 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterQuill: Investigating the Potential of Human-AI Collaboration in Online Counterspeech Writing
Oct 03, 2024



Online hate speech has become increasingly prevalent on social media platforms, causing harm to individuals and society. While efforts have been made to combat this issue through content moderation, the potential of user-driven counterspeech as an alternative solution remains underexplored. Existing counterspeech methods often face challenges such as fear of retaliation and skill-related barriers. To address these challenges, we introduce CounterQuill, an AI-mediated system that assists users in composing effective and empathetic counterspeech. CounterQuill provides a three-step process: (1) a learning session to help users understand hate speech and counterspeech; (2) a brainstorming session that guides users in identifying key elements of hate speech and exploring counterspeech strategies; and (3) a co-writing session that enables users to draft and refine their counterspeech with CounterQuill. We conducted a within-subjects user study with 20 participants to evaluate CounterQuill in comparison to ChatGPT. Results show that CounterQuill's guidance and collaborative writing process provided users a stronger sense of ownership over their co-authored counterspeech. Users perceived CounterQuill as a writing partner and thus were more willing to post the co-written counterspeech online compared to the one written with ChatGPT.
Leveraging Prompt-Based Large Language Models: Predicting Pandemic Health Decisions and Outcomes Through Social Media Language
Mar 01, 2024



We introduce a multi-step reasoning framework using prompt-based LLMs to examine the relationship between social media language patterns and trends in national health outcomes. Grounded in fuzzy-trace theory, which emphasizes the importance of gists of causal coherence in effective health communication, we introduce Role-Based Incremental Coaching (RBIC), a prompt-based LLM framework, to identify gists at-scale. Using RBIC, we systematically extract gists from subreddit discussions opposing COVID-19 health measures (Study 1). We then track how these gists evolve across key events (Study 2) and assess their influence on online engagement (Study 3). Finally, we investigate how the volume of gists is associated with national health trends like vaccine uptake and hospitalizations (Study 4). Our work is the first to empirically link social media linguistic patterns to real-world public health trends, highlighting the potential of prompt-based LLMs in identifying critical online discussion patterns that can form the basis of public health communication strategies.
GupShup: An Annotated Corpus for Abstractive Summarization of Open-Domain Code-Switched Conversations
Apr 17, 2021
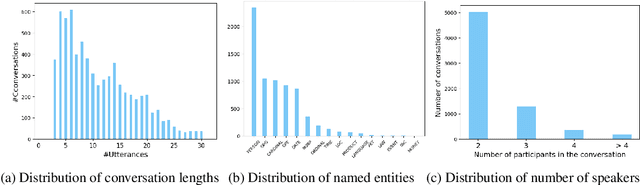
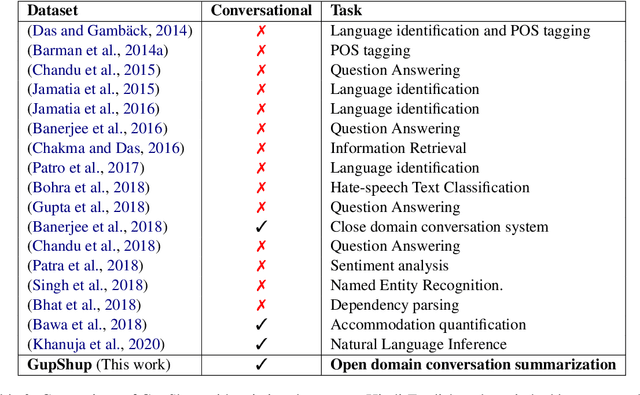

Code-switching is the communication phenomenon where speakers switch between different languages during a conversation. With the widespread adoption of conversational agents and chat platforms, code-switching has become an integral part of written conversations in many multi-lingual communities worldwide. This makes it essential to develop techniques for summarizing and understanding these conversations. Towards this objective, we introduce abstractive summarization of Hindi-English code-switched conversations and develop the first code-switched conversation summarization dataset - GupShup, which contains over 6,831 conversations in Hindi-English and their corresponding human-annotated summaries in English and Hindi-English. We present a detailed account of the entire data collection and annotation processes. We analyze the dataset using various code-switching statistics. We train state-of-the-art abstractive summarization models and report their performances using both automated metrics and human evaluation. Our results show that multi-lingual mBART and multi-view seq2seq models obtain the best performances on the new dataset