 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRIME: Uncovering Circadian Oscillation Patterns and Associations with AD in Untimed Genome-wide Gene Expression across Multiple Brain Regions
Aug 25, 2022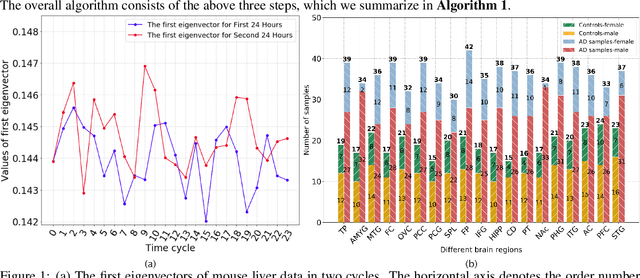
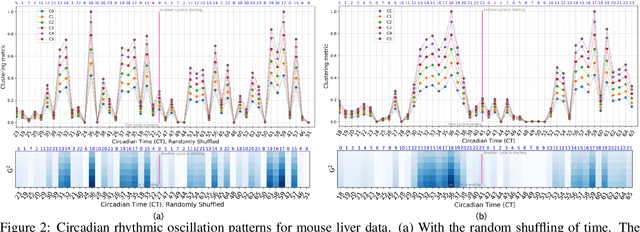
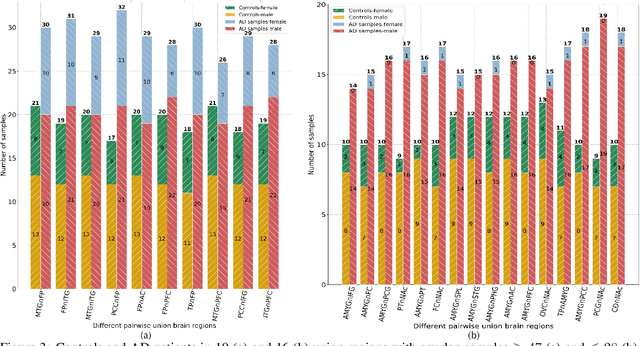
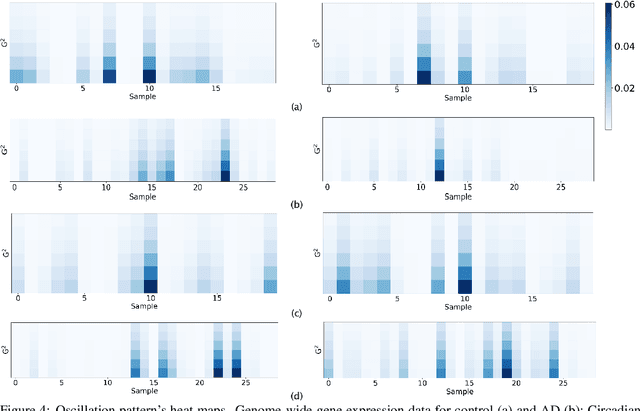
The disruption of circadian rhythm is a cardinal symptom for Alzheimer's disease (AD) patients. The full circadian rhythm orchestration of gene expression in the human brain and its inherent associations with AD remain largely unknown. We present a novel comprehensive approach, PRIME, to detect and analyze rhythmic oscillation patterns in untimed high-dimensional gene expression data across multiple datasets. To demonstrate the utility of PRIME, firstly, we validate it by a time course expression dataset from mouse liver as a cross-species and cross-organ validation. Then, we apply it to study oscillation patterns in untimed genome-wide gene expression from 19 human brain regions of controls and AD patients. Our findings reveal clear, synchronized oscillation patterns in 15 pairs of brain regions of control, while these oscillation patterns either disappear or dim for AD. It is worth noting that PRIME discovers the circadian rhythmic patterns without requiring the sample's timestamps. The codes for PRIME, along with codes to reproduce the figures in this paper, are available at https://github.com/xinxingwu-uk/PRIME.
* 10 pages
Log-based Sparse Nonnegative Matrix Factorization for Data Representation
Apr 22, 2022
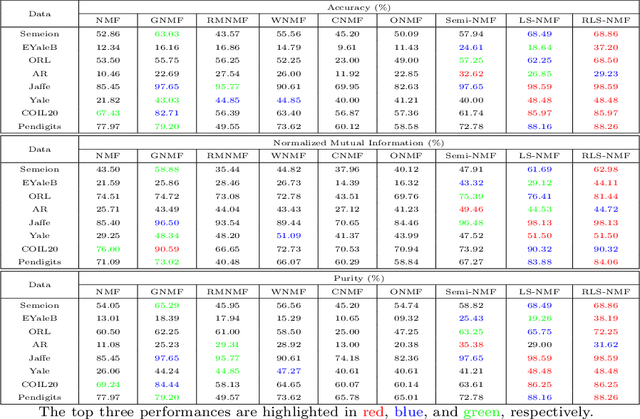

Nonnegative matrix factorization (NMF) has been widely studied in recent years due to its effectiveness in representing nonnegative data with parts-based representations. For NMF, a sparser solution implies better parts-based representation.However, current NMF methods do not always generate sparse solutions.In this paper, we propose a new NMF method with log-norm imposed on the factor matrices to enhance the sparseness.Moreover, we propose a novel column-wisely sparse norm, named $\ell_{2,\log}$-(pseudo) norm to enhance the robustness of the proposed method.The $\ell_{2,\log}$-(pseudo) norm is invariant, continuous, and differentiable.For the $\ell_{2,\log}$ regularized shrinkage problem, we derive a closed-form solution, which can be used for other general problems.Efficient multiplicative updating rules are developed for the optimization, which theoretically guarantees the convergence of the objective value sequence.Extensive experimental results confirm the effectiveness of the proposed method, as well as the enhanced sparseness and robustness.
Hyperspectral Image Denoising Using Non-convex Local Low-rank and Sparse Separation with Spatial-Spectral Total Variation Regularization
Jan 08, 2022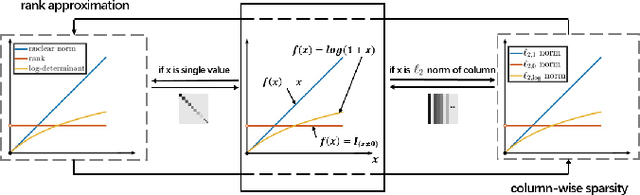


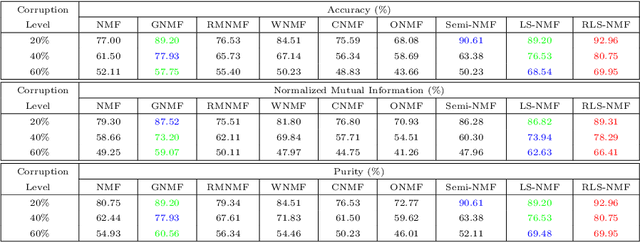
In this paper, we propose a novel nonconvex approach to robust principal component analysis for HSI denoising, which focuses on simultaneously developing more accurate approximations to both rank and column-wise sparsity for the low-rank and sparse components, respectively. In particular, the new method adopts the log-determinant rank approximation and a novel $\ell_{2,\log}$ norm, to restrict the local low-rank or column-wisely sparse properties for the component matrices, respectively. For the $\ell_{2,\log}$-regularized shrinkage problem, we develop an efficient, closed-form solution, which is named $\ell_{2,\log}$-shrinkage operator. The new regularization and the corresponding operator can be generally used in other problems that require column-wise sparsity. Moreover, we impose the spatial-spectral total variation regularization in the log-based nonconvex RPCA model, which enhances the global piece-wise smoothness and spectral consistency from the spatial and spectral views in the recovered HSI. Extensive experiments on both simulated and real HSIs demonstrate the effectiveness of the proposed method in denoising HSIs.
Modeling and Measurements for Multi-path Mitigation with Reconfigurable Intelligent Surfaces
Sep 24, 2021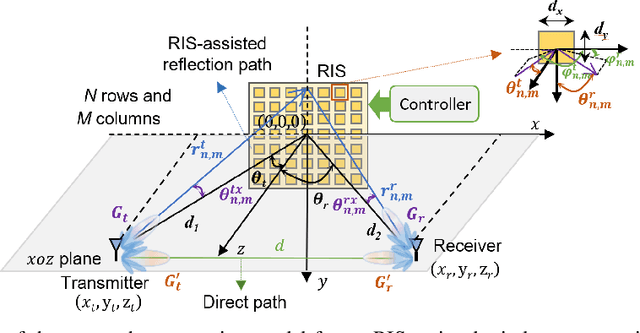
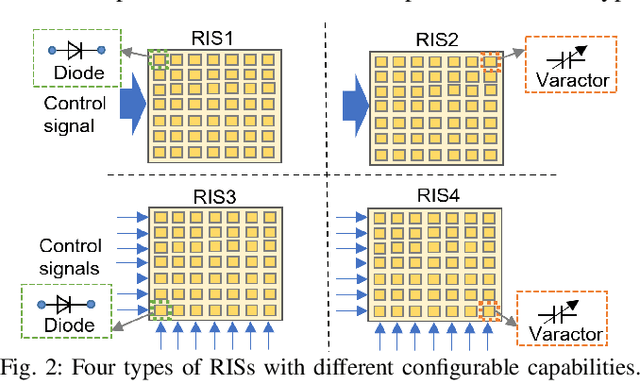
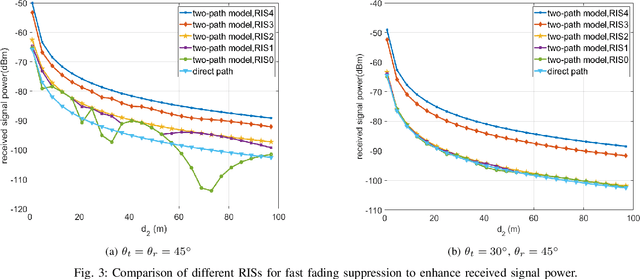
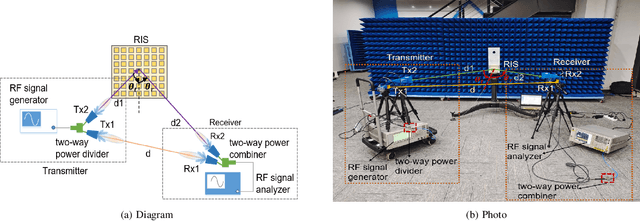
A reconfigurable intelligent surface (RIS) is capable of manipulating electromagnetic waves with its flexibly configurable unit cells, thus is an appealing technology to resist fast fading caused by multi-path in wireless communications. In this paper, a two-path propagation model for RIS-assisted wireless communications is proposed by considering both the direct path from the transmitter to the receiver and the assisted path provided by the RIS. The proposed propagation model unveils that the phase shifts of RISs can be optimized by appropriate configuration for multi-path fading mitigation. In particular, four types of RISs with different configuration capabilities are introduced and their performances on improving received signal power in virtue of the assisted path to resist fast fading are compared through extensive simulation results. In addition, an RIS operating at 35 GHz is used for experimental measurement. The experimental results verify that an RIS has the ability to combat fast fading and thus improves the receiving performance, which may lay a foundation for further researches.
Design and Implementation of MIMO Transmission Based on Dual-Polarized Reconfigurable Intelligent Surface
Jul 02, 2021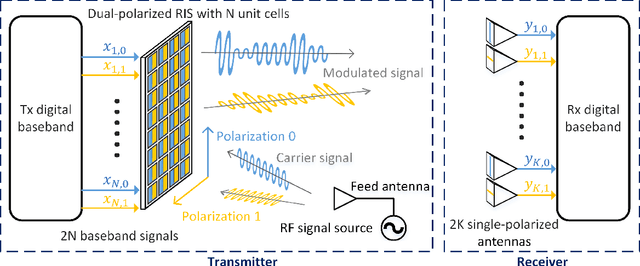
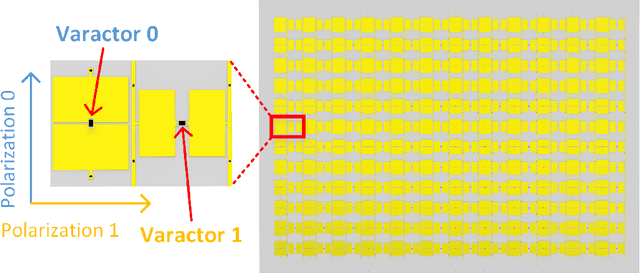
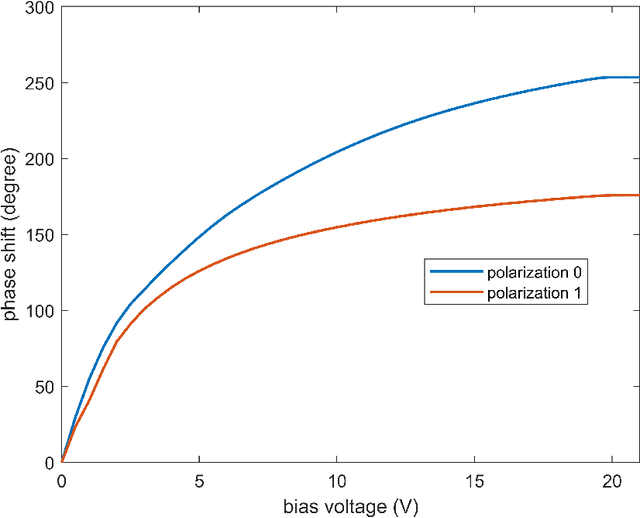
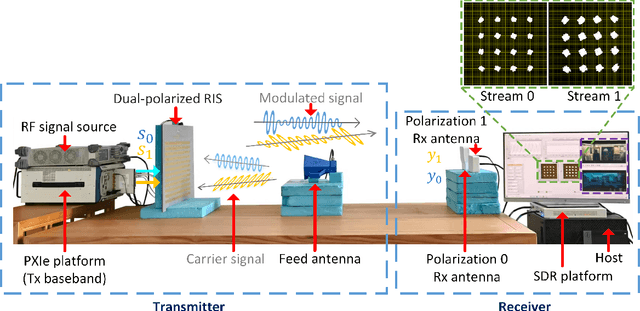
Multiple-input multiple-output (MIMO) signaling is one of the key technologies of current mobile communication systems. However, the complex and expensive radio frequency (RF) chains have always limited the increase of MIMO scale. In this paper, we propose a MIMO transmission architecture based on a dual-polarized reconfigurable intelligent surface (RIS), which can directly achieve modulation and transmission of multichannel signals without the need for conventional RF chains. Compared with previous works, the proposed architecture can improve the integration of RIS-based transmission systems. A prototype of the dual-polarized RIS-based MIMO transmission system is built and the experimental results confirm the feasibility of the proposed architecture. The dual-polarized RIS-based MIMO transmission architecture provides a promising solution for realizing low-cost ultra-massive MIMO towards future networks.
Top-$k$ Regularization for Supervised Feature Selection
Jun 04, 2021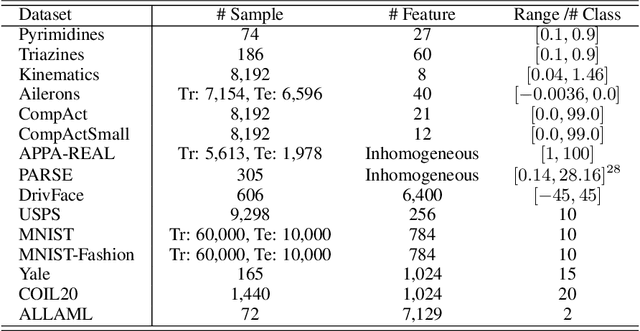
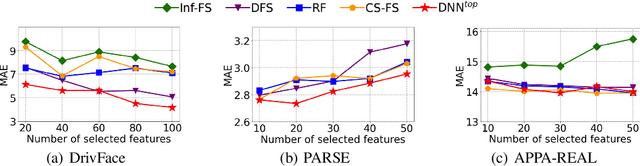
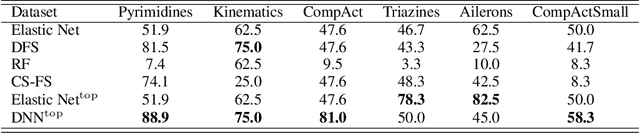
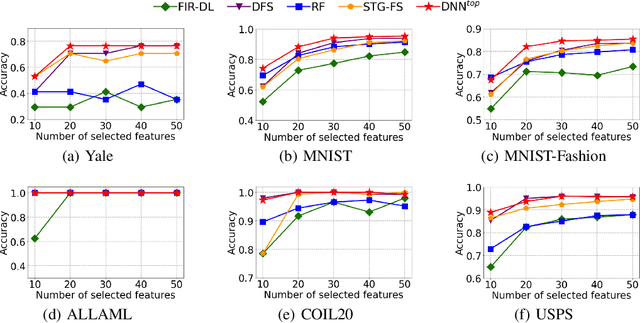
Feature selection identifies subsets of informative features and reduces dimensions in the original feature space, helping provide insights into data generation or a variety of domain problems. Existing methods mainly depend on feature scoring functions or sparse regularizations; nonetheless, they have limited ability to reconcile the representativeness and inter-correlations of features. In this paper, we introduce a novel, simple yet effective regularization approach, named top-$k$ regularization, to supervised feature selection in regression and classification tasks. Structurally, the top-$k$ regularization induces a sub-architecture on the architecture of a learning model to boost its ability to select the most informative features and model complex nonlinear relationships simultaneously. Theoretically, we derive and mathematically prove a uniform approximation error bound for using this approach to approximate high-dimensional sparse functions. Extensive experiments on a wide variety of benchmarking datasets show that the top-$k$ regularization is effective and stable for supervised feature selection.
Hyperspectral Image Denoising with Log-Based Robust PCA
May 25, 2021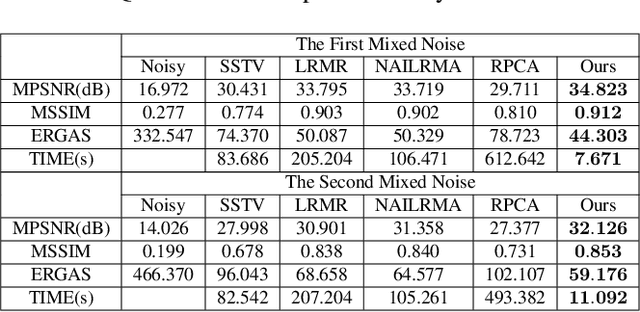


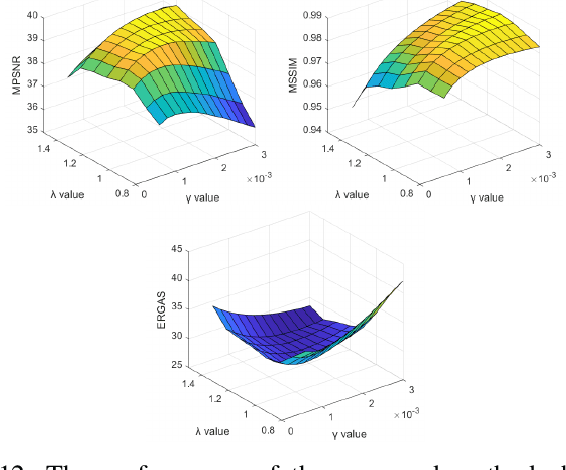
It is a challenging task to remove heavy and mixed types of noise from Hyperspectral images (HSIs). In this paper, we propose a novel nonconvex approach to RPCA for HSI denoising, which adopts the log-determinant rank approximation and a novel $\ell_{2,\log}$ norm, to restrict the low-rank or column-wise sparse properties for the component matrices, respectively.For the $\ell_{2,\log}$-regularized shrinkage problem, we develop an efficient, closed-form solution, which is named $\ell_{2,\log}$-shrinkage operator, which can be generally used in other problems. Extensive experiments on both simulated and real HSIs demonstrate the effectiveness of the proposed method in denoising HSIs.
Deepened Graph Auto-Encoders Help Stabilize and Enhance Link Prediction
Mar 21, 2021
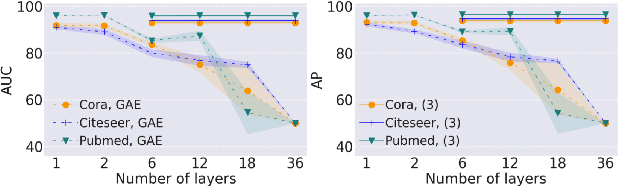
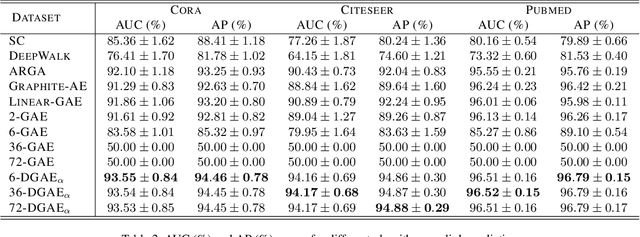
Graph neural networks have been used for a variety of learning tasks, such as link prediction, node classification, and node clustering. Among them, link prediction is a relatively under-studied graph learning task, with current state-of-the-art models based on one- or two-layer of shallow graph auto-encoder (GAE) architectures. In this paper, we focus on addressing a limitation of current methods for link prediction, which can only use shallow GAEs and variational GAEs, and creating effective methods to deepen (variational) GAE architectures to achieve stable and competitive performance. Our proposed methods innovatively incorporate standard auto-encoders (AEs) into the architectures of GAEs, where standard AEs are leveraged to learn essential, low-dimensional representations via seamlessly integrating the adjacency information and node features, while GAEs further build multi-scaled low-dimensional representations via residual connections to learn a compact overall embedding for link prediction. Empirically, extensive experiments on various benchmarking datasets verify the effectiveness of our methods and demonstrate the competitive performance of our deepened graph models for link prediction. Theoretically, we prove that our deep extensions inclusively express multiple polynomial filters with different orders.
Path Loss Modeling and Measurements for Reconfigurable Intelligent Surfaces in the Millimeter-Wave Frequency Band
Jan 21, 2021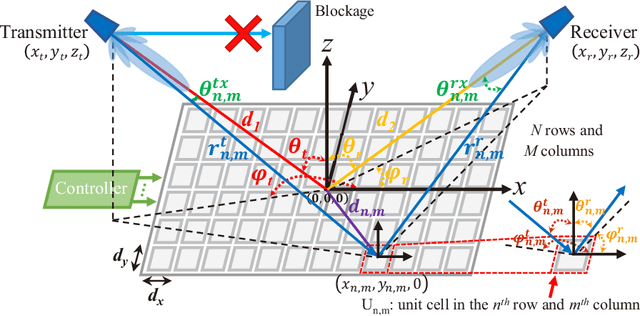
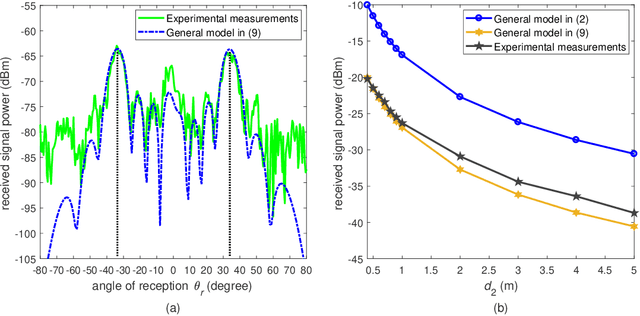
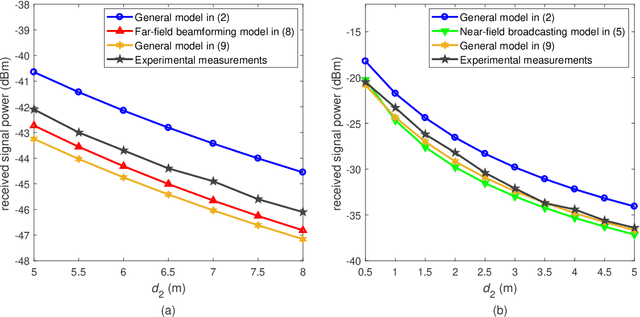
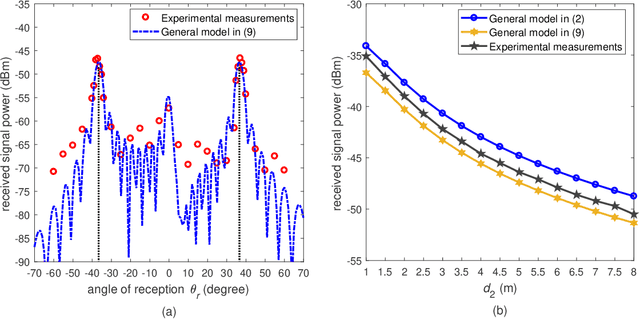
Reconfigurable intelligent surfaces (RISs) provide an interface between the electromagnetic world of the wireless propagation environment and the digital world of information science. Simple yet sufficiently accurate path loss models for RISs are an important basis for theoretical analysis and optimization of RIS-assisted wireless communication systems. In this paper, we refine our previously proposed free-space path loss model for RISs to make it simpler, more applicable, and easier to use. In the proposed path loss model, the impact of the radiation patterns of the antennas and unit cells of the RIS is formulated in terms of an angle-dependent loss factor. The refined model gives more accurate estimates of the path loss of RISs comprised of unit cells with a deep sub-wavelength size. The free-space path loss model of the sub-channel provided by a single unit cell is also explicitly provided. In addition, two fabricated RISs, which are designed to operate in the millimeter-wave (mmWave) band, are utilized to carry out a measurement campaign in order to characterize and validate the proposed path loss model for RIS-assisted wireless communications. The measurement results corroborate the proposed analytical model. The proposed refined path loss model for RISs reveals that the reflecting capability of a single unit cell is proportional to its physical aperture and to an angle-dependent factor. In particular, the far-field beamforming gain provided by an RIS is mainly determined by the total area of the surface and by the angles of incidence and reflection.
Adaptive Weighted Discriminator for Training Generative Adversarial Networks
Dec 05, 2020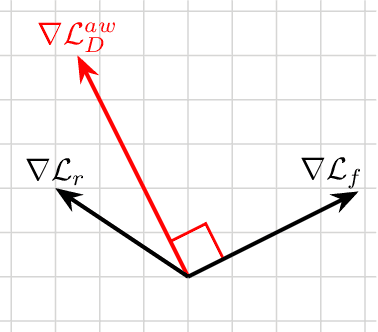
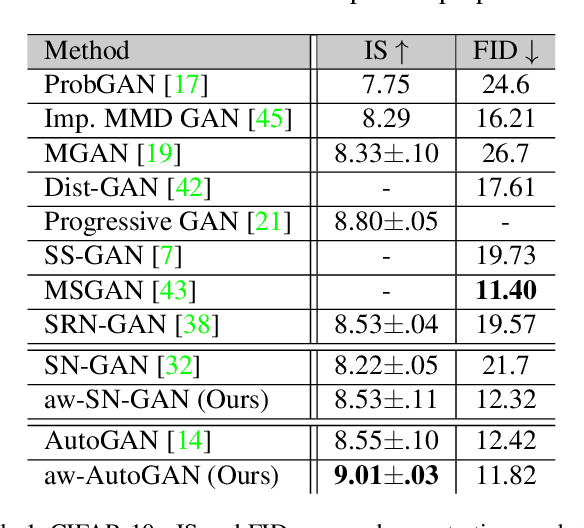

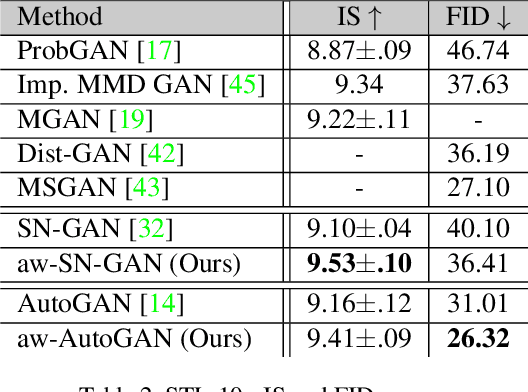
Generative adversarial network (GAN) has become one of the most important neural network models for classical unsupervised machine learning. A variety of discriminator loss functions have been developed to train GAN's discriminators and they all have a common structure: a sum of real and fake losses that only depends on the actual and generated data respectively. One challenge associated with an equally weighted sum of two losses is that the training may benefit one loss but harm the other, which we show causes instability and mode collapse. In this paper, we introduce a new family of discriminator loss functions that adopts a weighted sum of real and fake parts, which we call adaptive weighted loss functions or aw-loss functions. Using the gradients of the real and fake parts of the loss, we can adaptively choose weights to train a discriminator in the direction that benefits the GAN's stability. Our method can be potentially applied to any discriminator model with a loss that is a sum of the real and fake parts. Experiments validated the effectiveness of our loss functions on an unconditional image generation task, improving the baseline results by a significant margin on CIFAR-10, STL-10, and CIFAR-100 datasets in Inception Scores and FID.