 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Multi-Modal Image Correspondence Learning
Dec 05, 2016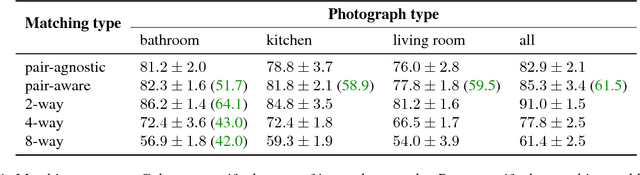
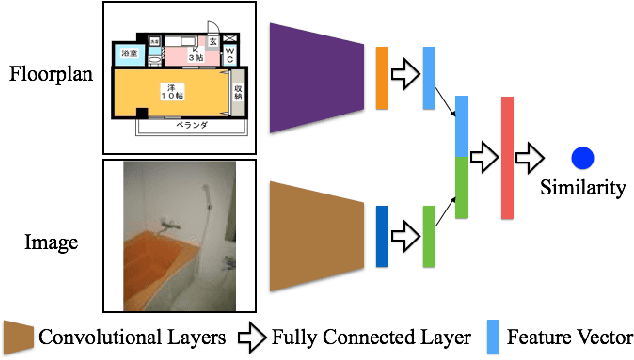
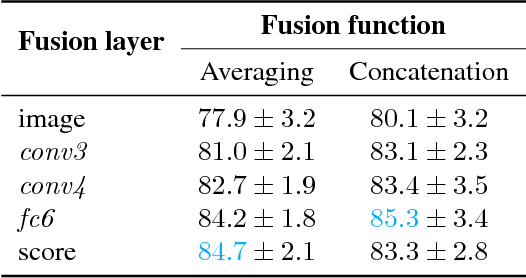
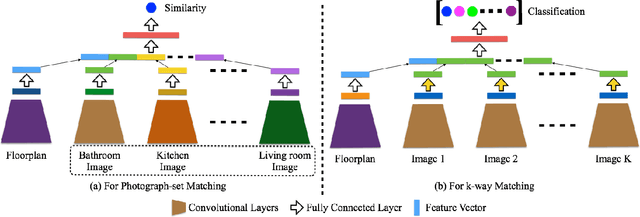
Inference of correspondences between images from different modalities is an extremely important perceptual ability that enables humans to understand and recognize cross-modal concepts. In this paper, we consider an instance of this problem that involves matching photographs of building interiors with their corresponding floorplan. This is a particularly challenging problem because a floorplan, as a stylized architectural drawing, is very different in appearance from a color photograph. Furthermore, individual photographs by themselves depict only a part of a floorplan (e.g., kitchen, bathroom, and living room). We propose the use of a number of different neural network architectures for this task, which are trained and evaluated on a novel large-scale dataset of 5 million floorplan images and 80 million associated photographs. Experimental evaluation reveals that our neural network architectures are able to identify visual cues that result in reliable matches across these two quite different modalities. In fact, the trained networks are able to even outperform human subjects in several challenging image matching problems. Our result implies that neural networks are effective at perceptual tasks that require long periods of reasoning even for humans to solve.
Learning to superoptimize programs - Workshop Version
Dec 04, 2016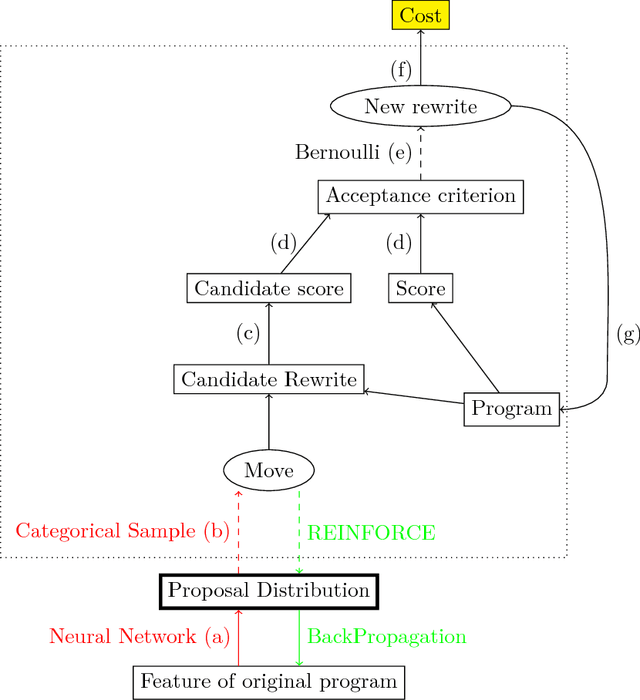
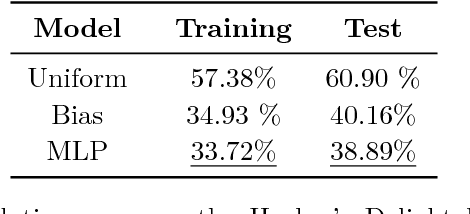
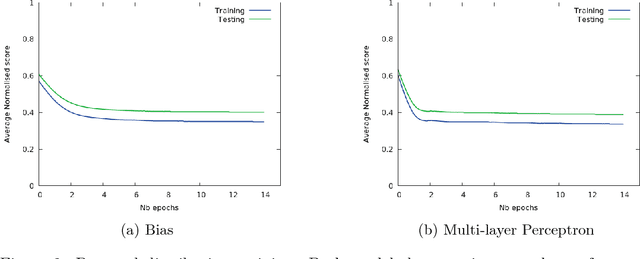
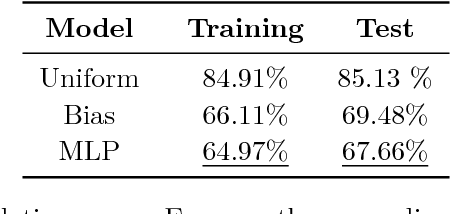
Superoptimization requires the estimation of the best program for a given computational task. In order to deal with large programs, superoptimization techniques perform a stochastic search. This involves proposing a modification of the current program, which is accepted or rejected based on the improvement achieved. The state of the art method uses uniform proposal distributions, which fails to exploit the problem structure to the fullest. To alleviate this deficiency, we learn a proposal distribution over possible modifications using Reinforcement Learning. We provide convincing results on the superoptimization of "Hacker's Delight" programs.
Summary - TerpreT: A Probabilistic Programming Language for Program Induction
Dec 02, 2016
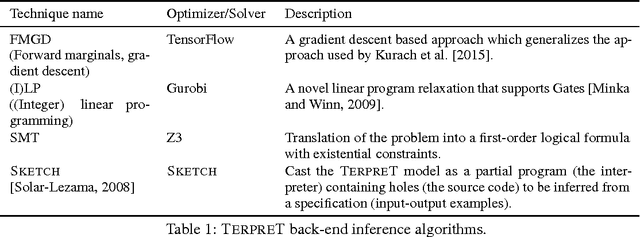
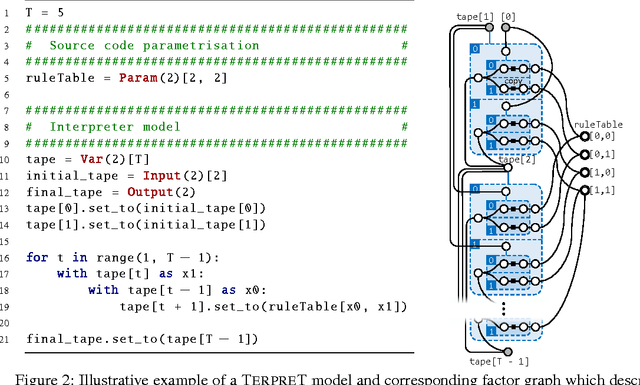
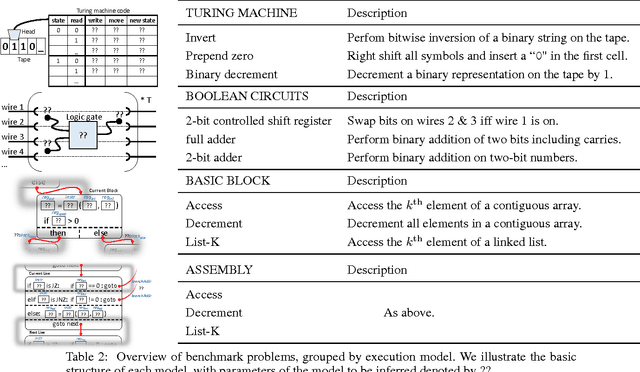
We study machine learning formulations of inductive program synthesis; that is, given input-output examples, synthesize source code that maps inputs to corresponding outputs. Our key contribution is TerpreT, a domain-specific language for expressing program synthesis problems. A TerpreT model is composed of a specification of a program representation and an interpreter that describes how programs map inputs to outputs. The inference task is to observe a set of input-output examples and infer the underlying program. From a TerpreT model we automatically perform inference using four different back-ends: gradient descent (thus each TerpreT model can be seen as defining a differentiable interpreter), linear program (LP) relaxations for graphical models, discrete satisfiability solving, and the Sketch program synthesis system. TerpreT has two main benefits. First, it enables rapid exploration of a range of domains, program representations, and interpreter models. Second, it separates the model specification from the inference algorithm, allowing proper comparisons between different approaches to inference. We illustrate the value of TerpreT by developing several interpreter models and performing an extensive empirical comparison between alternative inference algorithms on a variety of program models. To our knowledge, this is the first work to compare gradient-based search over program space to traditional search-based alternatives. Our key empirical finding is that constraint solvers dominate the gradient descent and LP-based formulations. This is a workshop summary of a longer report at arXiv:1608.04428
Inducing Interpretable Representations with Variational Autoencoders
Nov 22, 2016
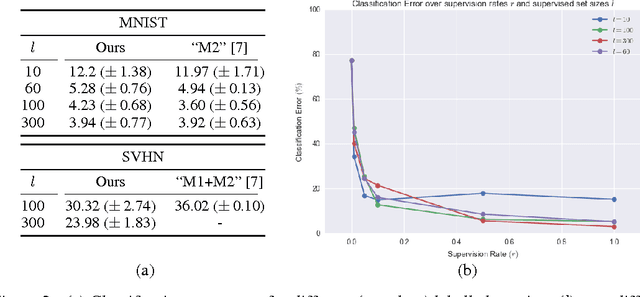

We develop a framework for incorporating structured graphical models in the \emph{encoders} of variational autoencoders (VAEs) that allows us to induce interpretable representations through approximate variational inference. This allows us to both perform reasoning (e.g. classification) under the structural constraints of a given graphical model, and use deep generative models to deal with messy, high-dimensional domains where it is often difficult to model all the variation. Learning in this framework is carried out end-to-end with a variational objective, applying to both unsupervised and semi-supervised schemes.
Batched Gaussian Process Bandit Optimization via Determinantal Point Processes
Nov 13, 2016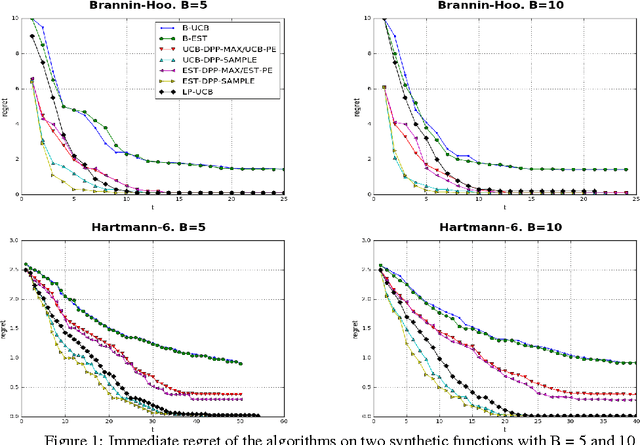
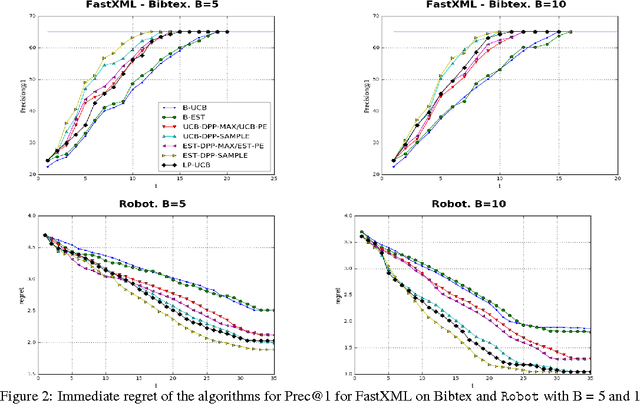
Gaussian Process bandit optimization has emerged as a powerful tool for optimizing noisy black box functions. One example in machine learning is hyper-parameter optimization where each evaluation of the target function requires training a model which may involve days or even weeks of computation. Most methods for this so-called "Bayesian optimization" only allow sequential exploration of the parameter space. However, it is often desirable to propose batches or sets of parameter values to explore simultaneously, especially when there are large parallel processing facilities at our disposal. Batch methods require modeling the interaction between the different evaluations in the batch, which can be expensive in complex scenarios. In this paper, we propose a new approach for parallelizing Bayesian optimization by modeling the diversity of a batch via Determinantal point processes (DPPs) whose kernels are learned automatically. This allows us to generalize a previous result as well as prove better regret bounds based on DPP sampling. Our experiments on a variety of synthetic and real-world robotics and hyper-parameter optimization tasks indicate that our DPP-based methods, especially those based on DPP sampling, outperform state-of-the-art methods.
Neuro-Symbolic Program Synthesis
Nov 06, 2016
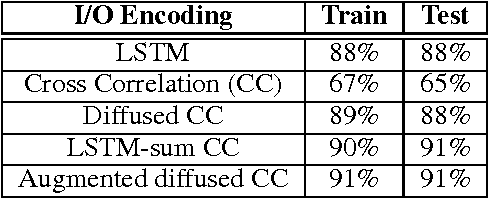
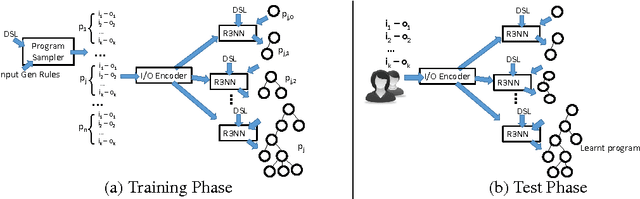
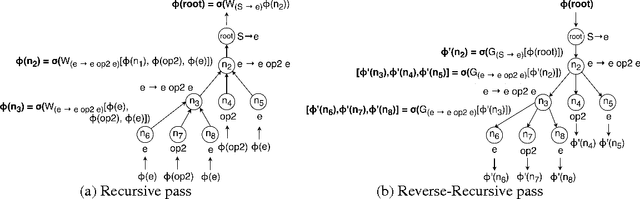
Recent years have seen the proposal of a number of neural architectures for the problem of Program Induction. Given a set of input-output examples, these architectures are able to learn mappings that generalize to new test inputs. While achieving impressive results, these approaches have a number of important limitations: (a) they are computationally expensive and hard to train, (b) a model has to be trained for each task (program) separately, and (c) it is hard to interpret or verify the correctness of the learnt mapping (as it is defined by a neural network). In this paper, we propose a novel technique, Neuro-Symbolic Program Synthesis, to overcome the above-mentioned problems. Once trained, our approach can automatically construct computer programs in a domain-specific language that are consistent with a set of input-output examples provided at test time. Our method is based on two novel neural modules. The first module, called the cross correlation I/O network, given a set of input-output examples, produces a continuous representation of the set of I/O examples. The second module, the Recursive-Reverse-Recursive Neural Network (R3NN), given the continuous representation of the examples, synthesizes a program by incrementally expanding partial programs. We demonstrate the effectiveness of our approach by applying it to the rich and complex domain of regular expression based string transformations. Experiments show that the R3NN model is not only able to construct programs from new input-output examples, but it is also able to construct new programs for tasks that it had never observed before during training.
PerforatedCNNs: Acceleration through Elimination of Redundant Convolutions
Oct 16, 2016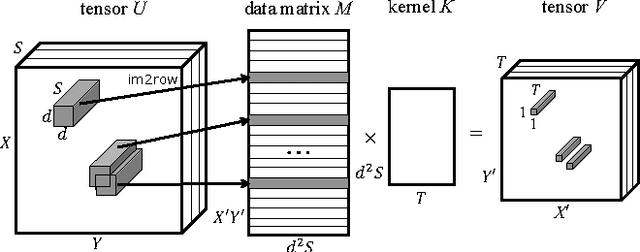

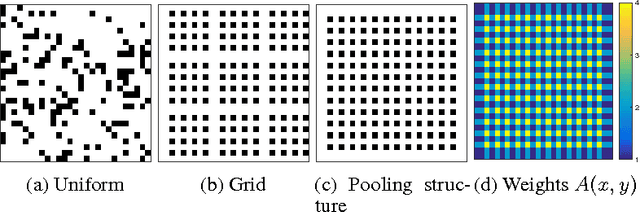

We propose a novel approach to reduce the computational cost of evaluation of convolutional neural networks, a factor that has hindered their deployment in low-power devices such as mobile phones. Inspired by the loop perforation technique from source code optimization, we speed up the bottleneck convolutional layers by skipping their evaluation in some of the spatial positions. We propose and analyze several strategies of choosing these positions. We demonstrate that perforation can accelerate modern convolutional networks such as AlexNet and VGG-16 by a factor of 2x - 4x. Additionally, we show that perforation is complementary to the recently proposed acceleration method of Zhang et al.
Deep disentangled representations for volumetric reconstruction
Oct 12, 2016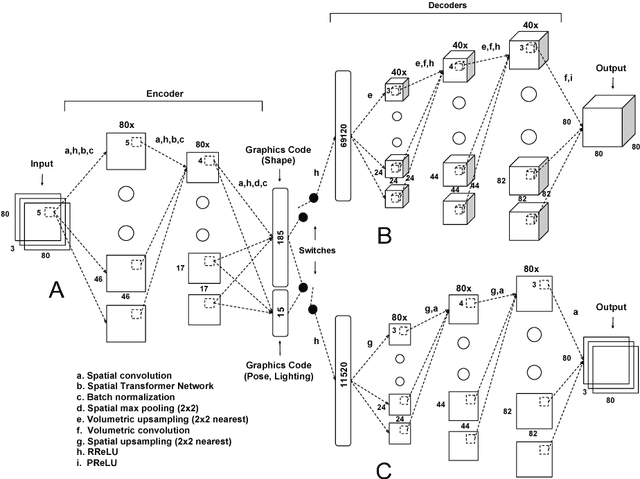
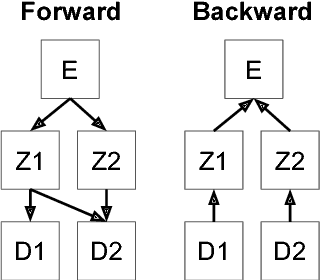

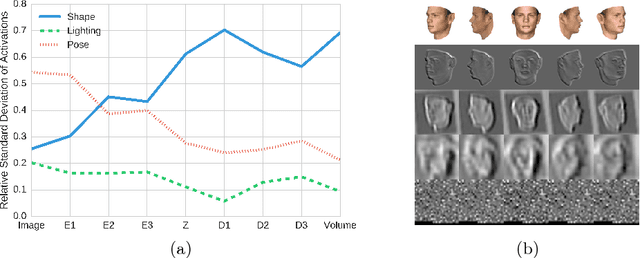
We introduce a convolutional neural network for inferring a compact disentangled graphical description of objects from 2D images that can be used for volumetric reconstruction. The network comprises an encoder and a twin-tailed decoder. The encoder generates a disentangled graphics code. The first decoder generates a volume, and the second decoder reconstructs the input image using a novel training regime that allows the graphics code to learn a separate representation of the 3D object and a description of its lighting and pose conditions. We demonstrate this method by generating volumes and disentangled graphical descriptions from images and videos of faces and chairs.
Efficient Continuous Relaxations for Dense CRF
Aug 22, 2016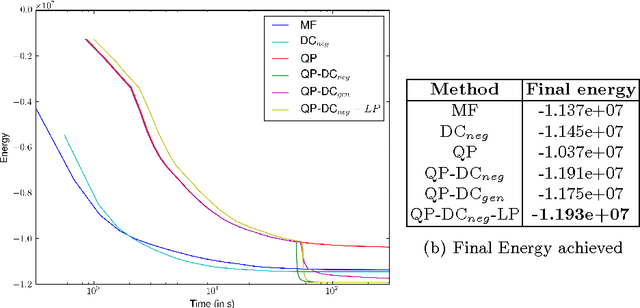
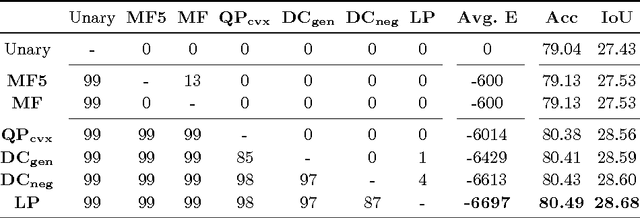


Dense conditional random fields (CRF) with Gaussian pairwise potentials have emerged as a popular framework for several computer vision applications such as stereo correspondence and semantic segmentation. By modeling long-range interactions, dense CRFs provide a more detailed labelling compared to their sparse counterparts. Variational inference in these dense models is performed using a filtering-based mean-field algorithm in order to obtain a fully-factorized distribution minimising the Kullback-Leibler divergence to the true distribution. In contrast to the continuous relaxation-based energy minimisation algorithms used for sparse CRFs, the mean-field algorithm fails to provide strong theoretical guarantees on the quality of its solutions. To address this deficiency, we show that it is possible to use the same filtering approach to speed-up the optimisation of several continuous relaxations. Specifically, we solve a convex quadratic programming (QP) relaxation using the efficient Frank-Wolfe algorithm. This also allows us to solve difference-of-convex relaxations via the iterative concave-convex procedure where each iteration requires solving a convex QP. Finally, we develop a novel divide-and-conquer method to compute the subgradients of a linear programming relaxation that provides the best theoretical bounds for energy minimisation. We demonstrate the advantage of continuous relaxations over the widely used mean-field algorithm on publicly available datasets.
TerpreT: A Probabilistic Programming Language for Program Induction
Aug 15, 2016We study machine learning formulations of inductive program synthesis; given input-output examples, we try to synthesize source code that maps inputs to corresponding outputs. Our aims are to develop new machine learning approaches based on neural networks and graphical models, and to understand the capabilities of machine learning techniques relative to traditional alternatives, such as those based on constraint solving from the programming languages community. Our key contribution is the proposal of TerpreT, a domain-specific language for expressing program synthesis problems. TerpreT is similar to a probabilistic programming language: a model is composed of a specification of a program representation (declarations of random variables) and an interpreter describing how programs map inputs to outputs (a model connecting unknowns to observations). The inference task is to observe a set of input-output examples and infer the underlying program. TerpreT has two main benefits. First, it enables rapid exploration of a range of domains, program representations, and interpreter models. Second, it separates the model specification from the inference algorithm, allowing like-to-like comparisons between different approaches to inference. From a single TerpreT specification we automatically perform inference using four different back-ends. These are based on gradient descent, linear program (LP) relaxations for graphical models, discrete satisfiability solving, and the Sketch program synthesis system. We illustrate the value of TerpreT by developing several interpreter models and performing an empirical comparison between alternative inference algorithms. Our key empirical finding is that constraint solvers dominate the gradient descent and LP-based formulations. We conclude with suggestions for the machine learning community to make progress on program synthesis.