 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Inference with Corrupted Data: Measurement Error, Missing Values, Discretization, and Differential Privacy
Jul 06, 2021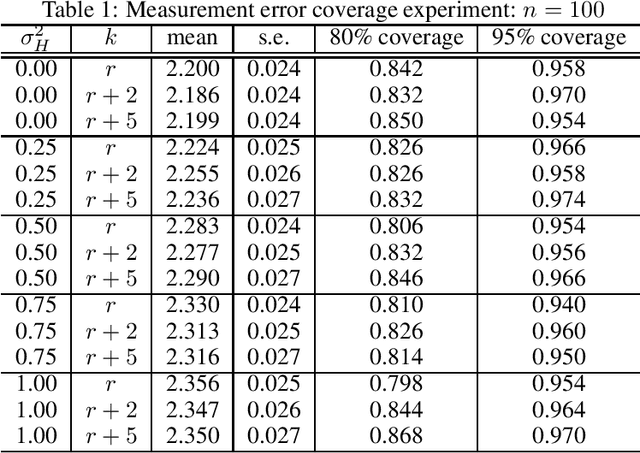
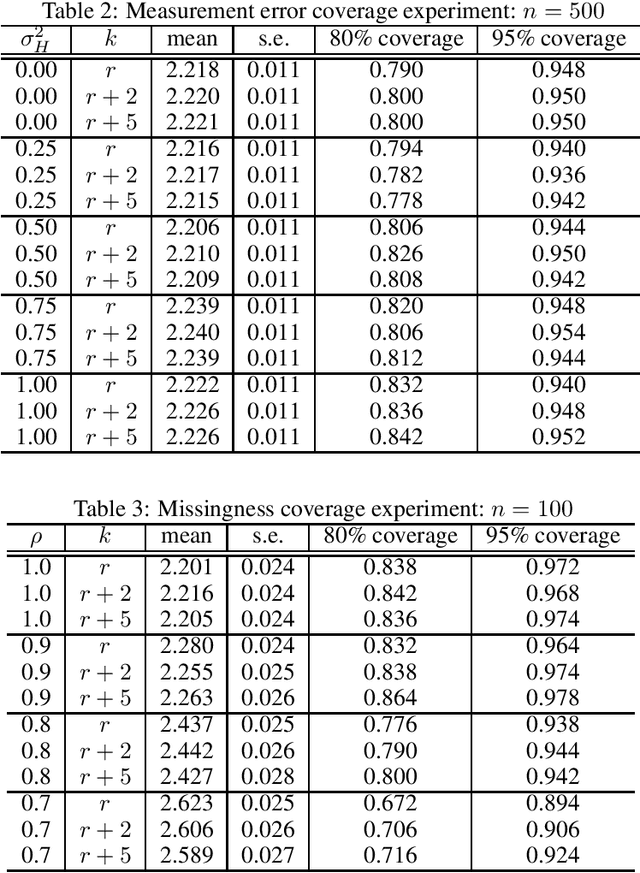
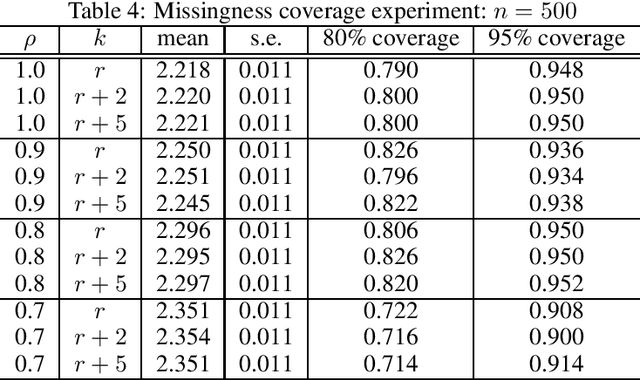
Even the most carefully curated economic data sets have variables that are noisy, missing, discretized, or privatized. The standard workflow for empirical research involves data cleaning followed by data analysis that typically ignores the bias and variance consequences of data cleaning. We formulate a semiparametric model for causal inference with corrupted data to encompass both data cleaning and data analysis. We propose a new end-to-end procedure for data cleaning, estimation, and inference with data cleaning-adjusted confidence intervals. We prove root-n consistency, Gaussian approximation, and semiparametric efficiency for our estimator of the causal parameter by finite sample arguments. Our key assumption is that the true covariates are approximately low rank. In our analysis, we provide nonasymptotic theoretical contributions to matrix completion, statistical learning, and semiparametric statistics. We verify the coverage of the data cleaning-adjusted confidence intervals in simulations.
A Simple and General Debiased Machine Learning Theorem with Finite Sample Guarantees
May 31, 2021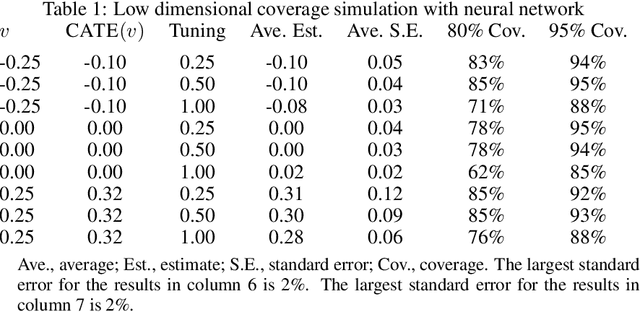
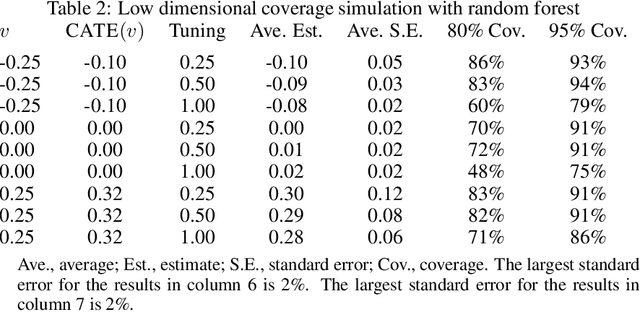
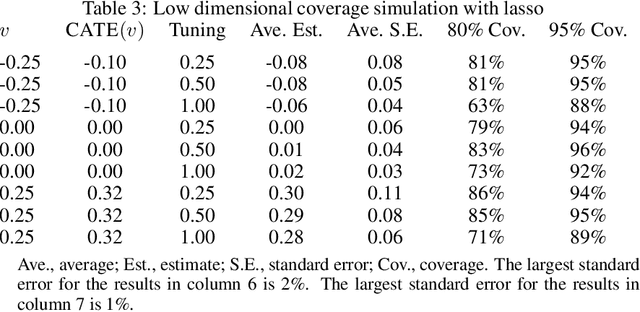
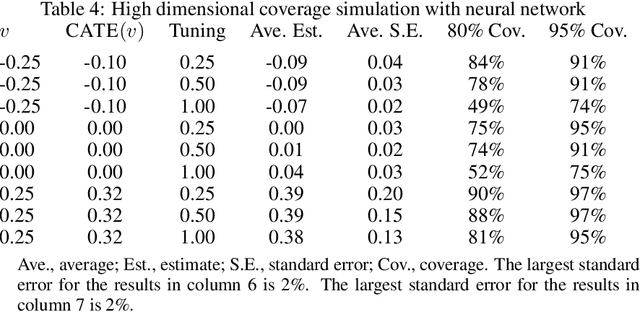
Debiased machine learning is a meta algorithm based on bias correction and sample splitting to calculate confidence intervals for functionals (i.e. scalar summaries) of machine learning algorithms. For example, an analyst may desire the confidence interval for a treatment effect estimated with a neural network. We provide a nonasymptotic debiased machine learning theorem that encompasses any global or local functional of any machine learning algorithm that satisfies a few simple, interpretable conditions. Formally, we prove consistency, Gaussian approximation, and semiparametric efficiency by finite sample arguments. The rate of convergence is root-n for global functionals, and it degrades gracefully for local functionals. Our results culminate in a simple set of conditions that an analyst can use to translate modern learning theory rates into traditional statistical inference. The conditions reveal a new double robustness property for ill posed inverse problems.
Self-interpretable Convolutional Neural Networks for Text Classification
May 18, 2021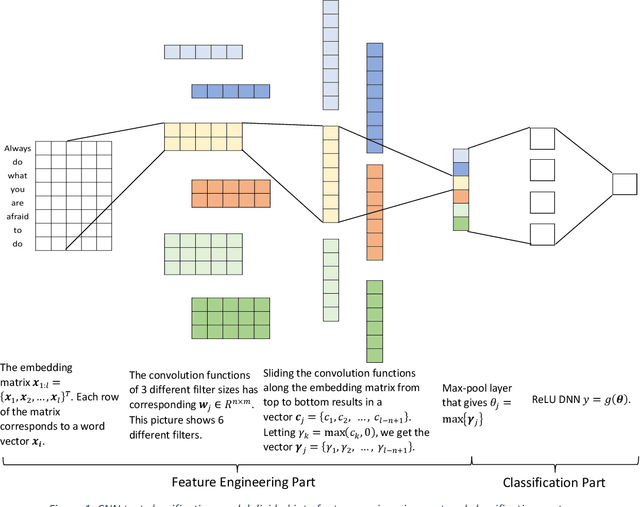
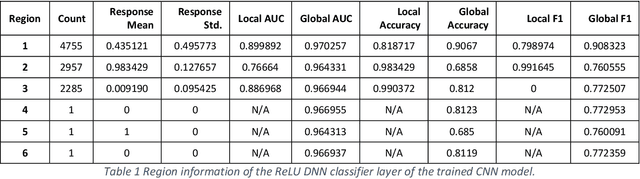
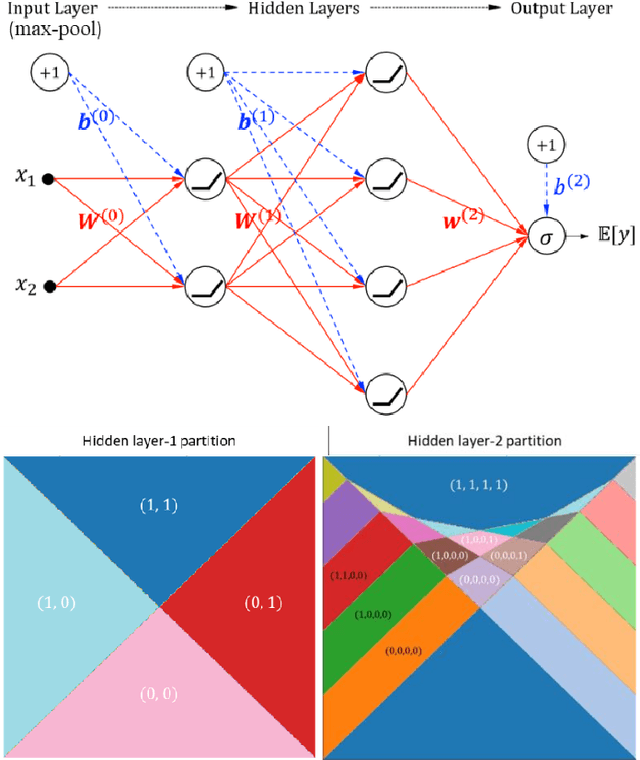
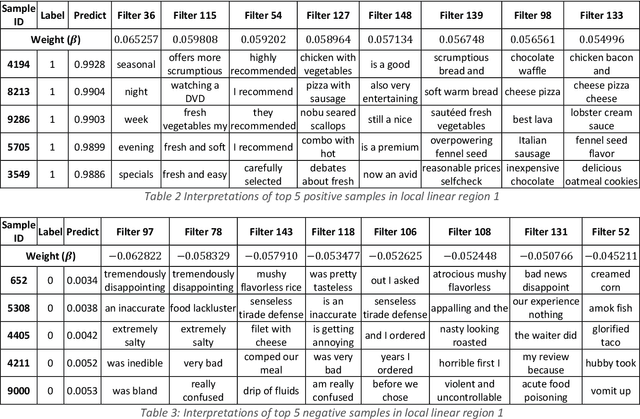
Deep learning models for natural language processing (NLP) are inherently complex and often viewed as black box in nature. This paper develops an approach for interpreting convolutional neural networks for text classification problems by exploiting the local-linear models inherent in ReLU-DNNs. The CNN model combines the word embedding through convolutional layers, filters them using max-pooling, and optimizes using a ReLU-DNN for classification. To get an overall self-interpretable model, the system of local linear models from the ReLU DNN are mapped back through the max-pool filter to the appropriate n-grams. Our results on experimental datasets demonstrate that our proposed technique produce parsimonious models that are self-interpretable and have comparable performance with respect to a more complex CNN model. We also study the impact of the complexity of the convolutional layers and the classification layers on the model performance.
Robustness Tests of NLP Machine Learning Models: Search and Semantically Replace
Apr 20, 2021
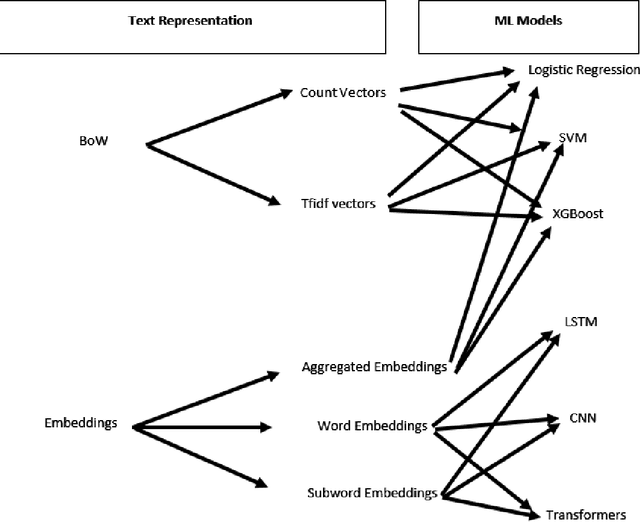
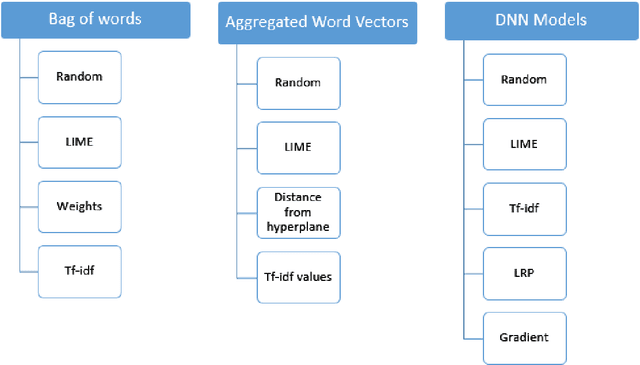
This paper proposes a strategy to assess the robustness of different machine learning models that involve natural language processing (NLP). The overall approach relies upon a Search and Semantically Replace strategy that consists of two steps: (1) Search, which identifies important parts in the text; (2) Semantically Replace, which finds replacements for the important parts, and constrains the replaced tokens with semantically similar words. We introduce different types of Search and Semantically Replace methods designed specifically for particular types of machine learning models. We also investigate the effectiveness of this strategy and provide a general framework to assess a variety of machine learning models. Finally, an empirical comparison is provided of robustness performance among three different model types, each with a different text representation.
Debiased Kernel Methods
Feb 22, 2021I propose a practical procedure based on bias correction and sample splitting to calculate confidence intervals for functionals of generic kernel methods, i.e. nonparametric estimators learned in a reproducing kernel Hilbert space (RKHS). For example, an analyst may desire confidence intervals for functionals of kernel ridge regression or kernel instrumental variable regression. The framework encompasses (i) evaluations over discrete domains, (ii) treatment effects of discrete treatments, and (iii) incremental treatment effects of continuous treatments. For the target quantity, whether it is (i)-(iii), I prove pointwise root-n consistency, Gaussian approximation, and semiparametric efficiency by finite sample arguments. I show that the classic assumptions of RKHS learning theory also imply inference.
Straggler-Resilient Distributed Machine Learning with Dynamic Backup Workers
Feb 11, 2021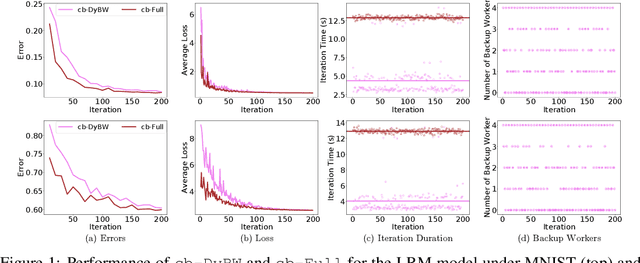

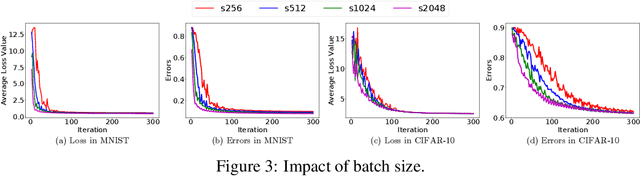
With the increasing demand for large-scale training of machine learning models, consensus-based distributed optimization methods have recently been advocated as alternatives to the popular parameter server framework. In this paradigm, each worker maintains a local estimate of the optimal parameter vector, and iteratively updates it by waiting and averaging all estimates obtained from its neighbors, and then corrects it on the basis of its local dataset. However, the synchronization phase can be time consuming due to the need to wait for \textit{stragglers}, i.e., slower workers. An efficient way to mitigate this effect is to let each worker wait only for updates from the fastest neighbors before updating its local parameter. The remaining neighbors are called \textit{backup workers.} To minimize the globally training time over the network, we propose a fully distributed algorithm to dynamically determine the number of backup workers for each worker. We show that our algorithm achieves a linear speedup for convergence (i.e., convergence performance increases linearly with respect to the number of workers). We conduct extensive experiments on MNIST and CIFAR-10 to verify our theoretical results.
Learning Augmented Index Policy for Optimal Service Placement at the Network Edge
Jan 14, 2021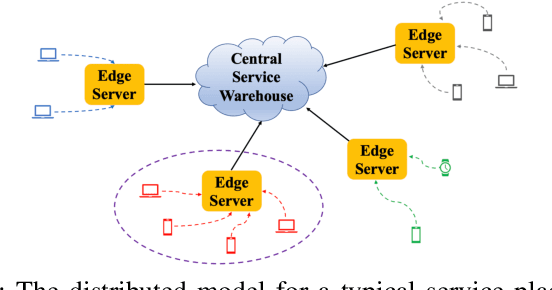
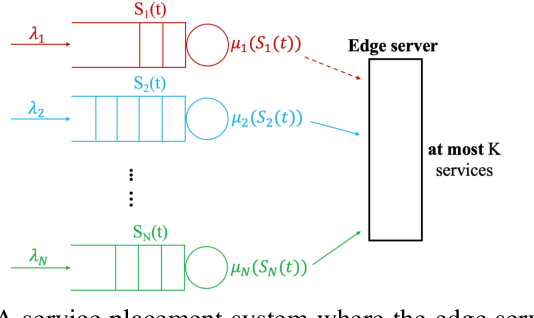
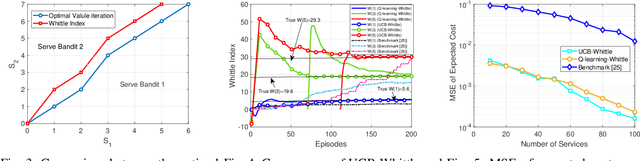

We consider the problem of service placement at the network edge, in which a decision maker has to choose between $N$ services to host at the edge to satisfy the demands of customers. Our goal is to design adaptive algorithms to minimize the average service delivery latency for customers. We pose the problem as a Markov decision process (MDP) in which the system state is given by describing, for each service, the number of customers that are currently waiting at the edge to obtain the service. However, solving this $N$-services MDP is computationally expensive due to the curse of dimensionality. To overcome this challenge, we show that the optimal policy for a single-service MDP has an appealing threshold structure, and derive explicitly the Whittle indices for each service as a function of the number of requests from customers based on the theory of Whittle index policy. Since request arrival and service delivery rates are usually unknown and possibly time-varying, we then develop efficient learning augmented algorithms that fully utilize the structure of optimal policies with a low learning regret. The first of these is UCB-Whittle, and relies upon the principle of optimism in the face of uncertainty. The second algorithm, Q-learning-Whittle, utilizes Q-learning iterations for each service by using a two time scale stochastic approximation. We characterize the non-asymptotic performance of UCB-Whittle by analyzing its learning regret, and also analyze the convergence properties of Q-learning-Whittle. Simulation results show that the proposed policies yield excellent empirical performance.
Adversarial Estimation of Riesz Representers
Dec 30, 2020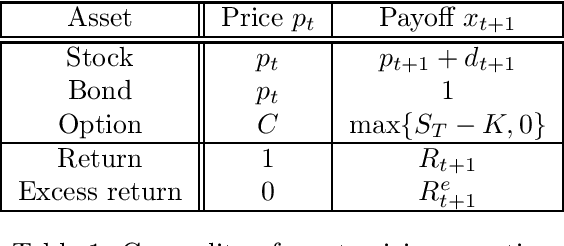
We provide an adversarial approach to estimating Riesz representers of linear functionals within arbitrary function spaces. We prove oracle inequalities based on the localized Rademacher complexity of the function space used to approximate the Riesz representer and the approximation error. These inequalities imply fast finite sample mean-squared-error rates for many function spaces of interest, such as high-dimensional sparse linear functions, neural networks and reproducing kernel Hilbert spaces. Our approach offers a new way of estimating Riesz representers with a plethora of recently introduced machine learning techniques. We show how our estimator can be used in the context of de-biasing structural/causal parameters in semi-parametric models, for automated orthogonalization of moment equations and for estimating the stochastic discount factor in the context of asset pricing.
Kernel Methods for Unobserved Confounding: Negative Controls, Proxies, and Instruments
Dec 18, 2020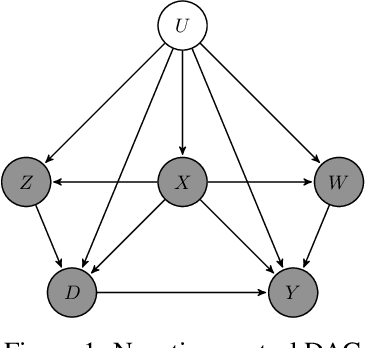
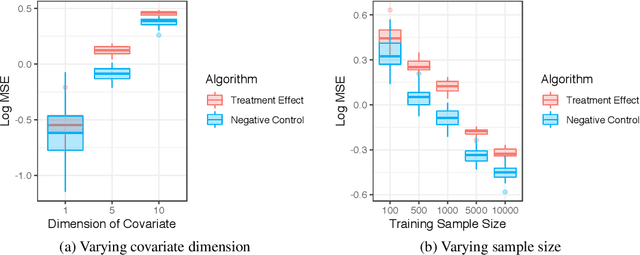
Negative control is a strategy for learning the causal relationship between treatment and outcome in the presence of unmeasured confounding. The treatment effect can nonetheless be identified if two auxiliary variables are available: a negative control treatment (which has no effect on the actual outcome), and a negative control outcome (which is not affected by the actual treatment). These auxiliary variables can also be viewed as proxies for a traditional set of control variables, and they bear resemblance to instrumental variables. I propose a new family of non-parametric algorithms for learning treatment effects with negative controls. I consider treatment effects of the population, of sub-populations, and of alternative populations. I allow for data that may be discrete or continuous, and low-, high-, or infinite-dimensional. I impose the additional structure of the reproducing kernel Hilbert space (RKHS), a popular non-parametric setting in machine learning. I prove uniform consistency and provide finite sample rates of convergence. I evaluate the estimators in simulations.
Learning Hidden Markov Models from Aggregate Observations
Nov 23, 2020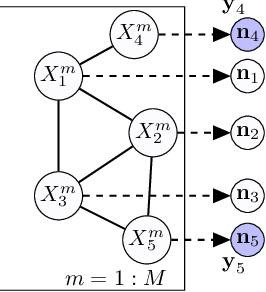
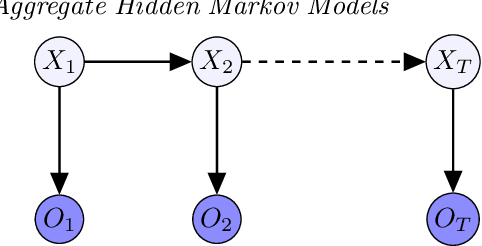
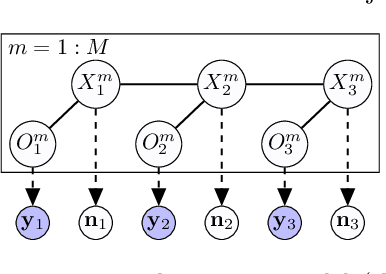
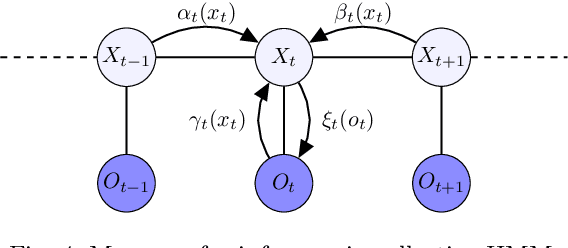
In this paper, we propose an algorithm for estimating the parameters of a time-homogeneous hidden Markov model from aggregate observations. This problem arises when only the population level counts of the number of individuals at each time step are available, from which one seeks to learn the individual hidden Markov model. Our algorithm is built upon expectation-maximization and the recently proposed aggregate inference algorithm, the Sinkhorn belief propagation. As compared with existing methods such as expectation-maximization with non-linear belief propagation, our algorithm exhibits convergence guarantees. Moreover, our learning framework naturally reduces to the standard Baum-Welch learning algorithm when observations corresponding to a single individual are recorded. We further extend our learning algorithm to handle HMMs with continuous observations. The efficacy of our algorithm is demonstrated on a variety of datasets.