, ODFs are unsigned and can thus model open surfaces (e.g., garments). We demonstrate that ODFs can be effectively learned with a neural network (NeuralODF) despite the inherent discontinuities at occlusion boundaries. We also introduce efficient forward mapping algorithms for transforming ODFs to and from common 3D representations. Specifically, we introduce an efficient Jumping Cubes algorithm for generating meshes from ODFs. Experiments demonstrate that NeuralODF can learn to capture high-quality shape by overfitting to a single object, and also learn to generalize on common shape categories.
Practical Distributed Control for Cooperative Multicopters in Structured Free Flight Concepts
Nov 22, 2021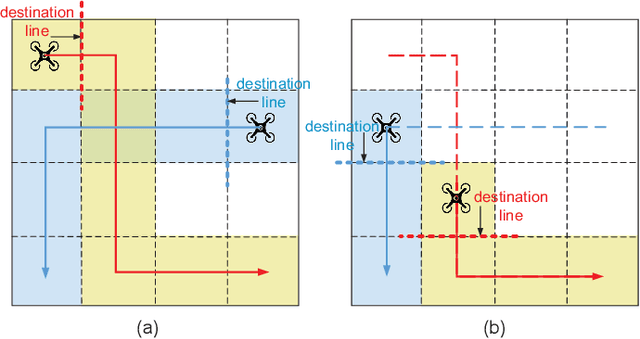
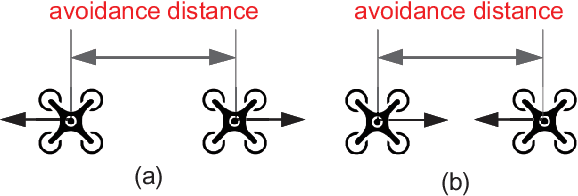

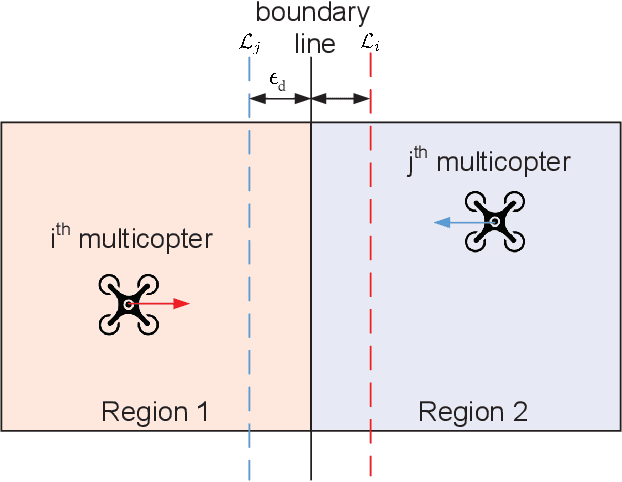
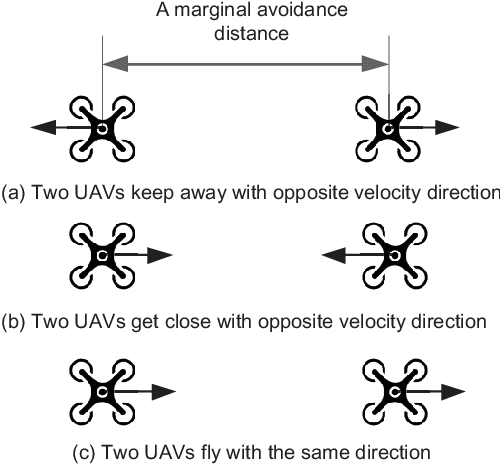
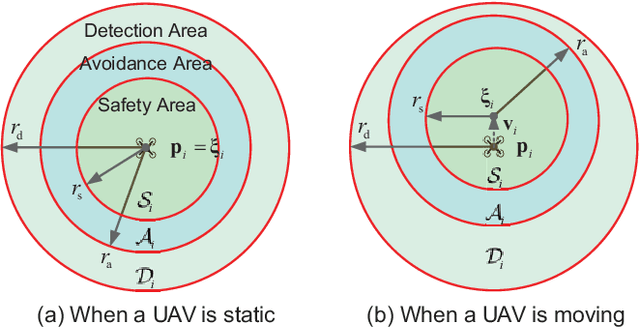
Unmanned Aerial Vehicles (UAVs) are now becoming increasingly accessible to amateur and com-mercial users alike. Several types of airspace structures are proposed in recent research, which include several structured free flight concepts. In this paper, for simplic-ity, distributed coordinating the motions of multicopters in structured airspace concepts is focused. This is formulated as a free flight problem, which includes convergence to destination lines and inter-agent collision avoidance. The destination line of each multicopter is known a priori. Further, Lyapunov-like functions are designed elaborately, and formal analysis and proofs of the proposed distributed control are made to show that the free flight control problem can be solved. What is more, by the proposed controller, a multicopter can keep away from another as soon as possible, once it enters into the safety area of another one. Simulations and experiments are given to show the effectiveness of the proposed method.
HRFormer: High-Resolution Transformer for Dense Prediction
Nov 07, 2021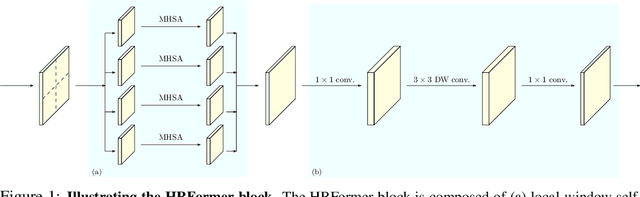
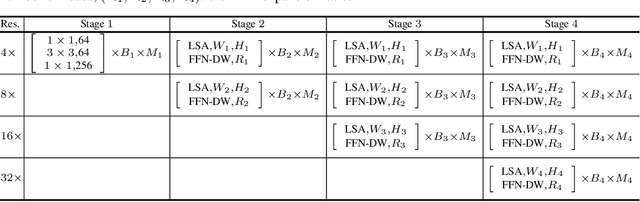


We present a High-Resolution Transformer (HRFormer) that learns high-resolution representations for dense prediction tasks, in contrast to the original Vision Transformer that produces low-resolution representations and has high memory and computational cost. We take advantage of the multi-resolution parallel design introduced in high-resolution convolutional networks (HRNet), along with local-window self-attention that performs self-attention over small non-overlapping image windows, for improving the memory and computation efficiency. In addition, we introduce a convolution into the FFN to exchange information across the disconnected image windows. We demonstrate the effectiveness of the High-Resolution Transformer on both human pose estimation and semantic segmentation tasks, e.g., HRFormer outperforms Swin transformer by $1.3$ AP on COCO pose estimation with $50\%$ fewer parameters and $30\%$ fewer FLOPs. Code is available at: https://github.com/HRNet/HRFormer.
How Far Two UAVs Should Be subject to Communication Uncertainties
Oct 18, 2021
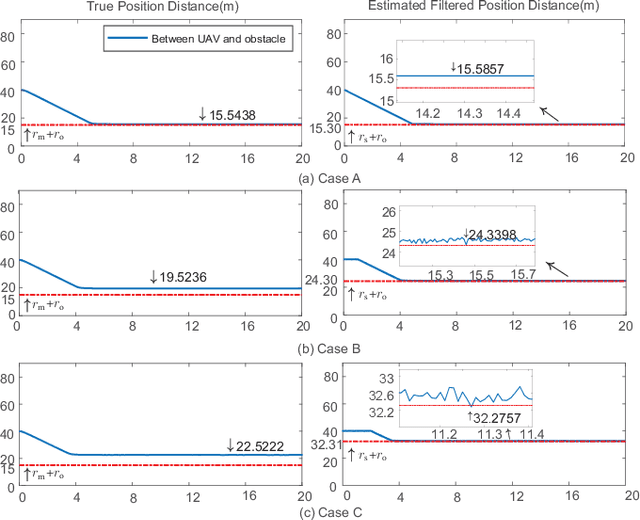
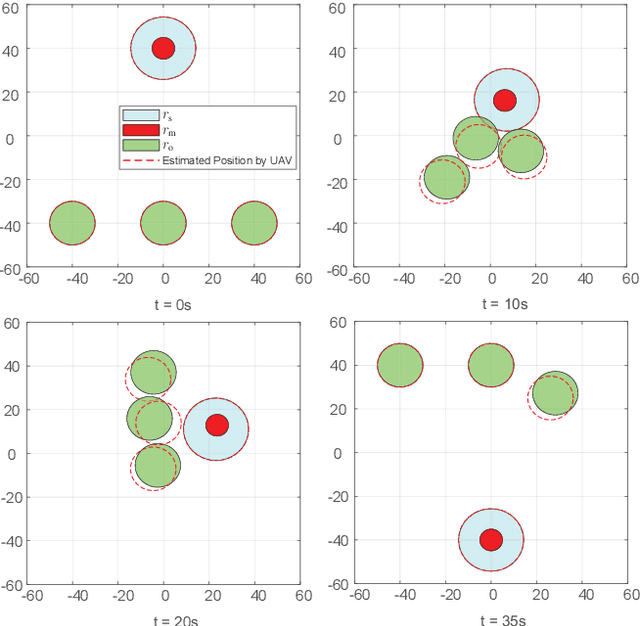
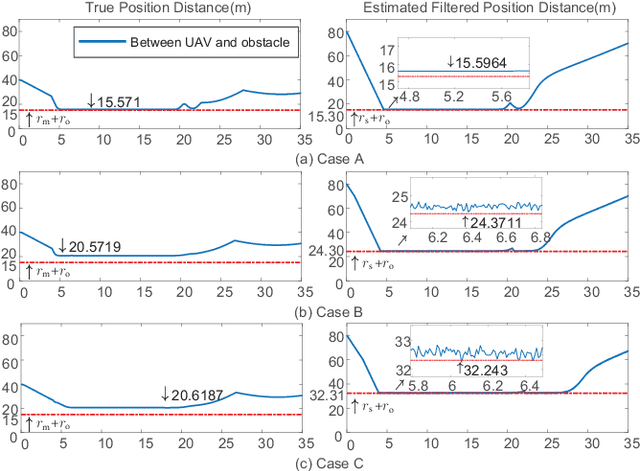
Unmanned aerial vehicles are now becoming increasingly accessible to amateur and commercial users alike. A safety air traffic management system is needed to help ensure that every newest entrant into the sky does not collide with others. Much research has been done to design various methods to perform collision avoidance with obstacles. However, how to decide the safety radius subject to communication uncertainties is still suspended. Based on assumptions on communication uncertainties and supposed control performance, a separation principle of the safety radius design and controller design is proposed. With it, the safety radius corresponding to the safety area in the design phase (without uncertainties) and flight phase (subject to uncertainties) are studied. Furthermore, the results are extended to multiple obstacles. Simulations and experiments are carried out to show the effectiveness of the proposed methods.
Practical Distributed Control for VTOL UAVs to Pass a Tunnel
Jan 19, 2021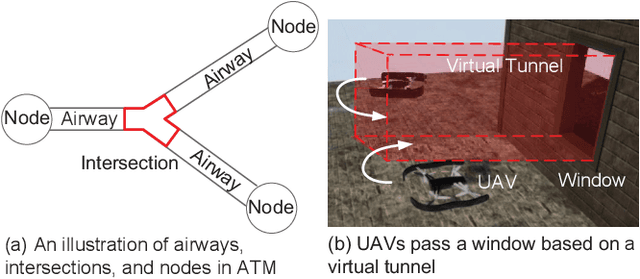
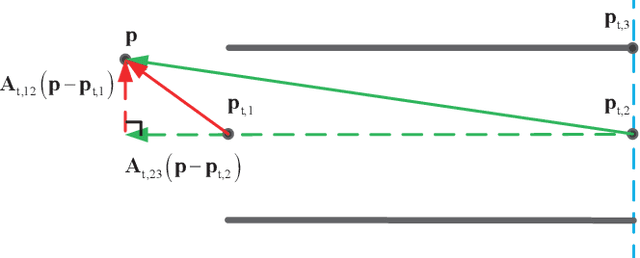
Unmanned Aerial Vehicles (UAVs) are now becoming increasingly accessible to amateur and commercial users alike. An air traffic management (ATM) system is needed to help ensure that this newest entrant into the skies does not collide with others. In an ATM, airspace can be composed of airways, intersections and nodes. In this paper, for simplicity, distributed coordinating the motions of Vertical TakeOff and Landing (VTOL) UAVs to pass an airway is focused. This is formulated as a tunnel passing problem, which includes passing a tunnel, inter-agent collision avoidance and keeping within the tunnel. Lyapunov-like functions are designed elaborately, and formal analysis based on invariant set theorem is made to show that all UAVs can pass the tunnel without getting trapped, avoid collision and keep within the tunnel. What is more, by the proposed distributed control, a VTOL UAV can keep away from another VTOL UAV or return back to the tunnel as soon as possible, once it enters into the safety area of another or has a collision with the tunnel during it is passing the tunnel. Simulations and experiments are carried out to show the effectiveness of the proposed method and the comparison with other methods.