 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Augmentation for Aspect Term Extraction via Masked Sequence-to-Sequence Generation
May 01, 2020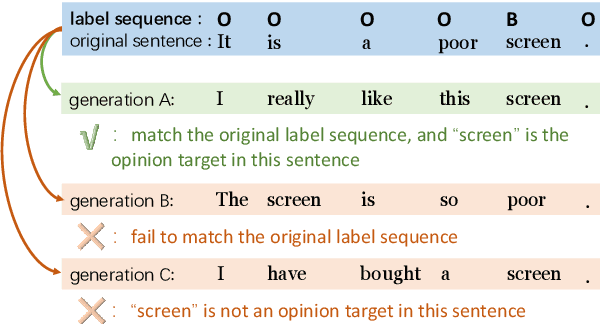
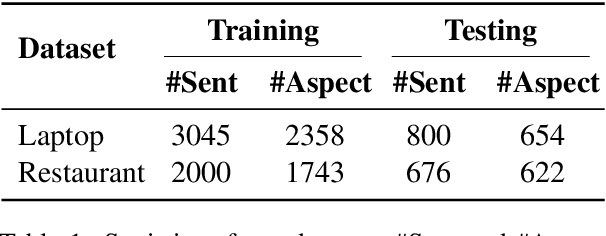
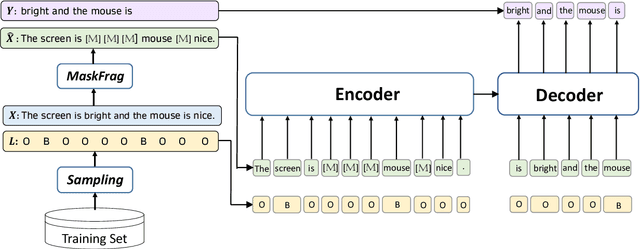
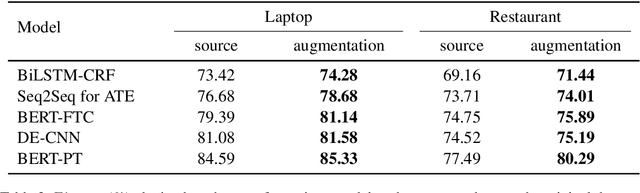
Aspect term extraction aims to extract aspect terms from review texts as opinion targets for sentiment analysis. One of the big challenges with this task is the lack of sufficient annotated data. While data augmentation is potentially an effective technique to address the above issue, it is uncontrollable as it may change aspect words and aspect labels unexpectedly. In this paper, we formulate the data augmentation as a conditional generation task: generating a new sentence while preserving the original opinion targets and labels. We propose a masked sequence-to-sequence method for conditional augmentation of aspect term extraction. Unlike existing augmentation approaches, ours is controllable and allows us to generate more diversified sentences. Experimental results confirm that our method alleviates the data scarcity problem significantly. It also effectively boosts the performances of several current models for aspect term extraction.
HierTrain: Fast Hierarchical Edge AI Learning with Hybrid Parallelism in Mobile-Edge-Cloud Computing
Mar 22, 2020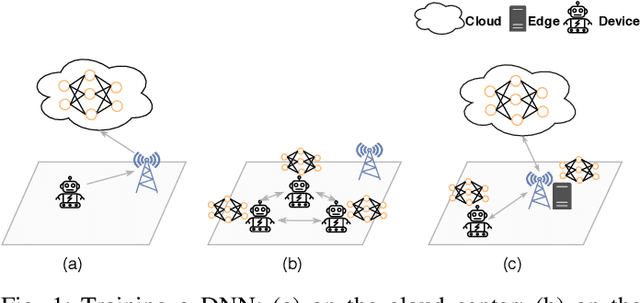
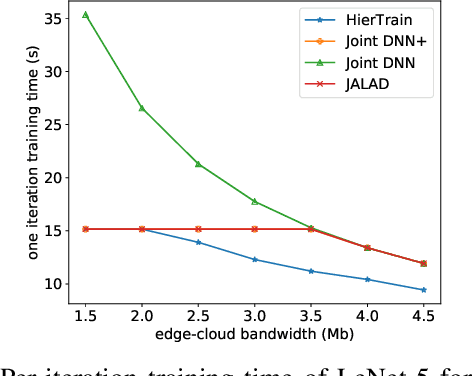
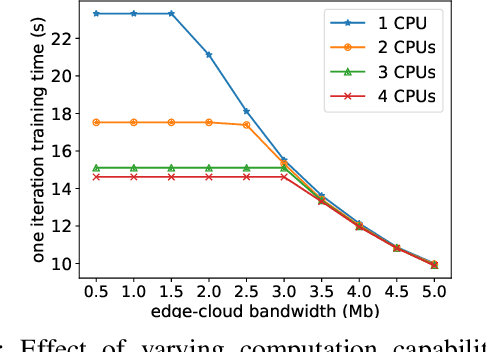
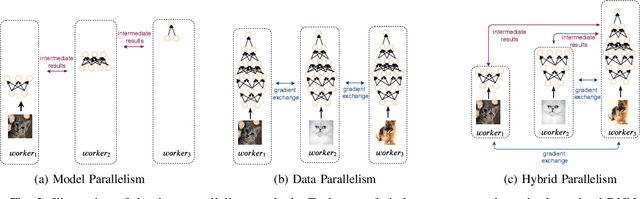
Nowadays, deep neural networks (DNNs) are the core enablers for many emerging edge AI applications. Conventional approaches to training DNNs are generally implemented at central servers or cloud centers for centralized learning, which is typically time-consuming and resource-demanding due to the transmission of a large amount of data samples from the device to the remote cloud. To overcome these disadvantages, we consider accelerating the learning process of DNNs on the Mobile-Edge-Cloud Computing (MECC) paradigm. In this paper, we propose HierTrain, a hierarchical edge AI learning framework, which efficiently deploys the DNN training task over the hierarchical MECC architecture. We develop a novel \textit{hybrid parallelism} method, which is the key to HierTrain, to adaptively assign the DNN model layers and the data samples across the three levels of edge device, edge server and cloud center. We then formulate the problem of scheduling the DNN training tasks at both layer-granularity and sample-granularity. Solving this optimization problem enables us to achieve the minimum training time. We further implement a hardware prototype consisting of an edge device, an edge server and a cloud server, and conduct extensive experiments on it. Experimental results demonstrate that HierTrain can achieve up to 6.9x speedup compared to the cloud-based hierarchical training approach.
Federated Variance-Reduced Stochastic Gradient Descent with Robustness to Byzantine Attacks
Dec 29, 2019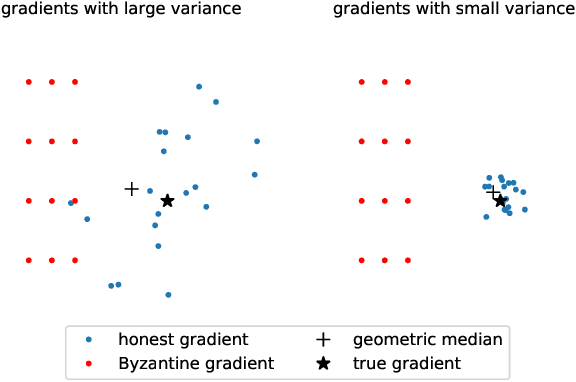
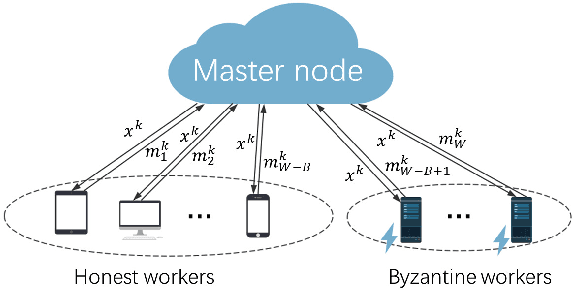
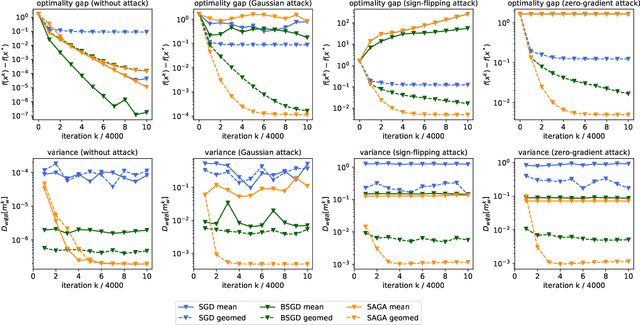
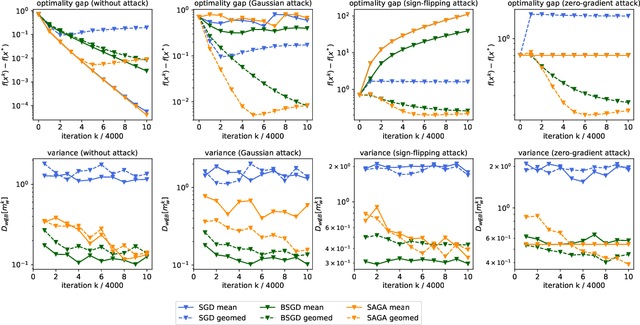
This paper deals with distributed finite-sum optimization for learning over networks in the presence of malicious Byzantine attacks. To cope with such attacks, most resilient approaches so far combine stochastic gradient descent (SGD) with different robust aggregation rules. However, the sizeable SGD-induced stochastic gradient noise makes it challenging to distinguish malicious messages sent by the Byzantine attackers from noisy stochastic gradients sent by the 'honest' workers. This motivates us to reduce the variance of stochastic gradients as a means of robustifying SGD in the presence of Byzantine attacks. To this end, the present work puts forth a Byzantine attack resilient distributed (Byrd-) SAGA approach for learning tasks involving finite-sum optimization over networks. Rather than the mean employed by distributed SAGA, the novel Byrd- SAGA relies on the geometric median to aggregate the corrected stochastic gradients sent by the workers. When less than half of the workers are Byzantine attackers, the robustness of geometric median to outliers enables Byrd-SAGA to attain provably linear convergence to a neighborhood of the optimal solution, with the asymptotic learning error determined by the number of Byzantine workers. Numerical tests corroborate the robustness to various Byzantine attacks, as well as the merits of Byrd- SAGA over Byzantine attack resilient distributed SGD.
Convolutional Neural Networks for Space-Time Block Coding Recognition
Oct 19, 2019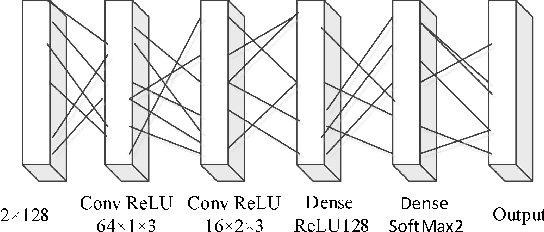
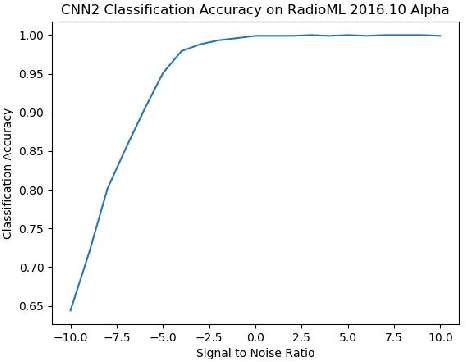
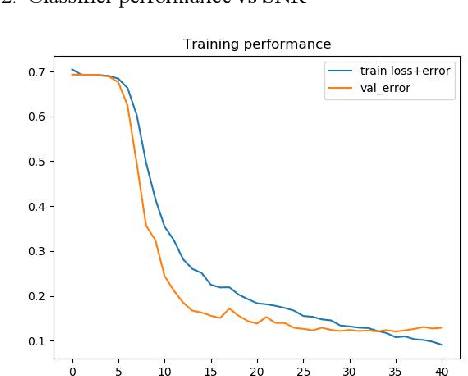
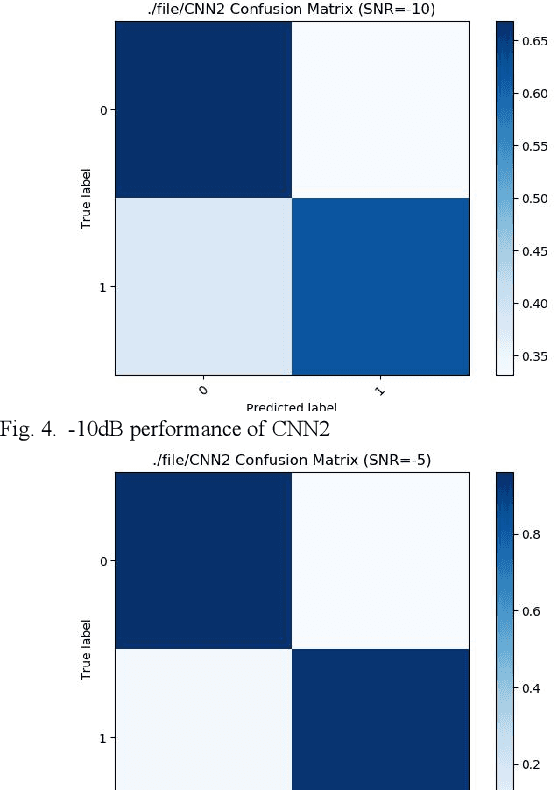
We find that the latest advances in machine learning with deep neural network by applying them to the task of radio modulation recognition, channel coding recognition, and spectrum monitor. This paper first proposes a novel identification algorithm for Space-Time Block coding(STBC) signal. The feature between Spatial Multiplexing (SM) and Alamouti (AL) signals is extracted via adapting convolutional neural networks after preprocessing the received sequence. Unlike other algorithms, this method does not require any prior information of channel coefficient, and noise power and, consequently, is well-suited for non-cooperative context. Results show that the proposed algorithm performs well even at a low signal to noise ratio (SNR).
Communication-Censored Linearized ADMM for Decentralized Consensus Optimization
Sep 15, 2019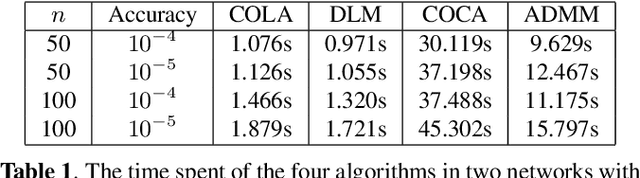
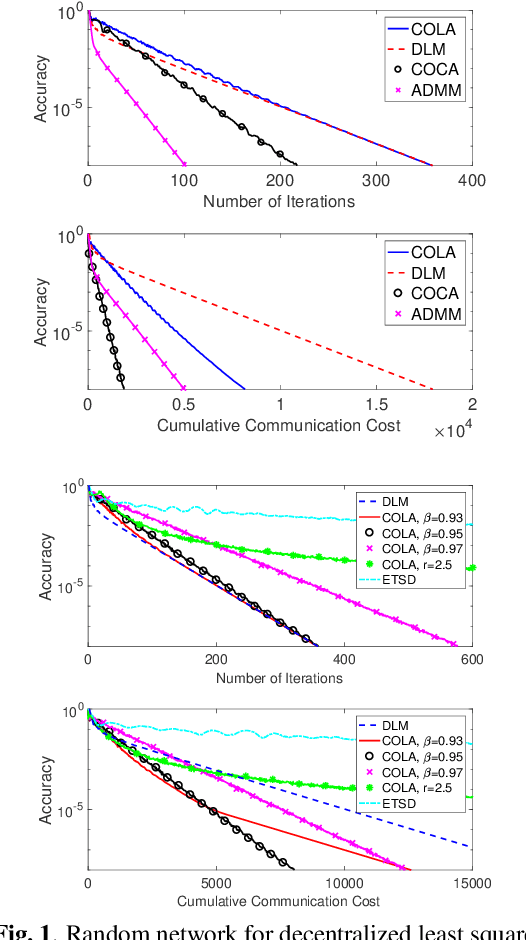
In this paper, we propose a communication- and computation-efficient algorithm to solve a convex consensus optimization problem defined over a decentralized network. A remarkable existing algorithm to solve this problem is the alternating direction method of multipliers (ADMM), in which at every iteration every node updates its local variable through combining neighboring variables and solving an optimization subproblem. The proposed algorithm, called as COmmunication-censored Linearized ADMM (COLA), leverages a linearization technique to reduce the iteration-wise computation cost of ADMM and uses a communication-censoring strategy to alleviate the communication cost. To be specific, COLA introduces successive linearization approximations to the local cost functions such that the resultant computation is first-order and light-weight. Since the linearization technique slows down the convergence speed, COLA further adopts the communication-censoring strategy to avoid transmissions of less informative messages. A node is allowed to transmit only if the distance between the current local variable and its previously transmitted one is larger than a censoring threshold. COLA is proven to be convergent when the local cost functions have Lipschitz continuous gradients and the censoring threshold is summable. When the local cost functions are further strongly convex, we establish the linear (sublinear) convergence rate of COLA, given that the censoring threshold linearly (sublinearly) decays to 0. Numerical experiments corroborate with the theoretical findings and demonstrate the satisfactory communication-computation tradeoff of COLA.
Communication-Censored Distributed Stochastic Gradient Descent
Sep 09, 2019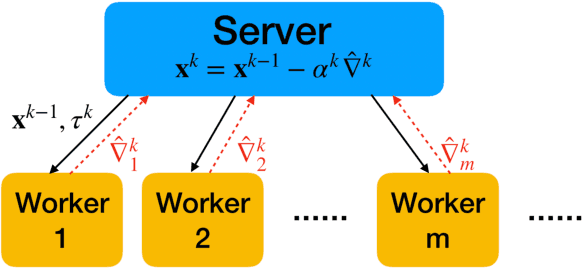

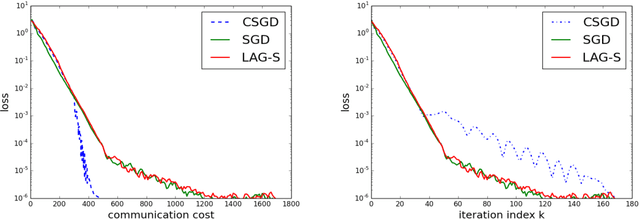
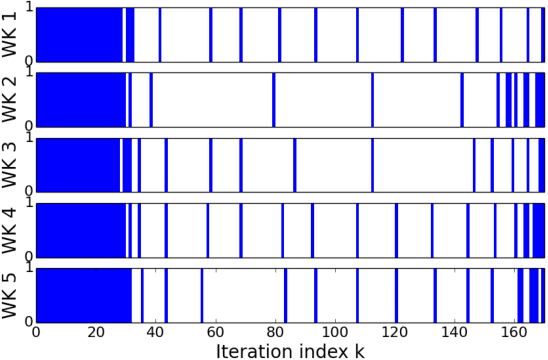
This paper develops a communication-efficient algorithm to solve the stochastic optimization problem defined over a distributed network, aiming at reducing the burdensome communication in applications such as distributed machine learning. Different from the existing works based on quantization and sparsification, we introduce a communication-censoring technique to reduce the transmissions of variables, which leads to our communication-Censored distributed Stochastic Gradient Descent (CSGD) algorithm. Specifically, in CSGD, the latest mini-batch stochastic gradient at a worker will be transmitted to the server only if it is sufficiently informative. When the latest gradient is not available, the stale one will be reused at the server. To implement this communication-censoring strategy, the batch sizes are increasing in order to alleviate the effect of gradient noise. Theoretically, CSGD enjoys the same order of convergence rate as that of SGD, but effectively reduces communication. Numerical experiments further demonstrate the sizable communication saving of CSGD.
Asynchronous Stochastic Composition Optimization with Variance Reduction
Nov 15, 2018
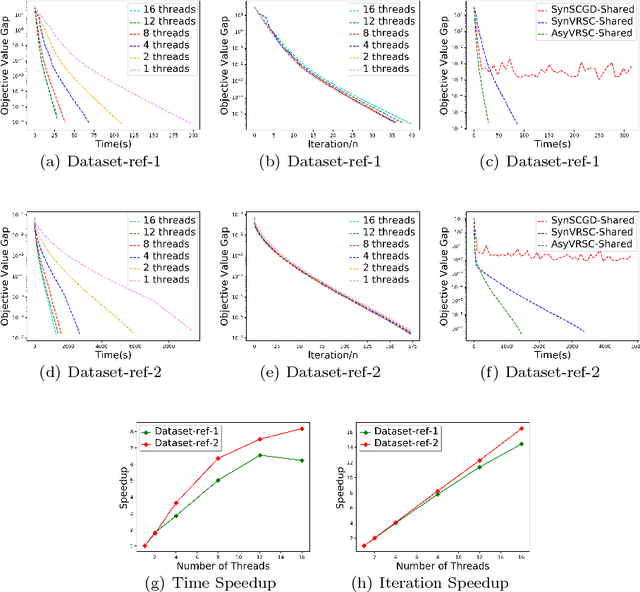

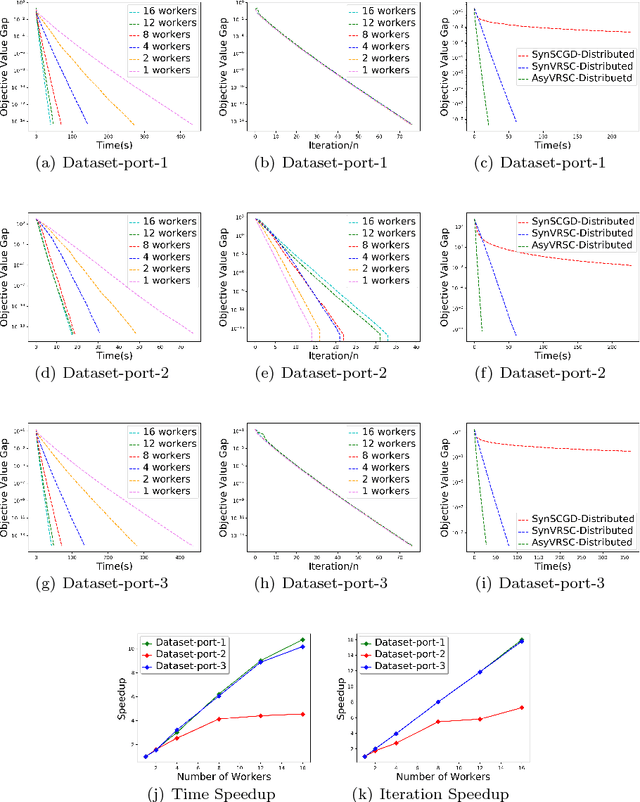
Composition optimization has drawn a lot of attention in a wide variety of machine learning domains from risk management to reinforcement learning. Existing methods solving the composition optimization problem often work in a sequential and single-machine manner, which limits their applications in large-scale problems. To address this issue, this paper proposes two asynchronous parallel variance reduced stochastic compositional gradient (AsyVRSC) algorithms that are suitable to handle large-scale data sets. The two algorithms are AsyVRSC-Shared for the shared-memory architecture and AsyVRSC-Distributed for the master-worker architecture. The embedded variance reduction techniques enable the algorithms to achieve linear convergence rates. Furthermore, AsyVRSC-Shared and AsyVRSC-Distributed enjoy provable linear speedup, when the time delays are bounded by the data dimensionality or the sparsity ratio of the partial gradients, respectively. Extensive experiments are conducted to verify the effectiveness of the proposed algorithms.
RSA: Byzantine-Robust Stochastic Aggregation Methods for Distributed Learning from Heterogeneous Datasets
Nov 09, 2018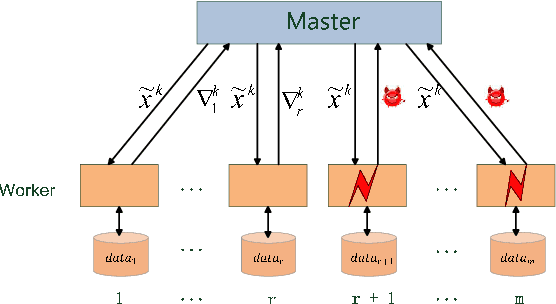
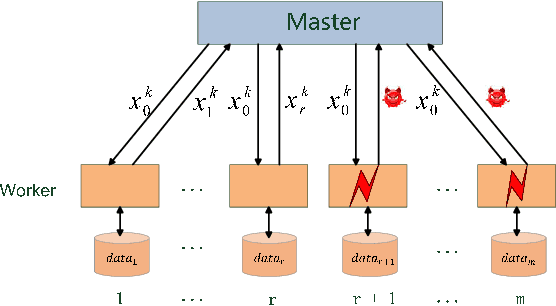
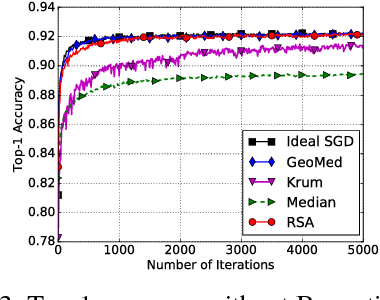
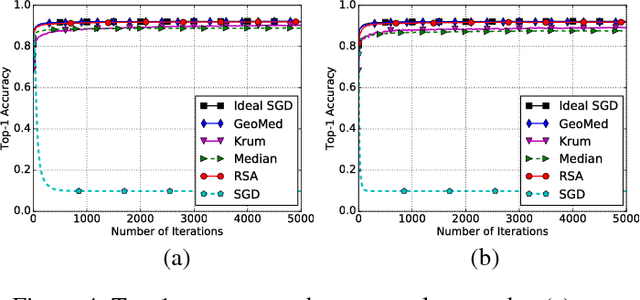
In this paper, we propose a class of robust stochastic subgradient methods for distributed learning from heterogeneous datasets at presence of an unknown number of Byzantine workers. The Byzantine workers, during the learning process, may send arbitrary incorrect messages to the master due to data corruptions, communication failures or malicious attacks, and consequently bias the learned model. The key to the proposed methods is a regularization term incorporated with the objective function so as to robustify the learning task and mitigate the negative effects of Byzantine attacks. The resultant subgradient-based algorithms are termed Byzantine-Robust Stochastic Aggregation methods, justifying our acronym RSA used henceforth. In contrast to most of the existing algorithms, RSA does not rely on the assumption that the data are independent and identically distributed (i.i.d.) on the workers, and hence fits for a wider class of applications. Theoretically, we show that: i) RSA converges to a near-optimal solution with the learning error dependent on the number of Byzantine workers; ii) the convergence rate of RSA under Byzantine attacks is the same as that of the stochastic gradient descent method, which is free of Byzantine attacks. Numerically, experiments on real dataset corroborate the competitive performance of RSA and a complexity reduction compared to the state-of-the-art alternatives.
DADA: Deep Adversarial Data Augmentation for Extremely Low Data Regime Classification
Aug 29, 2018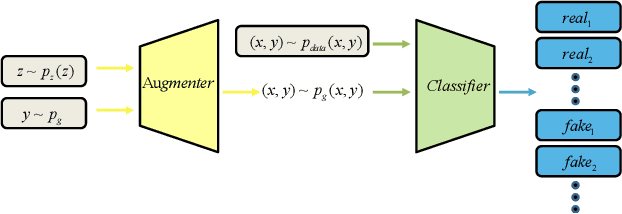

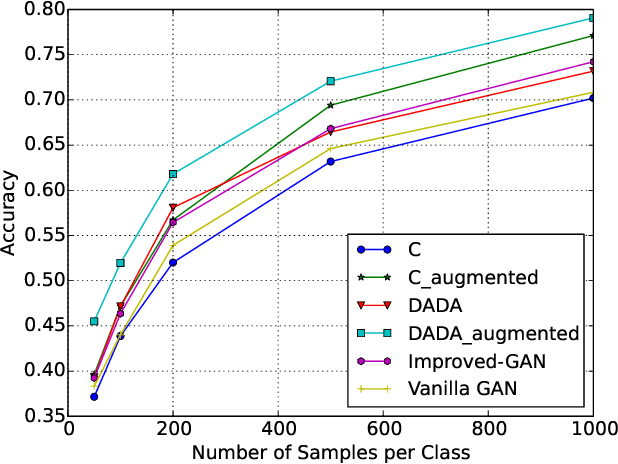
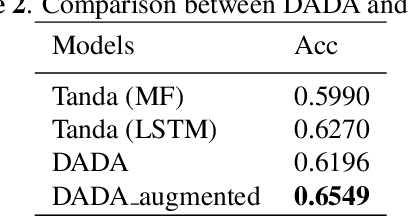
Deep learning has revolutionized the performance of classification, but meanwhile demands sufficient labeled data for training. Given insufficient data, while many techniques have been developed to help combat overfitting, the challenge remains if one tries to train deep networks, especially in the ill-posed extremely low data regimes: only a small set of labeled data are available, and nothing -- including unlabeled data -- else. Such regimes arise from practical situations where not only data labeling but also data collection itself is expensive. We propose a deep adversarial data augmentation (DADA) technique to address the problem, in which we elaborately formulate data augmentation as a problem of training a class-conditional and supervised generative adversarial network (GAN). Specifically, a new discriminator loss is proposed to fit the goal of data augmentation, through which both real and augmented samples are enforced to contribute to and be consistent in finding the decision boundaries. Tailored training techniques are developed accordingly. To quantitatively validate its effectiveness, we first perform extensive simulations to show that DADA substantially outperforms both traditional data augmentation and a few GAN-based options. We then extend experiments to three real-world small labeled datasets where existing data augmentation and/or transfer learning strategies are either less effective or infeasible. All results endorse the superior capability of DADA in enhancing the generalization ability of deep networks trained in practical extremely low data regimes. Source code is available at https://github.com/SchafferZhang/DADA.
An Online Convex Optimization Approach to Dynamic Network Resource Allocation
Jan 27, 2017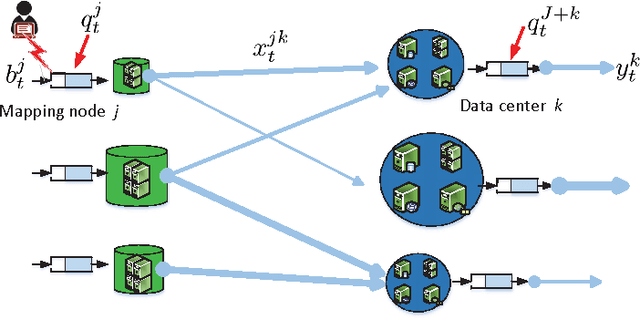
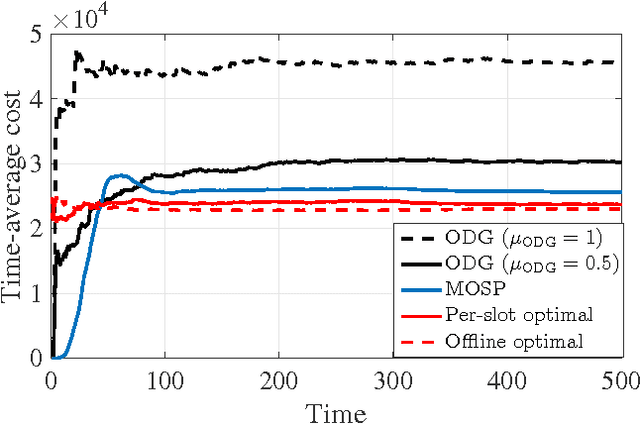
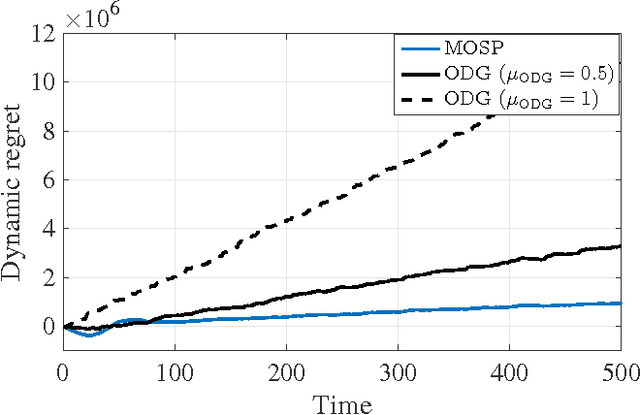
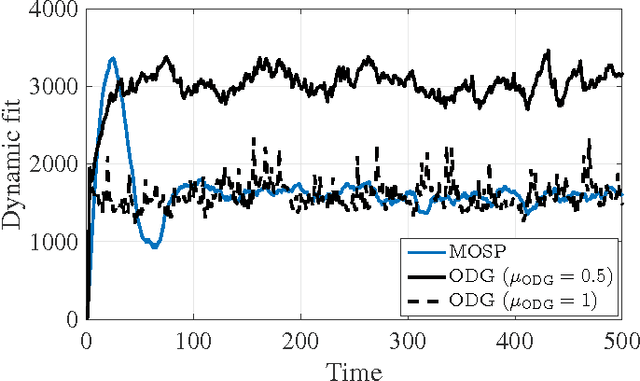
Existing approaches to online convex optimization (OCO) make sequential one-slot-ahead decisions, which lead to (possibly adversarial) losses that drive subsequent decision iterates. Their performance is evaluated by the so-called regret that measures the difference of losses between the online solution and the best yet fixed overall solution in hindsight. The present paper deals with online convex optimization involving adversarial loss functions and adversarial constraints, where the constraints are revealed after making decisions, and can be tolerable to instantaneous violations but must be satisfied in the long term. Performance of an online algorithm in this setting is assessed by: i) the difference of its losses relative to the best dynamic solution with one-slot-ahead information of the loss function and the constraint (that is here termed dynamic regret); and, ii) the accumulated amount of constraint violations (that is here termed dynamic fit). In this context, a modified online saddle-point (MOSP) scheme is developed, and proved to simultaneously yield sub-linear dynamic regret and fit, provided that the accumulated variations of per-slot minimizers and constraints are sub-linearly growing with time. MOSP is also applied to the dynamic network resource allocation task, and it is compared with the well-known stochastic dual gradient method. Under various scenarios, numerical experiments demonstrate the performance gain of MOSP relative to the state-of-the-art.