 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-learning an Intermediate Representation for Few-shot Block-wise Prediction of Landslide Susceptibility
Oct 03, 2021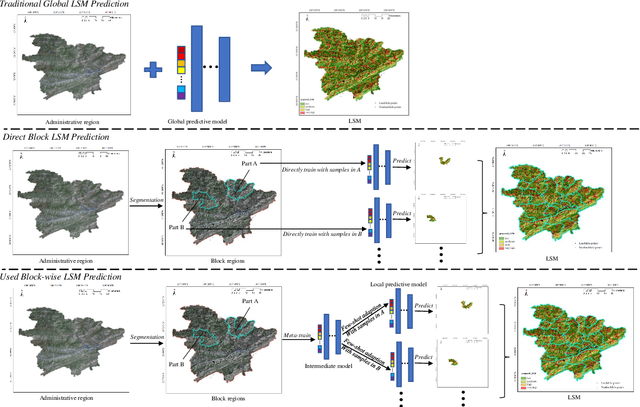
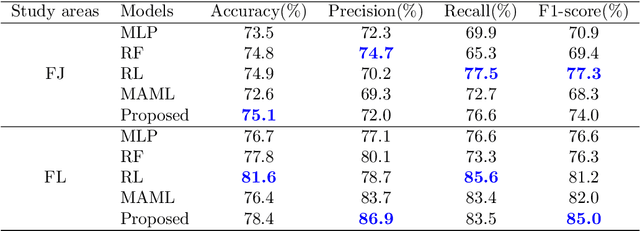
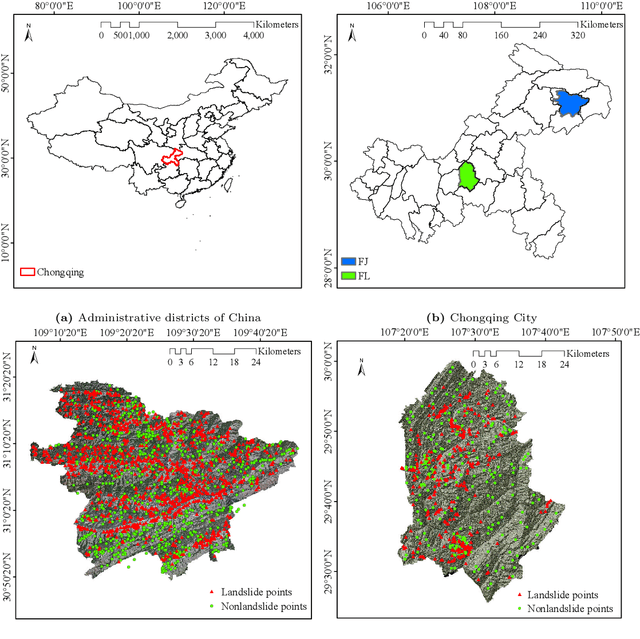
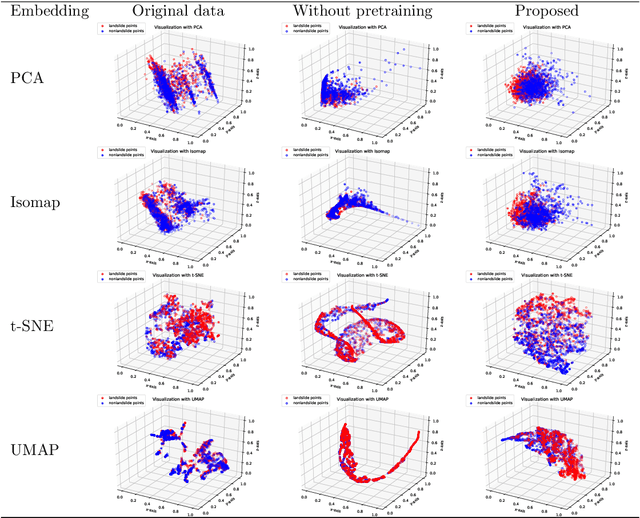
Predicting a landslide susceptibility map (LSM) is essential for risk recognition and disaster prevention. Despite the successful application of data-driven prediction approaches, current data-driven methods generally apply a single global model to predict the LSM for an entire target region. However, we argue that, in complex circumstances, especially in large-scale areas, each part of the region holds different landslide-inducing environments, and therefore, should be predicted individually with respective models. In this study, target scenarios were segmented into blocks for individual analysis using topographical factors. But simply conducting training and testing using limited samples within each block is hardly possible for a satisfactory LSM prediction, due to the adverse effect of \textit{overfitting}. To solve the problems, we train an intermediate representation by the meta-learning paradigm, which is superior for capturing information from LSM tasks in order to generalize proficiently. We chose this based on the hypothesis that there are more general concepts among LSM tasks that are sensitive to variations in input features. Thus, using the intermediate representation, we can easily adapt the model for different blocks or even unseen tasks using few exemplar samples. Experimental results on two study areas demonstrated the validity of our block-wise analysis in large scenarios and revealed the top few-shot adaption performances of the proposed methods.
Curvature Graph Neural Network
Jun 30, 2021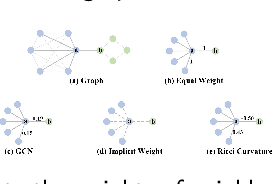

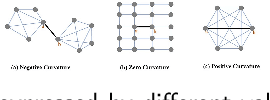
Graph neural networks (GNNs) have achieved great success in many graph-based tasks. Much work is dedicated to empowering GNNs with the adaptive locality ability, which enables measuring the importance of neighboring nodes to the target node by a node-specific mechanism. However, the current node-specific mechanisms are deficient in distinguishing the importance of nodes in the topology structure. We believe that the structural importance of neighboring nodes is closely related to their importance in aggregation. In this paper, we introduce discrete graph curvature (the Ricci curvature) to quantify the strength of structural connection of pairwise nodes. And we propose Curvature Graph Neural Network (CGNN), which effectively improves the adaptive locality ability of GNNs by leveraging the structural property of graph curvature. To improve the adaptability of curvature to various datasets, we explicitly transform curvature into the weights of neighboring nodes by the necessary Negative Curvature Processing Module and Curvature Normalization Module. Then, we conduct numerous experiments on various synthetic datasets and real-world datasets. The experimental results on synthetic datasets show that CGNN effectively exploits the topology structure information, and the performance is improved significantly. CGNN outperforms the baselines on 5 dense node classification benchmark datasets. This study deepens the understanding of how to utilize advanced topology information and assign the importance of neighboring nodes from the perspective of graph curvature and encourages us to bridge the gap between graph theory and neural networks.
Remote Sensing Images Semantic Segmentation with General Remote Sensing Vision Model via a Self-Supervised Contrastive Learning Method
Jun 20, 2021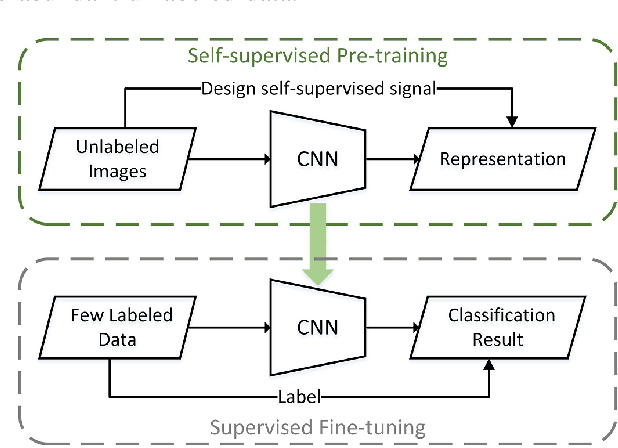
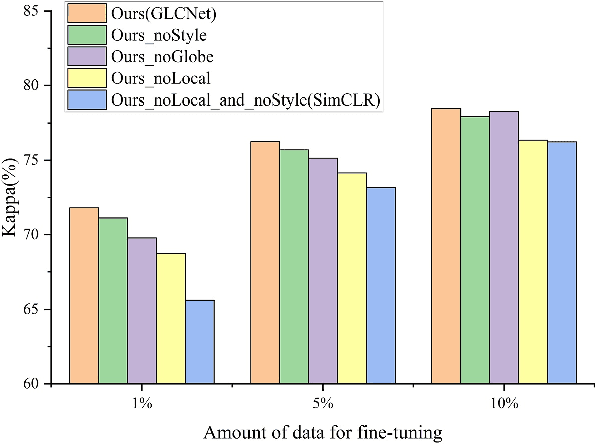
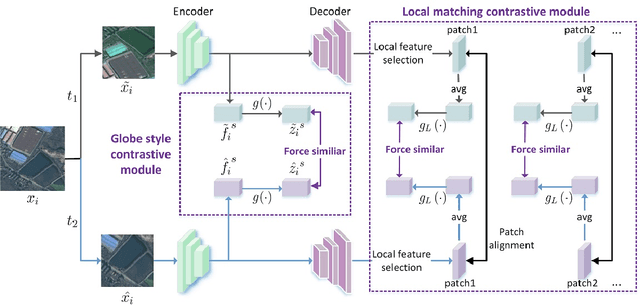
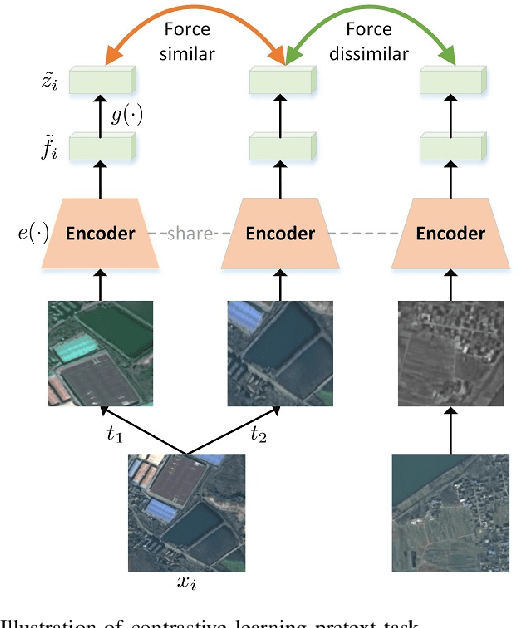
A new learning paradigm, self-supervised learning (SSL), can be used to solve such problems by pre-training a general model with large unlabeled images and then fine-tuning on a downstream task with very few labeled samples. Contrastive learning is a typical method of SSL, which can learn general invariant features. However, most of the existing contrastive learning is designed for classification tasks to obtain an image-level representation, which may be sub-optimal for semantic segmentation tasks requiring pixel-level discrimination. Therefore, we propose Global style and Local matching Contrastive Learning Network (GLCNet) for remote sensing semantic segmentation. Specifically, the global style contrastive module is used to learn an image-level representation better, as we consider the style features can better represent the overall image features; The local features matching contrastive module is designed to learn representations of local regions which is beneficial for semantic segmentation. We evaluate four remote sensing semantic segmentation datasets, and the experimental results show that our method mostly outperforms state-of-the-art self-supervised methods and ImageNet pre-training. Specifically, with 1\% annotation from the original dataset, our approach improves Kappa by 6\% on the ISPRS Potsdam dataset and 3\% on Deep Globe Land Cover Classification dataset relative to the existing baseline. Moreover, our method outperforms supervised learning when there are some differences between the datasets of upstream tasks and downstream tasks. Our study promotes the development of self-supervised learning in the field of remote sensing semantic segmentation. The source code is available at https://github.com/GeoX-Lab/G-RSIM.
Graph Information Vanishing Phenomenon inImplicit Graph Neural Networks
Mar 02, 2021One of the key problems of GNNs is how to describe the importance of neighbor nodes in the aggregation process for learning node representations. A class of GNNs solves this problem by learning implicit weights to represent the importance of neighbor nodes, which we call implicit GNNs such as Graph Attention Network. The basic idea of implicit GNNs is to introduce graph information with special properties followed by Learnable Transformation Structures (LTS) which encode the importance of neighbor nodes via a data-driven way. In this paper, we argue that LTS makes the special properties of graph information disappear during the learning process, resulting in graph information unhelpful for learning node representations. We call this phenomenon Graph Information Vanishing (GIV). Also, we find that LTS maps different graph information into highly similar results. To validate the above two points, we design two sets of 70 random experiments on five Implicit GNNs methods and seven benchmark datasets by using a random permutation operator to randomly disrupt the order of graph information and replacing graph information with random values. We find that randomization does not affect the model performance in 93\% of the cases, with about 7 percentage causing an average 0.5\% accuracy loss. And the cosine similarity of output results, generated by LTS mapping different graph information, over 99\% with an 81\% proportion. The experimental results provide evidence to support the existence of GIV in Implicit GNNs and imply that the existing methods of Implicit GNNs do not make good use of graph information. The relationship between graph information and LTS should be rethought to ensure that graph information is used in node representation.
Depth-Enhanced Feature Pyramid Network for Occlusion-Aware Verification of Buildings from Oblique Images
Nov 26, 2020


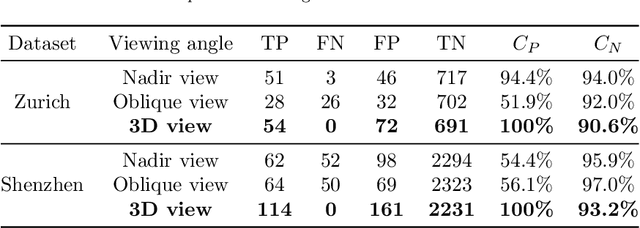
Detecting the changes of buildings in urban environments is essential. Existing methods that use only nadir images suffer from severe problems of ambiguous features and occlusions between buildings and other regions. Furthermore, buildings in urban environments vary significantly in scale, which leads to performance issues when using single-scale features. To solve these issues, this paper proposes a fused feature pyramid network, which utilizes both color and depth data for the 3D verification of existing buildings 2D footprints from oblique images. First, the color data of oblique images are enriched with the depth information rendered from 3D mesh models. Second, multiscale features are fused in the feature pyramid network to convolve both the color and depth data. Finally, multi-view information from both the nadir and oblique images is used in a robust voting procedure to label changes in existing buildings. Experimental evaluations using both the ISPRS benchmark datasets and Shenzhen datasets reveal that the proposed method outperforms the ResNet and EfficientNet networks by 5\% and 2\%, respectively, in terms of recall rate and precision. We demonstrate that the proposed method can successfully detect all changed buildings; therefore, only those marked as changed need to be manually checked during the pipeline updating procedure; this significantly reduces the manual quality control requirements. Moreover, ablation studies indicate that using depth data, feature pyramid modules, and multi-view voting strategies can lead to clear and progressive improvements.
Structure-Aware Completion of Photogrammetric Meshes in Urban Road Environment
Nov 24, 2020

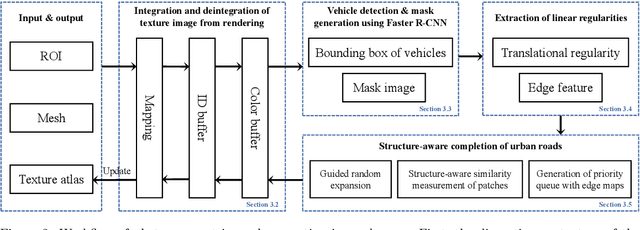

Photogrammetric mesh models obtained from aerial oblique images have been widely used for urban reconstruction. However, the photogrammetric meshes also suffer from severe texture problems, especially on the road areas due to occlusion. This paper proposes a structure-aware completion approach to improve the quality of meshes by removing undesired vehicles on the road seamlessly. Specifically, the discontinuous texture atlas is first integrated to a continuous screen space through rendering by the graphics pipeline; the rendering also records necessary mapping for deintegration to the original texture atlas after editing. Vehicle regions are masked by a standard object detection approach, e.g. Faster RCNN. Then, the masked regions are completed guided by the linear structures and regularities in the road region, which is implemented based on Patch Match. Finally, the completed rendered image is deintegrated to the original texture atlas and the triangles for the vehicles are also flattened for improved meshes. Experimental evaluations and analyses are conducted against three datasets, which are captured with different sensors and ground sample distances. The results reveal that the proposed method can quite realistic meshes after removing the vehicles. The structure-aware completion approach for road regions outperforms popular image completion methods and ablation study further confirms the effectiveness of the linear guidance. It should be noted that the proposed method is also capable to handle tiled mesh models for large-scale scenes. Dataset and code are available at vrlab.org.cn/~hanhu/projects/mesh.
Minimum Potential Energy of Point Cloud for Robust Global Registration
Jun 12, 2020

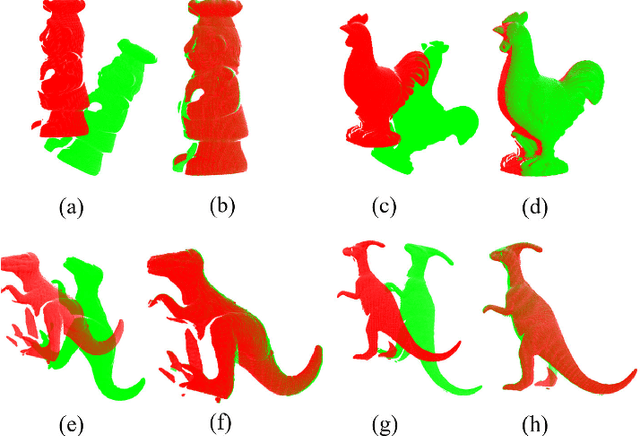
In this paper, we propose a novel minimum gravitational potential energy (MPE)-based algorithm for global point set registration. The feature descriptors extraction algorithms have emerged as the standard approach to align point sets in the past few decades. However, the alignment can be challenging to take effect when the point set suffers from raw point data problems such as noises (Gaussian and Uniformly). Different from the most existing point set registration methods which usually extract the descriptors to find correspondences between point sets, our proposed MPE alignment method is able to handle large scale raw data offset without depending on traditional descriptors extraction, whether for the local or global registration methods. We decompose the solution into a global optimal convex approximation and the fast descent process to a local minimum. For the approximation step, the proposed minimum potential energy (MPE) approach consists of two main steps. Firstly, according to the construction of the force traction operator, we could simply compute the position of the potential energy minimum; Secondly, with respect to the finding of the MPE point, we propose a new theory that employs the two flags to observe the status of the registration procedure. The method of fast descent process to the minimum that we employed is the iterative closest point algorithm; it can achieve the global minimum. We demonstrate the performance of the proposed algorithm on synthetic data as well as on real data. The proposed method outperforms the other global methods in terms of both efficiency, accuracy and noise resistance.
Leveraging Photogrammetric Mesh Models for Aerial-Ground Feature Point Matching Toward Integrated 3D Reconstruction
Feb 21, 2020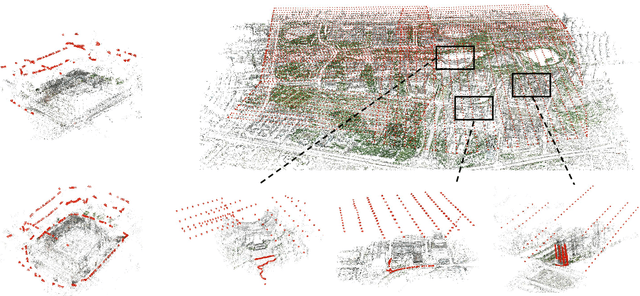

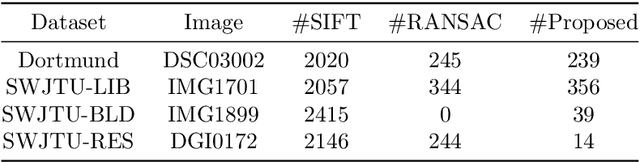
Integration of aerial and ground images has been proved as an efficient approach to enhance the surface reconstruction in urban environments. However, as the first step, the feature point matching between aerial and ground images is remarkably difficult, due to the large differences in viewpoint and illumination conditions. Previous studies based on geometry-aware image rectification have alleviated this problem, but the performance and convenience of this strategy is limited by several flaws, e.g. quadratic image pairs, segregated extraction of descriptors and occlusions. To address these problems, we propose a novel approach: leveraging photogrammetric mesh models for aerial-ground image matching. The methods of this proposed approach have linear time complexity with regard to the number of images, can explicitly handle low overlap using multi-view images and can be directly injected into off-the-shelf structure-from-motion (SfM) and multi-view stereo (MVS) solutions. First, aerial and ground images are reconstructed separately and initially co-registered through weak georeferencing data. Second, aerial models are rendered to the initial ground views, in which the color, depth and normal images are obtained. Then, the synthesized color images and the corresponding ground images are matched by comparing the descriptors, filtered by local geometrical information, and then propagated to the aerial views using depth images and patch-based matching. Experimental evaluations using various datasets confirm the superior performance of the proposed methods in aerial-ground image matching. In addition, incorporation of the existing SfM and MVS solutions into these methods enables more complete and accurate models to be directly obtained.
Fast and Regularized Reconstruction of Building Façades from Street-View Images using Binary Integer Programming
Feb 20, 2020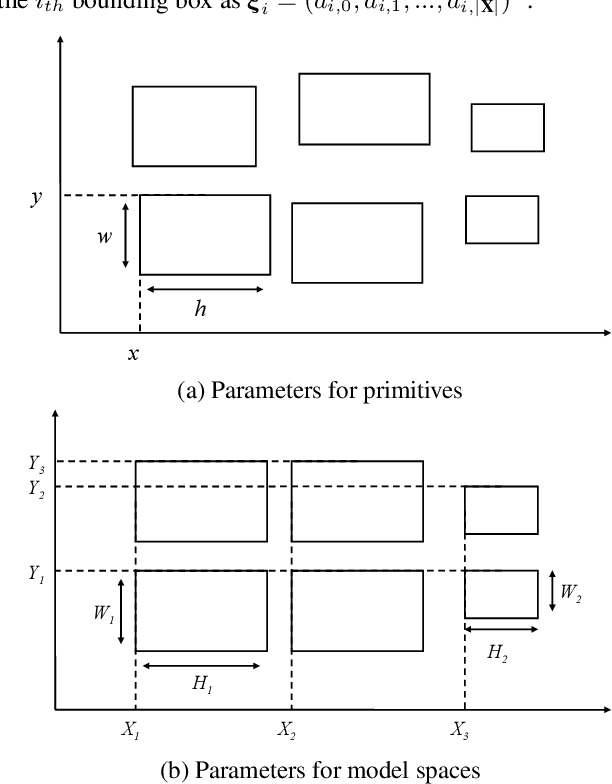
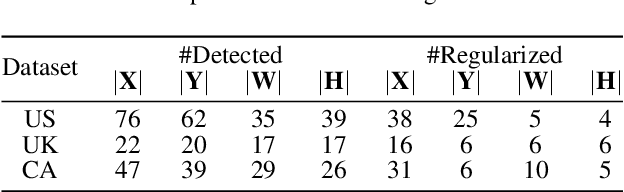
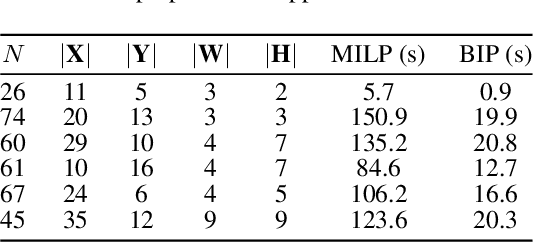

Regularized arrangement of primitives on building fa\c{c}ades to aligned locations and consistent sizes is important towards structured reconstruction of urban environment. Mixed integer linear programing was used to solve the problem, however, it is extreamly time consuming even for state-of-the-art commercial solvers. Aiming to alleviate this issue, we cast the problem into binary integer programming, which omits the requirements for real value parameters and is more efficient to be solved . Firstly, the bounding boxes of the primitives are detected using the YOLOv3 architecture in real-time. Secondly, the coordinates of the upper left corners and the sizes of the bounding boxes are automatically clustered in a binary integer programming optimization, which jointly considers the geometric fitness, regularity and additional constraints; this step does not require \emph{a priori} knowledge, such as the number of clusters or pre-defined grammars. Finally, the regularized bounding boxes can be directly used to guide the fa\c{c}ade reconstruction in an interactive envinronment. Experimental evaluations have revealed that the accuracies for the extraction of primitives are above 0.85, which is sufficient for the following 3D reconstruction. The proposed approach only takes about $ 10\% $ to $ 20\% $ of the runtime than previous approach and reduces the diversity of the bounding boxes to about $20\%$ to $50\%$
Deep Fusion of Local and Non-Local Features for Precision Landslide Recognition
Feb 20, 2020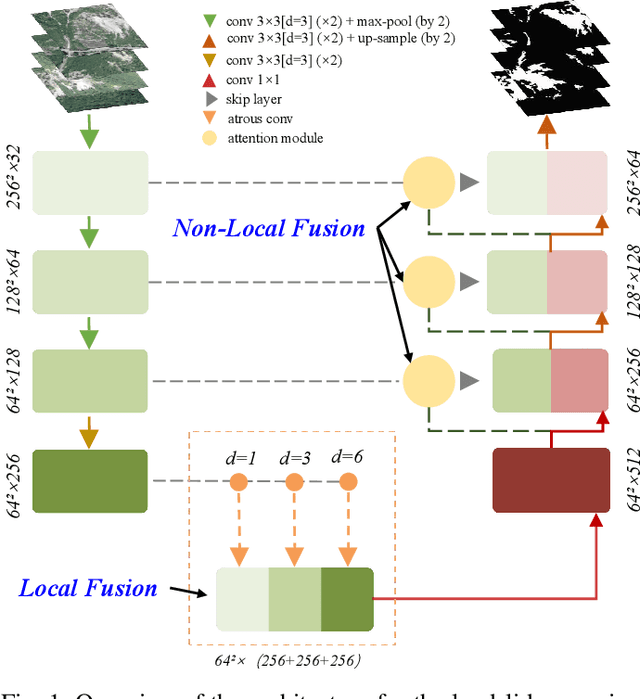
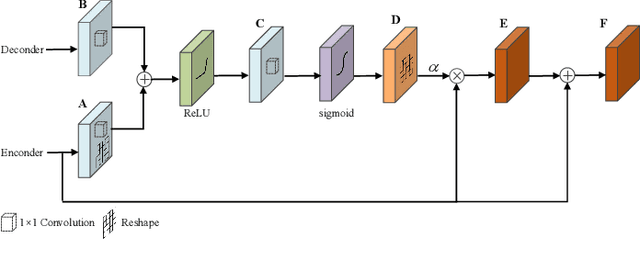


Precision mapping of landslide inventory is crucial for hazard mitigation. Most landslides generally co-exist with other confusing geological features, and the presence of such areas can only be inferred unambiguously at a large scale. In addition, local information is also important for the preservation of object boundaries. Aiming to solve this problem, this paper proposes an effective approach to fuse both local and non-local features to surmount the contextual problem. Built upon the U-Net architecture that is widely adopted in the remote sensing community, we utilize two additional modules. The first one uses dilated convolution and the corresponding atrous spatial pyramid pooling, which enlarged the receptive field without sacrificing spatial resolution or increasing memory usage. The second uses a scale attention mechanism to guide the up-sampling of features from the coarse level by a learned weight map. In implementation, the computational overhead against the original U-Net was only a few convolutional layers. Experimental evaluations revealed that the proposed method outperformed state-of-the-art general-purpose semantic segmentation approaches. Furthermore, ablation studies have shown that the two models afforded extensive enhancements in landslide-recognition performance.