 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVeriLoC: Line-of-Code Level Prediction of Hardware Design Quality from Verilog Code
Jun 08, 2025



Modern chip design is complex, and there is a crucial need for early-stage prediction of key design-quality metrics like timing and routing congestion directly from Verilog code (a commonly used programming language for hardware design). It is especially important yet complex to predict individual lines of code that cause timing violations or downstream routing congestion. Prior works have tried approaches like converting Verilog into an intermediate graph representation and using LLM embeddings alongside other features to predict module-level quality, but did not consider line-level quality prediction. We propose VeriLoC, the first method that predicts design quality directly from Verilog at both the line- and module-level. To this end, VeriLoC leverages recent Verilog code-generation LLMs to extract local line-level and module-level embeddings, and train downstream classifiers/regressors on concatenations of these embeddings. VeriLoC achieves high F1-scores of 0.86-0.95 for line-level congestion and timing prediction, and reduces the mean average percentage error from 14% - 18% for SOTA methods down to only 4%. We believe that VeriLoC embeddings and insights from our work will also be of value for other predictive and optimization tasks for complex hardware design.
PrefixLLM: LLM-aided Prefix Circuit Design
Dec 03, 2024



Prefix circuits are fundamental components in digital adders, widely used in digital systems due to their efficiency in calculating carry signals. Synthesizing prefix circuits with minimized area and delay is crucial for enhancing the performance of modern computing systems. Recently, large language models (LLMs) have demonstrated a surprising ability to perform text generation tasks. We propose PrefixLLM, that leverages LLMs for prefix circuit synthesis. PrefixLLM transforms the prefix circuit synthesis task into a structured text generation problem, termed the Structured Prefix Circuit Representation (SPCR), and introduces an iterative framework to automatically and accurately generate valid SPCRs. We further present a design space exploration (DSE) framework that uses LLMs to iteratively search for area and delay optimized prefix circuits. Compared to state-of-the-art, PrefixLLM can reduce the area by 3.70% under the same delay constraint. This work highlights the use of LLMs in the synthesis of arithmetic circuits, which can be transformed into the structured text generation.
AEVB-Comm: An Intelligent CommunicationSystem based on AEVBs
May 19, 2020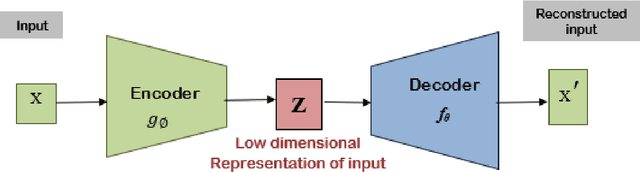
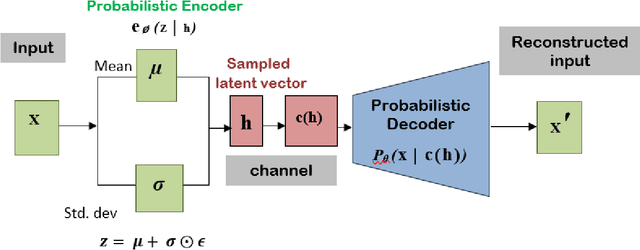
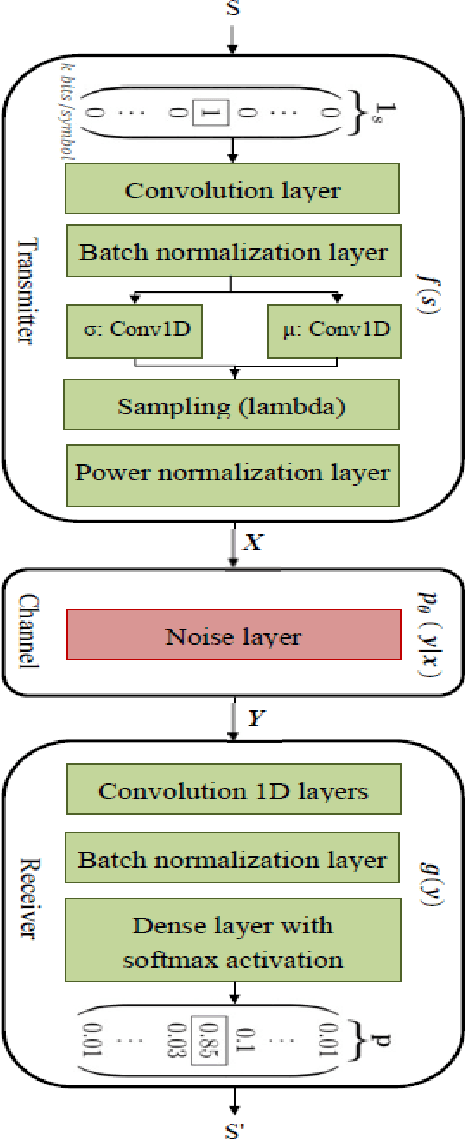
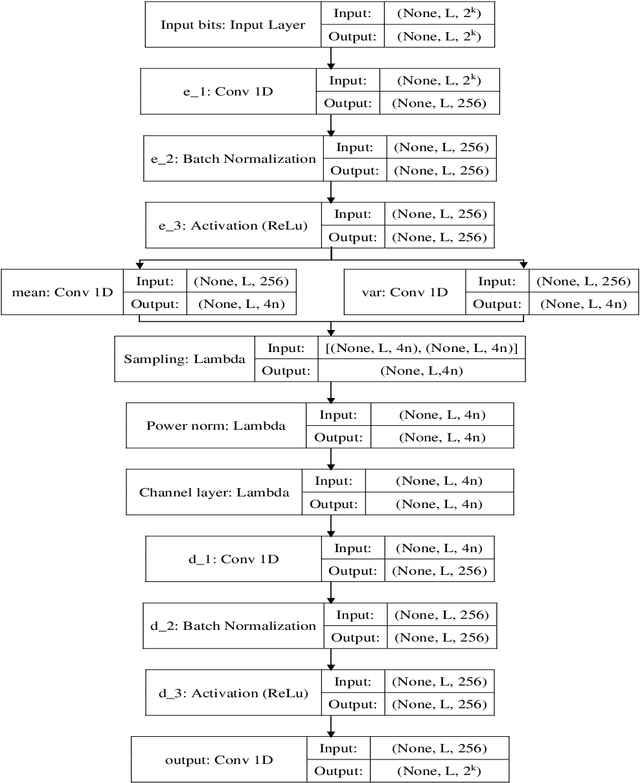
In recent years, applying Deep Learning (DL) techniques emerged as a common practice in the communication system, demonstrating promising results. The present paper proposes a new Convolutional Neural Network (CNN) based Variational Autoencoder (VAE) communication system. The VAE (continuous latent space) based communication systems confer unprecedented improvement in the system performance compared to AE (distributed latent space) and other traditional methods. We have introduced an adjustable hyperparameter beta in the proposed VAE, which is also known as beta-VAE, resulting in extremely disentangled latent space representation. Furthermore, a higher-dimensional representation of latent space is employed, such as 4n dimension instead of 2n, reducing the Block Error Rate (BLER). The proposed system can operate under Additive Wide Gaussian Noise (AWGN) and Rayleigh fading channels. The CNN based VAE architecture performs the encoding and modulation at the transmitter, whereas decoding and demodulation at the receiver. Finally, to prove that a continuous latent space-based system designated VAE performs better than the other, various simulation results supporting the same has been conferred under normal and noisy conditions.