 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker-Conditioned Hierarchical Modeling for Automated Speech Scoring
Aug 30, 2021
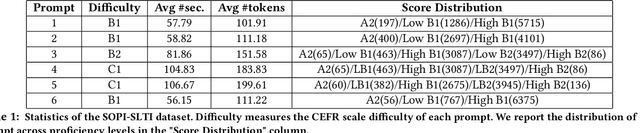
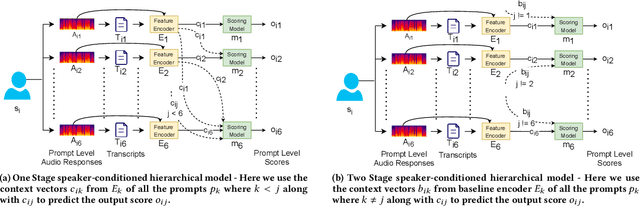

Automatic Speech Scoring (ASS) is the computer-assisted evaluation of a candidate's speaking proficiency in a language. ASS systems face many challenges like open grammar, variable pronunciations, and unstructured or semi-structured content. Recent deep learning approaches have shown some promise in this domain. However, most of these approaches focus on extracting features from a single audio, making them suffer from the lack of speaker-specific context required to model such a complex task. We propose a novel deep learning technique for non-native ASS, called speaker-conditioned hierarchical modeling. In our technique, we take advantage of the fact that oral proficiency tests rate multiple responses for a candidate. We extract context vectors from these responses and feed them as additional speaker-specific context to our network to score a particular response. We compare our technique with strong baselines and find that such modeling improves the model's average performance by 6.92% (maximum = 12.86%, minimum = 4.51%). We further show both quantitative and qualitative insights into the importance of this additional context in solving the problem of ASS.
Defending Touch-based Continuous Authentication Systems from Active Adversaries Using Generative Adversarial Networks
Jun 15, 2021
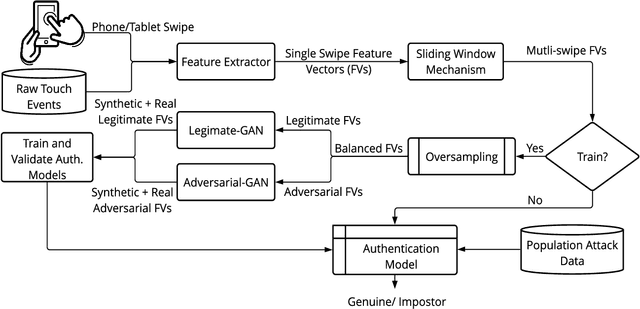
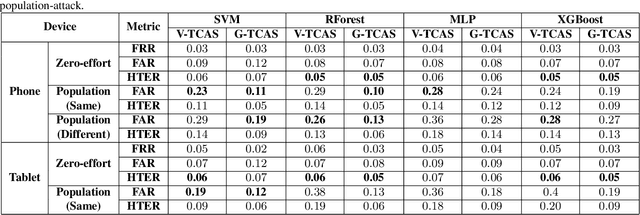

Previous studies have demonstrated that commonly studied (vanilla) touch-based continuous authentication systems (V-TCAS) are susceptible to population attack. This paper proposes a novel Generative Adversarial Network assisted TCAS (G-TCAS) framework, which showed more resilience to the population attack. G-TCAS framework was tested on a dataset of 117 users who interacted with a smartphone and tablet pair. On average, the increase in the false accept rates (FARs) for V-TCAS was much higher (22%) than G-TCAS (13%) for the smartphone. Likewise, the increase in the FARs for V-TCAS was 25% compared to G-TCAS (6%) for the tablet.
GupShup: An Annotated Corpus for Abstractive Summarization of Open-Domain Code-Switched Conversations
Apr 17, 2021
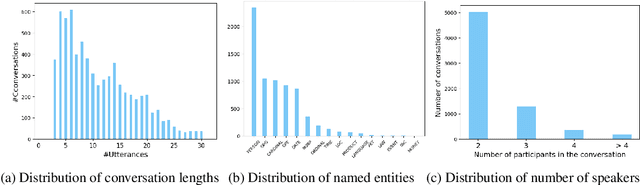
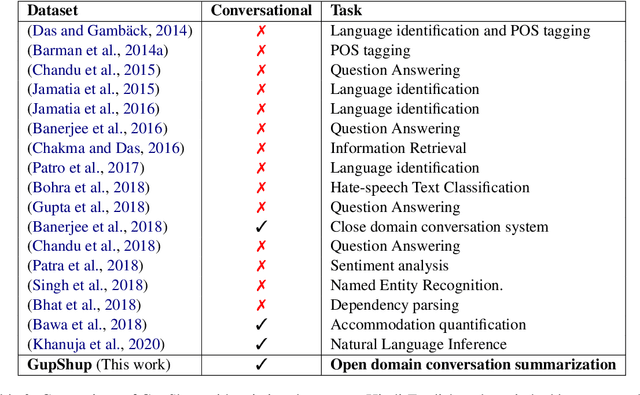

Code-switching is the communication phenomenon where speakers switch between different languages during a conversation. With the widespread adoption of conversational agents and chat platforms, code-switching has become an integral part of written conversations in many multi-lingual communities worldwide. This makes it essential to develop techniques for summarizing and understanding these conversations. Towards this objective, we introduce abstractive summarization of Hindi-English code-switched conversations and develop the first code-switched conversation summarization dataset - GupShup, which contains over 6,831 conversations in Hindi-English and their corresponding human-annotated summaries in English and Hindi-English. We present a detailed account of the entire data collection and annotation processes. We analyze the dataset using various code-switching statistics. We train state-of-the-art abstractive summarization models and report their performances using both automated metrics and human evaluation. Our results show that multi-lingual mBART and multi-view seq2seq models obtain the best performances on the new dataset
Factorization of Fact-Checks for Low Resource Indian Languages
Feb 23, 2021
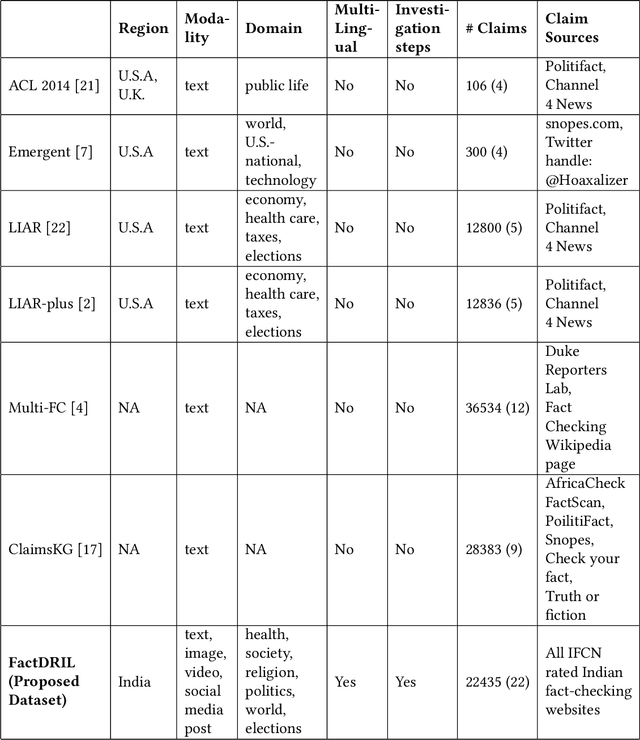

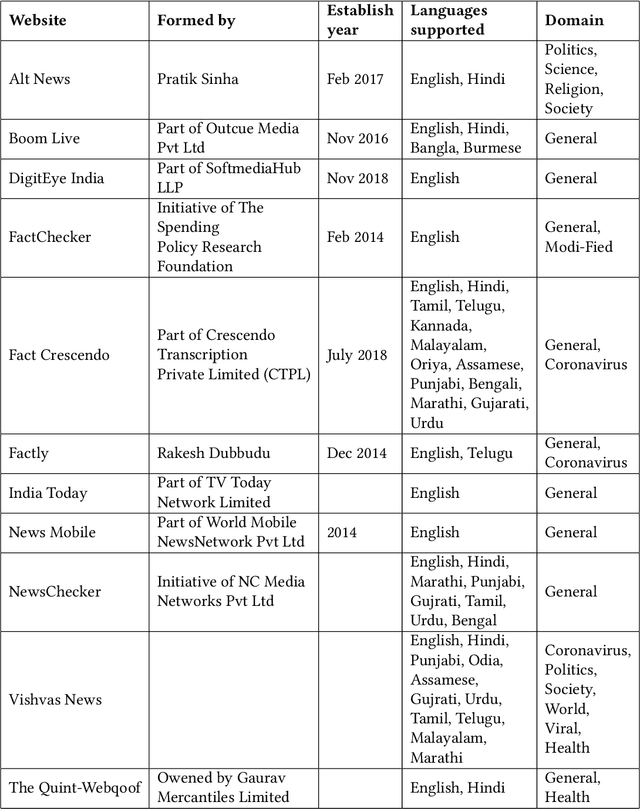
The advancement in technology and accessibility of internet to each individual is revolutionizing the real time information. The liberty to express your thoughts without passing through any credibility check is leading to dissemination of fake content in the ecosystem. It can have disastrous effects on both individuals and society as a whole. The amplification of fake news is becoming rampant in India too. Debunked information often gets republished with a replacement description, claiming it to depict some different incidence. To curb such fabricated stories, it is necessary to investigate such deduplicates and false claims made in public. The majority of studies on automatic fact-checking and fake news detection is restricted to English only. But for a country like India where only 10% of the literate population speak English, role of regional languages in spreading falsity cannot be undermined. In this paper, we introduce FactDRIL: the first large scale multilingual Fact-checking Dataset for Regional Indian Languages. We collect an exhaustive dataset across 7 months covering 11 low-resource languages. Our propose dataset consists of 9,058 samples belonging to English, 5,155 samples to Hindi and remaining 8,222 samples are distributed across various regional languages, i.e. Bangla, Marathi, Malayalam, Telugu, Tamil, Oriya, Assamese, Punjabi, Urdu, Sinhala and Burmese. We also present the detailed characterization of three M's (multi-lingual, multi-media, multi-domain) in the FactDRIL accompanied with the complete list of other varied attributes making it a unique dataset to study. Lastly, we present some potential use cases of the dataset. We expect this dataset will be a valuable resource and serve as a starting point to fight proliferation of fake news in low resource languages.
Cisco at AAAI-CAD21 shared task: Predicting Emphasis in Presentation Slides using Contextualized Embeddings
Feb 09, 2021
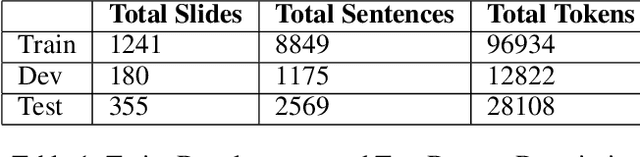
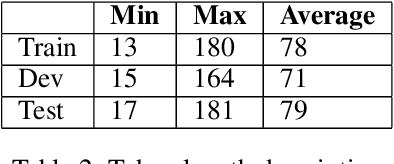
This paper describes our proposed system for the AAAI-CAD21 shared task: Predicting Emphasis in Presentation Slides. In this specific task, given the contents of a slide we are asked to predict the degree of emphasis to be laid on each word in the slide. We propose 2 approaches to this problem including a BiLSTM-ELMo approach and a transformers based approach based on RoBERTa and XLNet architectures. We achieve a score of 0.518 on the evaluation leaderboard which ranks us 3rd and 0.543 on the post-evaluation leaderboard which ranks us 1st at the time of writing the paper.
Exploring Semi-Supervised Learning for Predicting Listener Backchannels
Jan 06, 2021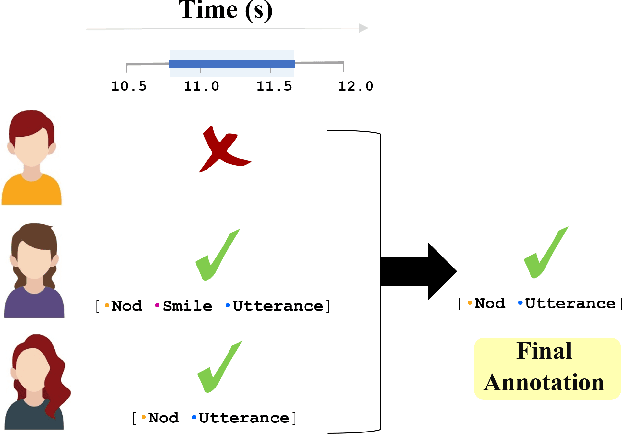
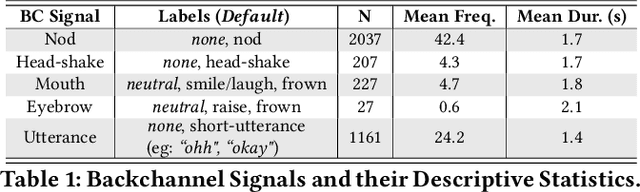
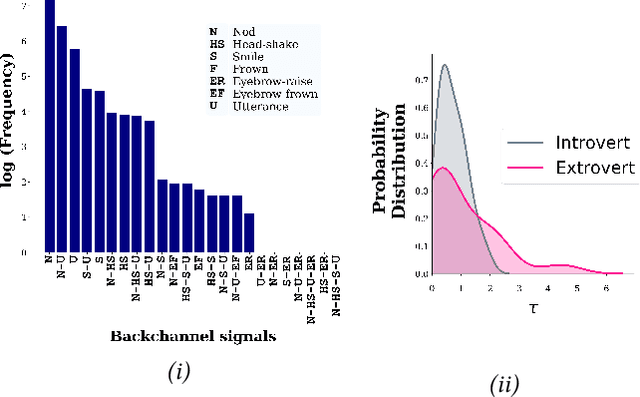

Developing human-like conversational agents is a prime area in HCI research and subsumes many tasks. Predicting listener backchannels is one such actively-researched task. While many studies have used different approaches for backchannel prediction, they all have depended on manual annotations for a large dataset. This is a bottleneck impacting the scalability of development. To this end, we propose using semi-supervised techniques to automate the process of identifying backchannels, thereby easing the annotation process. To analyze our identification module's feasibility, we compared the backchannel prediction models trained on (a) manually-annotated and (b) semi-supervised labels. Quantitative analysis revealed that the proposed semi-supervised approach could attain 95% of the former's performance. Our user-study findings revealed that almost 60% of the participants found the backchannel responses predicted by the proposed model more natural. Finally, we also analyzed the impact of personality on the type of backchannel signals and validated our findings in the user-study.
What all do audio transformer models hear? Probing Acoustic Representations for Language Delivery and its Structure
Jan 02, 2021

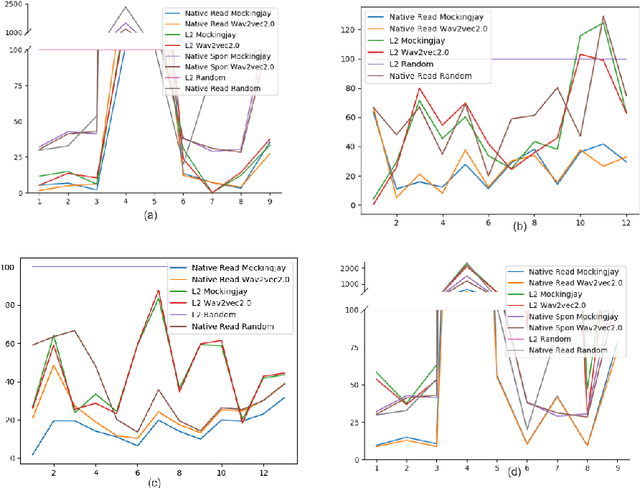

In recent times, BERT based transformer models have become an inseparable part of the 'tech stack' of text processing models. Similar progress is being observed in the speech domain with a multitude of models observing state-of-the-art results by using audio transformer models to encode speech. This begs the question of what are these audio transformer models learning. Moreover, although the standard methodology is to choose the last layer embedding for any downstream task, but is it the optimal choice? We try to answer these questions for the two recent audio transformer models, Mockingjay and wave2vec2.0. We compare them on a comprehensive set of language delivery and structure features including audio, fluency and pronunciation features. Additionally, we probe the audio models' understanding of textual surface, syntax, and semantic features and compare them to BERT. We do this over exhaustive settings for native, non-native, synthetic, read and spontaneous speech datasets
Towards Modelling Coherence in Spoken Discourse
Dec 31, 2020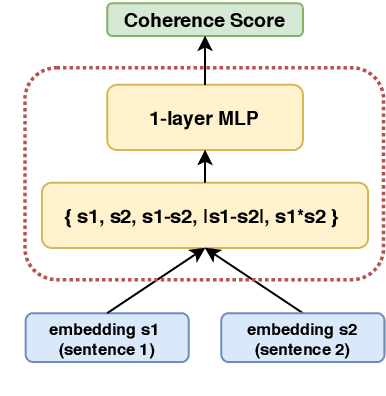
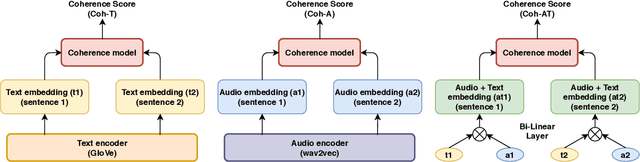
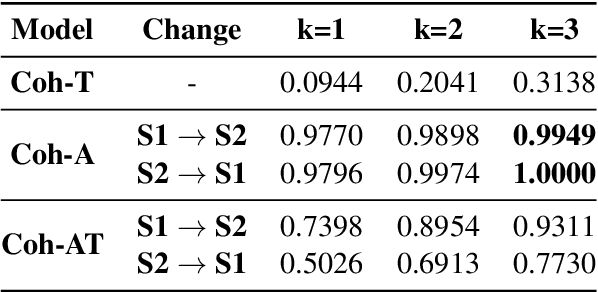
While there has been significant progress towards modelling coherence in written discourse, the work in modelling spoken discourse coherence has been quite limited. Unlike the coherence in text, coherence in spoken discourse is also dependent on the prosodic and acoustic patterns in speech. In this paper, we model coherence in spoken discourse with audio-based coherence models. We perform experiments with four coherence-related tasks with spoken discourses. In our experiments, we evaluate machine-generated speech against the speech delivered by expert human speakers. We also compare the spoken discourses generated by human language learners of varying language proficiency levels. Our results show that incorporating the audio modality along with the text benefits the coherence models in performing downstream coherence related tasks with spoken discourses.
My Teacher Thinks The World Is Flat! Interpreting Automatic Essay Scoring Mechanism
Dec 27, 2020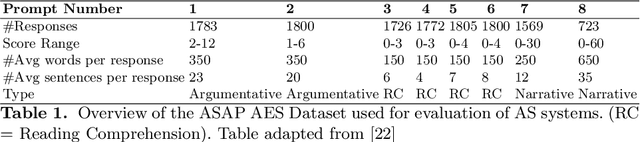
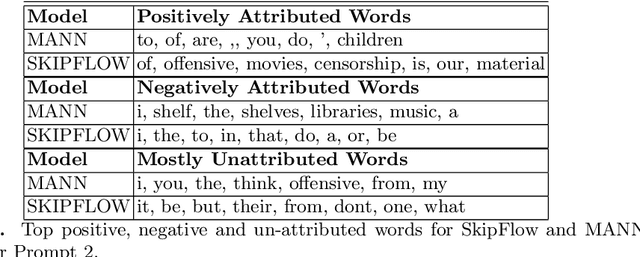
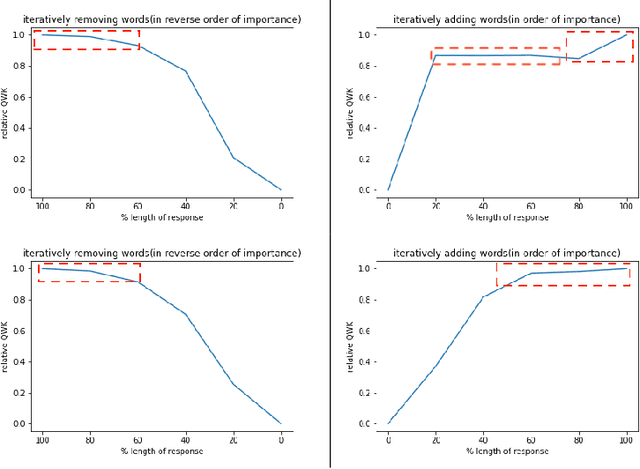
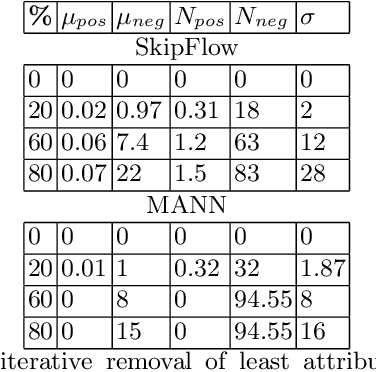
Significant progress has been made in deep-learning based Automatic Essay Scoring (AES) systems in the past two decades. However, little research has been put to understand and interpret the black-box nature of these deep-learning based scoring models. Recent work shows that automated scoring systems are prone to even common-sense adversarial samples. Their lack of natural language understanding capability raises questions on the models being actively used by millions of candidates for life-changing decisions. With scoring being a highly multi-modal task, it becomes imperative for scoring models to be validated and tested on all these modalities. We utilize recent advances in interpretability to find the extent to which features such as coherence, content and relevance are important for automated scoring mechanisms and why they are susceptible to adversarial samples. We find that the systems tested consider essays not as a piece of prose having the characteristics of natural flow of speech and grammatical structure, but as `word-soups' where a few words are much more important than the other words. Removing the context surrounding those few important words causes the prose to lose the flow of speech and grammar, however has little impact on the predicted score. We also find that since the models are not semantically grounded with world-knowledge and common sense, adding false facts such as ``the world is flat'' actually increases the score instead of decreasing it.
Get It Scored Using AutoSAS -- An Automated System for Scoring Short Answers
Dec 21, 2020
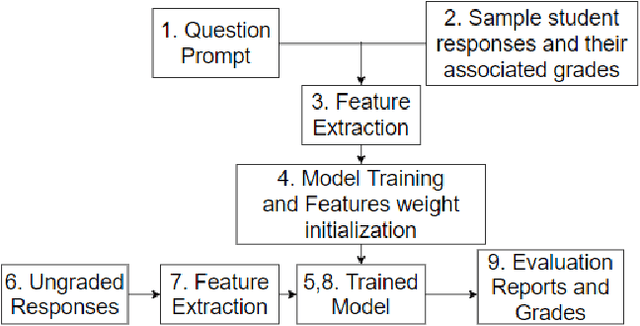


In the era of MOOCs, online exams are taken by millions of candidates, where scoring short answers is an integral part. It becomes intractable to evaluate them by human graders. Thus, a generic automated system capable of grading these responses should be designed and deployed. In this paper, we present a fast, scalable, and accurate approach towards automated Short Answer Scoring (SAS). We propose and explain the design and development of a system for SAS, namely AutoSAS. Given a question along with its graded samples, AutoSAS can learn to grade that prompt successfully. This paper further lays down the features such as lexical diversity, Word2Vec, prompt, and content overlap that plays a pivotal role in building our proposed model. We also present a methodology for indicating the factors responsible for scoring an answer. The trained model is evaluated on an extensively used public dataset, namely Automated Student Assessment Prize Short Answer Scoring (ASAP-SAS). AutoSAS shows state-of-the-art performance and achieves better results by over 8% in some of the question prompts as measured by Quadratic Weighted Kappa (QWK), showing performance comparable to humans.