 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Relative Pose Estimation Founded on Pose-only Imaging Geometry
Jan 24, 2024How to efficiently and accurately handle image matching outliers is a critical issue in two-view relative estimation. The prevailing RANSAC method necessitates that the minimal point pairs be inliers. This paper introduces a linear relative pose estimation algorithm for n $( n \geq 6$) point pairs, which is founded on the recent pose-only imaging geometry to filter out outliers by proper reweighting. The proposed algorithm is able to handle planar degenerate scenes, and enhance robustness and accuracy in the presence of a substantial ratio of outliers. Specifically, we embed the linear global translation (LiGT) constraint into the strategies of iteratively reweighted least-squares (IRLS) and RANSAC so as to realize robust outlier removal. Simulations and real tests of the Strecha dataset show that the proposed algorithm achieves relative rotation accuracy improvement of 2 $\sim$ 10 times in face of as large as 80% outliers.
An Analysis of Attention via the Lens of Exchangeability and Latent Variable Models
Dec 30, 2022



With the attention mechanism, transformers achieve significant empirical successes. Despite the intuitive understanding that transformers perform relational inference over long sequences to produce desirable representations, we lack a rigorous theory on how the attention mechanism achieves it. In particular, several intriguing questions remain open: (a) What makes a desirable representation? (b) How does the attention mechanism infer the desirable representation within the forward pass? (c) How does a pretraining procedure learn to infer the desirable representation through the backward pass? We observe that, as is the case in BERT and ViT, input tokens are often exchangeable since they already include positional encodings. The notion of exchangeability induces a latent variable model that is invariant to input sizes, which enables our theoretical analysis. - To answer (a) on representation, we establish the existence of a sufficient and minimal representation of input tokens. In particular, such a representation instantiates the posterior distribution of the latent variable given input tokens, which plays a central role in predicting output labels and solving downstream tasks. - To answer (b) on inference, we prove that attention with the desired parameter infers the latent posterior up to an approximation error, which is decreasing in input sizes. In detail, we quantify how attention approximates the conditional mean of the value given the key, which characterizes how it performs relational inference over long sequences. - To answer (c) on learning, we prove that both supervised and self-supervised objectives allow empirical risk minimization to learn the desired parameter up to a generalization error, which is independent of input sizes. Particularly, in the self-supervised setting, we identify a condition number that is pivotal to solving downstream tasks.
3D Cascade RCNN: High Quality Object Detection in Point Clouds
Nov 15, 2022



Recent progress on 2D object detection has featured Cascade RCNN, which capitalizes on a sequence of cascade detectors to progressively improve proposal quality, towards high-quality object detection. However, there has not been evidence in support of building such cascade structures for 3D object detection, a challenging detection scenario with highly sparse LiDAR point clouds. In this work, we present a simple yet effective cascade architecture, named 3D Cascade RCNN, that allocates multiple detectors based on the voxelized point clouds in a cascade paradigm, pursuing higher quality 3D object detector progressively. Furthermore, we quantitatively define the sparsity level of the points within 3D bounding box of each object as the point completeness score, which is exploited as the task weight for each proposal to guide the learning of each stage detector. The spirit behind is to assign higher weights for high-quality proposals with relatively complete point distribution, while down-weight the proposals with extremely sparse points that often incur noise during training. This design of completeness-aware re-weighting elegantly upgrades the cascade paradigm to be better applicable for the sparse input data, without increasing any FLOP budgets. Through extensive experiments on both the KITTI dataset and Waymo Open Dataset, we validate the superiority of our proposed 3D Cascade RCNN, when comparing to state-of-the-art 3D object detection techniques. The source code is publicly available at \url{https://github.com/caiqi/Cascasde-3D}.
Out-of-Distribution Detection with Hilbert-Schmidt Independence Optimization
Sep 26, 2022
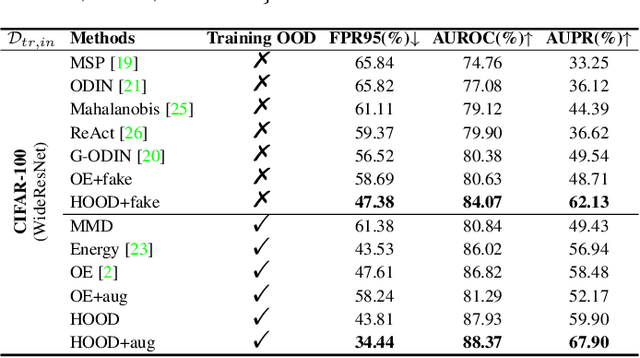
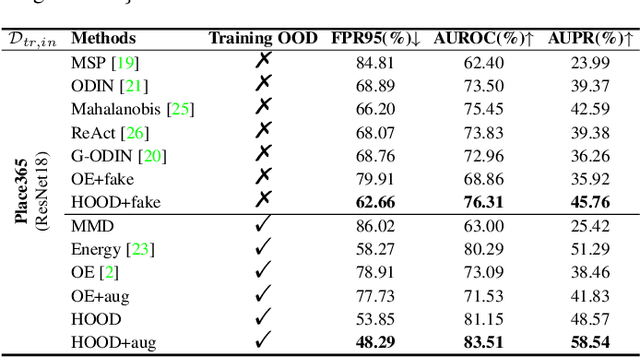
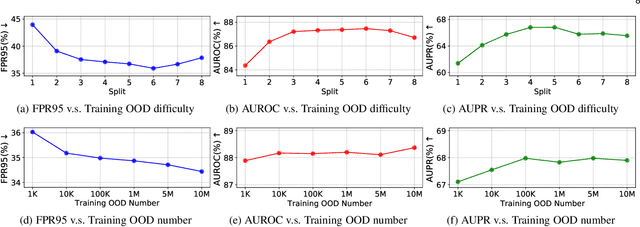
Outlier detection tasks have been playing a critical role in AI safety. There has been a great challenge to deal with this task. Observations show that deep neural network classifiers usually tend to incorrectly classify out-of-distribution (OOD) inputs into in-distribution classes with high confidence. Existing works attempt to solve the problem by explicitly imposing uncertainty on classifiers when OOD inputs are exposed to the classifier during training. In this paper, we propose an alternative probabilistic paradigm that is both practically useful and theoretically viable for the OOD detection tasks. Particularly, we impose statistical independence between inlier and outlier data during training, in order to ensure that inlier data reveals little information about OOD data to the deep estimator during training. Specifically, we estimate the statistical dependence between inlier and outlier data through the Hilbert-Schmidt Independence Criterion (HSIC), and we penalize such metric during training. We also associate our approach with a novel statistical test during the inference time coupled with our principled motivation. Empirical results show that our method is effective and robust for OOD detection on various benchmarks. In comparison to SOTA models, our approach achieves significant improvement regarding FPR95, AUROC, and AUPR metrics. Code is available: \url{https://github.com/jylins/hood}.
Silver-Bullet-3D at ManiSkill 2021: Learning-from-Demonstrations and Heuristic Rule-based Methods for Object Manipulation
Jun 13, 2022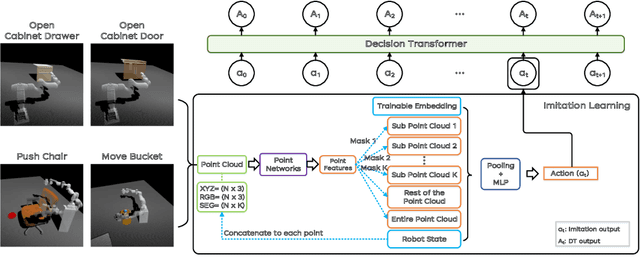



This paper presents an overview and comparative analysis of our systems designed for the following two tracks in SAPIEN ManiSkill Challenge 2021: No Interaction Track: The No Interaction track targets for learning policies from pre-collected demonstration trajectories. We investigate both imitation learning-based approach, i.e., imitating the observed behavior using classical supervised learning techniques, and offline reinforcement learning-based approaches, for this track. Moreover, the geometry and texture structures of objects and robotic arms are exploited via Transformer-based networks to facilitate imitation learning. No Restriction Track: In this track, we design a Heuristic Rule-based Method (HRM) to trigger high-quality object manipulation by decomposing the task into a series of sub-tasks. For each sub-task, the simple rule-based controlling strategies are adopted to predict actions that can be applied to robotic arms. To ease the implementations of our systems, all the source codes and pre-trained models are available at \url{https://github.com/caiqi/Silver-Bullet-3D/}.
Embed to Control Partially Observed Systems: Representation Learning with Provable Sample Efficiency
May 26, 2022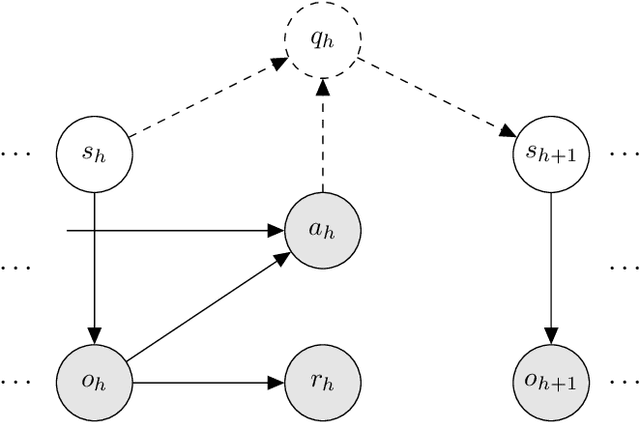
Reinforcement learning in partially observed Markov decision processes (POMDPs) faces two challenges. (i) It often takes the full history to predict the future, which induces a sample complexity that scales exponentially with the horizon. (ii) The observation and state spaces are often continuous, which induces a sample complexity that scales exponentially with the extrinsic dimension. Addressing such challenges requires learning a minimal but sufficient representation of the observation and state histories by exploiting the structure of the POMDP. To this end, we propose a reinforcement learning algorithm named Embed to Control (ETC), which learns the representation at two levels while optimizing the policy.~(i) For each step, ETC learns to represent the state with a low-dimensional feature, which factorizes the transition kernel. (ii) Across multiple steps, ETC learns to represent the full history with a low-dimensional embedding, which assembles the per-step feature. We integrate (i) and (ii) in a unified framework that allows a variety of estimators (including maximum likelihood estimators and generative adversarial networks). For a class of POMDPs with a low-rank structure in the transition kernel, ETC attains an $O(1/\epsilon^2)$ sample complexity that scales polynomially with the horizon and the intrinsic dimension (that is, the rank). Here $\epsilon$ is the optimality gap. To our best knowledge, ETC is the first sample-efficient algorithm that bridges representation learning and policy optimization in POMDPs with infinite observation and state spaces.
Sample-Efficient Reinforcement Learning for POMDPs with Linear Function Approximations
Apr 20, 2022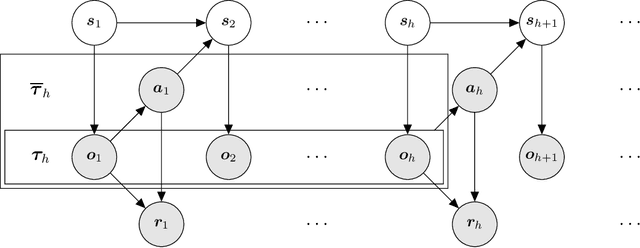
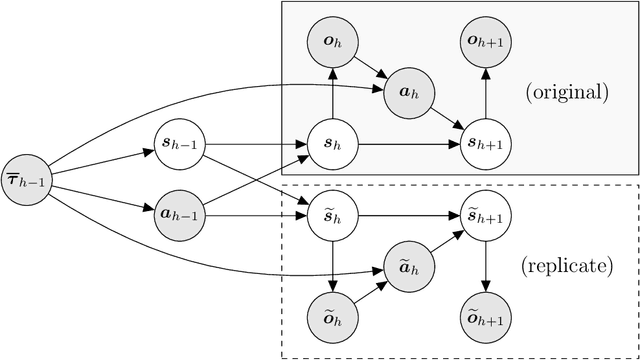
Despite the success of reinforcement learning (RL) for Markov decision processes (MDPs) with function approximation, most RL algorithms easily fail if the agent only has partial observations of the state. Such a setting is often modeled as a partially observable Markov decision process (POMDP). Existing sample-efficient algorithms for POMDPs are restricted to the tabular setting where the state and observation spaces are finite. In this paper, we make the first attempt at tackling the tension between function approximation and partial observability. In specific, we focus on a class of undercomplete POMDPs with linear function approximations, which allows the state and observation spaces to be infinite. For such POMDPs, we show that the optimal policy and value function can be characterized by a sequence of finite-memory Bellman operators. We propose an RL algorithm that constructs optimistic estimators of these operators via reproducing kernel Hilbert space (RKHS) embedding. Moreover, we theoretically prove that the proposed algorithm finds an $\varepsilon$-optimal policy with $\tilde O (1/\varepsilon^2)$ episodes of exploration. Also, this sample complexity only depends on the intrinsic dimension of the POMDP polynomially and is independent of the size of the state and observation spaces. To our best knowledge, we develop the first provably sample-efficient algorithm for POMDPs with function approximation.
A Low Rank Promoting Prior for Unsupervised Contrastive Learning
Aug 05, 2021
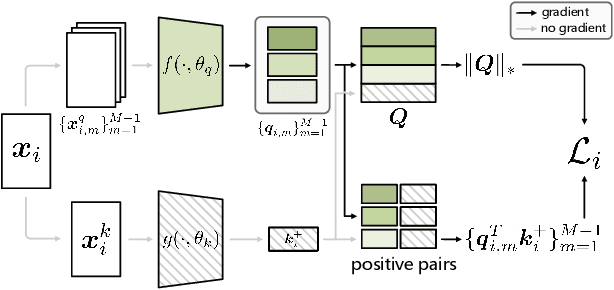

Unsupervised learning is just at a tipping point where it could really take off. Among these approaches, contrastive learning has seen tremendous progress and led to state-of-the-art performance. In this paper, we construct a novel probabilistic graphical model that effectively incorporates the low rank promoting prior into the framework of contrastive learning, referred to as LORAC. In contrast to the existing conventional self-supervised approaches that only considers independent learning, our hypothesis explicitly requires that all the samples belonging to the same instance class lie on the same subspace with small dimension. This heuristic poses particular joint learning constraints to reduce the degree of freedom of the problem during the search of the optimal network parameterization. Most importantly, we argue that the low rank prior employed here is not unique, and many different priors can be invoked in a similar probabilistic way, corresponding to different hypotheses about underlying truth behind the contrastive features. Empirical evidences show that the proposed algorithm clearly surpasses the state-of-the-art approaches on multiple benchmarks, including image classification, object detection, instance segmentation and keypoint detection.
A Pose-only Solution to Visual Reconstruction and Navigation
Mar 02, 2021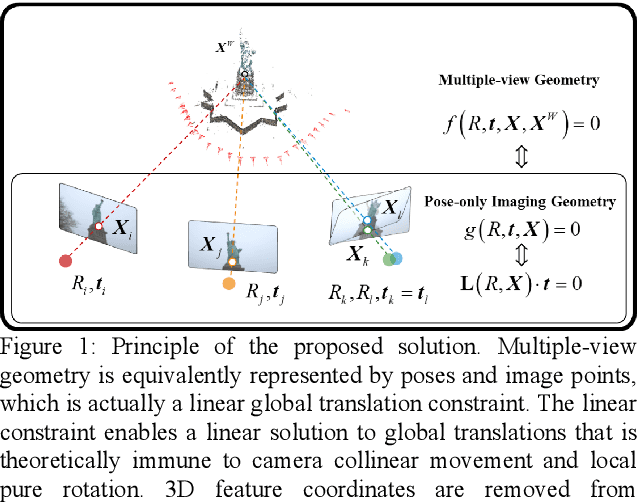
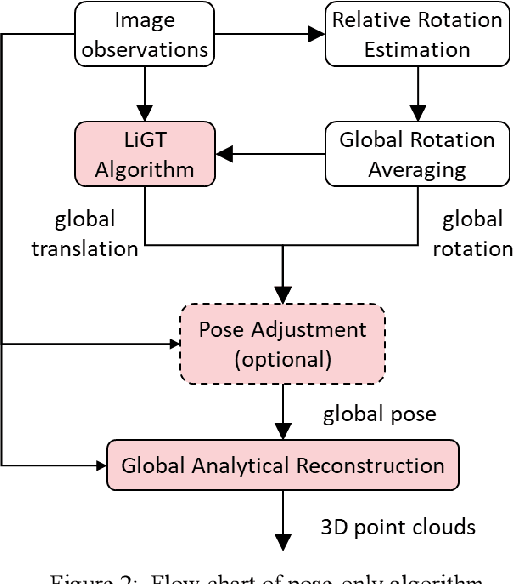
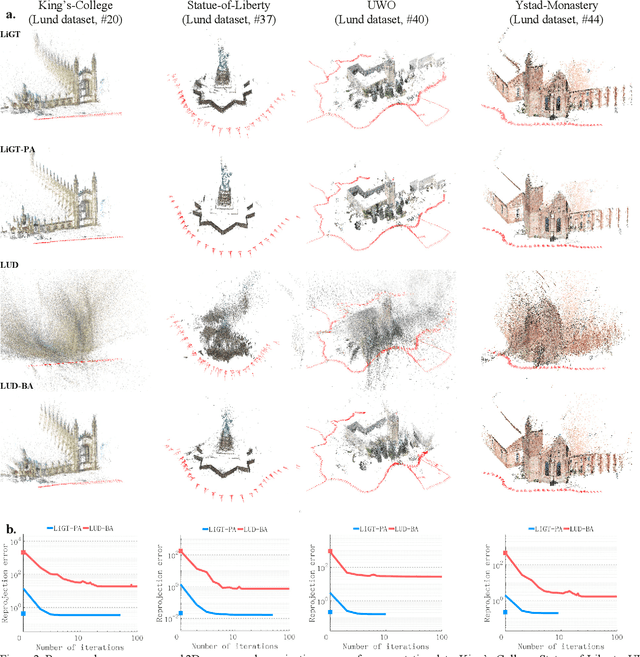
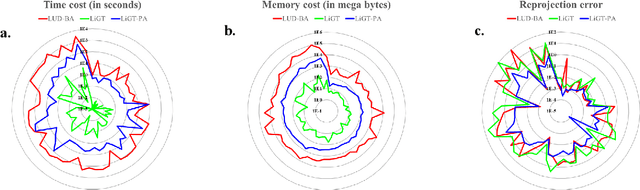
Visual navigation and three-dimensional (3D) scene reconstruction are essential for robotics to interact with the surrounding environment. Large-scale scenes and critical camera motions are great challenges facing the research community to achieve this goal. We raised a pose-only imaging geometry framework and algorithms that can help solve these challenges. The representation is a linear function of camera global translations, which allows for efficient and robust camera motion estimation. As a result, the spatial feature coordinates can be analytically reconstructed and do not require nonlinear optimization. Experiments demonstrate that the computational efficiency of recovering the scene and associated camera poses is significantly improved by 2-4 orders of magnitude. This solution might be promising to unlock real-time 3D visual computing in many forefront applications.
Segmenting Epipolar Line
Oct 11, 2020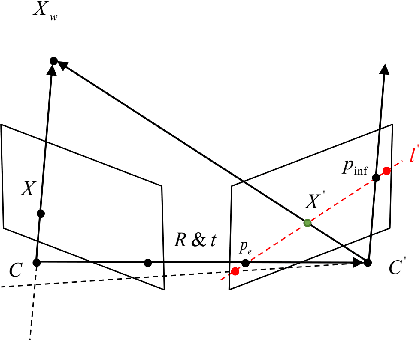


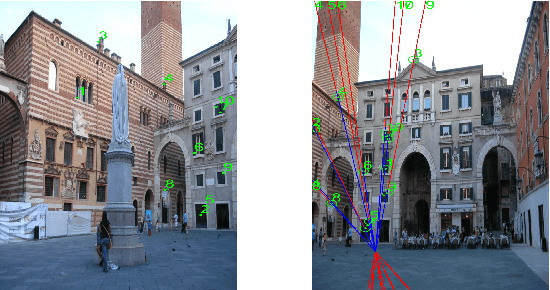
Identifying feature correspondence between two images is a fundamental procedure in three-dimensional computer vision. Usually the feature search space is confined by the epipolar line. Using the cheirality constraint, this paper finds that the feature search space can be restrained to one of two or three segments of the epipolar line that are defined by the epipole and a so-called virtual infinity point.