 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Task Generalization with Multi-Task Deep Reinforcement Learning
Nov 07, 2017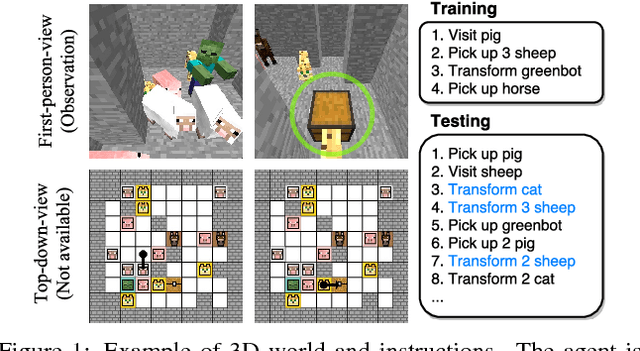
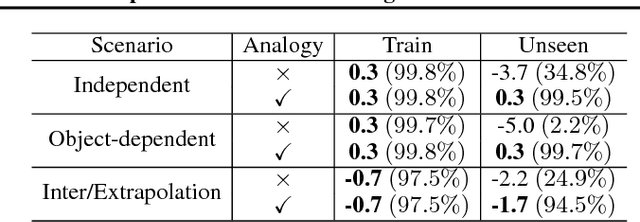
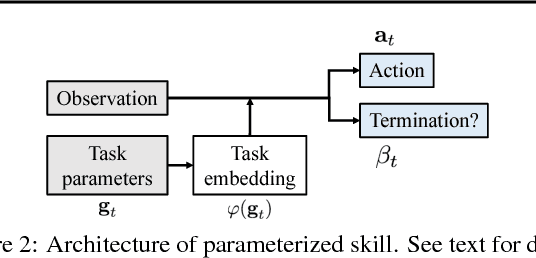
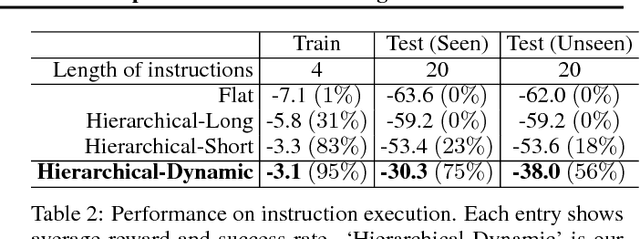
As a step towards developing zero-shot task generalization capabilities in reinforcement learning (RL), we introduce a new RL problem where the agent should learn to execute sequences of instructions after learning useful skills that solve subtasks. In this problem, we consider two types of generalizations: to previously unseen instructions and to longer sequences of instructions. For generalization over unseen instructions, we propose a new objective which encourages learning correspondences between similar subtasks by making analogies. For generalization over sequential instructions, we present a hierarchical architecture where a meta controller learns to use the acquired skills for executing the instructions. To deal with delayed reward, we propose a new neural architecture in the meta controller that learns when to update the subtask, which makes learning more efficient. Experimental results on a stochastic 3D domain show that the proposed ideas are crucial for generalization to longer instructions as well as unseen instructions.
Semantic Code Repair using Neuro-Symbolic Transformation Networks
Oct 30, 2017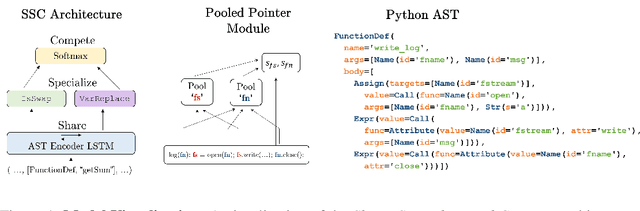

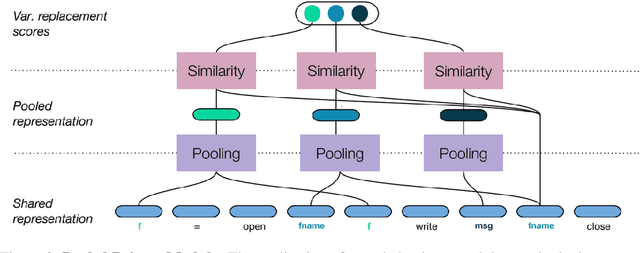
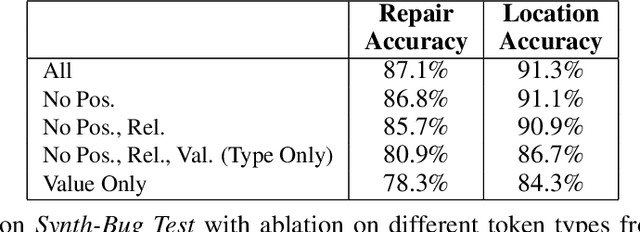
We study the problem of semantic code repair, which can be broadly defined as automatically fixing non-syntactic bugs in source code. The majority of past work in semantic code repair assumed access to unit tests against which candidate repairs could be validated. In contrast, the goal here is to develop a strong statistical model to accurately predict both bug locations and exact fixes without access to information about the intended correct behavior of the program. Achieving such a goal requires a robust contextual repair model, which we train on a large corpus of real-world source code that has been augmented with synthetically injected bugs. Our framework adopts a two-stage approach where first a large set of repair candidates are generated by rule-based processors, and then these candidates are scored by a statistical model using a novel neural network architecture which we refer to as Share, Specialize, and Compete. Specifically, the architecture (1) generates a shared encoding of the source code using an RNN over the abstract syntax tree, (2) scores each candidate repair using specialized network modules, and (3) then normalizes these scores together so they can compete against one another in comparable probability space. We evaluate our model on a real-world test set gathered from GitHub containing four common categories of bugs. Our model is able to predict the exact correct repair 41\% of the time with a single guess, compared to 13\% accuracy for an attentional sequence-to-sequence model.
Neural Program Meta-Induction
Oct 11, 2017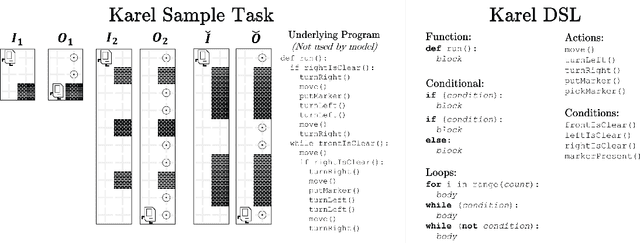

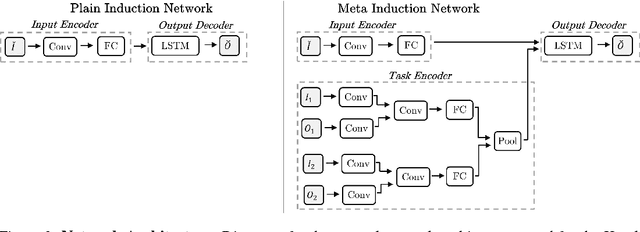

Most recently proposed methods for Neural Program Induction work under the assumption of having a large set of input/output (I/O) examples for learning any underlying input-output mapping. This paper aims to address the problem of data and computation efficiency of program induction by leveraging information from related tasks. Specifically, we propose two approaches for cross-task knowledge transfer to improve program induction in limited-data scenarios. In our first proposal, portfolio adaptation, a set of induction models is pretrained on a set of related tasks, and the best model is adapted towards the new task using transfer learning. In our second approach, meta program induction, a $k$-shot learning approach is used to make a model generalize to new tasks without additional training. To test the efficacy of our methods, we constructed a new benchmark of programs written in the Karel programming language. Using an extensive experimental evaluation on the Karel benchmark, we demonstrate that our proposals dramatically outperform the baseline induction method that does not use knowledge transfer. We also analyze the relative performance of the two approaches and study conditions in which they perform best. In particular, meta induction outperforms all existing approaches under extreme data sparsity (when a very small number of examples are available), i.e., fewer than ten. As the number of available I/O examples increase (i.e. a thousand or more), portfolio adapted program induction becomes the best approach. For intermediate data sizes, we demonstrate that the combined method of adapted meta program induction has the strongest performance.
DeepContext: Context-Encoding Neural Pathways for 3D Holistic Scene Understanding
Aug 16, 2017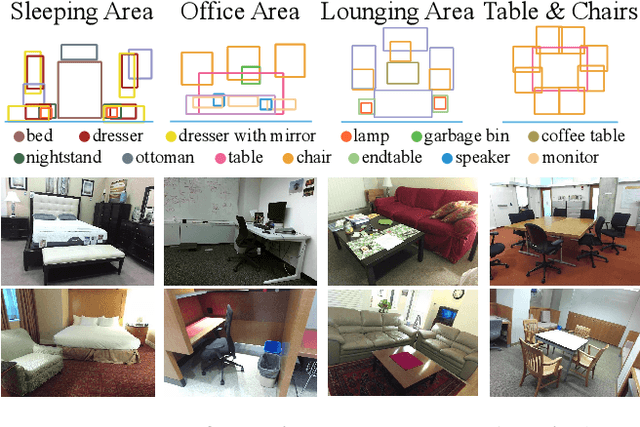
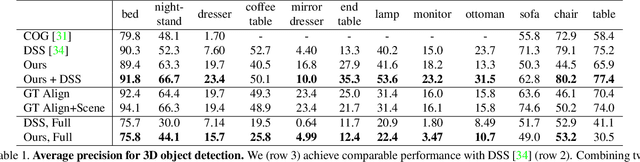

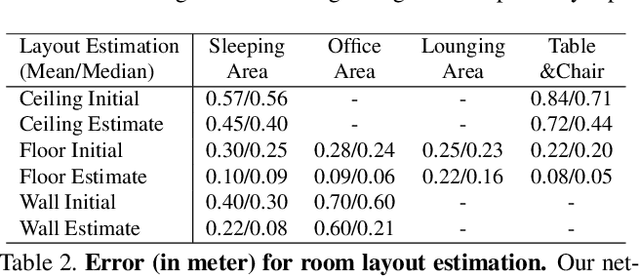
While deep neural networks have led to human-level performance on computer vision tasks, they have yet to demonstrate similar gains for holistic scene understanding. In particular, 3D context has been shown to be an extremely important cue for scene understanding - yet very little research has been done on integrating context information with deep models. This paper presents an approach to embed 3D context into the topology of a neural network trained to perform holistic scene understanding. Given a depth image depicting a 3D scene, our network aligns the observed scene with a predefined 3D scene template, and then reasons about the existence and location of each object within the scene template. In doing so, our model recognizes multiple objects in a single forward pass of a 3D convolutional neural network, capturing both global scene and local object information simultaneously. To create training data for this 3D network, we generate partly hallucinated depth images which are rendered by replacing real objects with a repository of CAD models of the same object category. Extensive experiments demonstrate the effectiveness of our algorithm compared to the state-of-the-arts. Source code and data are available at http://deepcontext.cs.princeton.edu.
Learning to superoptimize programs
Jun 28, 2017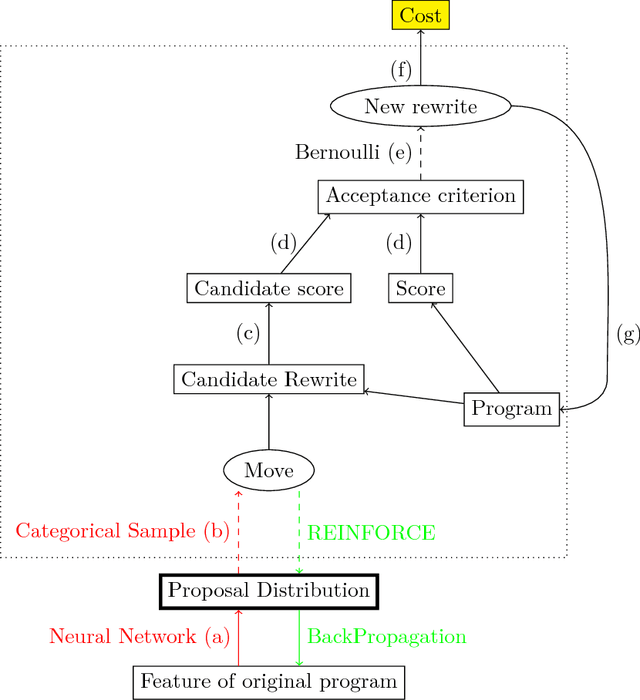
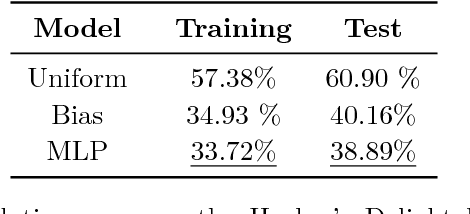
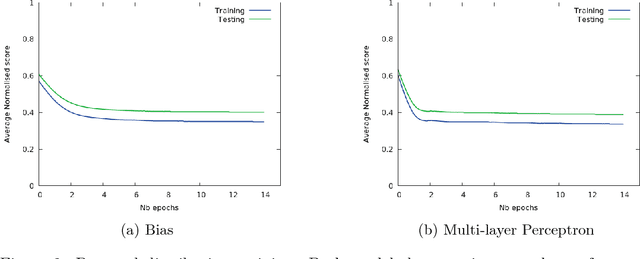
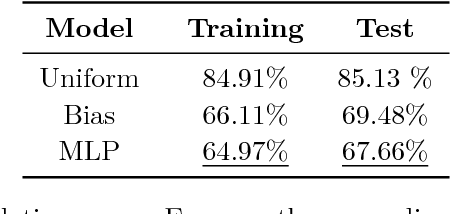
Code super-optimization is the task of transforming any given program to a more efficient version while preserving its input-output behaviour. In some sense, it is similar to the paraphrase problem from natural language processing where the intention is to change the syntax of an utterance without changing its semantics. Code-optimization has been the subject of years of research that has resulted in the development of rule-based transformation strategies that are used by compilers. More recently, however, a class of stochastic search based methods have been shown to outperform these strategies. This approach involves repeated sampling of modifications to the program from a proposal distribution, which are accepted or rejected based on whether they preserve correctness, and the improvement they achieve. These methods, however, neither learn from past behaviour nor do they try to leverage the semantics of the program under consideration. Motivated by this observation, we present a novel learning based approach for code super-optimization. Intuitively, our method works by learning the proposal distribution using unbiased estimators of the gradient of the expected improvement. Experiments on benchmarks comprising of automatically generated as well as existing ("Hacker's Delight") programs show that the proposed method is able to significantly outperform state of the art approaches for code super-optimization.
Learning Continuous Semantic Representations of Symbolic Expressions
Jun 10, 2017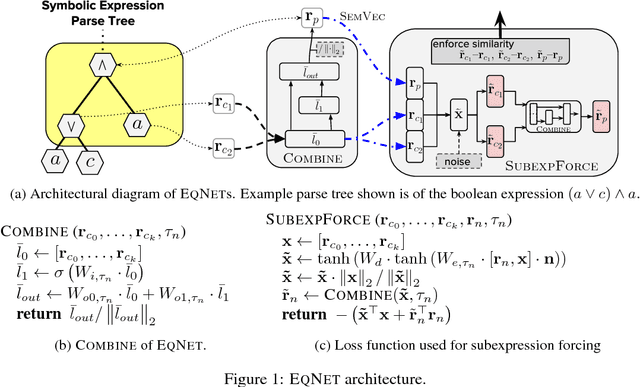
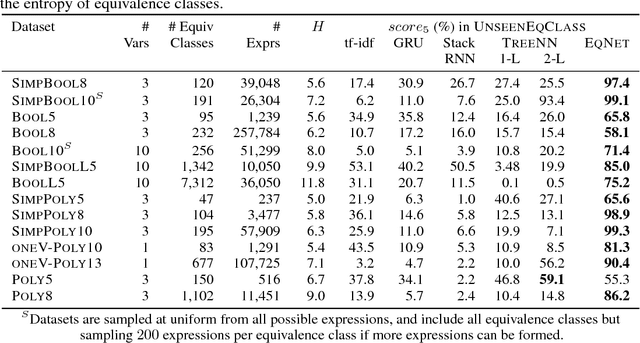
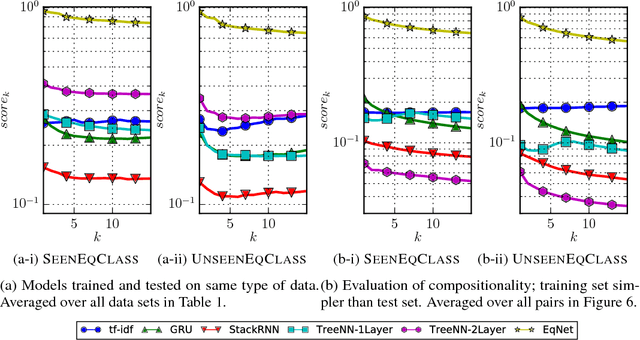
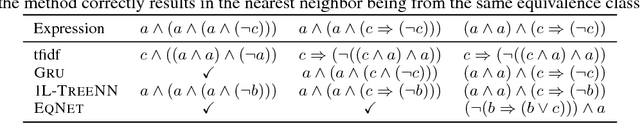
Combining abstract, symbolic reasoning with continuous neural reasoning is a grand challenge of representation learning. As a step in this direction, we propose a new architecture, called neural equivalence networks, for the problem of learning continuous semantic representations of algebraic and logical expressions. These networks are trained to represent semantic equivalence, even of expressions that are syntactically very different. The challenge is that semantic representations must be computed in a syntax-directed manner, because semantics is compositional, but at the same time, small changes in syntax can lead to very large changes in semantics, which can be difficult for continuous neural architectures. We perform an exhaustive evaluation on the task of checking equivalence on a highly diverse class of symbolic algebraic and boolean expression types, showing that our model significantly outperforms existing architectures.
Memory-augmented Attention Modelling for Videos
Apr 24, 2017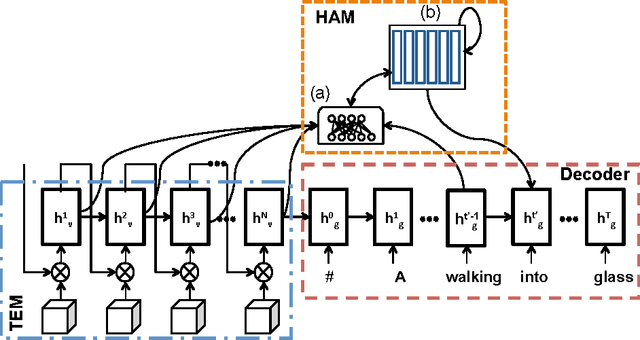
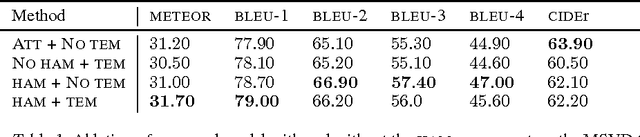

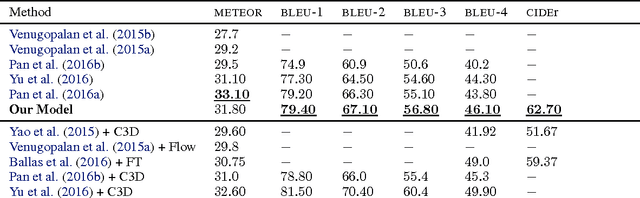
We present a method to improve video description generation by modeling higher-order interactions between video frames and described concepts. By storing past visual attention in the video associated to previously generated words, the system is able to decide what to look at and describe in light of what it has already looked at and described. This enables not only more effective local attention, but tractable consideration of the video sequence while generating each word. Evaluation on the challenging and popular MSVD and Charades datasets demonstrates that the proposed architecture outperforms previous video description approaches without requiring external temporal video features.
Deep API Programmer: Learning to Program with APIs
Apr 14, 2017


We present DAPIP, a Programming-By-Example system that learns to program with APIs to perform data transformation tasks. We design a domain-specific language (DSL) that allows for arbitrary concatenations of API outputs and constant strings. The DSL consists of three family of APIs: regular expression-based APIs, lookup APIs, and transformation APIs. We then present a novel neural synthesis algorithm to search for programs in the DSL that are consistent with a given set of examples. The search algorithm uses recently introduced neural architectures to encode input-output examples and to model the program search in the DSL. We show that synthesis algorithm outperforms baseline methods for synthesizing programs on both synthetic and real-world benchmarks.
RobustFill: Neural Program Learning under Noisy I/O
Mar 21, 2017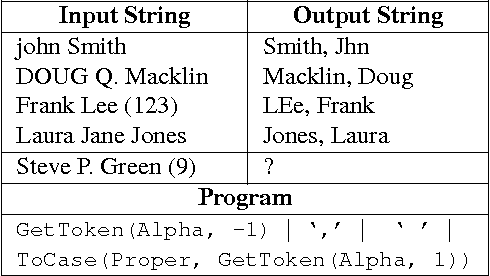

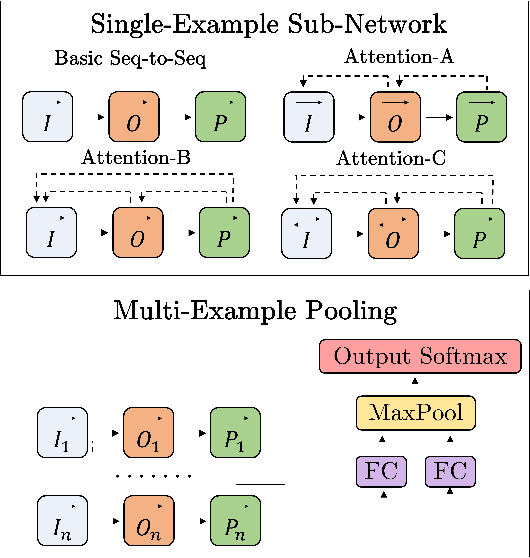
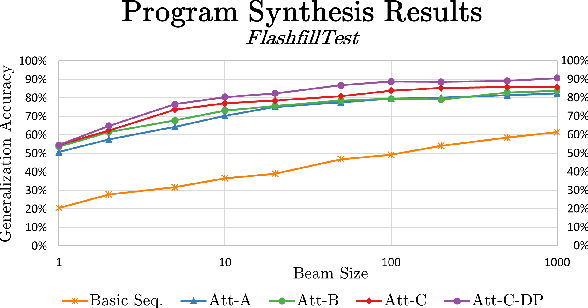
The problem of automatically generating a computer program from some specification has been studied since the early days of AI. Recently, two competing approaches for automatic program learning have received significant attention: (1) neural program synthesis, where a neural network is conditioned on input/output (I/O) examples and learns to generate a program, and (2) neural program induction, where a neural network generates new outputs directly using a latent program representation. Here, for the first time, we directly compare both approaches on a large-scale, real-world learning task. We additionally contrast to rule-based program synthesis, which uses hand-crafted semantics to guide the program generation. Our neural models use a modified attention RNN to allow encoding of variable-sized sets of I/O pairs. Our best synthesis model achieves 92% accuracy on a real-world test set, compared to the 34% accuracy of the previous best neural synthesis approach. The synthesis model also outperforms a comparable induction model on this task, but we more importantly demonstrate that the strength of each approach is highly dependent on the evaluation metric and end-user application. Finally, we show that we can train our neural models to remain very robust to the type of noise expected in real-world data (e.g., typos), while a highly-engineered rule-based system fails entirely.
Multi-way Particle Swarm Fusion
Dec 05, 2016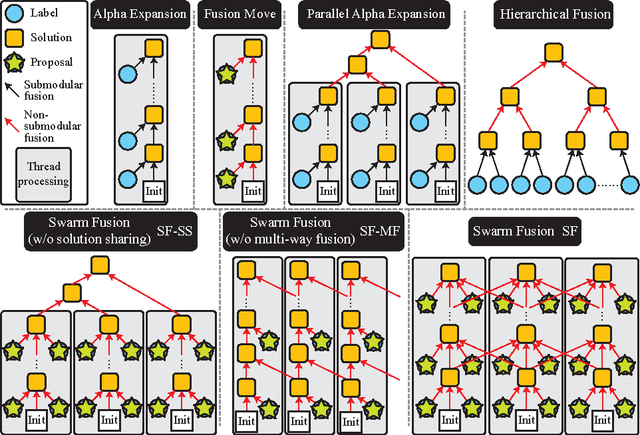
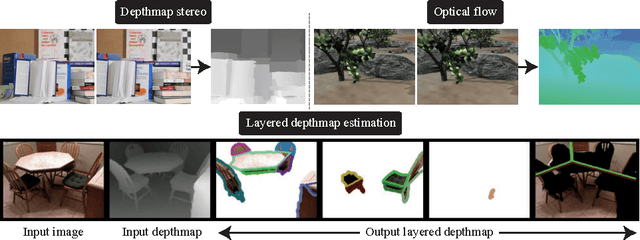
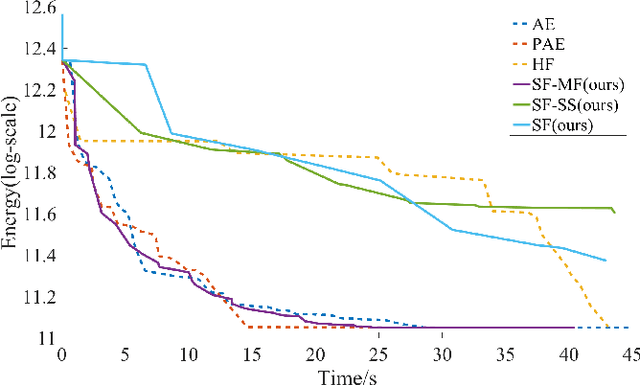
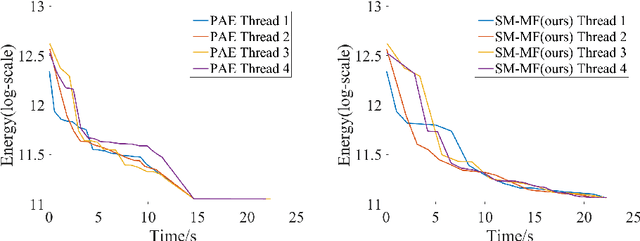
This paper proposes a novel MAP inference framework for Markov Random Field (MRF) in parallel computing environments. The inference framework, dubbed Swarm Fusion, is a natural generalization of the Fusion Move method. Every thread (in a case of multi-threading environments) maintains and updates a solution. At each iteration, a thread can generate arbitrary number of solution proposals and take arbitrary number of concurrent solutions from the other threads to perform multi-way fusion in updating its solution. The framework is general, making popular existing inference techniques such as alpha-expansion, fusion move, parallel alpha-expansion, and hierarchical fusion, its special cases. We have evaluated the effectiveness of our approach against competing methods on three problems of varying difficulties, in particular, the stereo, the optical flow, and the layered depthmap estimation problems.