 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBIC: Twitter Bot Detection with Text-Graph Interaction and Semantic Consistency
Aug 17, 2022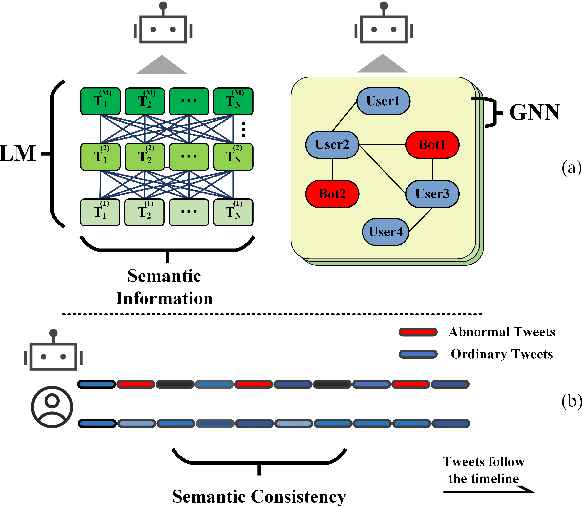
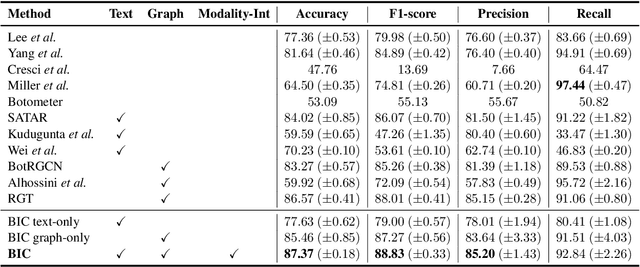
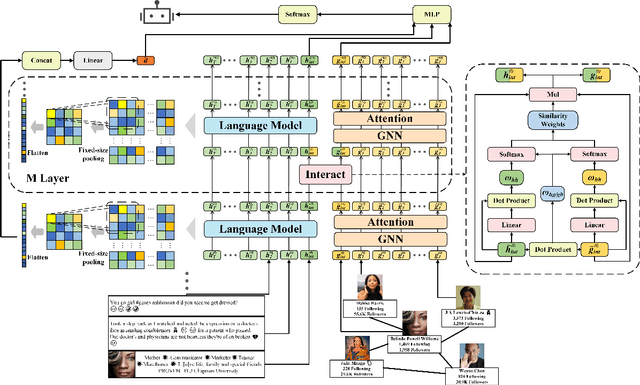
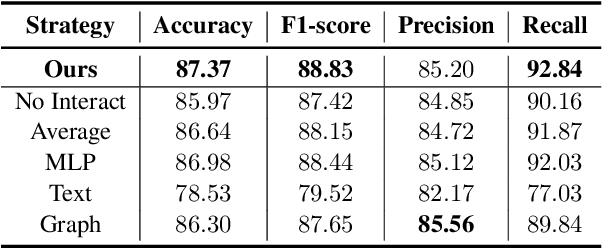
Twitter bot detection is an important and meaningful task. Existing text-based methods can deeply analyze user tweet content, achieving high performance. However, novel Twitter bots evade these detections by stealing genuine users' tweets and diluting malicious content with benign tweets. These novel bots are proposed to be characterized by semantic inconsistency. In addition, methods leveraging Twitter graph structure are recently emerging, showing great competitiveness. However, hardly a method has made text and graph modality deeply fused and interacted to leverage both advantages and learn the relative importance of the two modalities. In this paper, we propose a novel model named BIC that makes the text and graph modalities deeply interactive and detects tweet semantic inconsistency. Specifically, BIC contains a text propagation module, a graph propagation module to conduct bot detection respectively on text and graph structure, and a proven effective text-graph interactive module to make the two interact. Besides, BIC contains a semantic consistency detection module to learn semantic consistency information from tweets. Extensive experiments demonstrate that our framework outperforms competitive baselines on a comprehensive Twitter bot benchmark. We also prove the effectiveness of the proposed interaction and semantic consistency detection.
AHEAD: A Triple Attention Based Heterogeneous Graph Anomaly Detection Approach
Aug 17, 2022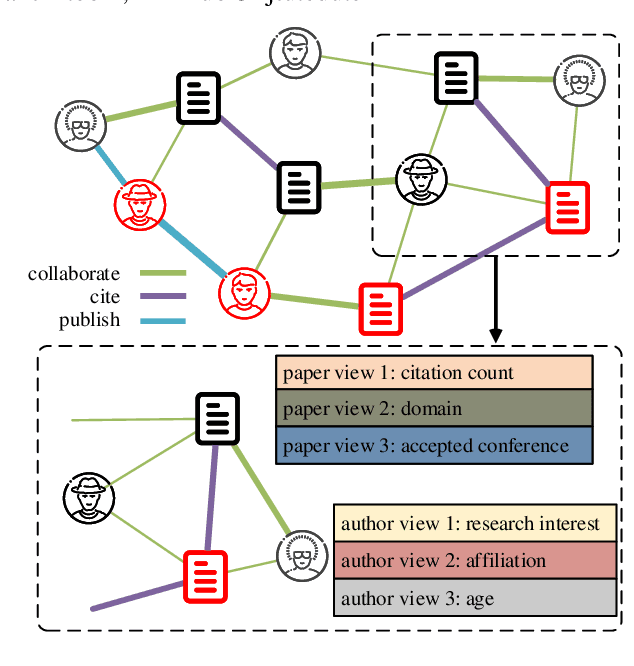
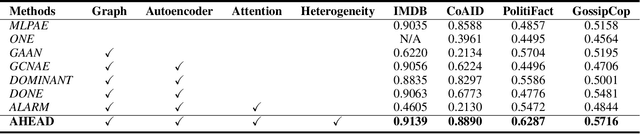
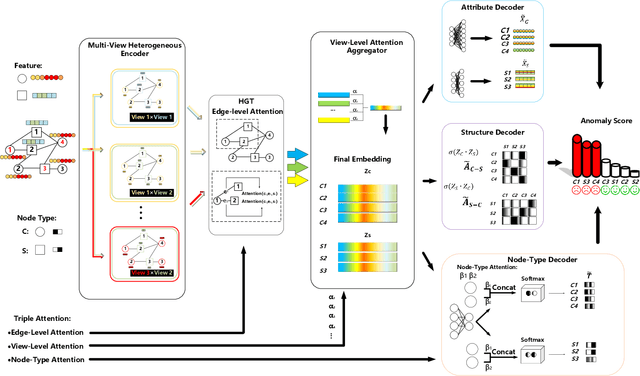

Graph anomaly detection on attributed networks has become a prevalent research topic due to its broad applications in many influential domains. In real-world scenarios, nodes and edges in attributed networks usually display distinct heterogeneity, i.e. attributes of different types of nodes show great variety, different types of relations represent diverse meanings. Anomalies usually perform differently from the majority in various perspectives of heterogeneity in these networks. However, existing graph anomaly detection approaches do not leverage heterogeneity in attributed networks, which is highly related to anomaly detection. In light of this problem, we propose AHEAD: a heterogeneity-aware unsupervised graph anomaly detection approach based on the encoder-decoder framework. Specifically, for the encoder, we design three levels of attention, i.e. attribute level, node type level, and edge level attentions to capture the heterogeneity of network structure, node properties and information of a single node, respectively. In the decoder, we exploit structure, attribute, and node type reconstruction terms to obtain an anomaly score for each node. Extensive experiments show the superiority of AHEAD on several real-world heterogeneous information networks compared with the state-of-arts in the unsupervised setting. Further experiments verify the effectiveness and robustness of our triple attention, model backbone, and decoder in general.
KRACL: Contrastive Learning with Graph Context Modeling for Sparse Knowledge Graph Completion
Aug 16, 2022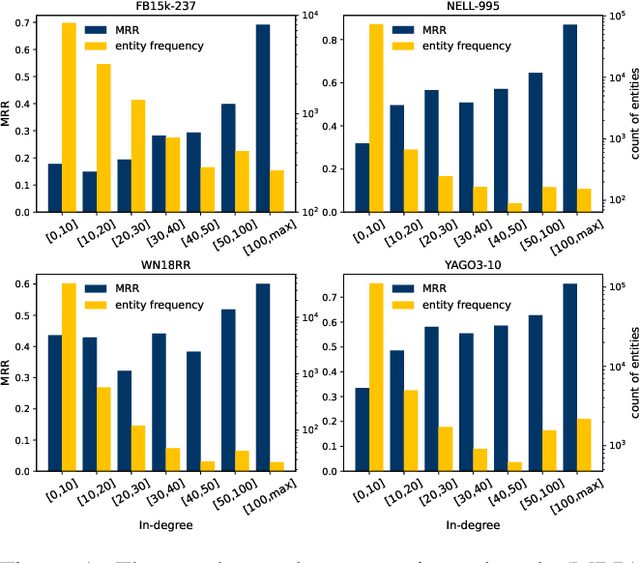
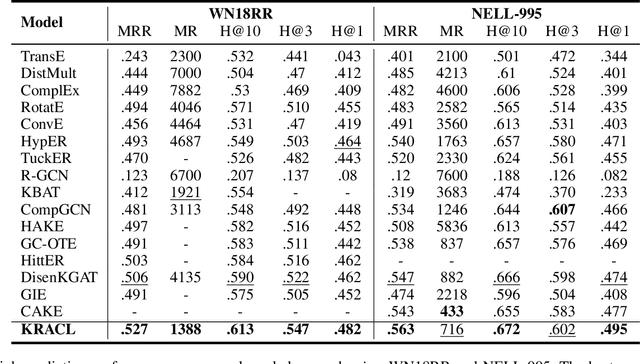
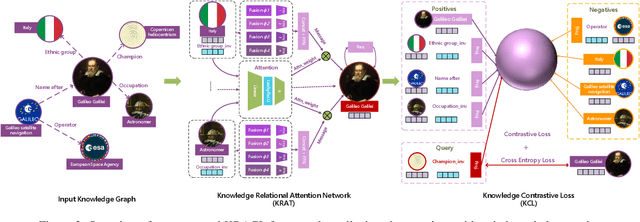
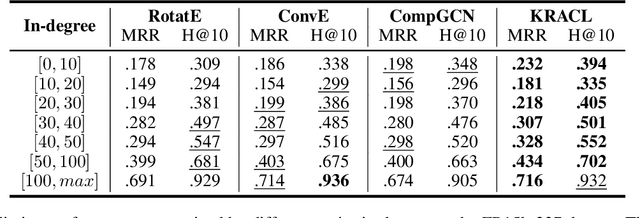
Knowledge Graph Embeddings (KGE) aim to map entities and relations to low dimensional spaces and have become the \textit{de-facto} standard for knowledge graph completion. Most existing KGE methods suffer from the sparsity challenge, where it is harder to predict entities that appear less frequently in knowledge graphs. In this work, we propose a novel framework KRACL to alleviate the widespread sparsity in KGs with graph context and contrastive learning. Firstly, we propose the Knowledge Relational Attention Network (KRAT) to leverage the graph context by simultaneously projecting neighboring triples to different latent spaces and jointly aggregating messages with the attention mechanism. KRAT is capable of capturing the subtle semantic information and importance of different context triples as well as leveraging multi-hop information in knowledge graphs. Secondly, we propose the knowledge contrastive loss by combining the contrastive loss with cross entropy loss, which introduces more negative samples and thus enriches the feedback to sparse entities. Our experiments demonstrate that KRACL achieves superior results across various standard knowledge graph benchmarks, especially on WN18RR and NELL-995 which have large numbers of low in-degree entities. Extensive experiments also bear out KRACL's effectiveness in handling sparse knowledge graphs and robustness against noisy triples.
TwiBot-22: Towards Graph-Based Twitter Bot Detection
Jun 12, 2022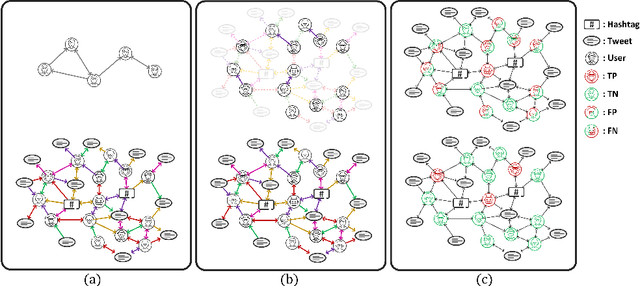
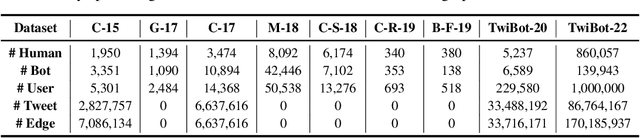
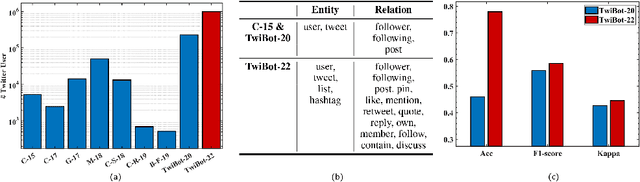
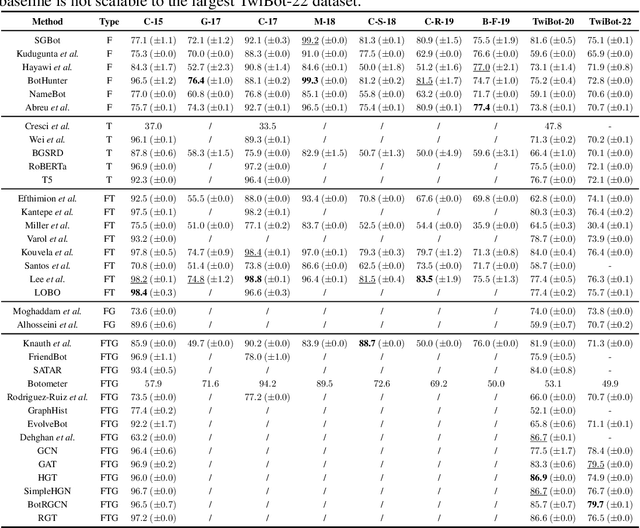
Twitter bot detection has become an increasingly important task to combat misinformation, facilitate social media moderation, and preserve the integrity of the online discourse. State-of-the-art bot detection methods generally leverage the graph structure of the Twitter network, and they exhibit promising performance when confronting novel Twitter bots that traditional methods fail to detect. However, very few of the existing Twitter bot detection datasets are graph-based, and even these few graph-based datasets suffer from limited dataset scale, incomplete graph structure, as well as low annotation quality. In fact, the lack of a large-scale graph-based Twitter bot detection benchmark that addresses these issues has seriously hindered the development and evaluation of novel graph-based bot detection approaches. In this paper, we propose TwiBot-22, a comprehensive graph-based Twitter bot detection benchmark that presents the largest dataset to date, provides diversified entities and relations on the Twitter network, and has considerably better annotation quality than existing datasets. In addition, we re-implement 35 representative Twitter bot detection baselines and evaluate them on 9 datasets, including TwiBot-22, to promote a fair comparison of model performance and a holistic understanding of research progress. To facilitate further research, we consolidate all implemented codes and datasets into the TwiBot-22 evaluation framework, where researchers could consistently evaluate new models and datasets. The TwiBot-22 Twitter bot detection benchmark and evaluation framework are publicly available at https://twibot22.github.io/
Noise-Tolerant Learning for Audio-Visual Action Recognition
May 20, 2022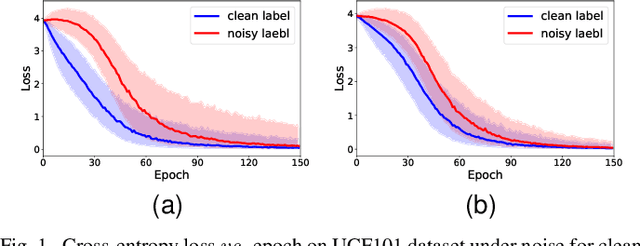
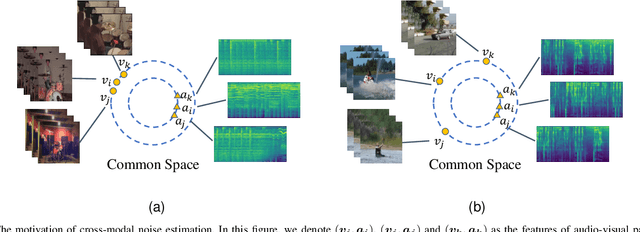
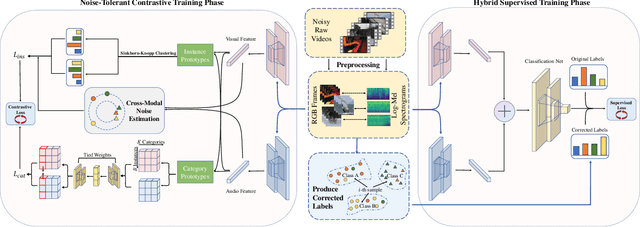
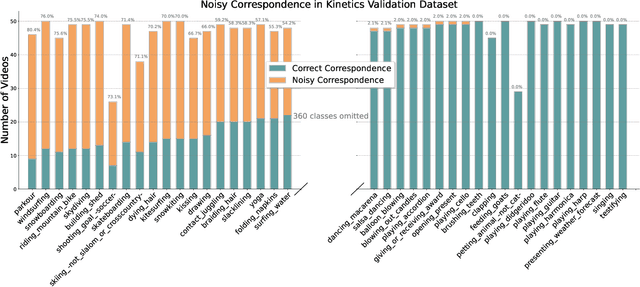
Recently, video recognition is emerging with the help of multi-modal learning, which focuses on integrating multiple modalities to improve the performance or robustness of a model. Although various multi-modal learning methods have been proposed and offer remarkable recognition results, almost all of these methods rely on high-quality manual annotations and assume that modalities among multi-modal data provide relevant semantic information. Unfortunately, most widely used video datasets are collected from the Internet and inevitably contain noisy labels and noisy correspondence. To solve this problem, we use the audio-visual action recognition task as a proxy and propose a noise-tolerant learning framework to find anti-interference model parameters to both noisy labels and noisy correspondence. Our method consists of two phases and aims to rectify noise by the inherent correlation between modalities. A noise-tolerant contrastive training phase is performed first to learn robust model parameters unaffected by the noisy labels. To reduce the influence of noisy correspondence, we propose a cross-modal noise estimation component to adjust the consistency between different modalities. Since the noisy correspondence existed at the instance level, a category-level contrastive loss is proposed to further alleviate the interference of noisy correspondence. Then in the hybrid supervised training phase, we calculate the distance metric among features to obtain corrected labels, which are used as complementary supervision. In addition, we investigate the noisy correspondence in real-world datasets and conduct comprehensive experiments with synthetic and real noise data. The results verify the advantageous performance of our method compared to state-of-the-art methods.
Towards Explanation for Unsupervised Graph-Level Representation Learning
May 20, 2022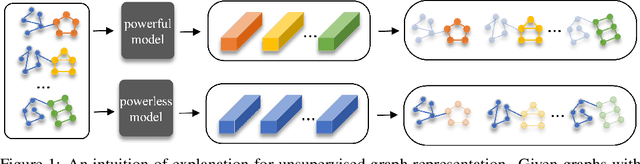

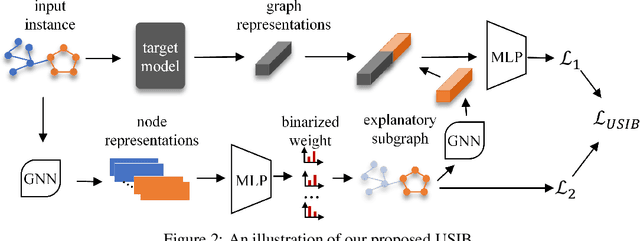
Due to the superior performance of Graph Neural Networks (GNNs) in various domains, there is an increasing interest in the GNN explanation problem "\emph{which fraction of the input graph is the most crucial to decide the model's decision?}" Existing explanation methods focus on the supervised settings, \eg, node classification and graph classification, while the explanation for unsupervised graph-level representation learning is still unexplored. The opaqueness of the graph representations may lead to unexpected risks when deployed for high-stake decision-making scenarios. In this paper, we advance the Information Bottleneck principle (IB) to tackle the proposed explanation problem for unsupervised graph representations, which leads to a novel principle, \textit{Unsupervised Subgraph Information Bottleneck} (USIB). We also theoretically analyze the connection between graph representations and explanatory subgraphs on the label space, which reveals that the expressiveness and robustness of representations benefit the fidelity of explanatory subgraphs. Experimental results on both synthetic and real-world datasets demonstrate the superiority of our developed explainer and the validity of our theoretical analysis.
CGUA: Context-Guided and Unpaired-Assisted Weakly Supervised Person Search
Mar 27, 2022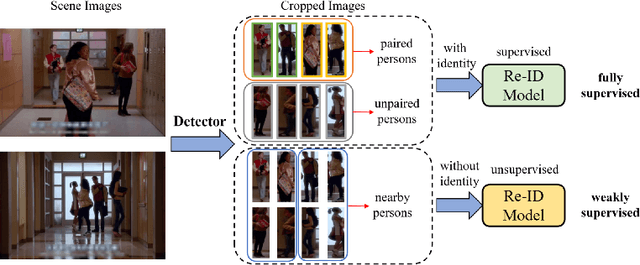
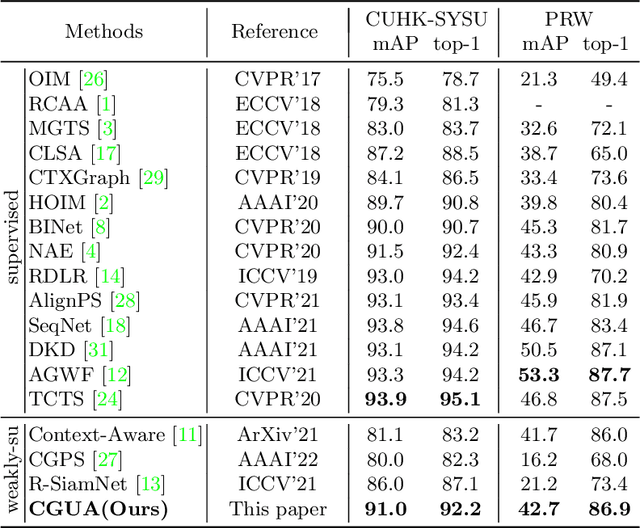
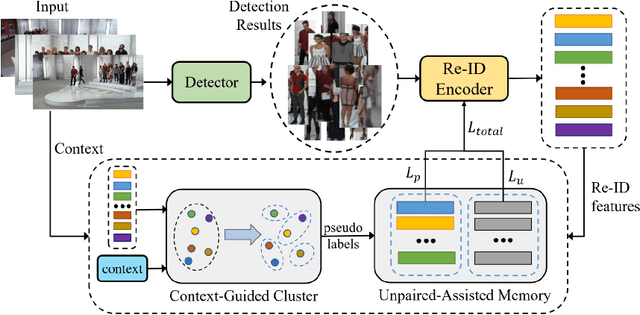
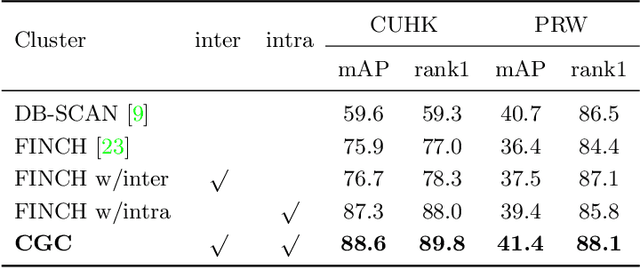
Recently, weakly supervised person search is proposed to discard human-annotated identities and train the model with only bounding box annotations. A natural way to solve this problem is to separate it into detection and unsupervised re-identification (Re-ID) steps. However, in this way, two important clues in unconstrained scene images are ignored. On the one hand, existing unsupervised Re-ID models only leverage cropped images from scene images but ignore its rich context information. On the other hand, there are numerous unpaired persons in real-world scene images. Directly dealing with them as independent identities leads to the long-tail effect, while completely discarding them can result in serious information loss. In light of these challenges, we introduce a Context-Guided and Unpaired-Assisted (CGUA) weakly supervised person search framework. Specifically, we propose a novel Context-Guided Cluster (CGC) algorithm to leverage context information in the clustering process and an Unpaired-Assisted Memory (UAM) unit to distinguish unpaired and paired persons by pushing them away. Extensive experiments demonstrate that the proposed approach can surpass the state-of-the-art weakly supervised methods by a large margin (more than 5% mAP on CUHK-SYSU). Moreover, our method achieves comparable or better performance to the state-of-the-art supervised methods by leveraging more diverse unlabeled data. Codes and models will be released soon.
Robust Unsupervised Graph Representation Learning via Mutual Information Maximization
Jan 21, 2022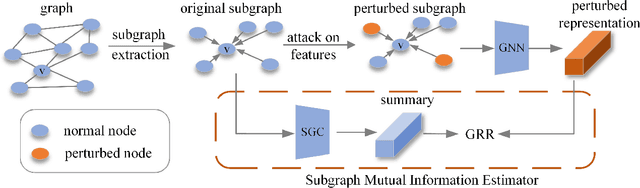
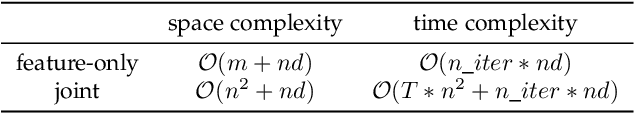
Recent studies have shown that GNNs are vulnerable to adversarial attack. Thus, many approaches are proposed to improve the robustness of GNNs against adversarial attacks. Nevertheless, most of these methods measure the model robustness based on label information and thus become infeasible when labels information is not available. Therefore, this paper focuses on robust unsupervised graph representation learning. In particular, to quantify the robustness of GNNs without label information, we propose a robustness measure, named graph representation robustness (GRR), to evaluate the mutual information between adversarially perturbed node representations and the original graph. There are mainly two challenges to estimate GRR: 1) mutual information estimation upon adversarially attacked graphs; 2) high complexity of adversarial attack to perturb node features and graph structure jointly in the training procedure. To tackle these problems, we further propose an effective mutual information estimator with subgraph-level summary and an efficient adversarial training strategy with only feature perturbations. Moreover, we theoretically establish a connection between our proposed GRR measure and the robustness of downstream classifiers, which reveals that GRR can provide a lower bound to the adversarial risk of downstream classifiers. Extensive experiments over several benchmarks demonstrate the effectiveness and superiority of our proposed method.
Computationally Efficient Approximations for Matrix-based Renyi's Entropy
Dec 27, 2021
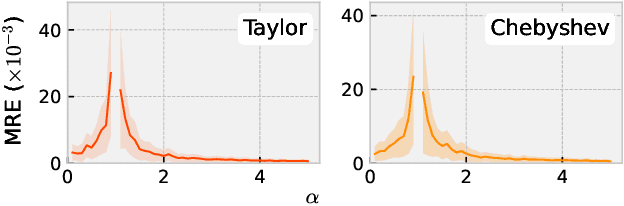
The recently developed matrix based Renyi's entropy enables measurement of information in data simply using the eigenspectrum of symmetric positive semi definite (PSD) matrices in reproducing kernel Hilbert space, without estimation of the underlying data distribution. This intriguing property makes the new information measurement widely adopted in multiple statistical inference and learning tasks. However, the computation of such quantity involves the trace operator on a PSD matrix $G$ to power $\alpha$(i.e., $tr(G^\alpha)$), with a normal complexity of nearly $O(n^3)$, which severely hampers its practical usage when the number of samples (i.e., $n$) is large. In this work, we present computationally efficient approximations to this new entropy functional that can reduce its complexity to even significantly less than $O(n^2)$. To this end, we first develop randomized approximations to $\tr(\G^\alpha)$ that transform the trace estimation into matrix-vector multiplications problem. We extend such strategy for arbitrary values of $\alpha$ (integer or non-integer). We then establish the connection between the matrix-based Renyi's entropy and PSD matrix approximation, which enables us to exploit both clustering and block low-rank structure of $\G$ to further reduce the computational cost. We theoretically provide approximation accuracy guarantees and illustrate the properties of different approximations. Large-scale experimental evaluations on both synthetic and real-world data corroborate our theoretical findings, showing promising speedup with negligible loss in accuracy.
PPSGCN: A Privacy-Preserving Subgraph Sampling Based Distributed GCN Training Method
Oct 22, 2021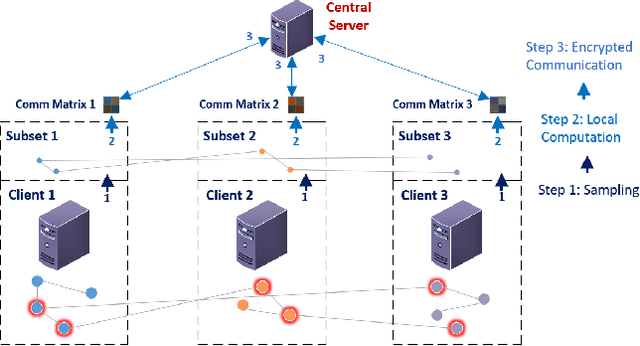
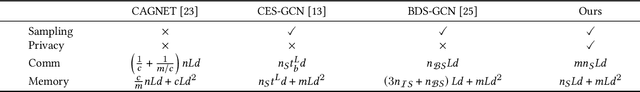

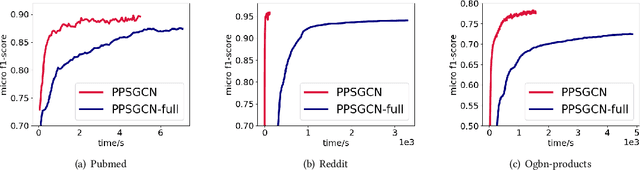
Graph convolutional networks (GCNs) have been widely adopted for graph representation learning and achieved impressive performance. For larger graphs stored separately on different clients, distributed GCN training algorithms were proposed to improve efficiency and scalability. However, existing methods directly exchange node features between different clients, which results in data privacy leakage. Federated learning was incorporated in graph learning to tackle data privacy, while they suffer from severe performance drop due to non-iid data distribution. Besides, these approaches generally involve heavy communication and memory overhead during the training process. In light of these problems, we propose a Privacy-Preserving Subgraph sampling based distributed GCN training method (PPSGCN), which preserves data privacy and significantly cuts back on communication and memory overhead. Specifically, PPSGCN employs a star-topology client-server system. We firstly sample a local node subset in each client to form a global subgraph, which greatly reduces communication and memory costs. We then conduct local computation on each client with features or gradients of the sampled nodes. Finally, all clients securely communicate with the central server with homomorphic encryption to combine local results while preserving data privacy. Compared with federated graph learning methods, our PPSGCN model is trained on a global graph to avoid the negative impact of local data distribution. We prove that our PPSGCN algorithm would converge to a local optimum with probability 1. Experiment results on three prevalent benchmarks demonstrate that our algorithm significantly reduces communication and memory overhead while maintaining desirable performance. Further studies not only demonstrate the fast convergence of PPSGCN, but discuss the trade-off between communication and local computation cost as well.