 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRan Zhang
Deep-Learning Tool for Early Identifying Non-Traumatic Intracranial Hemorrhage Etiology based on CT Scan
Feb 02, 2023
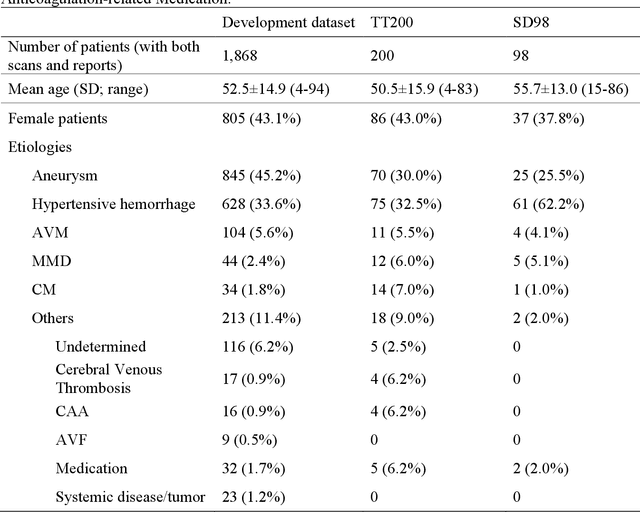
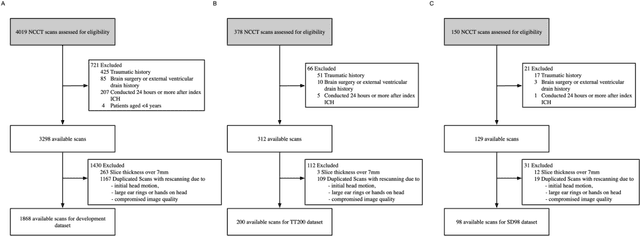
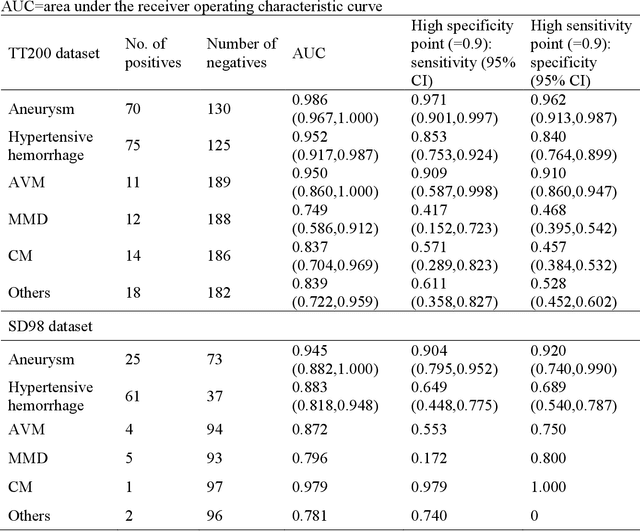
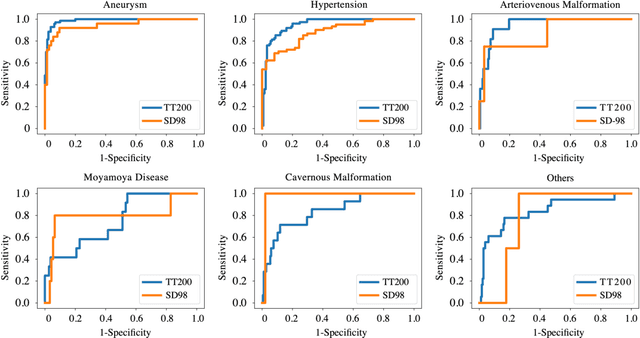
Background: To develop an artificial intelligence system that can accurately identify acute non-traumatic intracranial hemorrhage (ICH) etiology based on non-contrast CT (NCCT) scans and investigate whether clinicians can benefit from it in a diagnostic setting. Materials and Methods: The deep learning model was developed with 1868 eligible NCCT scans with non-traumatic ICH collected between January 2011 and April 2018. We tested the model on two independent datasets (TT200 and SD 98) collected after April 2018. The model's diagnostic performance was compared with clinicians's performance. We further designed a simulated study to compare the clinicians's performance with and without the deep learning system augmentation. Results: The proposed deep learning system achieved area under the receiver operating curve of 0.986 (95% CI 0.967-1.000) on aneurysms, 0.952 (0.917-0.987) on hypertensive hemorrhage, 0.950 (0.860-1.000) on arteriovenous malformation (AVM), 0.749 (0.586-0.912) on Moyamoya disease (MMD), 0.837 (0.704-0.969) on cavernous malformation (CM), and 0.839 (0.722-0.959) on other causes in TT200 dataset. Given a 90% specificity level, the sensitivities of our model were 97.1% and 90.9% for aneurysm and AVM diagnosis, respectively. The model also shows an impressive generalizability in an independent dataset SD98. The clinicians achieve significant improvements in the sensitivity, specificity, and accuracy of diagnoses of certain hemorrhage etiologies with proposed system augmentation. Conclusions: The proposed deep learning algorithms can be an effective tool for early identification of hemorrhage etiologies based on NCCT scans. It may also provide more information for clinicians for triage and further imaging examination selection.
SAGE: Saliency-Guided Mixup with Optimal Rearrangements
Oct 31, 2022

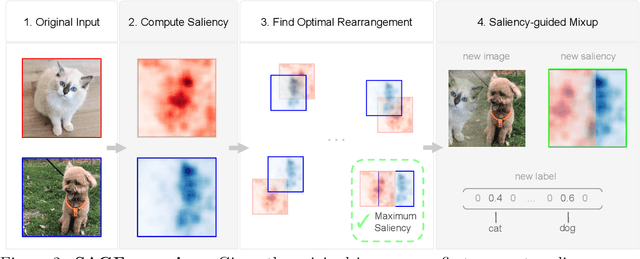
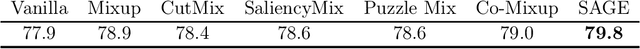
Data augmentation is a key element for training accurate models by reducing overfitting and improving generalization. For image classification, the most popular data augmentation techniques range from simple photometric and geometrical transformations, to more complex methods that use visual saliency to craft new training examples. As augmentation methods get more complex, their ability to increase the test accuracy improves, yet, such methods become cumbersome, inefficient and lead to poor out-of-domain generalization, as we show in this paper. This motivates a new augmentation technique that allows for high accuracy gains while being simple, efficient (i.e., minimal computation overhead) and generalizable. To this end, we introduce Saliency-Guided Mixup with Optimal Rearrangements (SAGE), which creates new training examples by rearranging and mixing image pairs using visual saliency as guidance. By explicitly leveraging saliency, SAGE promotes discriminative foreground objects and produces informative new images useful for training. We demonstrate on CIFAR-10 and CIFAR-100 that SAGE achieves better or comparable performance to the state of the art while being more efficient. Additionally, evaluations in the out-of-distribution setting, and few-shot learning on mini-ImageNet, show that SAGE achieves improved generalization performance without trading off robustness.
A Generalizable Artificial Intelligence Model for COVID-19 Classification Task Using Chest X-ray Radiographs: Evaluated Over Four Clinical Datasets with 15,097 Patients
Oct 04, 2022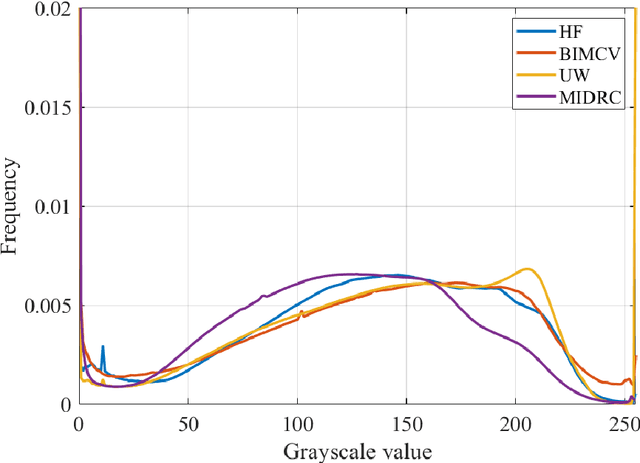
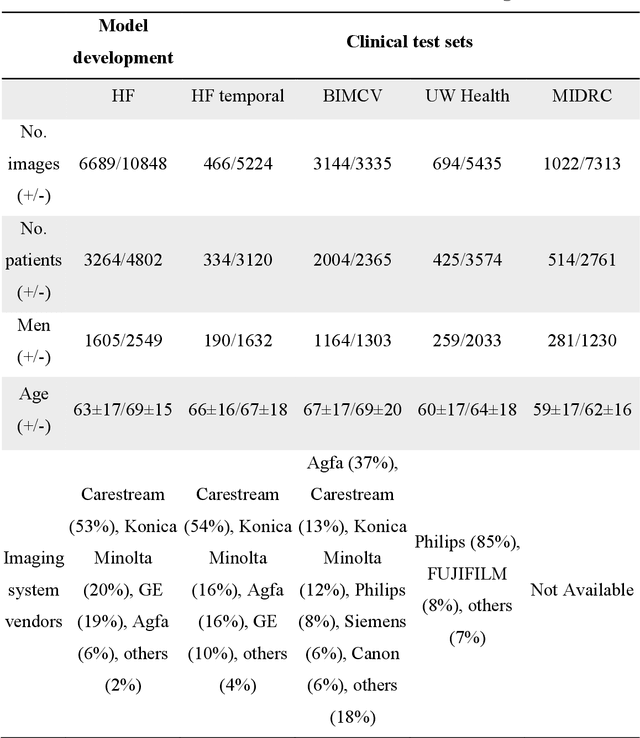
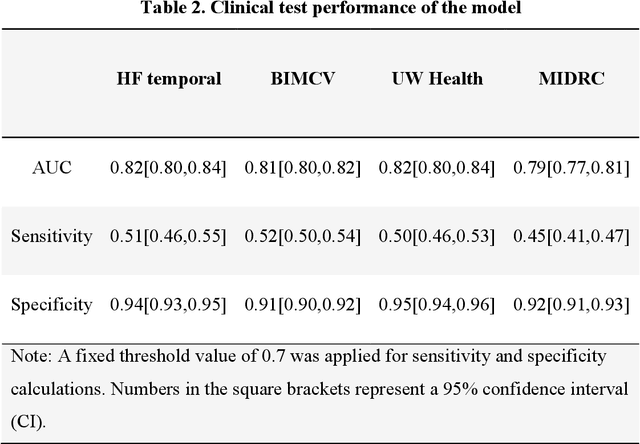
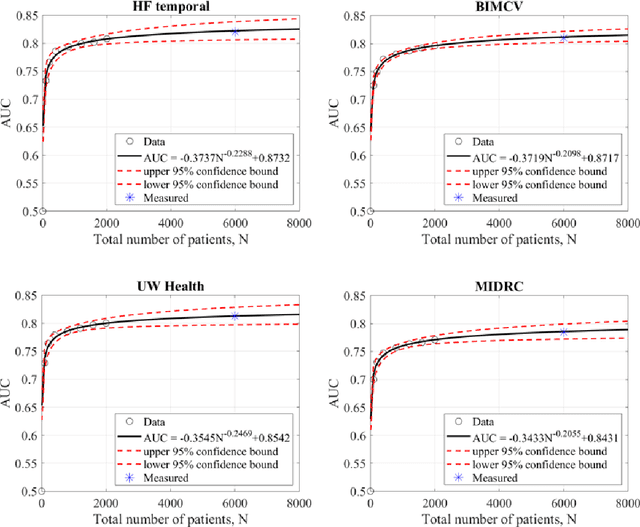
Purpose: To answer the long-standing question of whether a model trained from a single clinical site can be generalized to external sites. Materials and Methods: 17,537 chest x-ray radiographs (CXRs) from 3,264 COVID-19-positive patients and 4,802 COVID-19-negative patients were collected from a single site for AI model development. The generalizability of the trained model was retrospectively evaluated using four different real-world clinical datasets with a total of 26,633 CXRs from 15,097 patients (3,277 COVID-19-positive patients). The area under the receiver operating characteristic curve (AUC) was used to assess diagnostic performance. Results: The AI model trained using a single-source clinical dataset achieved an AUC of 0.82 (95% CI: 0.80, 0.84) when applied to the internal temporal test set. When applied to datasets from two external clinical sites, an AUC of 0.81 (95% CI: 0.80, 0.82) and 0.82 (95% CI: 0.80, 0.84) were achieved. An AUC of 0.79 (95% CI: 0.77, 0.81) was achieved when applied to a multi-institutional COVID-19 dataset collected by the Medical Imaging and Data Resource Center (MIDRC). A power-law dependence, N^(k )(k is empirically found to be -0.21 to -0.25), indicates a relatively weak performance dependence on the training data sizes. Conclusion: COVID-19 classification AI model trained using well-curated data from a single clinical site is generalizable to external clinical sites without a significant drop in performance.
Counterbalancing Teacher: Regularizing Batch Normalized Models for Robustness
Jul 04, 2022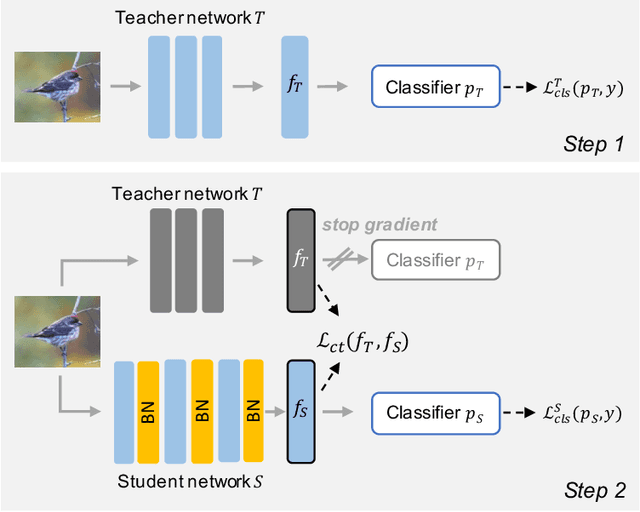
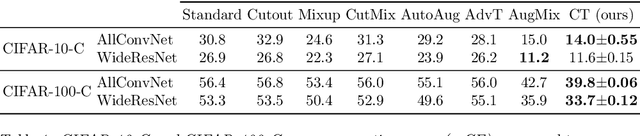
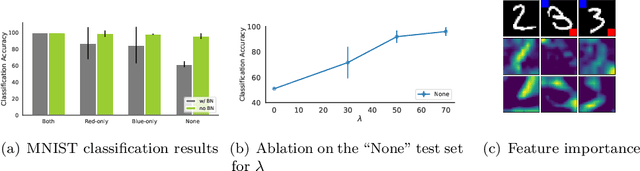
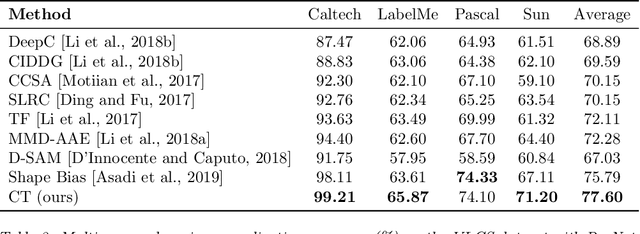
Batch normalization (BN) is a ubiquitous technique for training deep neural networks that accelerates their convergence to reach higher accuracy. However, we demonstrate that BN comes with a fundamental drawback: it incentivizes the model to rely on low-variance features that are highly specific to the training (in-domain) data, hurting generalization performance on out-of-domain examples. In this work, we investigate this phenomenon by first showing that removing BN layers across a wide range of architectures leads to lower out-of-domain and corruption errors at the cost of higher in-domain errors. We then propose Counterbalancing Teacher (CT), a method which leverages a frozen copy of the same model without BN as a teacher to enforce the student network's learning of robust representations by substantially adapting its weights through a consistency loss function. This regularization signal helps CT perform well in unforeseen data shifts, even without information from the target domain as in prior works. We theoretically show in an overparameterized linear regression setting why normalization leads to a model's reliance on such in-domain features, and empirically demonstrate the efficacy of CT by outperforming several baselines on robustness benchmarks such as CIFAR-10-C, CIFAR-100-C, and VLCS.
Uncertainty-based Cross-Modal Retrieval with Probabilistic Representations
Apr 20, 2022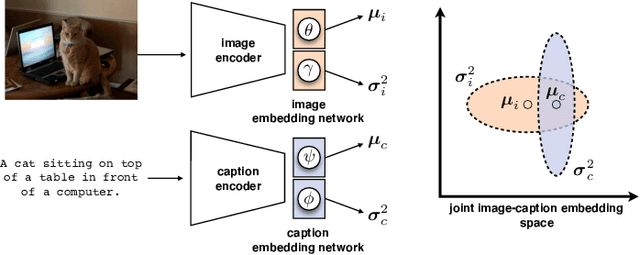
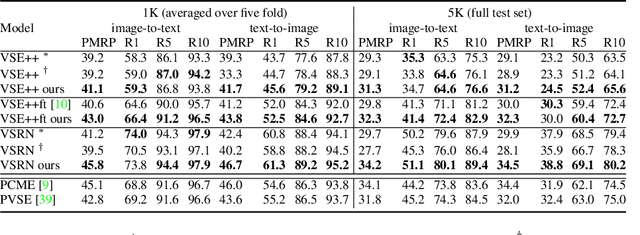
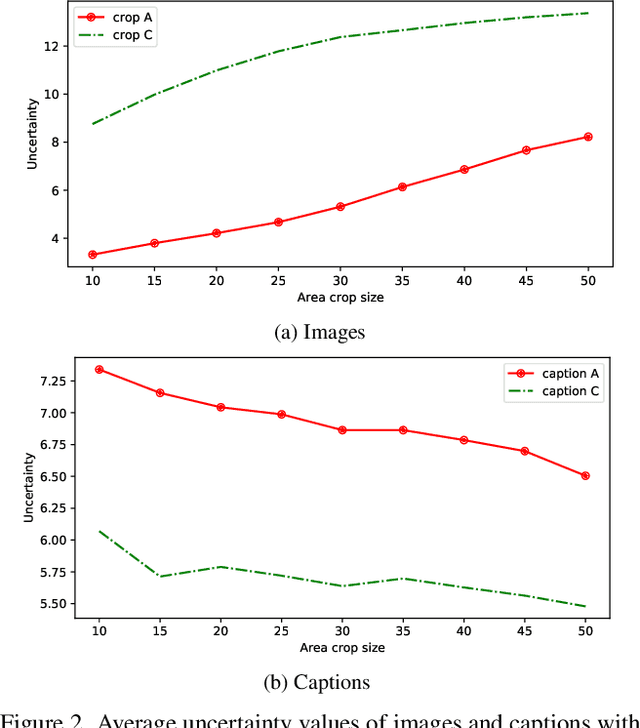
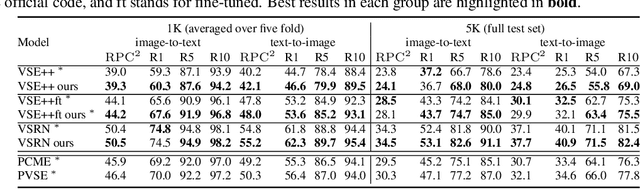
Probabilistic embeddings have proven useful for capturing polysemous word meanings, as well as ambiguity in image matching. In this paper, we study the advantages of probabilistic embeddings in a cross-modal setting (i.e., text and images), and propose a simple approach that replaces the standard vector point embeddings in extant image-text matching models with probabilistic distributions that are parametrically learned. Our guiding hypothesis is that the uncertainty encoded in the probabilistic embeddings captures the cross-modal ambiguity in the input instances, and that it is through capturing this uncertainty that the probabilistic models can perform better at downstream tasks, such as image-to-text or text-to-image retrieval. Through extensive experiments on standard and new benchmarks, we show a consistent advantage for probabilistic representations in cross-modal retrieval, and validate the ability of our embeddings to capture uncertainty.
A Deep Reinforcement Learning based Approach for NOMA-based Random Access Network with Truncated Channel Inversion Power Control
Feb 22, 2022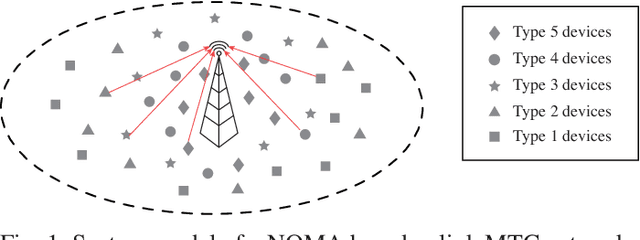
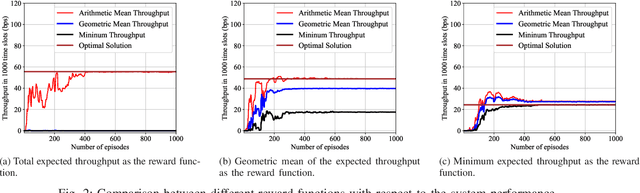

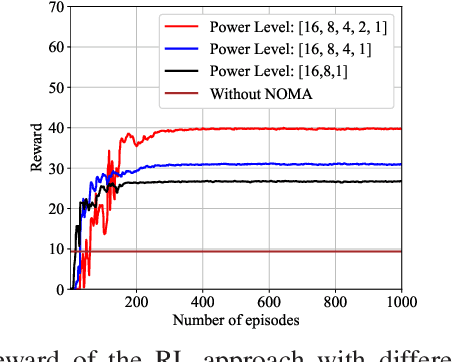
As a main use case of 5G and Beyond wireless network, the ever-increasing machine type communications (MTC) devices pose critical challenges over MTC network in recent years. It is imperative to support massive MTC devices with limited resources. To this end, Non-orthogonal multiple access (NOMA) based random access network has been deemed as a prospective candidate for MTC network. In this paper, we propose a deep reinforcement learning (RL) based approach for NOMA-based random access network with truncated channel inversion power control. Specifically, each MTC device randomly selects a pre-defined power level with a certain probability for data transmission. Devices are using channel inversion power control yet subject to the upper bound of the transmission power. Due to the stochastic feature of the channel fading and the limited transmission power, devices with different achievable power levels have been categorized as different types of devices. In order to achieve high throughput with considering the fairness between all devices, two objective functions are formulated. One is to maximize the minimum long-term expected throughput of all MTC devices, the other is to maximize the geometric mean of the long-term expected throughput for all MTC devices. A Policy based deep reinforcement learning approach is further applied to tune the transmission probabilities of each device to solve the formulated optimization problems. Extensive simulations are conducted to show the merits of our proposed approach.
MELONS: generating melody with long-term structure using transformers and structure graph
Nov 03, 2021

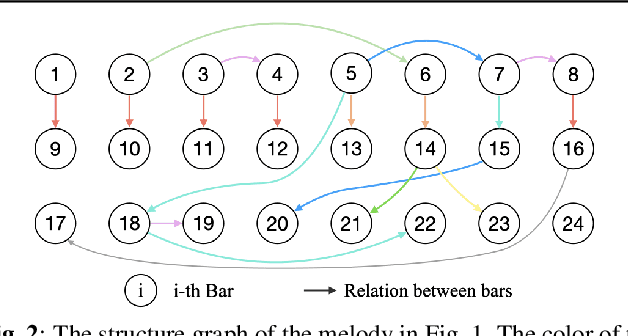
The creation of long melody sequences requires effective expression of coherent musical structure. However, there is no clear representation of musical structure. Recent works on music generation have suggested various approaches to deal with the structural information of music, but generating a full-song melody with clear long-term structure remains a challenge. In this paper, we propose MELONS, a melody generation framework based on a graph representation of music structure which consists of eight types of bar-level relations. MELONS adopts a multi-step generation method with transformer-based networks by factoring melody generation into two sub-problems: structure generation and structure conditional melody generation. Experimental results show that MELONS can produce structured melodies with high quality and rich contents.
Learning-Based Strategy Design for Robot-Assisted Reminiscence Therapy Based on a Developed Model for People with Dementia
Sep 06, 2021
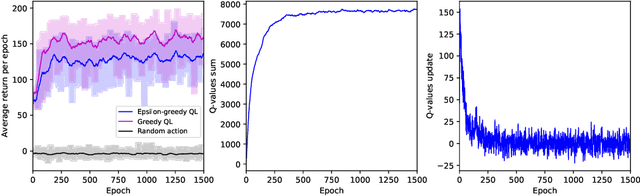
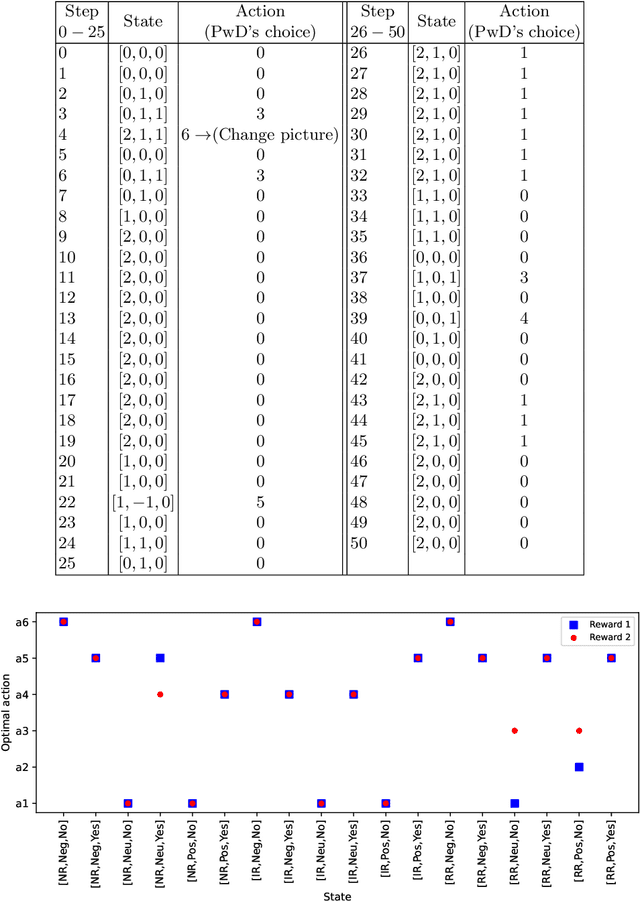
In this paper, the robot-assisted Reminiscence Therapy (RT) is studied as a psychosocial intervention to persons with dementia (PwDs). We aim at a conversation strategy for the robot by reinforcement learning to stimulate the PwD to talk. Specifically, to characterize the stochastic reactions of a PwD to the robot's actions, a simulation model of a PwD is developed which features the transition probabilities among different PwD states consisting of the response relevance, emotion levels and confusion conditions. A Q-learning (QL) algorithm is then designed to achieve the best conversation strategy for the robot. The objective is to stimulate the PwD to talk as much as possible while keeping the PwD's states as positive as possible. In certain conditions, the achieved strategy gives the PwD choices to continue or change the topic, or stop the conversation, so that the PwD has a sense of control to mitigate the conversation stress. To achieve this, the standard QL algorithm is revised to deliberately integrate the impact of PwD's choices into the Q-value updates. Finally, the simulation results demonstrate the learning convergence and validate the efficacy of the achieved strategy. Tests show that the strategy is capable to duly adjust the difficulty level of prompt according to the PwD's states, take actions (e.g., repeat or explain the prompt, or comfort) to help the PwD out of bad states, and allow the PwD to control the conversation tendency when bad states continue.
Responsive Regulation of Dynamic UAV Communication Networks Based on Deep Reinforcement Learning
Aug 25, 2021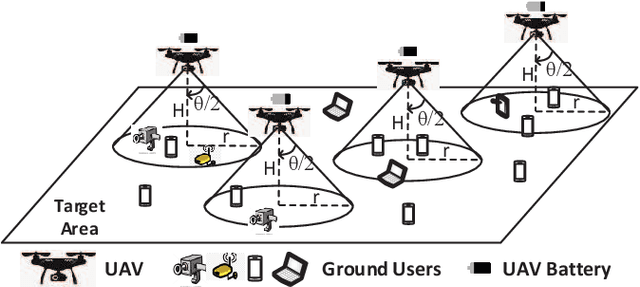
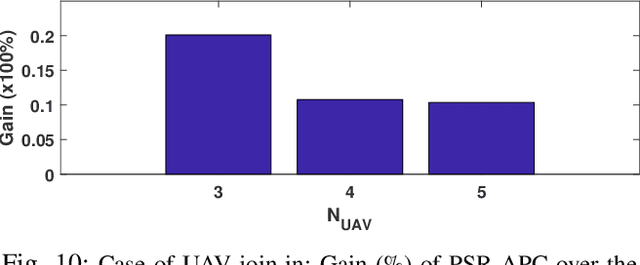
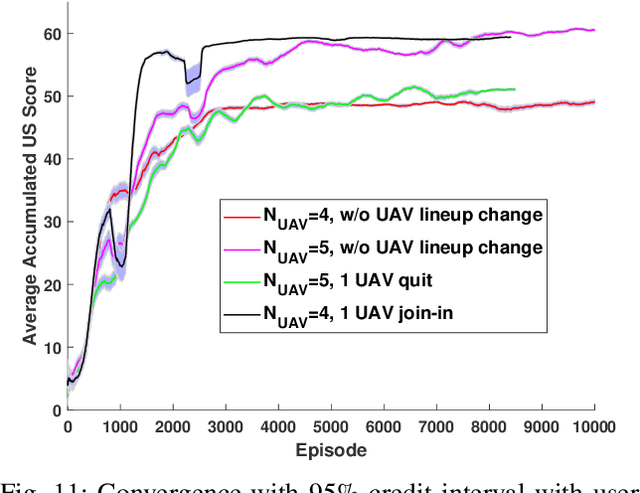
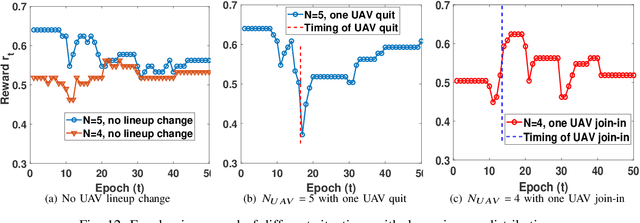
In this chapter, the regulation of Unmanned Aerial Vehicle (UAV) communication network is investigated in the presence of dynamic changes in the UAV lineup and user distribution. We target an optimal UAV control policy which is capable of identifying the upcoming change in the UAV lineup (quit or join-in) or user distribution, and proactively relocating the UAVs ahead of the change rather than passively dispatching the UAVs after the change. Specifically, a deep reinforcement learning (DRL)-based UAV control framework is developed to maximize the accumulated user satisfaction (US) score for a given time horizon which is able to handle the change in both the UAV lineup and user distribution. The framework accommodates the changed dimension of the state-action space before and after the UAV lineup change by deliberate state transition design. In addition, to handle the continuous state and action space, deep deterministic policy gradient (DDPG) algorithm, which is an actor-critic based DRL, is exploited. Furthermore, to promote the learning exploration around the timing of the change, the original DDPG is adapted into an asynchronous parallel computing (APC) structure which leads to a better training performance in both the critic and actor networks. Finally, extensive simulations are conducted to validate the convergence of the proposed learning approach, and demonstrate its capability in jointly handling the dynamics in UAV lineup and user distribution as well as its superiority over a passive reaction method.