 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncoding Heterogeneous Social and Political Context for Entity Stance Prediction
Sep 07, 2021
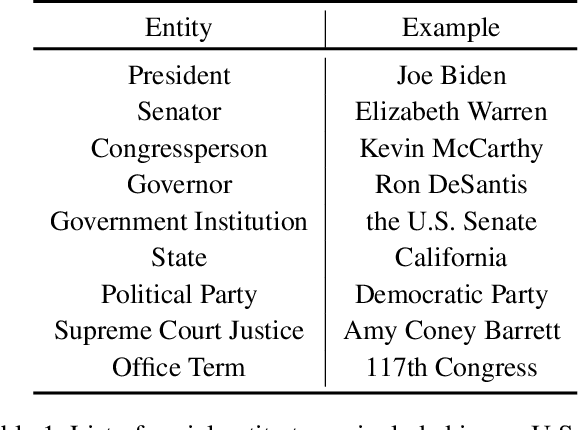

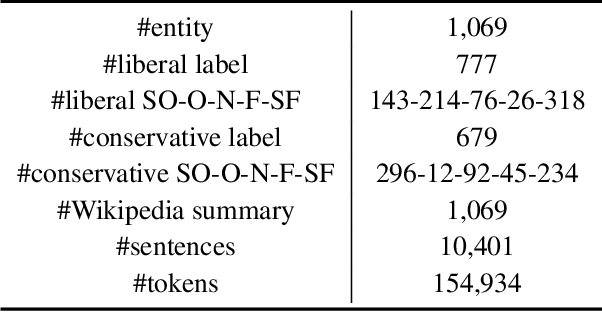
Political stance detection has become an important task due to the increasingly polarized political ideologies. Most existing works focus on identifying perspectives in news articles or social media posts, while social entities, such as individuals and organizations, produce these texts and actually take stances. In this paper, we propose the novel task of entity stance prediction, which aims to predict entities' stances given their social and political context. Specifically, we retrieve facts from Wikipedia about social entities regarding contemporary U.S. politics. We then annotate social entities' stances towards political ideologies with the help of domain experts. After defining the task of entity stance prediction, we propose a graph-based solution, which constructs a heterogeneous information network from collected facts and adopts gated relational graph convolutional networks for representation learning. Our model is then trained with a combination of supervised, self-supervised and unsupervised loss functions, which are motivated by multiple social and political phenomenons. We conduct extensive experiments to compare our method with existing text and graph analysis baselines. Our model achieves highest stance detection accuracy and yields inspiring insights regarding social entity stances. We further conduct ablation study and parameter analysis to study the mechanism and effectiveness of our proposed approach.
Knowledge Graph Augmented Political Perspective Detection in News Media
Sep 07, 2021


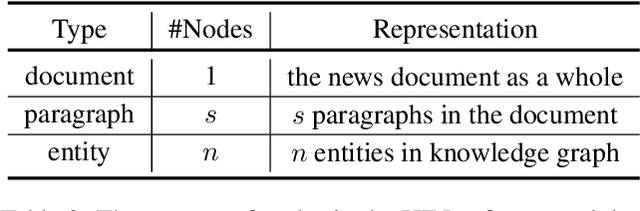
Identifying political perspective in news media has become an important task due to the rapid growth of political commentary and the increasingly polarized ideologies. Previous approaches only focus on leveraging the semantic information and leaves out the rich social and political context that helps individuals understand political stances. In this paper, we propose a perspective detection method that incorporates external knowledge of real-world politics. Specifically, we construct a contemporary political knowledge graph with 1,071 entities and 10,703 triples. We then build a heterogeneous information network for each news document that jointly models article semantics and external knowledge in knowledge graphs. Finally, we apply gated relational graph convolutional networks and conduct political perspective detection as graph-level classification. Extensive experiments show that our method achieves the best performance and outperforms state-of-the-art methods by 5.49%. Numerous ablation studies further bear out the necessity of external knowledge and the effectiveness of our graph-based approach.
Semantics-Guided Contrastive Network for Zero-Shot Object detection
Sep 04, 2021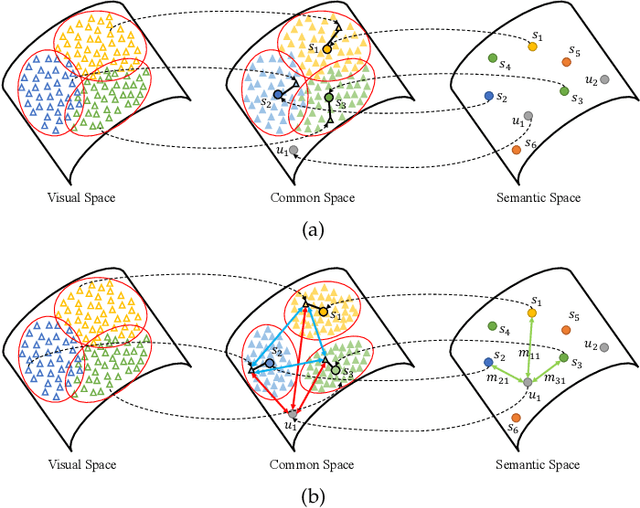
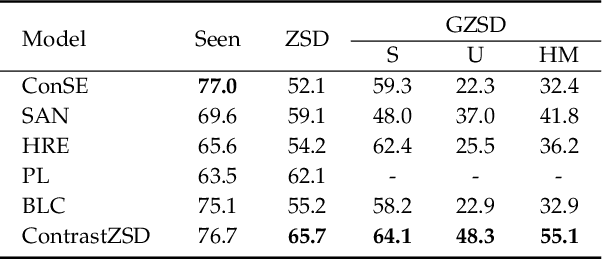
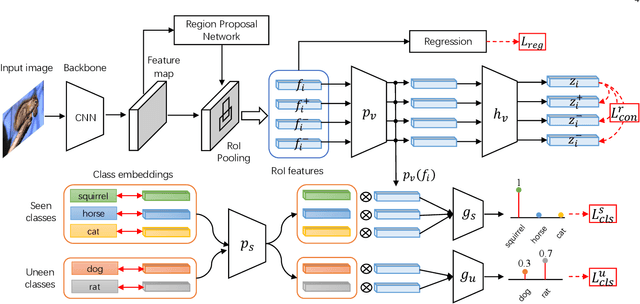
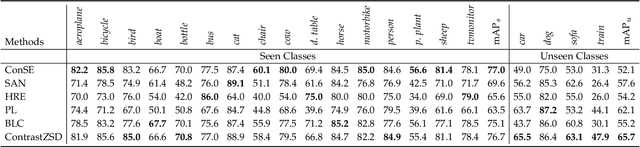
Zero-shot object detection (ZSD), the task that extends conventional detection models to detecting objects from unseen categories, has emerged as a new challenge in computer vision. Most existing approaches tackle the ZSD task with a strict mapping-transfer strategy, which may lead to suboptimal ZSD results: 1) the learning process of those models ignores the available unseen class information, and thus can be easily biased towards the seen categories; 2) the original visual feature space is not well-structured and lack of discriminative information. To address these issues, we develop a novel Semantics-Guided Contrastive Network for ZSD, named ContrastZSD, a detection framework that first brings contrastive learning mechanism into the realm of zero-shot detection. Particularly, ContrastZSD incorporates two semantics-guided contrastive learning subnets that contrast between region-category and region-region pairs respectively. The pairwise contrastive tasks take advantage of additional supervision signals derived from both ground truth label and pre-defined class similarity distribution. Under the guidance of those explicit semantic supervision, the model can learn more knowledge about unseen categories to avoid the bias problem to seen concepts, while optimizing the data structure of visual features to be more discriminative for better visual-semantic alignment. Extensive experiments are conducted on two popular benchmarks for ZSD, i.e., PASCAL VOC and MS COCO. Results show that our method outperforms the previous state-of-the-art on both ZSD and generalized ZSD tasks.
Annotation of Chinese Predicate Heads and Relevant Elements
Apr 01, 2021
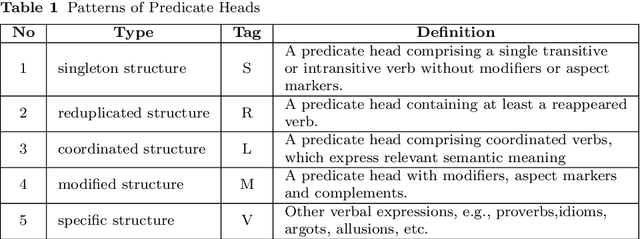
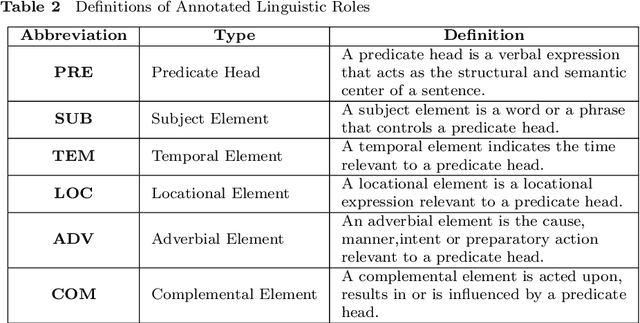
A predicate head is a verbal expression that plays a role as the structural center of a sentence. Identifying predicate heads is critical to understanding a sentence. It plays the leading role in organizing the relevant syntactic elements in a sentence, including subject elements, adverbial elements, etc. For some languages, such as English, word morphologies are valuable for identifying predicate heads. However, Chinese offers no morphological information to indicate words` grammatical roles. A Chinese sentence often contains several verbal expressions; identifying the expression that plays the role of the predicate head is not an easy task. Furthermore, Chinese sentences are inattentive to structure and provide no delimitation between words. Therefore, identifying Chinese predicate heads involves significant challenges. In Chinese information extraction, little work has been performed in predicate head recognition. No generally accepted evaluation dataset supports work in this important area. This paper presents the first attempt to develop an annotation guideline for Chinese predicate heads and their relevant syntactic elements. This annotation guideline emphasizes the role of the predicate as the structural center of a sentence. The design of relevant syntactic element annotation also follows this principle. Many considerations are proposed to achieve this goal, e.g., patterns of predicate heads, a flattened annotation structure, and a simpler syntactic unit type. Based on the proposed annotation guideline, more than 1,500 documents were manually annotated. The corpus will be available online for public access. With this guideline and annotated corpus, our goal is to broadly impact and advance the research in the area of Chinese information extraction and to provide the research community with a critical resource that has been lacking for a long time.
Towards Entity Alignment in the Open World: An Unsupervised Approach
Jan 26, 2021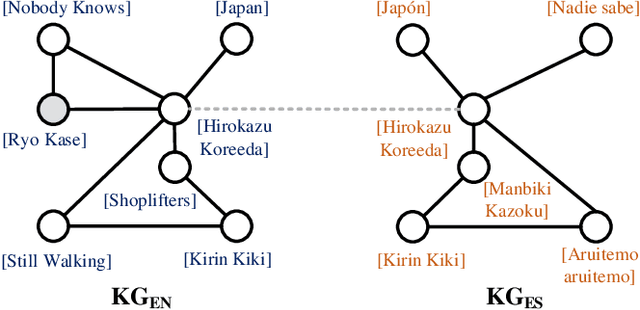
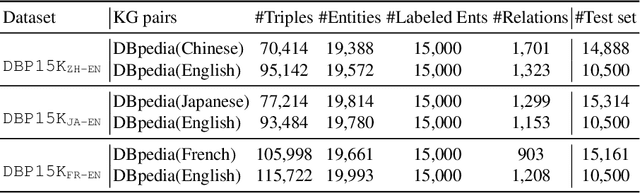
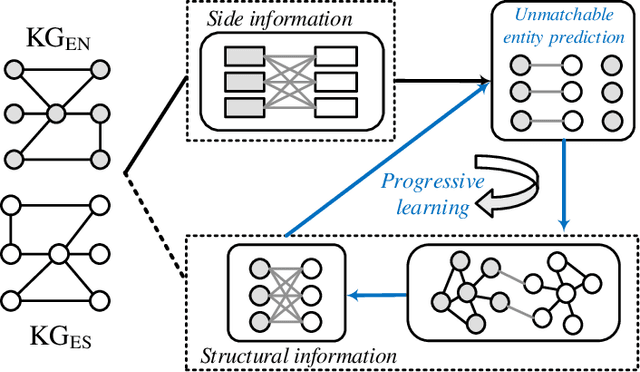
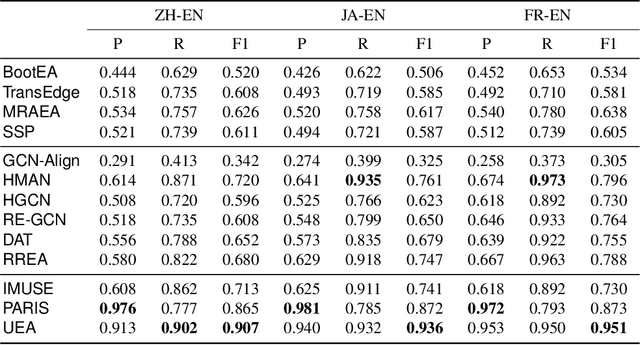
Entity alignment (EA) aims to discover the equivalent entities in different knowledge graphs (KGs). It is a pivotal step for integrating KGs to increase knowledge coverage and quality. Recent years have witnessed a rapid increase of EA frameworks. However, state-of-the-art solutions tend to rely on labeled data for model training. Additionally, they work under the closed-domain setting and cannot deal with entities that are unmatchable. To address these deficiencies, we offer an unsupervised framework that performs entity alignment in the open world. Specifically, we first mine useful features from the side information of KGs. Then, we devise an unmatchable entity prediction module to filter out unmatchable entities and produce preliminary alignment results. These preliminary results are regarded as the pseudo-labeled data and forwarded to the progressive learning framework to generate structural representations, which are integrated with the side information to provide a more comprehensive view for alignment. Finally, the progressive learning framework gradually improves the quality of structural embeddings and enhances the alignment performance by enriching the pseudo-labeled data with alignment results from the previous round. Our solution does not require labeled data and can effectively filter out unmatchable entities. Comprehensive experimental evaluations validate its superiority.
A Boundary Regression Model for Nested Named Entity Recognition
Dec 27, 2020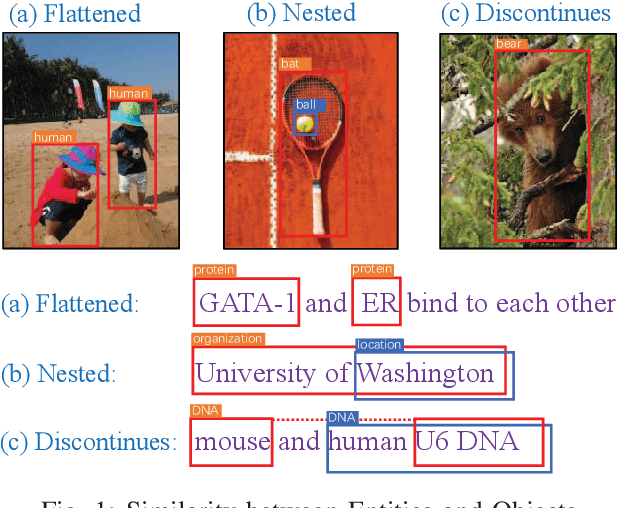
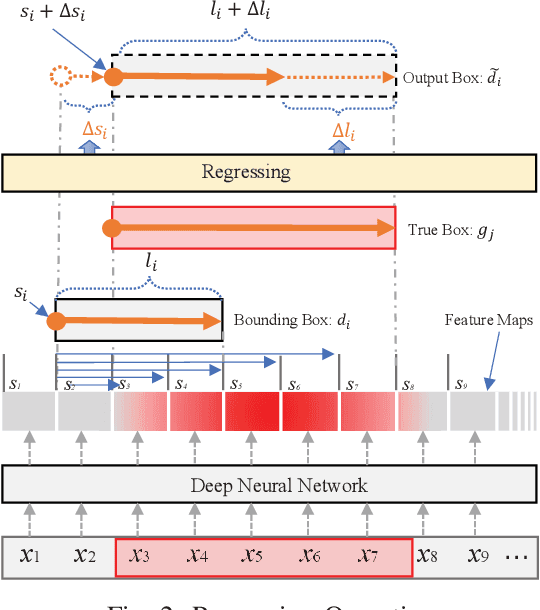
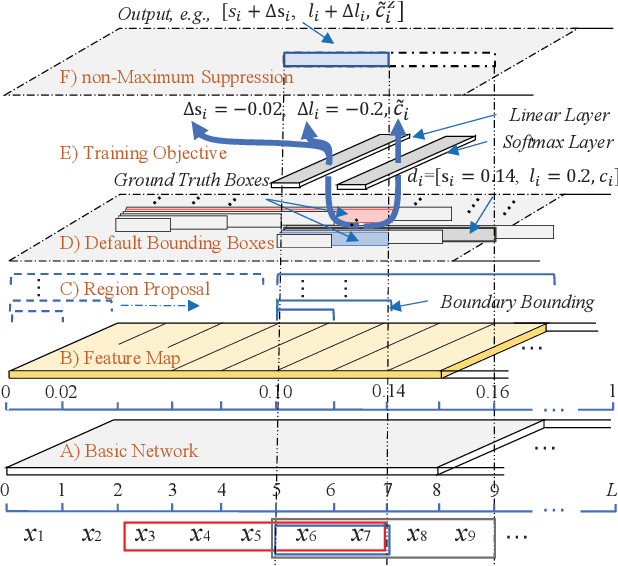
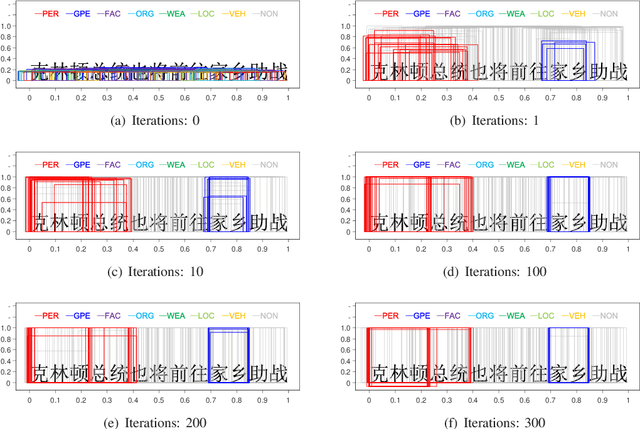
Recognizing named entities (NEs) is commonly conducted as a classification problem that predicts a class tag for an NE candidate in a sentence. In shallow structures, categorized features are weighted to support the prediction. Recent developments in neural networks have adopted deep structures that map categorized features into continuous representations. This approach unfolds a dense space saturated with high-order abstract semantic information, where the prediction is based on distributed feature representations. In this paper, the regression operation is introduced to locate NEs in a sentence. In this approach, a deep network is first designed to transform an input sentence into recurrent feature maps. Bounding boxes are generated from the feature maps, where a box is an abstract representation of an NE candidate. In addition to the class tag, each bounding box has two parameters denoting the start position and the length of an NE candidate. In the training process, the location offset between a bounding box and a true NE are learned to minimize the location loss. Based on this motivation, a multiobjective learning framework is designed to simultaneously locate entities and predict the class probability. By sharing parameters for locating and predicting, the framework can take full advantage of annotated data and enable more potent nonlinear function approximators to enhance model discriminability. Experiments demonstrate state-of-the-art performance for nested named entities\footnote{Our codes will be available at: \url{https://github.com/wuyuefei3/BR}}.
XTQA: Span-Level Explanations of the Textbook Question Answering
Dec 17, 2020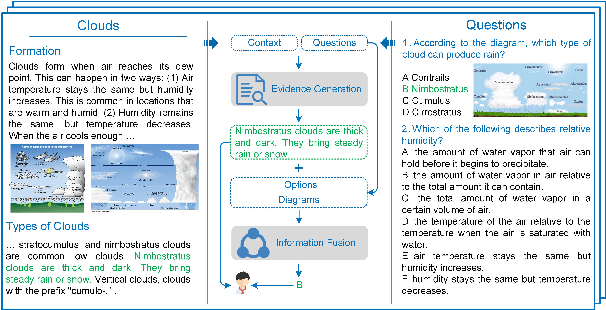
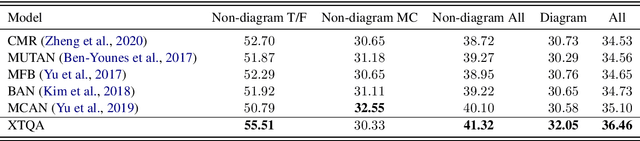
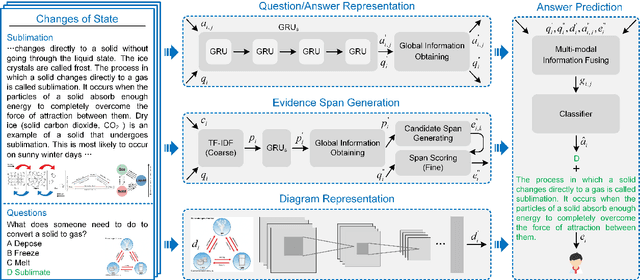
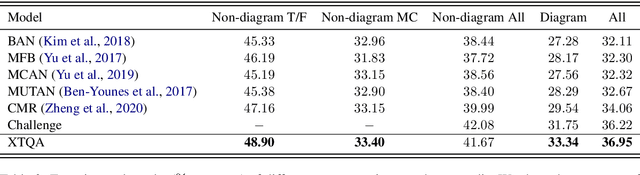
Textbook Question Answering (TQA) is a task that one should answer a diagram/non-diagram question given a large multi-modal context consisting of abundant essays and diagrams. We argue that the explainability of this task should place students as a key aspect to be considered. To address this issue, we devise a novel architecture towards span-level eXplanations of the TQA (XTQA) based on our proposed coarse-to-fine grained algorithm, which can provide not only the answers but also the span-level evidences to choose them for students. This algorithm first coarsely chooses top $M$ paragraphs relevant to questions using the TF-IDF method, and then chooses top $K$ evidence spans finely from all candidate spans within these paragraphs by computing the information gain of each span to questions. Experimental results shows that XTQA significantly improves the state-of-the-art performance compared with baselines. The source code is available at https://github.com/keep-smile-001/opentqa
Self-Weighted Robust LDA for Multiclass Classification with Edge Classes
Sep 24, 2020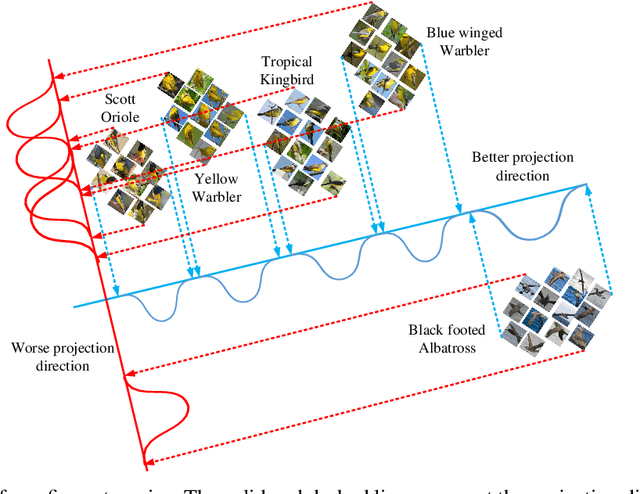
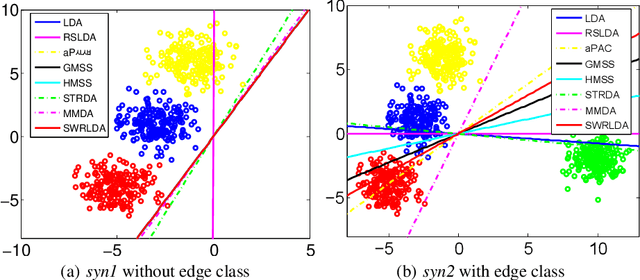
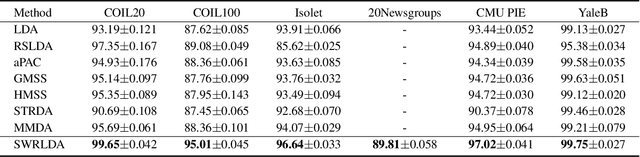
Linear discriminant analysis (LDA) is a popular technique to learn the most discriminative features for multi-class classification. A vast majority of existing LDA algorithms are prone to be dominated by the class with very large deviation from the others, i.e., edge class, which occurs frequently in multi-class classification. First, the existence of edge classes often makes the total mean biased in the calculation of between-class scatter matrix. Second, the exploitation of l2-norm based between-class distance criterion magnifies the extremely large distance corresponding to edge class. In this regard, a novel self-weighted robust LDA with l21-norm based pairwise between-class distance criterion, called SWRLDA, is proposed for multi-class classification especially with edge classes. SWRLDA can automatically avoid the optimal mean calculation and simultaneously learn adaptive weights for each class pair without setting any additional parameter. An efficient re-weighted algorithm is exploited to derive the global optimum of the challenging l21-norm maximization problem. The proposed SWRLDA is easy to implement, and converges fast in practice. Extensive experiments demonstrate that SWRLDA performs favorably against other compared methods on both synthetic and real-world datasets, while presenting superior computational efficiency in comparison with other techniques.
DWMD: Dimensional Weighted Orderwise Moment Discrepancy for Domain-specific Hidden Representation Matching
Jul 18, 2020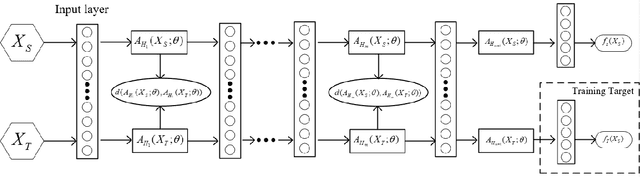
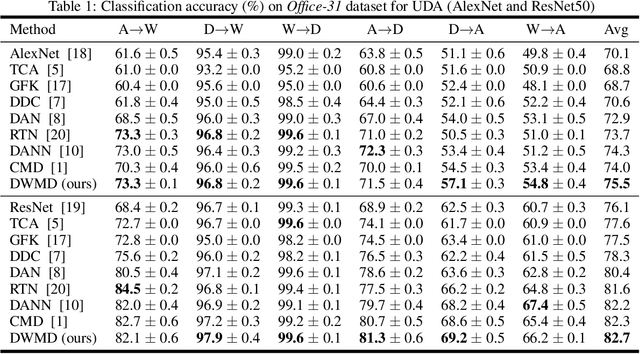
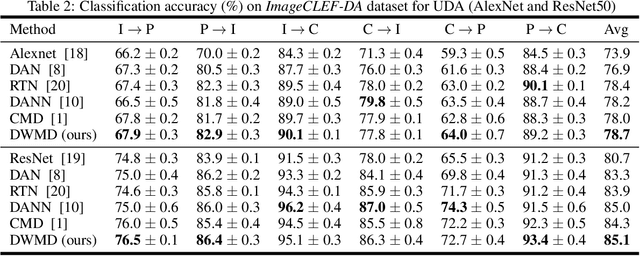
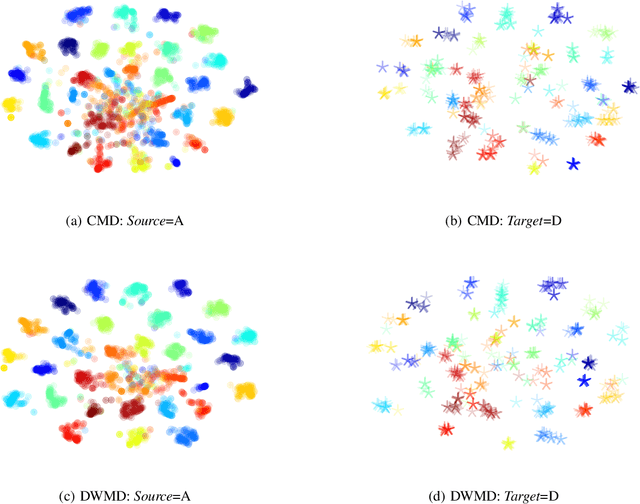
Knowledge transfer from a source domain to a different but semantically related target domain has long been an important topic in the context of unsupervised domain adaptation (UDA). A key challenge in this field is establishing a metric that can exactly measure the data distribution discrepancy between two homogeneous domains and adopt it in distribution alignment, especially in the matching of feature representations in the hidden activation space. Existing distribution matching approaches can be interpreted as failing to either explicitly orderwise align higher-order moments or satisfy the prerequisite of certain assumptions in practical uses. We propose a novel moment-based probability distribution metric termed dimensional weighted orderwise moment discrepancy (DWMD) for feature representation matching in the UDA scenario. Our metric function takes advantage of a series for high-order moment alignment, and we theoretically prove that our DWMD metric function is error-free, which means that it can strictly reflect the distribution differences between domains and is valid without any feature distribution assumption. In addition, since the discrepancies between probability distributions in each feature dimension are different, dimensional weighting is considered in our function. We further calculate the error bound of the empirical estimate of the DWMD metric in practical applications. Comprehensive experiments on benchmark datasets illustrate that our method yields state-of-the-art distribution metrics.
Scalable Attack on Graph Data by Injecting Vicious Nodes
Apr 22, 2020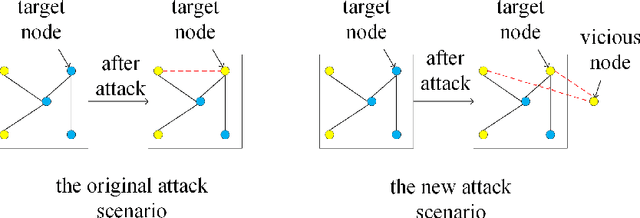
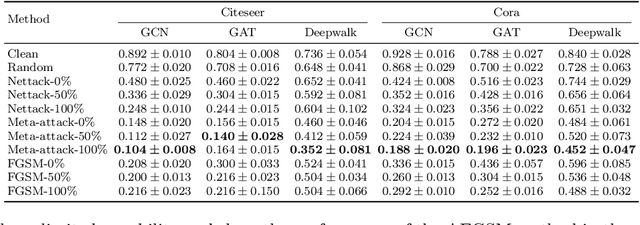
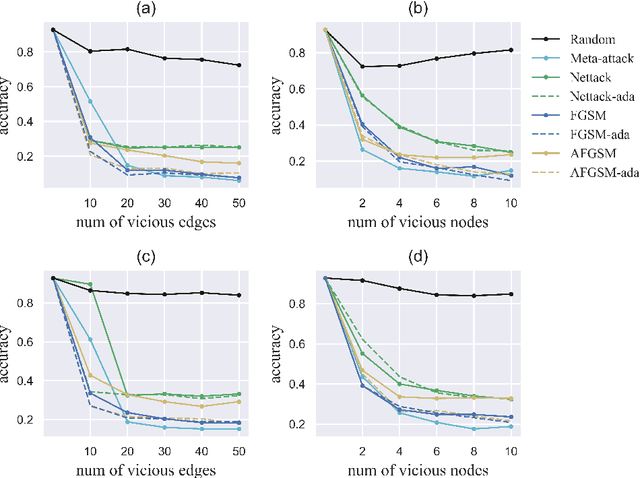
Recent studies have shown that graph convolution networks (GCNs) are vulnerable to carefully designed attacks, which aim to cause misclassification of a specific node on the graph with unnoticeable perturbations. However, a vast majority of existing works cannot handle large-scale graphs because of their high time complexity. Additionally, existing works mainly focus on manipulating existing nodes on the graph, while in practice, attackers usually do not have the privilege to modify information of existing nodes. In this paper, we develop a more scalable framework named Approximate Fast Gradient Sign Method (AFGSM) which considers a more practical attack scenario where adversaries can only inject new vicious nodes to the graph while having no control over the original graph. Methodologically, we provide an approximation strategy to linearize the model we attack and then derive an approximate closed-from solution with a lower time cost. To have a fair comparison with existing attack methods that manipulate the original graph, we adapt them to the new attack scenario by injecting vicious nodes. Empirical experimental results show that our proposed attack method can significantly reduce the classification accuracy of GCNs and is much faster than existing methods without jeopardizing the attack performance.