 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Sink in Transformers: A Survey on Utilization, Interpretation, and Mitigation
Apr 11, 2026As the foundational architecture of modern machine learning, Transformers have driven remarkable progress across diverse AI domains. Despite their transformative impact, a persistent challenge across various Transformers is Attention Sink (AS), in which a disproportionate amount of attention is focused on a small subset of specific yet uninformative tokens. AS complicates interpretability, significantly affecting the training and inference dynamics, and exacerbates issues such as hallucinations. In recent years, substantial research has been dedicated to understanding and harnessing AS. However, a comprehensive survey that systematically consolidates AS-related research and offers guidance for future advancements remains lacking. To address this gap, we present the first survey on AS, structured around three key dimensions that define the current research landscape: Fundamental Utilization, Mechanistic Interpretation, and Strategic Mitigation. Our work provides a pivotal contribution by clarifying key concepts and guiding researchers through the evolution and trends of the field. We envision this survey as a definitive resource, empowering researchers and practitioners to effectively manage AS within the current Transformer paradigm, while simultaneously inspiring innovative advancements for the next generation of Transformers. The paper list of this work is available at https://github.com/ZunhaiSu/Awesome-Attention-Sink.
BPDQ: Bit-Plane Decomposition Quantization on a Variable Grid for Large Language Models
Feb 04, 2026Large language model (LLM) inference is often bounded by memory footprint and memory bandwidth in resource-constrained deployments, making quantization a fundamental technique for efficient serving. While post-training quantization (PTQ) maintains high fidelity at 4-bit, it deteriorates at 2-3 bits. Fundamentally, existing methods enforce a shape-invariant quantization grid (e.g., the fixed uniform intervals of UINT2) for each group, severely restricting the feasible set for error minimization. To address this, we propose Bit-Plane Decomposition Quantization (BPDQ), which constructs a variable quantization grid via bit-planes and scalar coefficients, and iteratively refines them using approximate second-order information while progressively compensating quantization errors to minimize output discrepancy. In the 2-bit regime, BPDQ enables serving Qwen2.5-72B on a single RTX 3090 with 83.85% GSM8K accuracy (vs. 90.83% at 16-bit). Moreover, we provide theoretical analysis showing that the variable grid expands the feasible set, and that the quantization process consistently aligns with the optimization objective in Hessian-induced geometry. Code: github.com/KingdalfGoodman/BPDQ.
Deep Learning for CSI Feedback Based on Superimposed Coding
Jul 27, 2019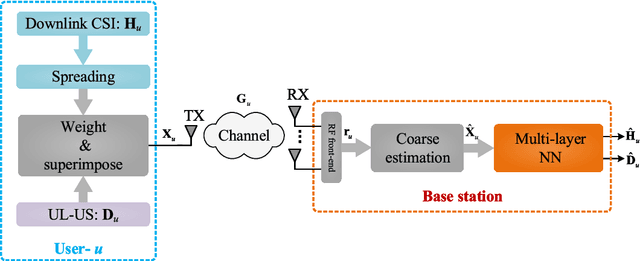
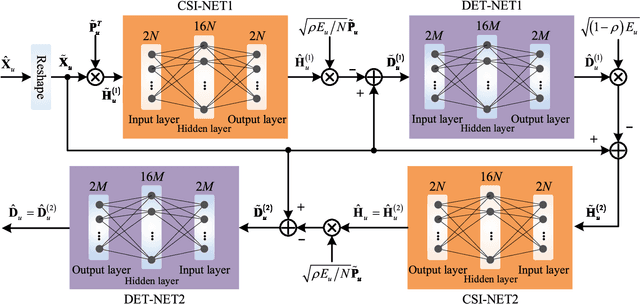
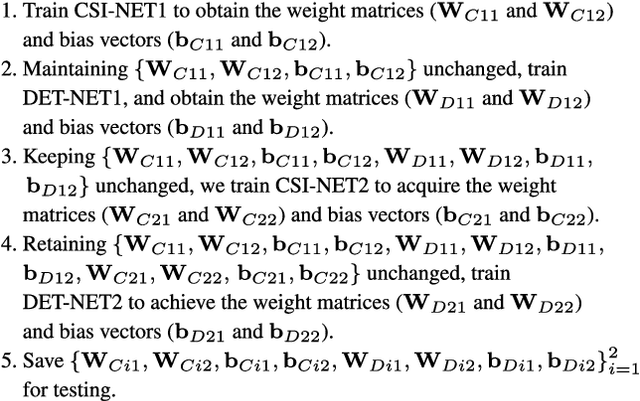
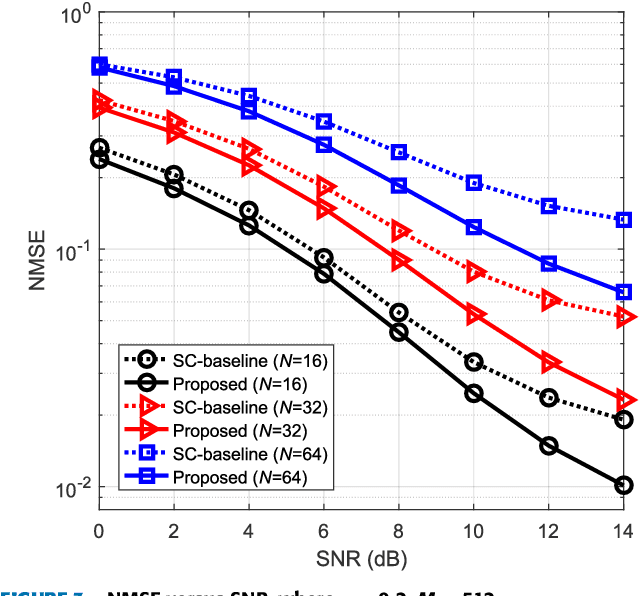
Massive multiple-input multiple-output (MIMO) with frequency division duplex (FDD) mode is a promising approach to increasing system capacity and link robustness for the fifth generation (5G) wireless cellular systems. The premise of these advantages is the accurate downlink channel state information (CSI) fed back from user equipment. However, conventional feedback methods have difficulties in reducing feedback overhead due to significant amount of base station (BS) antennas in massive MIMO systems. Recently, deep learning (DL)-based CSI feedback conquers many difficulties, yet still shows insufficiency to decrease the occupation of uplink bandwidth resources. In this paper, to solve this issue, we combine DL and superimposed coding (SC) for CSI feedback, in which the downlink CSI is spread and then superimposed on uplink user data sequences (UL-US) toward the BS. Then, a multi-task neural network (NN) architecture is proposed at BS to recover the downlink CSI and UL-US by unfolding two iterations of the minimum mean-squared error (MMSE) criterion-based interference reduction. In addition, for a network training, a subnet-by-subnet approach is exploited to facilitate the parameter tuning and expedite the convergence rate. Compared with standalone SC-based CSI scheme, our multi-task NN, trained in a specific signal-to-noise ratio (SNR) and power proportional coefficient (PPC), consistently improves the estimation of downlink CSI with similar or better UL-US detection under SNR and PPC varying.