 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Learning by Generating Task-specific Adapters
Jan 02, 2021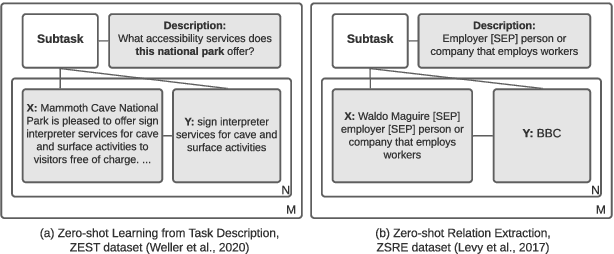

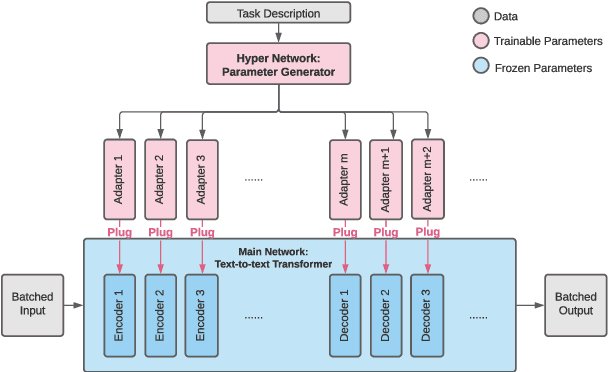
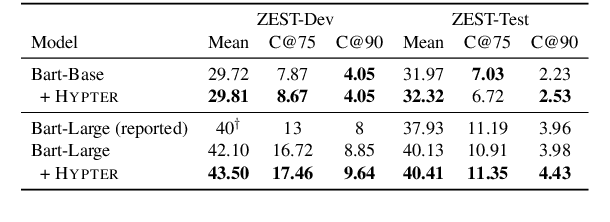
Pre-trained text-to-text transformers achieve impressive performance across a wide range of NLP tasks, and they naturally support zero-shot learning (ZSL) by using the task description as prompt in the input. However, this approach has potential limitations, as it learns from input-output pairs at instance level, instead of learning to solve tasks at task level. Alternatively, applying existing ZSL methods to text-to-text transformers is non-trivial due to their text generation objective and huge size. To address these issues, we introduce Hypter, a framework that improves zero-shot transferability by training a hypernetwork to generate task-specific adapters from task descriptions. This formulation enables learning at task level, and greatly reduces the number of parameters by using light-weight adapters. Experiments on two datasets demonstrate Hypter improves upon fine-tuning baselines.
Studying Strategically: Learning to Mask for Closed-book QA
Jan 01, 2021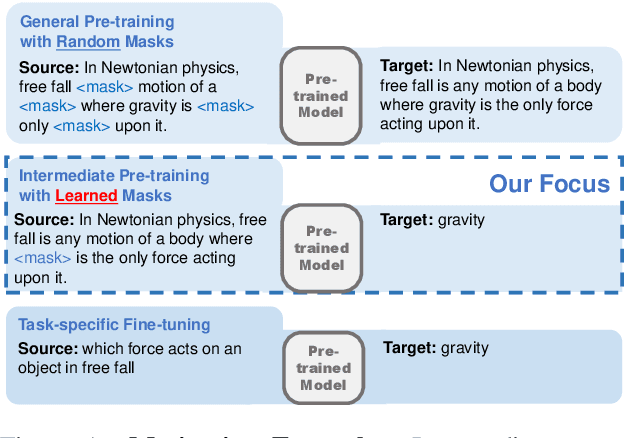

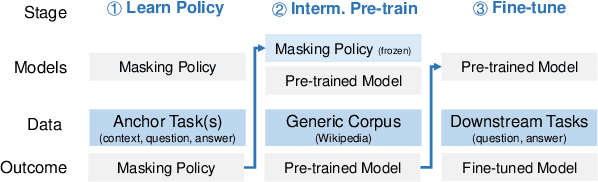

Closed-book question-answering (QA) is a challenging task that requires a model to directly answer questions without access to external knowledge. It has been shown that directly fine-tuning pre-trained language models with (question, answer) examples yields surprisingly competitive performance, which is further improved upon through adding an intermediate pre-training stage between general pre-training and fine-tuning. Prior work used a heuristic during this intermediate stage, whereby named entities and dates are masked, and the model is trained to recover these tokens. In this paper, we aim to learn the optimal masking strategy for the intermediate pre-training stage. We first train our masking policy to extract spans that are likely to be tested, using supervision from the downstream task itself, then deploy the learned policy during intermediate pre-training. Thus, our policy packs task-relevant knowledge into the parameters of a language model. Our approach is particularly effective on TriviaQA, outperforming strong heuristics when used to pre-train BART.
Teaching Machine Comprehension with Compositional Explanations
May 02, 2020


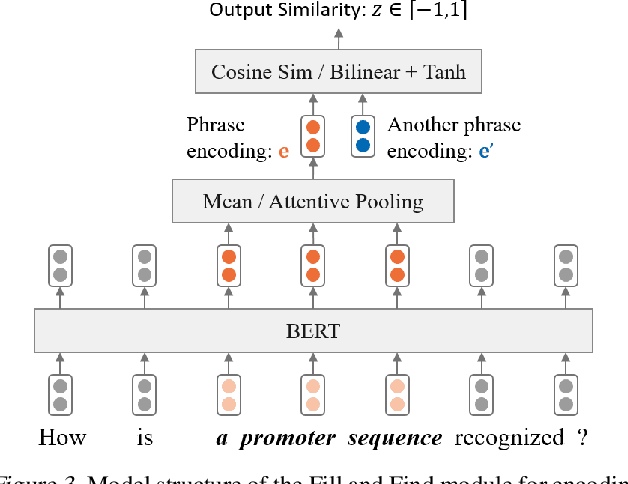
Advances in extractive machine reading comprehension (MRC) rely heavily on the collection of large scale human-annotated training data (in the form of "question-paragraph-answer span"). A single question-answer example provides limited supervision, while an explanation in natural language describing human's deduction process may generalize to many other questions that share similar solution patterns. In this paper, we focus on "teaching" machines on reading comprehension with (a small number of) natural language explanations. We propose a data augmentation framework that exploits the compositional nature of explanations to rapidly create pseudo-labeled data for training downstream MRC models. Structured variables and rules are extracted from each explanation and formulated into neural module teacher, which employs softened neural modules and combinatorial search to handle linguistic variations and overcome sparse coverage. The proposed work is particularly effective when limited annotation effort is available, and achieved a practicable F1 score of 59.80% with supervision from 52 explanations on the SQuAD dataset.
LEAN-LIFE: A Label-Efficient Annotation Framework Towards Learning from Explanation
Apr 16, 2020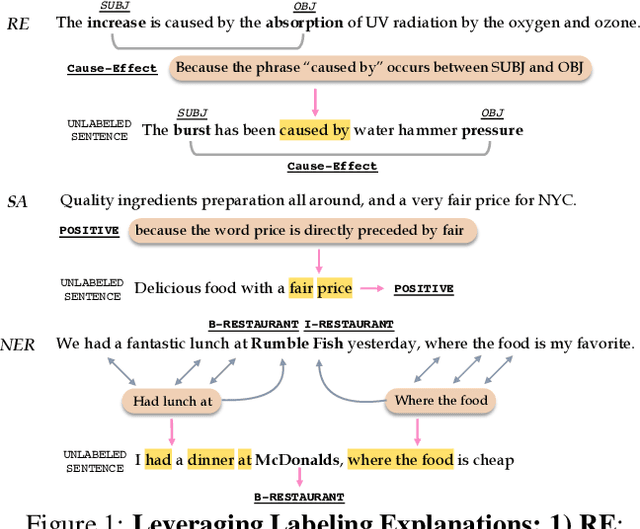
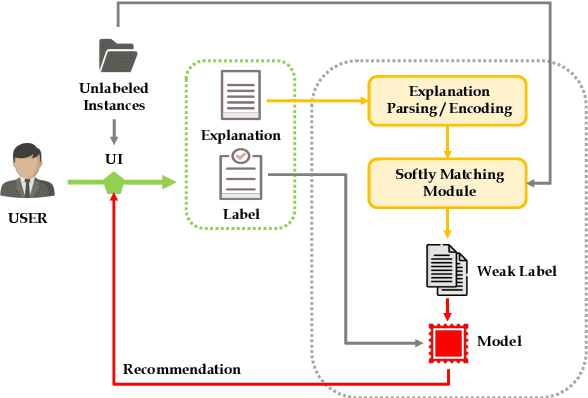

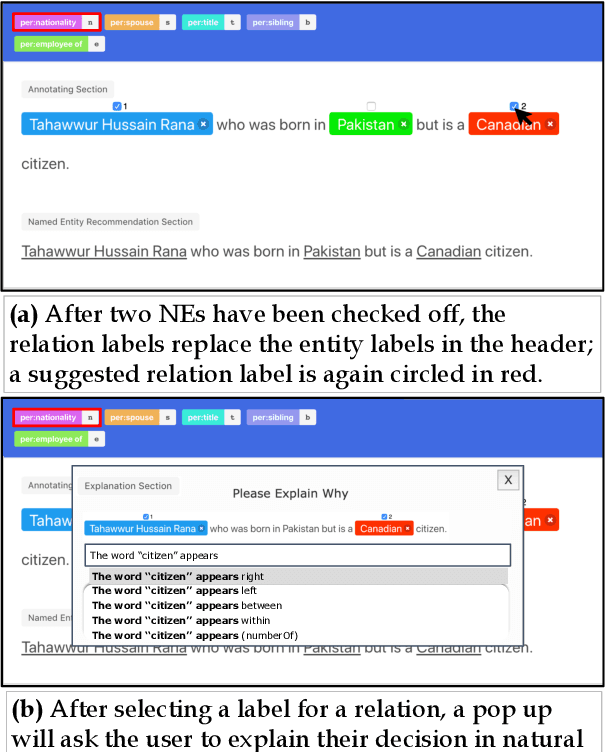
Successfully training a deep neural network demands a huge corpus of labeled data. However, each label only provides limited information to learn from and collecting the requisite number of labels involves massive human effort. In this work, we introduce LEAN-LIFE, a web-based, Label-Efficient AnnotatioN framework for sequence labeling and classification tasks, with an easy-to-use UI that not only allows an annotator to provide the needed labels for a task, but also enables LearnIng From Explanations for each labeling decision. Such explanations enable us to generate useful additional labeled data from unlabeled instances, bolstering the pool of available training data. On three popular NLP tasks (named entity recognition, relation extraction, sentiment analysis), we find that using this enhanced supervision allows our models to surpass competitive baseline F1 scores by more than 5-10 percentage points, while using 2X times fewer labeled instances. Our framework is the first to utilize this enhanced supervision technique and does so for three important tasks -- thus providing improved annotation recommendations to users and an ability to build datasets of (data, label, explanation) triples instead of the regular (data, label) pair.
Learning to Annotate: Modularizing Data Augmentation for Text Classifiers with Natural Language Explanations
Nov 07, 2019

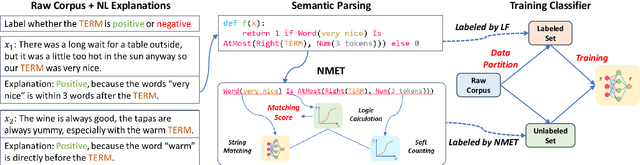
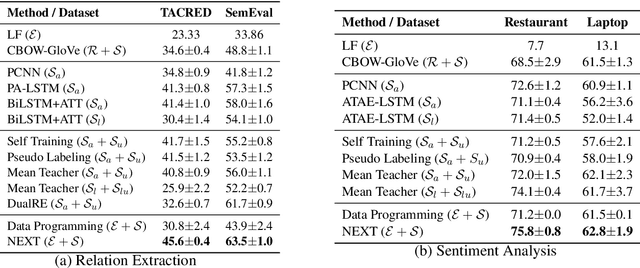
Deep neural networks usually require massive labeled data, which restricts their applications in scenarios where data annotation is expensive. Natural language (NL) explanations have been demonstrated very useful additional supervision, which can provide sufficient domain knowledge for generating more labeled data over new instances, while the annotation time only doubles. However, directly applying them for augmenting model learning encounters two challenges: (1) NL explanations are unstructured and inherently compositional. (2) NL explanations often have large numbers of linguistic variants, resulting in low recall and limited generalization ability. In this paper, we propose a novel Neural EXecution Tree (NEXT) framework to augment training data for text classification using NL explanations. After transforming NL explanations into executable logical forms by semantic parsing, NEXT generalizes different types of actions specified by the logical forms for labeling data instances, which substantially increases the coverage of each NL explanation. Experiments on two NLP tasks (relation extraction and sentiment analysis) demonstrate its superiority over baseline methods. Its extension to multi-hop question answering achieves performance gain with light annotation effort.
Looking Beyond Label Noise: Shifted Label Distribution Matters in Distantly Supervised Relation Extraction
Apr 19, 2019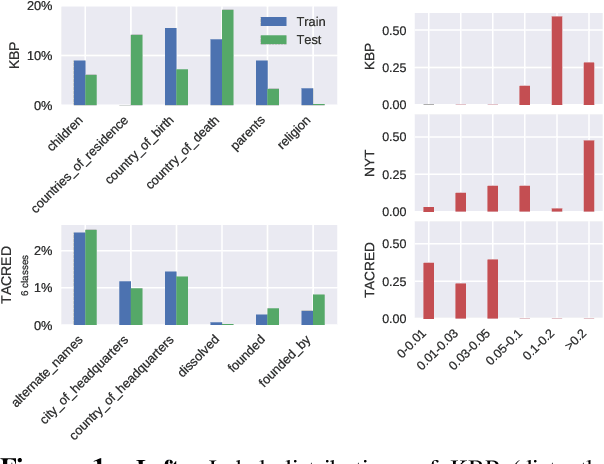
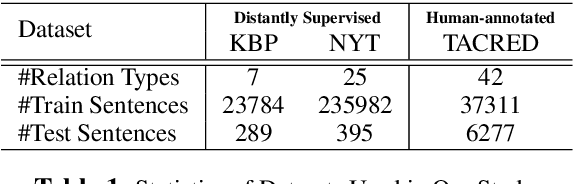
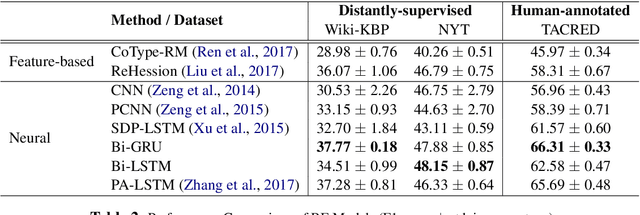
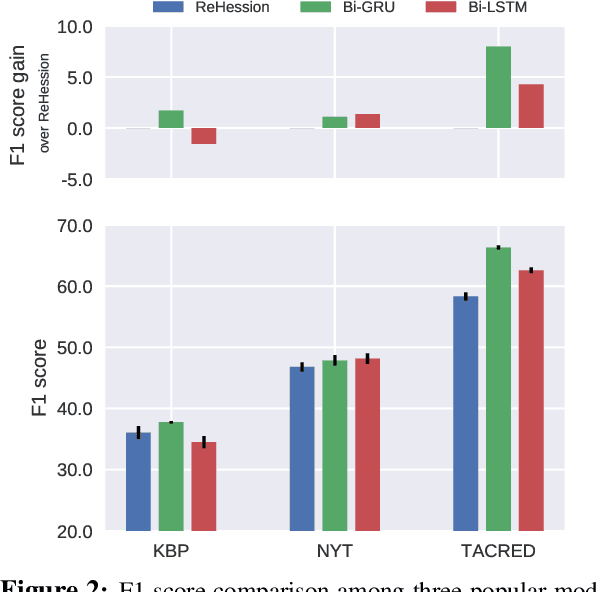
In recent years there is surge of interest in applying distant supervision (DS) to automatically generate training data for relation extraction. However, despite extensive efforts have been done on constructing advanced neural models, our experiments reveal that these neural models demonstrate only similar (or even worse) performance as compared with simple, feature-based methods. In this paper, we conduct thorough analysis to answer the question what other factors limit the performance of DS-trained neural models? Our results show that shifted labeled distribution commonly exists on real-world DS datasets, and impact of such issue is further validated using synthetic datasets for all models. Building upon the new insight, we develop a simple yet effective adaptation method for DS methods, called bias adjustment, to update models learned over source domain (i.e., DS training set) with label distribution statistics estimated on target domain (i.e., evaluation set). Experiments demonstrate that bias adjustment achieves consistent performance gains on all methods, especially on neural models, with up to a 22% relative F1 improvement.