 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dataset for Discourse Structure in Peer Review Discussions
Oct 16, 2021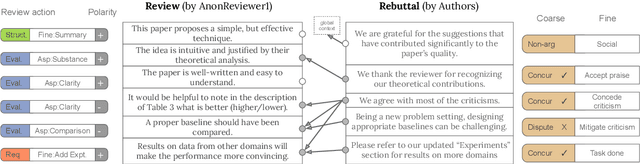
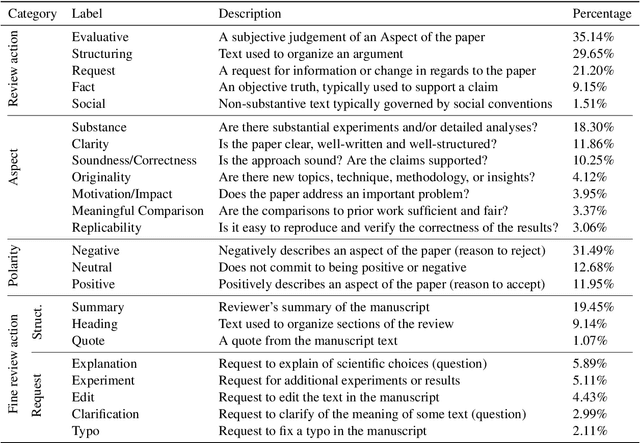

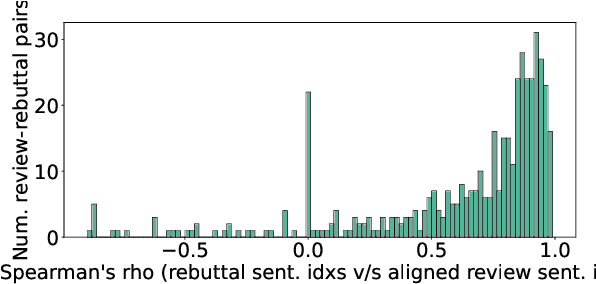
At the foundation of scientific evaluation is the labor-intensive process of peer review. This critical task requires participants to consume and interpret vast amounts of highly technical text. We show that discourse cues from rebuttals can shed light on the quality and interpretation of reviews. Further, an understanding of the argumentative strategies employed by the reviewers and authors provides useful signal for area chairs and other decision makers. This paper presents a new labeled dataset of 20k sentences contained in 506 review-rebuttal pairs in English, annotated by experts. While existing datasets annotate a subset of review sentences using various schemes, ours synthesizes existing label sets and extends them to include fine-grained annotation of the rebuttal sentences, characterizing the authors' stance towards the reviewers' criticisms and their commitment to addressing them. Further, we annotate \textit{every} sentence in both the review and the rebuttal, including a description of the context for each rebuttal sentence.
Case-based Reasoning for Natural Language Queries over Knowledge Bases
Apr 18, 2021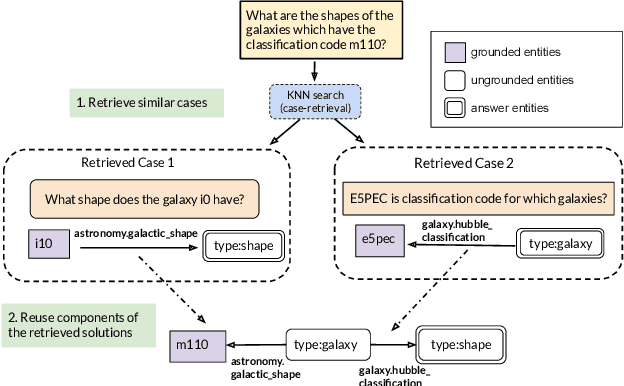
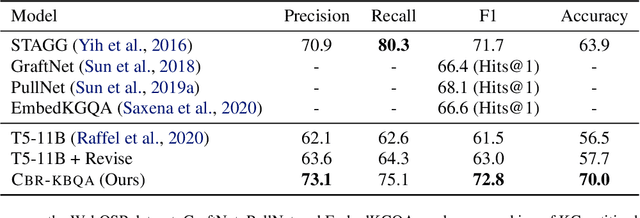
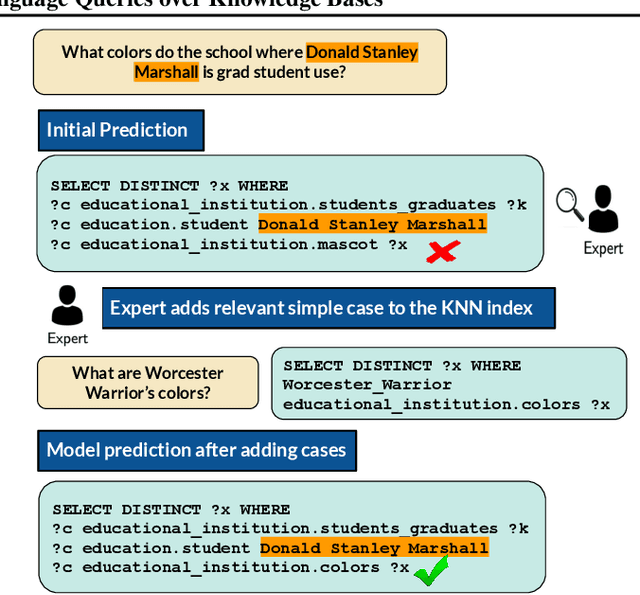
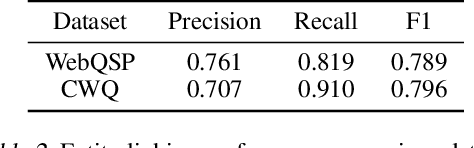
It is often challenging for a system to solve a new complex problem from scratch, but much easier if the system can access other similar problems and description of their solutions -- a paradigm known as case-based reasoning (CBR). We propose a neuro-symbolic CBR approach for question answering over large knowledge bases (CBR-KBQA). While the idea of CBR is tempting, composing a solution from cases is nontrivial, when individual cases only contain partial logic to the full solution. To resolve this, CBR-KBQA consists of two modules: a non-parametric memory that stores cases (question and logical forms) and a parametric model which can generate logical forms by retrieving relevant cases from memory. Through experiments, we show that CBR-KBQA can effectively derive novel combination of relations not presented in case memory that is required to answer compositional questions. On several KBQA datasets that test compositional generalization, CBR-KBQA achieves competitive performance. For example, on the challenging ComplexWebQuestions dataset, CBR-KBQA outperforms the current state of the art by 11% accuracy. Furthermore, we show that CBR-KBQA is capable of using new cases \emph{without} any further training. Just by incorporating few human-labeled examples in the non-parametric case memory, CBR-KBQA is able to successfully generate queries containing unseen KB relations.
Long Document Summarization in a Low Resource Setting using Pretrained Language Models
Mar 01, 2021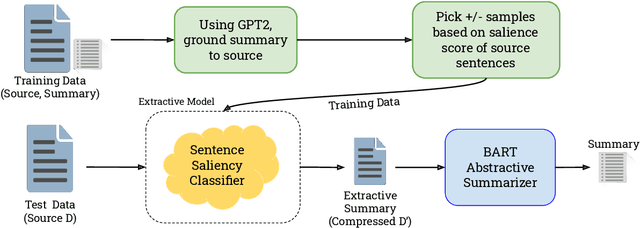
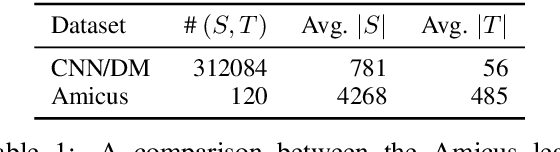

Abstractive summarization is the task of compressing a long document into a coherent short document while retaining salient information. Modern abstractive summarization methods are based on deep neural networks which often require large training datasets. Since collecting summarization datasets is an expensive and time-consuming task, practical industrial settings are usually low-resource. In this paper, we study a challenging low-resource setting of summarizing long legal briefs with an average source document length of 4268 words and only 120 available (document, summary) pairs. To account for data scarcity, we used a modern pretrained abstractive summarizer BART (Lewis et al., 2020), which only achieves 17.9 ROUGE-L as it struggles with long documents. We thus attempt to compress these long documents by identifying salient sentences in the source which best ground the summary, using a novel algorithm based on GPT-2 (Radford et al., 2019) language model perplexity scores, that operates within the low resource regime. On feeding the compressed documents to BART, we observe a 6.0 ROUGE-L improvement. Our method also beats several competitive salience detection baselines. Furthermore, the identified salient sentences tend to agree with an independent human labeling by domain experts.
Probabilistic Case-based Reasoning for Open-World Knowledge Graph Completion
Oct 09, 2020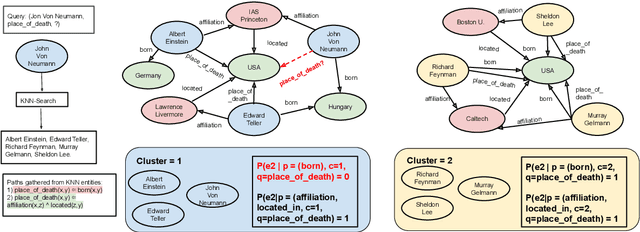

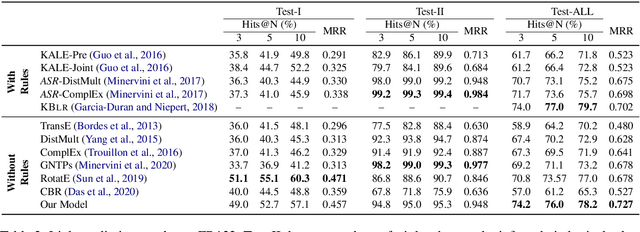
A case-based reasoning (CBR) system solves a new problem by retrieving `cases' that are similar to the given problem. If such a system can achieve high accuracy, it is appealing owing to its simplicity, interpretability, and scalability. In this paper, we demonstrate that such a system is achievable for reasoning in knowledge-bases (KBs). Our approach predicts attributes for an entity by gathering reasoning paths from similar entities in the KB. Our probabilistic model estimates the likelihood that a path is effective at answering a query about the given entity. The parameters of our model can be efficiently computed using simple path statistics and require no iterative optimization. Our model is non-parametric, growing dynamically as new entities and relations are added to the KB. On several benchmark datasets our approach significantly outperforms other rule learning approaches and performs comparably to state-of-the-art embedding-based approaches. Furthermore, we demonstrate the effectiveness of our model in an "open-world" setting where new entities arrive in an online fashion, significantly outperforming state-of-the-art approaches and nearly matching the best offline method. Code available at https://github.com/ameyagodbole/Prob-CBR
A Simple Approach to Case-Based Reasoning in Knowledge Bases
Jun 25, 2020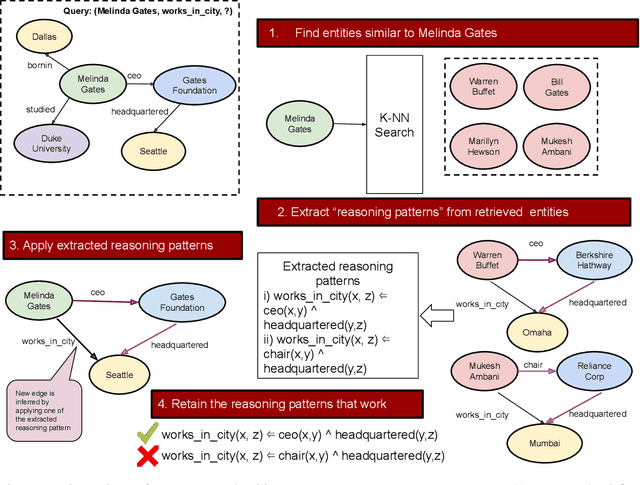
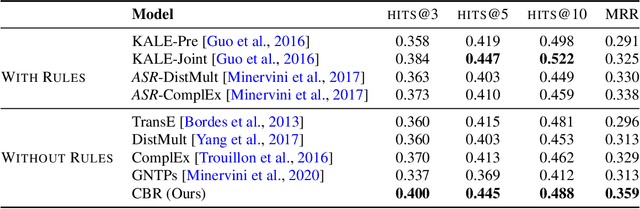
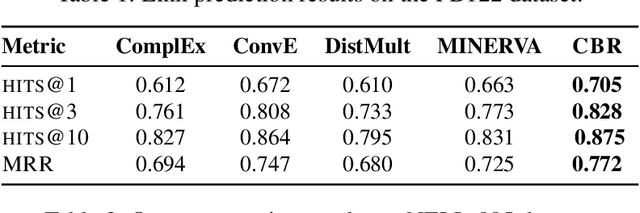
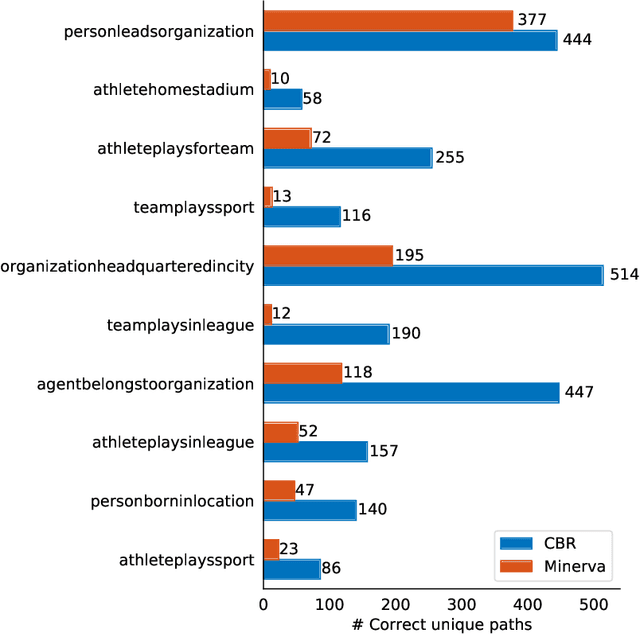
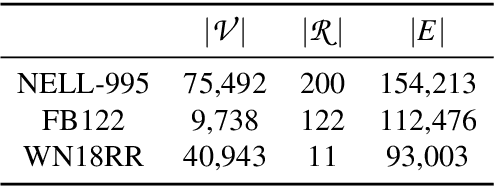
We present a surprisingly simple yet accurate approach to reasoning in knowledge graphs (KGs) that requires \emph{no training}, and is reminiscent of case-based reasoning in classical artificial intelligence (AI). Consider the task of finding a target entity given a source entity and a binary relation. Our non-parametric approach derives crisp logical rules for each query by finding multiple \textit{graph path patterns} that connect similar source entities through the given relation. Using our method, we obtain new state-of-the-art accuracy, outperforming all previous models, on NELL-995 and FB-122. We also demonstrate that our model is robust in low data settings, outperforming recently proposed meta-learning approaches
ProtoQA: A Question Answering Dataset for Prototypical Common-Sense Reasoning
May 02, 2020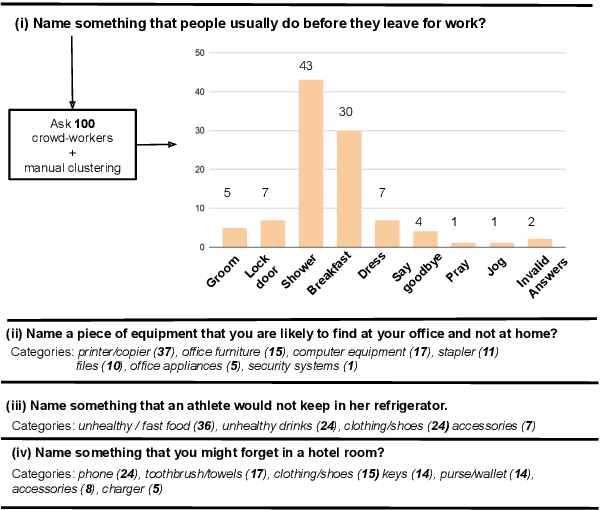

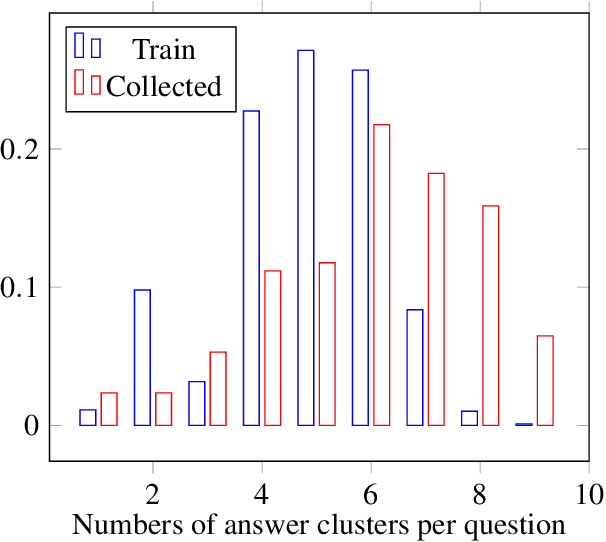
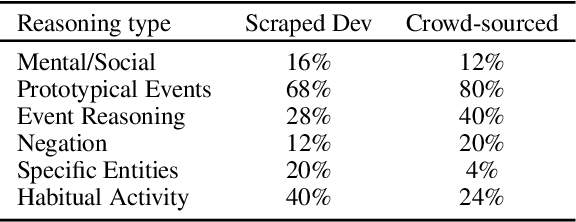
Given questions regarding some prototypical situation -- such as Name something that people usually do before they leave the house for work? -- a human can easily answer them via acquired experiences. There can be multiple right answers for such questions with some more common for a situation than others. This paper introduces a new question answering dataset for training and evaluating common-sense reasoning capabilities of artificial intelligence systems in such prototypical situations. The training set is gathered from an existing set of questions played in a long-running international trivia game show -- Family Feud. The hidden evaluation set is created by gathering answers for each question from 100 crowd-workers. We also propose an open-domain task where a model has to output a ranked list of answers, ideally covering all prototypical answers for a question. On evaluating our dataset with various competitive state-of-the-art models, we find there is a significant gap between the best model and human performance on a number of evaluation metrics.
Do Multi-hop Readers Dream of Reasoning Chains?
Oct 31, 2019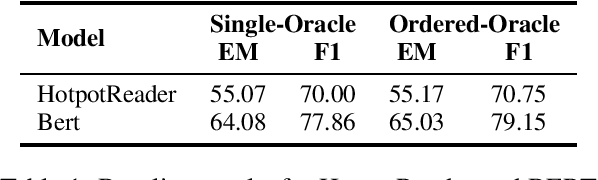
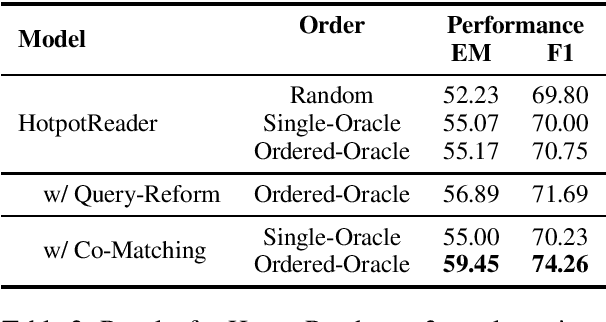

General Question Answering (QA) systems over texts require the multi-hop reasoning capability, i.e. the ability to reason with information collected from multiple passages to derive the answer. In this paper we conduct a systematic analysis to assess such an ability of various existing models proposed for multi-hop QA tasks. Specifically, our analysis investigates that whether providing the full reasoning chain of multiple passages, instead of just one final passage where the answer appears, could improve the performance of the existing QA models. Surprisingly, when using the additional evidence passages, the improvements of all the existing multi-hop reading approaches are rather limited, with the highest error reduction of 5.8% on F1 (corresponding to 1.3% absolute improvement) from the BERT model. To better understand whether the reasoning chains could indeed help find correct answers, we further develop a co-matching-based method that leads to 13.1% error reduction with passage chains when applied to two of our base readers (including BERT). Our results demonstrate the existence of the potential improvement using explicit multi-hop reasoning and the necessity to develop models with better reasoning abilities.
Multi-step Entity-centric Information Retrieval for Multi-Hop Question Answering
Sep 17, 2019
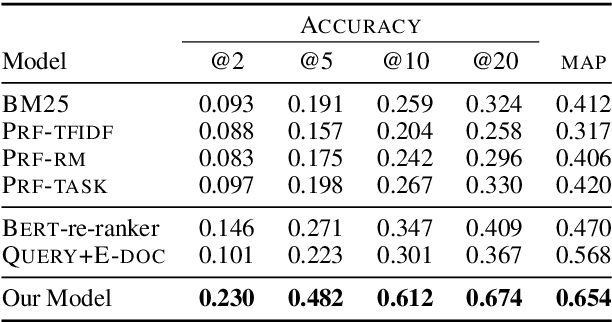
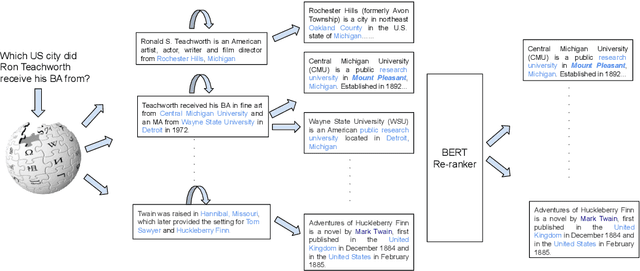
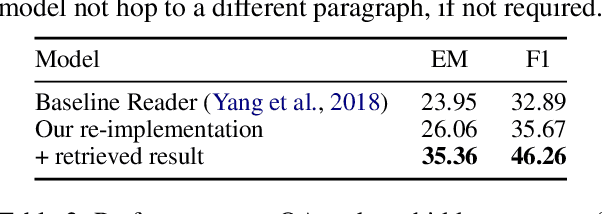
Multi-hop question answering (QA) requires an information retrieval (IR) system that can find \emph{multiple} supporting evidence needed to answer the question, making the retrieval process very challenging. This paper introduces an IR technique that uses information of entities present in the initially retrieved evidence to learn to `\emph{hop}' to other relevant evidence. In a setting, with more than \textbf{5 million} Wikipedia paragraphs, our approach leads to significant boost in retrieval performance. The retrieved evidence also increased the performance of an existing QA model (without any training) on the \hotpot benchmark by \textbf{10.59} F1.
Optimal Transport-based Alignment of Learned Character Representations for String Similarity
Jul 23, 2019



String similarity models are vital for record linkage, entity resolution, and search. In this work, we present STANCE --a learned model for computing the similarity of two strings. Our approach encodes the characters of each string, aligns the encodings using Sinkhorn Iteration (alignment is posed as an instance of optimal transport) and scores the alignment with a convolutional neural network. We evaluate STANCE's ability to detect whether two strings can refer to the same entity--a task we term alias detection. We construct five new alias detection datasets (and make them publicly available). We show that STANCE or one of its variants outperforms both state-of-the-art and classic, parameter-free similarity models on four of the five datasets. We also demonstrate STANCE's ability to improve downstream tasks by applying it to an instance of cross-document coreference and show that it leads to a 2.8 point improvement in B^3 F1 over the previous state-of-the-art approach.
Multi-step Retriever-Reader Interaction for Scalable Open-domain Question Answering
May 14, 2019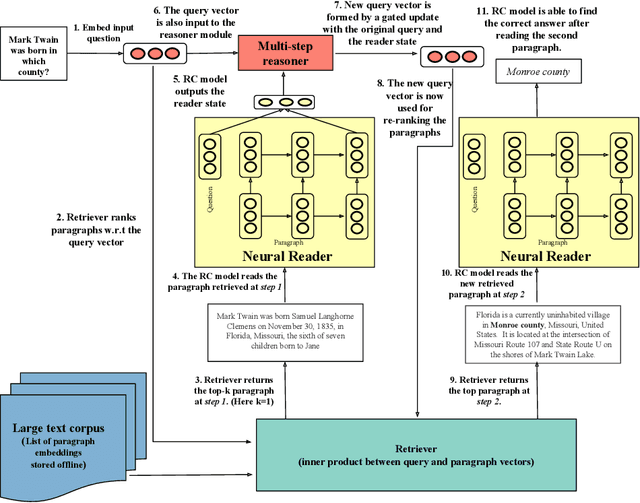
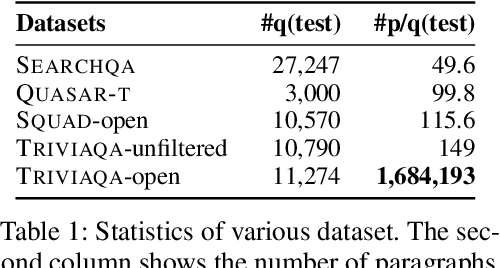
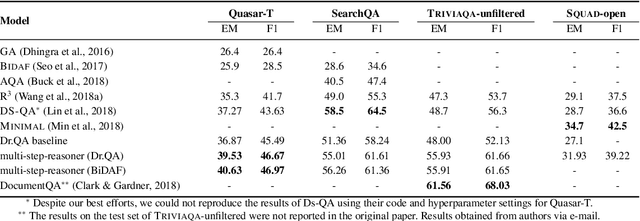
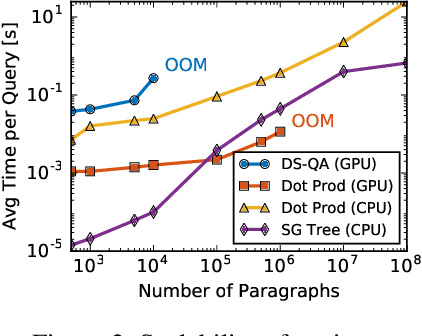
This paper introduces a new framework for open-domain question answering in which the retriever and the reader iteratively interact with each other. The framework is agnostic to the architecture of the machine reading model, only requiring access to the token-level hidden representations of the reader. The retriever uses fast nearest neighbor search to scale to corpora containing millions of paragraphs. A gated recurrent unit updates the query at each step conditioned on the state of the reader and the reformulated query is used to re-rank the paragraphs by the retriever. We conduct analysis and show that iterative interaction helps in retrieving informative paragraphs from the corpus. Finally, we show that our multi-step-reasoning framework brings consistent improvement when applied to two widely used reader architectures DrQA and BiDAF on various large open-domain datasets --- TriviaQA-unfiltered, QuasarT, SearchQA, and SQuAD-Open.