 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Multi-Agent Coordination through Common Operating Picture Integration
Nov 08, 2023



In multi-agent systems, agents possess only local observations of the environment. Communication between teammates becomes crucial for enhancing coordination. Past research has primarily focused on encoding local information into embedding messages which are unintelligible to humans. We find that using these messages in agent's policy learning leads to brittle policies when tested on out-of-distribution initial states. We present an approach to multi-agent coordination, where each agent is equipped with the capability to integrate its (history of) observations, actions and messages received into a Common Operating Picture (COP) and disseminate the COP. This process takes into account the dynamic nature of the environment and the shared mission. We conducted experiments in the StarCraft2 environment to validate our approach. Our results demonstrate the efficacy of COP integration, and show that COP-based training leads to robust policies compared to state-of-the-art Multi-Agent Reinforcement Learning (MARL) methods when faced with out-of-distribution initial states.
AG-CVG: Coverage Planning with a Mobile Recharging UGV and an Energy-Constrained UAV
Oct 11, 2023



In this paper, we present an approach for coverage path planning for a team of an energy-constrained Unmanned Aerial Vehicle (UAV) and an Unmanned Ground Vehicle (UGV). Both the UAV and the UGV have predefined areas that they have to cover. The goal is to perform complete coverage by both robots while minimizing the coverage time. The UGV can also serve as a mobile recharging station. The UAV and UGV need to occasionally rendezvous for recharging. We propose a heuristic method to address this NP-Hard planning problem. Our approach involves initially determining coverage paths without factoring in energy constraints. Subsequently, we cluster segments of these paths and employ graph matching to assign UAV clusters to UGV clusters for efficient recharging management. We perform numerical analysis on real-world coverage applications and show that compared with a greedy approach our method reduces rendezvous overhead on average by 11.33\%. We demonstrate proof-of-concept with a team of a VOXL m500 drone and a Clearpath Jackal ground vehicle, providing a complete system from the offline algorithm to the field execution.
D2M2N: Decentralized Differentiable Memory-Enabled Mapping and Navigation for Multiple Robots
Oct 10, 2023



Recently, a number of learning-based models have been proposed for multi-robot navigation. However, these models lack memory and only rely on the current observations of the robot to plan their actions. They are unable to leverage past observations to plan better paths, especially in complex environments. In this work, we propose a fully differentiable and decentralized memory-enabled architecture for multi-robot navigation and mapping called D2M2N. D2M2N maintains a compact representation of the environment to remember past observations and uses Value Iteration Network for complex navigation. We conduct extensive experiments to show that D2M2N significantly outperforms the state-of-the-art model in complex mapping and navigation task.
Pre-Trained Masked Image Model for Mobile Robot Navigation
Oct 10, 20232D top-down maps are commonly used for the navigation and exploration of mobile robots through unknown areas. Typically, the robot builds the navigation maps incrementally from local observations using onboard sensors. Recent works have shown that predicting the structural patterns in the environment through learning-based approaches can greatly enhance task efficiency. While many such works build task-specific networks using limited datasets, we show that the existing foundational vision networks can accomplish the same without any fine-tuning. Specifically, we use Masked Autoencoders, pre-trained on street images, to present novel applications for field-of-view expansion, single-agent topological exploration, and multi-agent exploration for indoor mapping, across different input modalities. Our work motivates the use of foundational vision models for generalized structure prediction-driven applications, especially in the dearth of training data. For more qualitative results see https://raaslab.org/projects/MIM4Robots.
Energy-Aware Route Planning for a Battery-Constrained Robot with Multiple Charging Depots
Oct 02, 2023



This paper considers energy-aware route planning for a battery-constrained robot operating in environments with multiple recharging depots. The robot has a battery discharge time $D$, and it should visit the recharging depots at most every $D$ time units to not run out of charge. The objective is to minimize robot's travel time while ensuring it visits all task locations in the environment. We present a $O(\log D)$ approximation algorithm for this problem. We also present heuristic improvements to the approximation algorithm and assess its performance on instances from TSPLIB, comparing it to an optimal solution obtained through Integer Linear Programming (ILP). The simulation results demonstrate that, despite a more than $20$-fold reduction in runtime, the proposed algorithm provides solutions that are, on average, within $31\%$ of the ILP solution.
Decision-Oriented Intervention Cost Prediction for Multi-robot Persistent Monitoring
Oct 02, 2023



In this paper, we present a differentiable, decision-oriented learning technique for a class of vehicle routing problems. Specifically, we consider a scenario where a team of Unmanned Aerial Vehicles (UAVs) and Unmanned Ground Vehicles (UGVs) are persistently monitoring an environment. The UGVs are occasionally taken over by humans to take detours to recharge the depleted UAVs. The goal is to select routes for the UGVs so that they can efficiently monitor the environment while reducing the cost of interventions. The former is modeled as a monotone, submodular function whereas the latter is a linear function of the routes of the UGVs. We consider a scenario where the former is known but the latter depends on the context (e.g., wind and terrain conditions) that must be learned. Typically, we first learn to predict the cost function and then solve the optimization problem. However, the loss function used in prediction may be misaligned with our final goal of finding good routes. We propose a \emph{decision-oriented learning} framework that incorporates task optimization as a differentiable layer in the prediction phase. To make the task optimization (which is a non-monotone submodular function) differentiable, we propose the Differentiable Cost Scaled Greedy algorithm. We demonstrate the efficacy of the proposed framework through numerical simulations. The results show that the proposed framework can result in better performance than the traditional approach.
LANCAR: Leveraging Language for Context-Aware Robot Locomotion in Unstructured Environments
Sep 30, 2023



Robotic locomotion is a challenging task, especially in unstructured terrains. In practice, the optimal locomotion policy can be context-dependent by using the contextual information of encountered terrains in decision-making. Humans can interpret the environmental context for robots, but the ambiguity of human language makes it challenging to use in robot locomotion directly. In this paper, we propose a novel approach, LANCAR, that introduces a context translator that works with reinforcement learning (RL) agents for context-aware locomotion. Our formulation allows a robot to interpret the contextual information from environments generated by human observers or Vision-Language Models (VLM) with Large Language Models (LLM) and use this information to generate contextual embeddings. We incorporate the contextual embeddings with the robot's internal environmental observations as the input to the RL agent's decision neural network. We evaluate LANCAR with contextual information in varying ambiguity levels and compare its performance using several alternative approaches. Our experimental results demonstrate that our approach exhibits good generalizability and adaptability across diverse terrains, by achieving at least 10% of performance improvement in episodic reward over baselines. The experiment video can be found at the following link: https://raaslab.org/projects/LLM_Context_Estimation/.
UIVNAV: Underwater Information-driven Vision-based Navigation via Imitation Learning
Sep 15, 2023Autonomous navigation in the underwater environment is challenging due to limited visibility, dynamic changes, and the lack of a cost-efficient accurate localization system. We introduce UIVNav, a novel end-to-end underwater navigation solution designed to drive robots over Objects of Interest (OOI) while avoiding obstacles, without relying on localization. UIVNav uses imitation learning and is inspired by the navigation strategies used by human divers who do not rely on localization. UIVNav consists of the following phases: (1) generating an intermediate representation (IR), and (2) training the navigation policy based on human-labeled IR. By training the navigation policy on IR instead of raw data, the second phase is domain-invariant -- the navigation policy does not need to be retrained if the domain or the OOI changes. We show this by deploying the same navigation policy for surveying two different OOIs, oyster and rock reefs, in two different domains, simulation, and a real pool. We compared our method with complete coverage and random walk methods which showed that our method is more efficient in gathering information for OOIs while also avoiding obstacles. The results show that UIVNav chooses to visit the areas with larger area sizes of oysters or rocks with no prior information about the environment or localization. Moreover, a robot using UIVNav compared to complete coverage method surveys on average 36% more oysters when traveling the same distances. We also demonstrate the feasibility of real-time deployment of UIVNavin pool experiments with BlueROV underwater robot for surveying a bed of oyster shells.
Efficiently Identifying Hotspots in a Spatially Varying Field with Multiple Robots
Sep 14, 2023In this paper, we present algorithms to identify environmental hotspots using mobile sensors. We examine two approaches: one involving a single robot and another using multiple robots coordinated through a decentralized robot system. We introduce an adaptive algorithm that does not require precise knowledge of Gaussian Processes (GPs) hyperparameters, making the modeling process more flexible. The robots operate for a pre-defined time in the environment. The multi-robot system uses Voronoi partitioning to divide tasks and a Monte Carlo Tree Search for optimal path planning. Our tests on synthetic and a real-world dataset of Chlorophyll density from a Pacific Ocean sub-region suggest that accurate estimation of GP hyperparameters may not be essential for hotspot detection, potentially simplifying environmental monitoring tasks.
Decision-Theoretic Approaches for Robotic Environmental Monitoring -- A Survey
Aug 04, 2023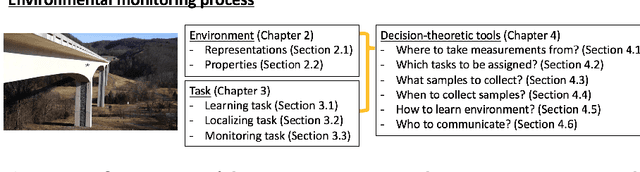



Robotics has dramatically increased our ability to gather data about our environments. This is an opportune time for the robotics and algorithms community to come together to contribute novel solutions to pressing environmental monitoring problems. In order to do so, it is useful to consider a taxonomy of problems and methods in this realm. We present the first comprehensive summary of decision theoretic approaches that are enabling efficient sampling of various kinds of environmental processes. Representations for different kinds of environments are explored, followed by a discussion of tasks of interest such as learning, localization, or monitoring. Finally, various algorithms to carry out these tasks are presented, along with a few illustrative prior results from the community.