 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained control over Music Generation with Activation Steering
Jun 11, 2025We present a method for fine-grained control over music generation through inference-time interventions on an autoregressive generative music transformer called MusicGen. Our approach enables timbre transfer, style transfer, and genre fusion by steering the residual stream using weights of linear probes trained on it, or by steering the attention layer activations in a similar manner. We observe that modelling this as a regression task provides improved performance, hypothesizing that the mean-squared-error better preserve meaningful directional information in the activation space. Combined with the global conditioning offered by text prompts in MusicGen, our method provides both global and local control over music generation. Audio samples illustrating our method are available at our demo page.
EgoMimic: Scaling Imitation Learning via Egocentric Video
Oct 31, 2024



The scale and diversity of demonstration data required for imitation learning is a significant challenge. We present EgoMimic, a full-stack framework which scales manipulation via human embodiment data, specifically egocentric human videos paired with 3D hand tracking. EgoMimic achieves this through: (1) a system to capture human embodiment data using the ergonomic Project Aria glasses, (2) a low-cost bimanual manipulator that minimizes the kinematic gap to human data, (3) cross-domain data alignment techniques, and (4) an imitation learning architecture that co-trains on human and robot data. Compared to prior works that only extract high-level intent from human videos, our approach treats human and robot data equally as embodied demonstration data and learns a unified policy from both data sources. EgoMimic achieves significant improvement on a diverse set of long-horizon, single-arm and bimanual manipulation tasks over state-of-the-art imitation learning methods and enables generalization to entirely new scenes. Finally, we show a favorable scaling trend for EgoMimic, where adding 1 hour of additional hand data is significantly more valuable than 1 hour of additional robot data. Videos and additional information can be found at https://egomimic.github.io/
Neural Visibility Field for Uncertainty-Driven Active Mapping
Jun 11, 2024This paper presents Neural Visibility Field (NVF), a novel uncertainty quantification method for Neural Radiance Fields (NeRF) applied to active mapping. Our key insight is that regions not visible in the training views lead to inherently unreliable color predictions by NeRF at this region, resulting in increased uncertainty in the synthesized views. To address this, we propose to use Bayesian Networks to composite position-based field uncertainty into ray-based uncertainty in camera observations. Consequently, NVF naturally assigns higher uncertainty to unobserved regions, aiding robots to select the most informative next viewpoints. Extensive evaluations show that NVF excels not only in uncertainty quantification but also in scene reconstruction for active mapping, outperforming existing methods.
Proactive Human-Robot Interaction using Visuo-Lingual Transformers
Oct 04, 2023Humans possess the innate ability to extract latent visuo-lingual cues to infer context through human interaction. During collaboration, this enables proactive prediction of the underlying intention of a series of tasks. In contrast, robotic agents collaborating with humans naively follow elementary instructions to complete tasks or use specific hand-crafted triggers to initiate proactive collaboration when working towards the completion of a goal. Endowing such robots with the ability to reason about the end goal and proactively suggest intermediate tasks will engender a much more intuitive method for human-robot collaboration. To this end, we propose a learning-based method that uses visual cues from the scene, lingual commands from a user and knowledge of prior object-object interaction to identify and proactively predict the underlying goal the user intends to achieve. Specifically, we propose ViLing-MMT, a vision-language multimodal transformer-based architecture that captures inter and intra-modal dependencies to provide accurate scene descriptions and proactively suggest tasks where applicable. We evaluate our proposed model in simulation and real-world scenarios.
Sparse Image based Navigation Architecture to Mitigate the need of precise Localization in Mobile Robots
Mar 29, 2022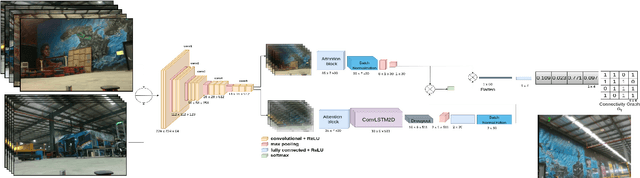
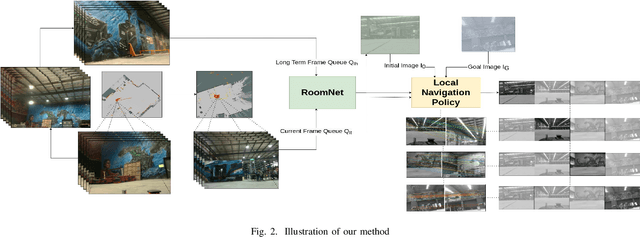


Traditional simultaneous localization and mapping (SLAM) methods focus on improvement in the robot's localization under environment and sensor uncertainty. This paper, however, focuses on mitigating the need for exact localization of a mobile robot to pursue autonomous navigation using a sparse set of images. The proposed method consists of a model architecture - RoomNet, for unsupervised learning resulting in a coarse identification of the environment and a separate local navigation policy for local identification and navigation. The former learns and predicts the scene based on the short term image sequences seen by the robot along with the transition image scenarios using long term image sequences. The latter uses sparse image matching to characterise the similarity of frames achieved vis-a-vis the frames viewed by the robot during the mapping and training stage. A sparse graph of the image sequence is created which is then used to carry out robust navigation purely on the basis of visual goals. The proposed approach is evaluated on two robots in a test environment and demonstrates the ability to navigate in dynamic environments where landmarks are obscured and classical localization methods fail.
A Generalized Kalman Filter Augmented Deep-Learning based Approach for Autonomous Landing in MAVs
Sep 30, 2021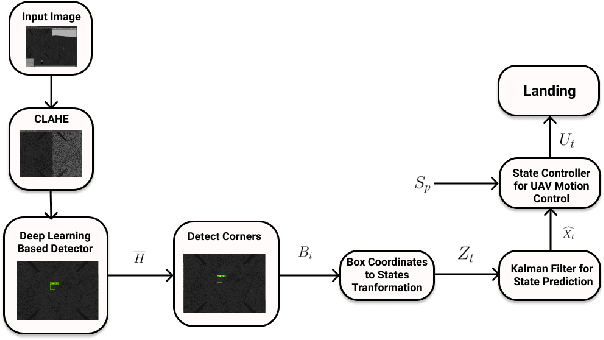
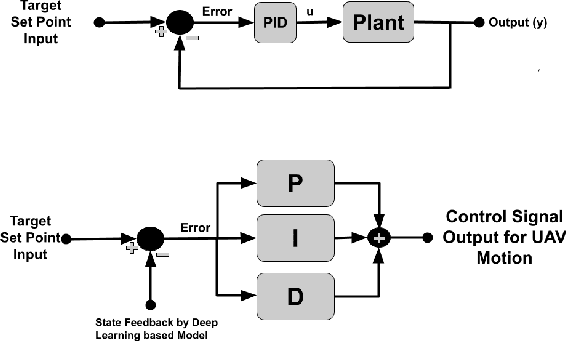

Autonomous landing systems for Micro Aerial Vehicles (MAV) have been proposed using various combinations of GPS-based, vision, and fiducial tag-based schemes. Landing is a critical activity that a MAV performs and poor resolution of GPS, degraded camera images, fiducial tags not meeting required specifications and environmental factors pose challenges. An ideal solution to MAV landing should account for these challenges and for operational challenges which could cause unplanned movements and landings. Most approaches do not attempt to solve this general problem but look at restricted sub-problems with at least one well-defined parameter. In this work, we propose a generalized end-to-end landing site detection system using a two-stage training mechanism, which makes no pre-assumption about the landing site. Experimental results show that we achieve comparable accuracy and outperform existing methods for the time required for landing.
Resource-aware Online Parameter Adaptation for Computationally-constrained Visual-Inertial Navigation Systems
Jun 01, 2021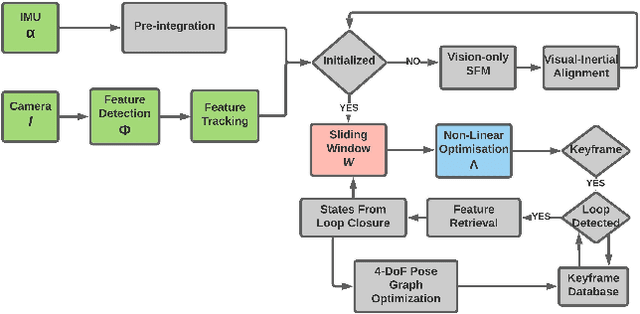
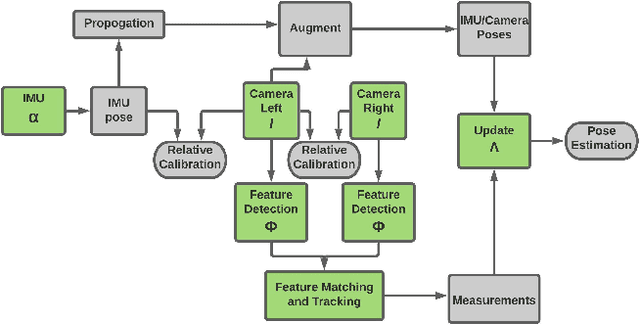
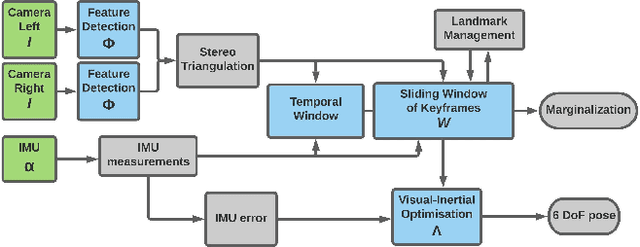
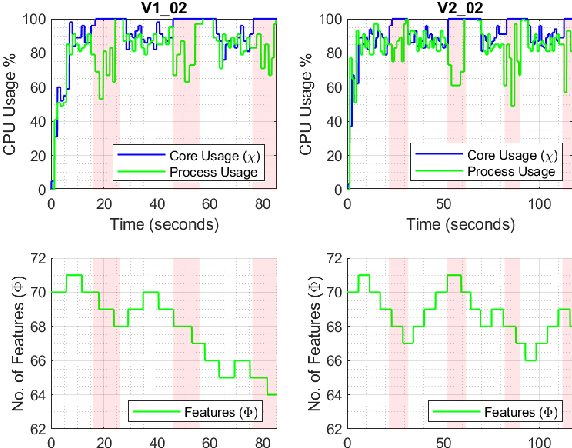
In this paper, a computational resources-aware parameter adaptation method for visual-inertial navigation systems is proposed with the goal of enabling the improved deployment of such algorithms on computationally constrained systems. Such a capacity can prove critical when employed on ultra-lightweight systems or alongside mission critical computationally expensive processes. To achieve this objective, the algorithm proposes selected changes in the vision front-end and optimization back-end of visual-inertial odometry algorithms, both prior to execution and in real-time based on an online profiling of available resources. The method also utilizes information from the motion dynamics experienced by the system to manipulate parameters online. The general policy is demonstrated on three established algorithms, namely S-MSCKF, VINS-Mono and OKVIS and has been verified experimentally on the EuRoC dataset. The proposed approach achieved comparable performance at a fraction of the original computational cost.