 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Token Dropping Strategy in Efficient BERT Pretraining
May 24, 2023



Token dropping is a recently-proposed strategy to speed up the pretraining of masked language models, such as BERT, by skipping the computation of a subset of the input tokens at several middle layers. It can effectively reduce the training time without degrading much performance on downstream tasks. However, we empirically find that token dropping is prone to a semantic loss problem and falls short in handling semantic-intense tasks. Motivated by this, we propose a simple yet effective semantic-consistent learning method (ScTD) to improve the token dropping. ScTD aims to encourage the model to learn how to preserve the semantic information in the representation space. Extensive experiments on 12 tasks show that, with the help of our ScTD, token dropping can achieve consistent and significant performance gains across all task types and model sizes. More encouragingly, ScTD saves up to 57% of pretraining time and brings up to +1.56% average improvement over the vanilla token dropping.
Self-Evolution Learning for Mixup: Enhance Data Augmentation on Few-Shot Text Classification Tasks
May 22, 2023



Text classification tasks often encounter few shot scenarios with limited labeled data, and addressing data scarcity is crucial. Data augmentation with mixup has shown to be effective on various text classification tasks. However, most of the mixup methods do not consider the varying degree of learning difficulty in different stages of training and generate new samples with one hot labels, resulting in the model over confidence. In this paper, we propose a self evolution learning (SE) based mixup approach for data augmentation in text classification, which can generate more adaptive and model friendly pesudo samples for the model training. SE focuses on the variation of the model's learning ability. To alleviate the model confidence, we introduce a novel instance specific label smoothing approach, which linearly interpolates the model's output and one hot labels of the original samples to generate new soft for label mixing up. Through experimental analysis, in addition to improving classification accuracy, we demonstrate that SE also enhances the model's generalize ability.
Towards Making the Most of ChatGPT for Machine Translation
Mar 24, 2023



ChatGPT shows remarkable capabilities for machine translation (MT). Several prior studies have shown that it achieves comparable results to commercial systems for high-resource languages, but lags behind in complex tasks, e.g, low-resource and distant-language-pairs translation. However, they usually adopt simple prompts which can not fully elicit the capability of ChatGPT. In this report, we aim to further mine ChatGPT's translation ability by revisiting several aspects: temperature, task information, and domain information, and correspondingly propose two (simple but effective) prompts: Task-Specific Prompts (TSP) and Domain-Specific Prompts (DSP). We show that: 1) The performance of ChatGPT depends largely on temperature, and a lower temperature usually can achieve better performance; 2) Emphasizing the task information further improves ChatGPT's performance, particularly in complex MT tasks; 3) Introducing domain information can elicit ChatGPT's generalization ability and improve its performance in the specific domain; 4) ChatGPT tends to generate hallucinations for non-English-centric MT tasks, which can be partially addressed by our proposed prompts but still need to be highlighted for the MT/NLP community. We also explore the effects of advanced in-context learning strategies and find a (negative but interesting) observation: the powerful chain-of-thought prompt leads to word-by-word translation behavior, thus bringing significant translation degradation.
Can ChatGPT Understand Too? A Comparative Study on ChatGPT and Fine-tuned BERT
Mar 02, 2023



Recently, ChatGPT has attracted great attention, as it can generate fluent and high-quality responses to human inquiries. Several prior studies have shown that ChatGPT attains remarkable generation ability compared with existing models. However, the quantitative analysis of ChatGPT's understanding ability has been given little attention. In this report, we explore the understanding ability of ChatGPT by evaluating it on the most popular GLUE benchmark, and comparing it with 4 representative fine-tuned BERT-style models. We find that: 1) ChatGPT falls short in handling paraphrase and similarity tasks; 2) ChatGPT outperforms all BERT models on inference tasks by a large margin; 3) ChatGPT achieves comparable performance compared with BERT on sentiment analysis and question-answering tasks. Additionally, by combining some advanced prompting strategies, we show that the understanding ability of ChatGPT can be further improved.
AdaSAM: Boosting Sharpness-Aware Minimization with Adaptive Learning Rate and Momentum for Training Deep Neural Networks
Mar 01, 2023Sharpness aware minimization (SAM) optimizer has been extensively explored as it can generalize better for training deep neural networks via introducing extra perturbation steps to flatten the landscape of deep learning models. Integrating SAM with adaptive learning rate and momentum acceleration, dubbed AdaSAM, has already been explored empirically to train large-scale deep neural networks without theoretical guarantee due to the triple difficulties in analyzing the coupled perturbation step, adaptive learning rate and momentum step. In this paper, we try to analyze the convergence rate of AdaSAM in the stochastic non-convex setting. We theoretically show that AdaSAM admits a $\mathcal{O}(1/\sqrt{bT})$ convergence rate, which achieves linear speedup property with respect to mini-batch size $b$. Specifically, to decouple the stochastic gradient steps with the adaptive learning rate and perturbed gradient, we introduce the delayed second-order momentum term to decompose them to make them independent while taking an expectation during the analysis. Then we bound them by showing the adaptive learning rate has a limited range, which makes our analysis feasible. To the best of our knowledge, we are the first to provide the non-trivial convergence rate of SAM with an adaptive learning rate and momentum acceleration. At last, we conduct several experiments on several NLP tasks, which show that AdaSAM could achieve superior performance compared with SGD, AMSGrad, and SAM optimizers.
Bag of Tricks for Effective Language Model Pretraining and Downstream Adaptation: A Case Study on GLUE
Feb 18, 2023



This technical report briefly describes our JDExplore d-team's submission Vega v1 on the General Language Understanding Evaluation (GLUE) leaderboard, where GLUE is a collection of nine natural language understanding tasks, including question answering, linguistic acceptability, sentiment analysis, text similarity, paraphrase detection, and natural language inference. [Method] We investigate several effective strategies and choose their best combination setting as the training recipes. As for model structure, we employ the vanilla Transformer with disentangled attention as the basic block encoder. For self-supervised training, we employ the representative denoising objective (i.e., replaced token detection) in phase 1 and combine the contrastive objective (i.e., sentence embedding contrastive learning) with it in phase 2. During fine-tuning, several advanced techniques such as transductive fine-tuning, self-calibrated fine-tuning, and adversarial fine-tuning are adopted. [Results] According to our submission record (Jan. 2022), with our optimized pretraining and fine-tuning strategies, our 1.3 billion model sets new state-of-the-art on 4/9 tasks, achieving the best average score of 91.3. Encouragingly, our Vega v1 is the first to exceed powerful human performance on the two challenging tasks, i.e., SST-2 and WNLI. We believe our empirically successful recipe with a bag of tricks could shed new light on developing efficient discriminative large language models.
Toward Efficient Language Model Pretraining and Downstream Adaptation via Self-Evolution: A Case Study on SuperGLUE
Dec 04, 2022



This technical report briefly describes our JDExplore d-team's Vega v2 submission on the SuperGLUE leaderboard. SuperGLUE is more challenging than the widely used general language understanding evaluation (GLUE) benchmark, containing eight difficult language understanding tasks, including question answering, natural language inference, word sense disambiguation, coreference resolution, and reasoning. [Method] Instead of arbitrarily increasing the size of a pretrained language model (PLM), our aim is to 1) fully extract knowledge from the input pretraining data given a certain parameter budget, e.g., 6B, and 2) effectively transfer this knowledge to downstream tasks. To achieve goal 1), we propose self-evolution learning for PLMs to wisely predict the informative tokens that should be masked, and supervise the masked language modeling (MLM) process with rectified smooth labels. For goal 2), we leverage the prompt transfer technique to improve the low-resource tasks by transferring the knowledge from the foundation model and related downstream tasks to the target task. [Results] According to our submission record (Oct. 2022), with our optimized pretraining and fine-tuning strategies, our 6B Vega method achieved new state-of-the-art performance on 4/8 tasks, sitting atop the SuperGLUE leaderboard on Oct. 8, 2022, with an average score of 91.3.
Improving Sharpness-Aware Minimization with Fisher Mask for Better Generalization on Language Models
Oct 11, 2022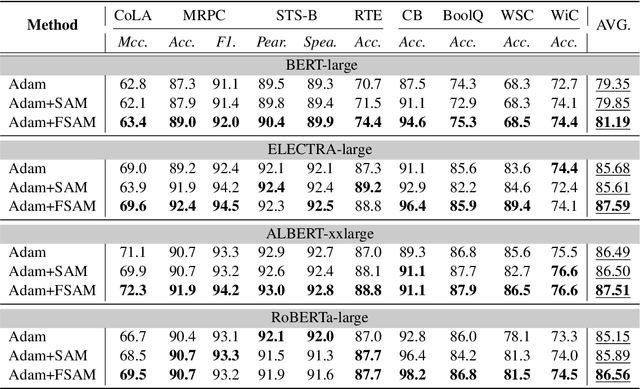
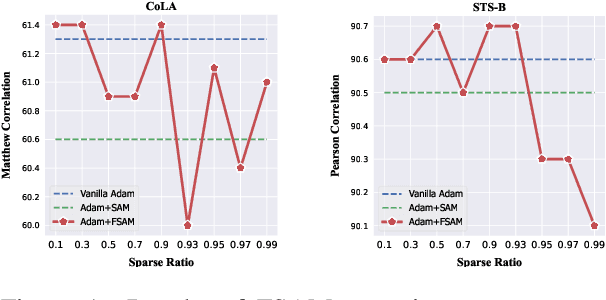
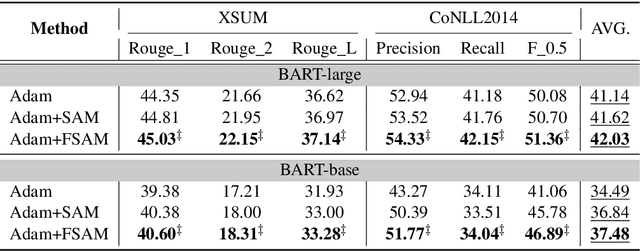
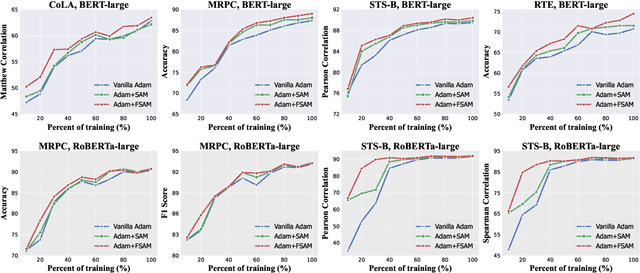
Fine-tuning large pretrained language models on a limited training corpus usually suffers from poor generalization. Prior works show that the recently-proposed sharpness-aware minimization (SAM) optimization method can improve the model generalization. However, SAM adds a perturbation to each model parameter equally (but not all parameters contribute equally to the optimization of training), which we argue is sub-optimal and will lead to excessive computation. In this paper, we propose a novel optimization procedure, namely FSAM, which introduces a Fisher mask to improve the efficiency and performance of SAM. In short, instead of adding perturbation to all parameters, FSAM uses the Fisher information to identity the important parameters and formulates a Fisher mask to obtain the sparse perturbation, i.e., making the optimizer focus on these important parameters. Experiments on various tasks in GLUE and SuperGLUE benchmarks show that FSAM consistently outperforms the vanilla SAM by 0.67~1.98 average score among four different pretrained models. We also empirically show that FSAM works well in other complex scenarios, e.g., fine-tuning on generation tasks or limited training data. Encouragingly, when training data is limited, FSAM improves the SAM by a large margin, i.e., up to 15.1.
PANDA: Prompt Transfer Meets Knowledge Distillation for Efficient Model Adaptation
Aug 22, 2022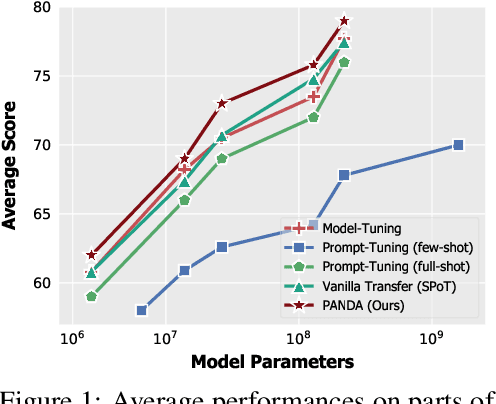
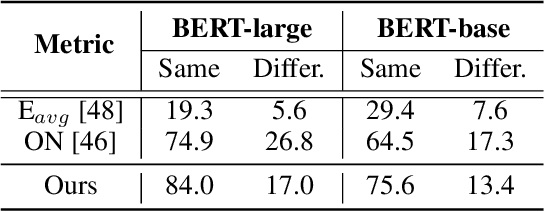
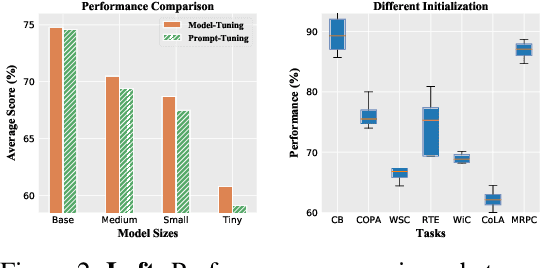
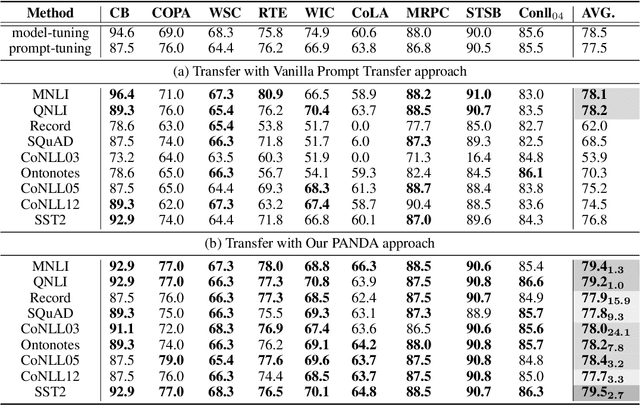
Prompt-tuning, which freezes pretrained language models (PLMs) and only fine-tunes few parameters of additional soft prompt, shows competitive performance against full-parameter fine-tuning (i.e.model-tuning) when the PLM has billions of parameters, but still performs poorly in the case of smaller PLMs. Hence, prompt transfer (PoT), which initializes the target prompt with the trained prompt of similar source tasks, is recently proposed to improve over prompt-tuning. However, such a vanilla PoT approach usually achieves sub-optimal performance, as (i) the PoT is sensitive to the similarity of source-target pair and (ii) directly fine-tuning the prompt initialized with source prompt on target task might lead to catastrophic forgetting of source knowledge. In response to these problems, we propose a new metric to accurately predict the prompt transferability (regarding (i)), and a novel PoT approach (namely PANDA) that leverages the knowledge distillation technique to transfer the "knowledge" from the source prompt to the target prompt in a subtle manner and alleviate the catastrophic forgetting effectively (regarding (ii)). Furthermore, to achieve adaptive prompt transfer for each source-target pair, we use our metric to control the knowledge transfer in our PANDA approach. Extensive and systematic experiments on 189 combinations of 21 source and 9 target datasets across 5 scales of PLMs demonstrate that: 1) our proposed metric works well to predict the prompt transferability; 2) our PANDA consistently outperforms the vanilla PoT approach by 2.3% average score (up to 24.1%) among all tasks and model sizes; 3) with our PANDA approach, prompt-tuning can achieve competitive and even better performance than model-tuning in various PLM scales scenarios. Code and models will be released upon acceptance.
E2S2: Encoding-Enhanced Sequence-to-Sequence Pretraining for Language Understanding and Generation
May 30, 2022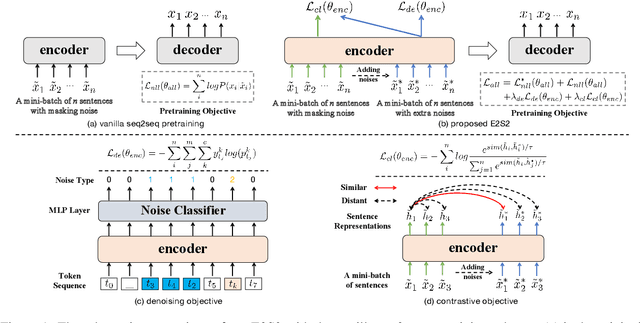
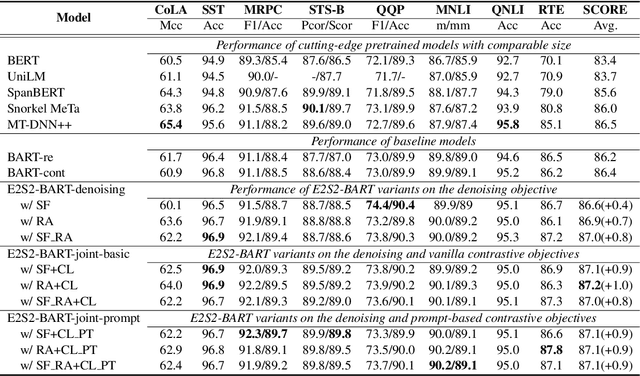
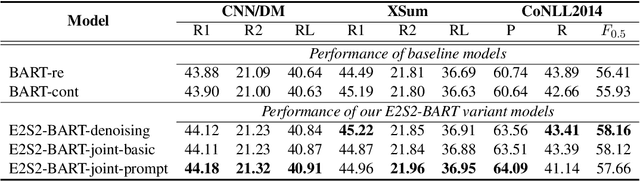
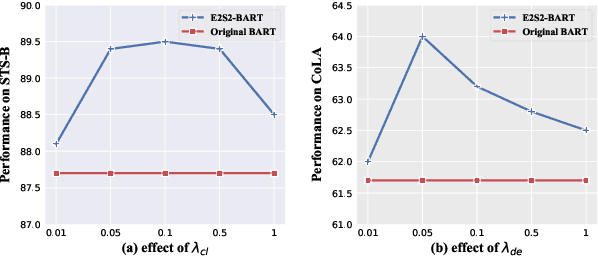
Sequence-to-sequence (seq2seq) learning has become a popular trend for pretraining language models, due to its succinct and universal framework. However, the prior seq2seq pretraining models generally focus on reconstructive objectives on the decoder side and neglect the effect of encoder-side supervisions, which may lead to sub-optimal performance. To this end, we propose an encoding-enhanced seq2seq pretraining strategy, namely E2S2, which improves the seq2seq models via integrating more efficient self-supervised information into the encoders. Specifically, E2S2 contains two self-supervised objectives upon the encoder, which are from two perspectives: 1) denoising the corrupted sentence (denoising objective); 2) learning robust sentence representations (contrastive objective). With these two objectives, the encoder can effectively distinguish the noise tokens and capture more syntactic and semantic knowledge, thus strengthening the ability of seq2seq model to comprehend the input sentence and conditionally generate the target. We conduct extensive experiments spanning language understanding and generation tasks upon the state-of-the-art seq2seq pretrained language model BART. We show that E2S2 can consistently boost the performance, including 1.0% averaged gain on GLUE benchmark and 1.75% F_0.5 score improvement on CoNLL2014 dataset, validating the effectiveness and robustness of our E2S2.