 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUAV-VLN: End-to-End Vision Language guided Navigation for UAVs
Apr 30, 2025A core challenge in AI-guided autonomy is enabling agents to navigate realistically and effectively in previously unseen environments based on natural language commands. We propose UAV-VLN, a novel end-to-end Vision-Language Navigation (VLN) framework for Unmanned Aerial Vehicles (UAVs) that seamlessly integrates Large Language Models (LLMs) with visual perception to facilitate human-interactive navigation. Our system interprets free-form natural language instructions, grounds them into visual observations, and plans feasible aerial trajectories in diverse environments. UAV-VLN leverages the common-sense reasoning capabilities of LLMs to parse high-level semantic goals, while a vision model detects and localizes semantically relevant objects in the environment. By fusing these modalities, the UAV can reason about spatial relationships, disambiguate references in human instructions, and plan context-aware behaviors with minimal task-specific supervision. To ensure robust and interpretable decision-making, the framework includes a cross-modal grounding mechanism that aligns linguistic intent with visual context. We evaluate UAV-VLN across diverse indoor and outdoor navigation scenarios, demonstrating its ability to generalize to novel instructions and environments with minimal task-specific training. Our results show significant improvements in instruction-following accuracy and trajectory efficiency, highlighting the potential of LLM-driven vision-language interfaces for safe, intuitive, and generalizable UAV autonomy.
A Generalized Kalman Filter Augmented Deep-Learning based Approach for Autonomous Landing in MAVs
Sep 30, 2021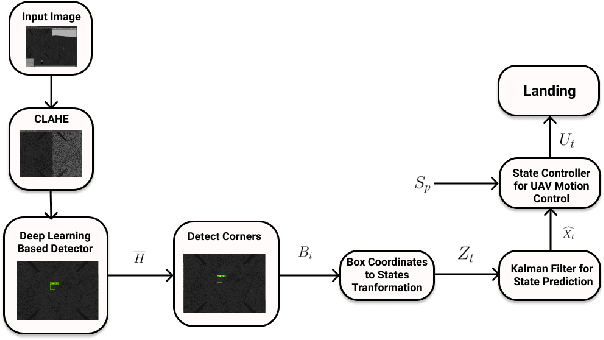
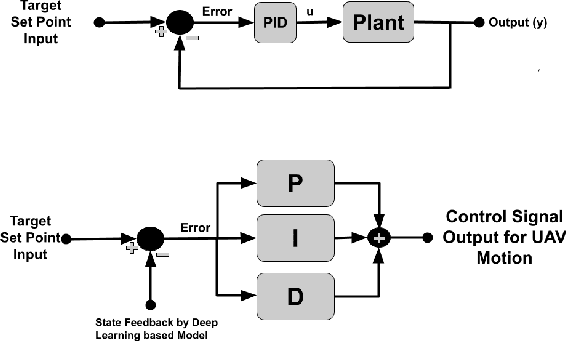

Autonomous landing systems for Micro Aerial Vehicles (MAV) have been proposed using various combinations of GPS-based, vision, and fiducial tag-based schemes. Landing is a critical activity that a MAV performs and poor resolution of GPS, degraded camera images, fiducial tags not meeting required specifications and environmental factors pose challenges. An ideal solution to MAV landing should account for these challenges and for operational challenges which could cause unplanned movements and landings. Most approaches do not attempt to solve this general problem but look at restricted sub-problems with at least one well-defined parameter. In this work, we propose a generalized end-to-end landing site detection system using a two-stage training mechanism, which makes no pre-assumption about the landing site. Experimental results show that we achieve comparable accuracy and outperform existing methods for the time required for landing.