 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTreatment Learning Transformer for Noisy Image Classification
Mar 29, 2022
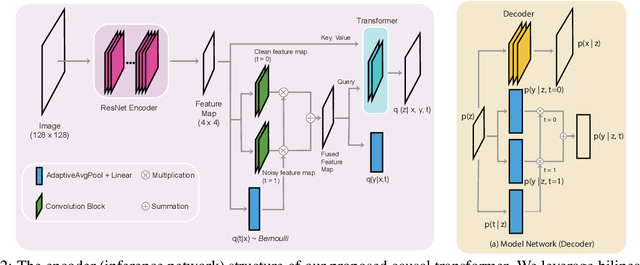


Current top-notch deep learning (DL) based vision models are primarily based on exploring and exploiting the inherent correlations between training data samples and their associated labels. However, a known practical challenge is their degraded performance against "noisy" data, induced by different circumstances such as spurious correlations, irrelevant contexts, domain shift, and adversarial attacks. In this work, we incorporate this binary information of "existence of noise" as treatment into image classification tasks to improve prediction accuracy by jointly estimating their treatment effects. Motivated from causal variational inference, we propose a transformer-based architecture, Treatment Learning Transformer (TLT), that uses a latent generative model to estimate robust feature representations from current observational input for noise image classification. Depending on the estimated noise level (modeled as a binary treatment factor), TLT assigns the corresponding inference network trained by the designed causal loss for prediction. We also create new noisy image datasets incorporating a wide range of noise factors (e.g., object masking, style transfer, and adversarial perturbation) for performance benchmarking. The superior performance of TLT in noisy image classification is further validated by several refutation evaluation metrics. As a by-product, TLT also improves visual salience methods for perceiving noisy images.
Exploiting Low-Rank Tensor-Train Deep Neural Networks Based on Riemannian Gradient Descent With Illustrations of Speech Processing
Mar 11, 2022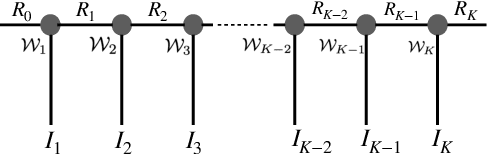
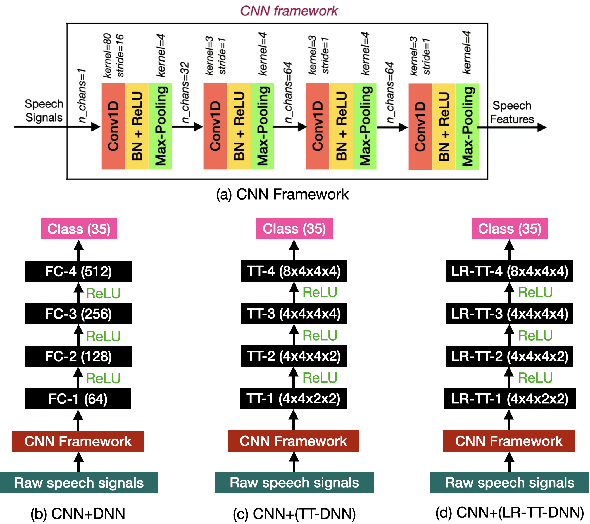
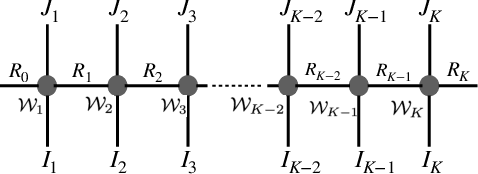
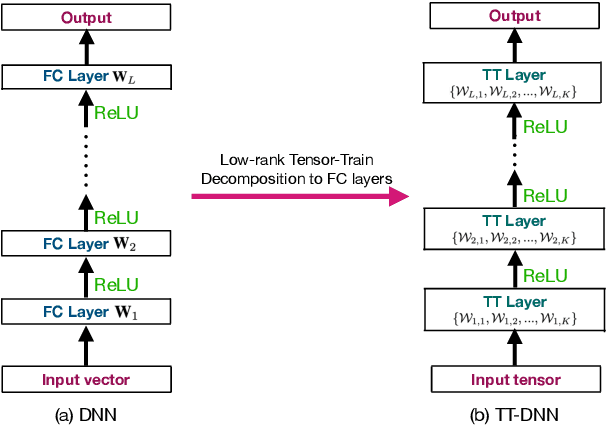
This work focuses on designing low complexity hybrid tensor networks by considering trade-offs between the model complexity and practical performance. Firstly, we exploit a low-rank tensor-train deep neural network (TT-DNN) to build an end-to-end deep learning pipeline, namely LR-TT-DNN. Secondly, a hybrid model combining LR-TT-DNN with a convolutional neural network (CNN), which is denoted as CNN+(LR-TT-DNN), is set up to boost the performance. Instead of randomly assigning large TT-ranks for TT-DNN, we leverage Riemannian gradient descent to determine a TT-DNN associated with small TT-ranks. Furthermore, CNN+(LR-TT-DNN) consists of convolutional layers at the bottom for feature extraction and several TT layers at the top to solve regression and classification problems. We separately assess the LR-TT-DNN and CNN+(LR-TT-DNN) models on speech enhancement and spoken command recognition tasks. Our empirical evidence demonstrates that the LR-TT-DNN and CNN+(LR-TT-DNN) models with fewer model parameters can outperform the TT-DNN and CNN+(TT-DNN) counterparts.
Towards Creativity Characterization of Generative Models via Group-based Subset Scanning
Mar 03, 2022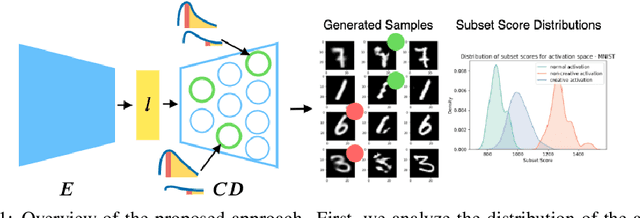
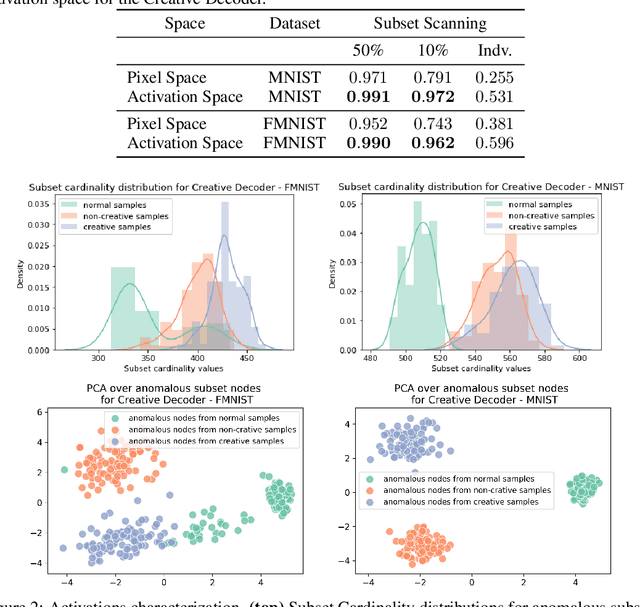
Deep generative models, such as Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs), have been employed widely in computational creativity research. However, such models discourage out-of-distribution generation to avoid spurious sample generation, thereby limiting their creativity. Thus, incorporating research on human creativity into generative deep learning techniques presents an opportunity to make their outputs more compelling and human-like. As we see the emergence of generative models directed toward creativity research, a need for machine learning-based surrogate metrics to characterize creative output from these models is imperative. We propose group-based subset scanning to identify, quantify, and characterize creative processes by detecting a subset of anomalous node-activations in the hidden layers of the generative models. Our experiments on the standard image benchmarks, and their "creatively generated" variants, reveal that the proposed subset scores distribution is more useful for detecting creative processes in the activation space rather than the pixel space. Further, we found that creative samples generate larger subsets of anomalies than normal or non-creative samples across datasets. The node activations highlighted during the creative decoding process are different from those responsible for the normal sample generation. Lastly, we assess if the images from the subsets selected by our method were also found creative by human evaluators, presenting a link between creativity perception in humans and node activations within deep neural nets.
Model Reprogramming: Resource-Efficient Cross-Domain Machine Learning
Feb 22, 2022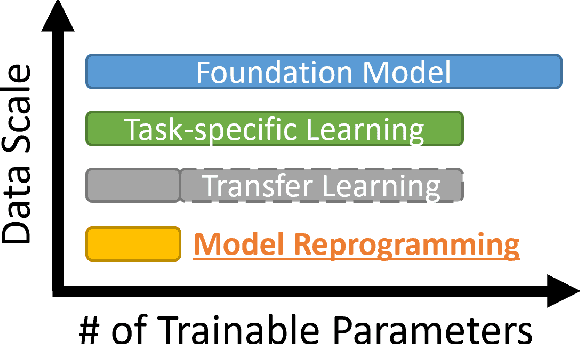

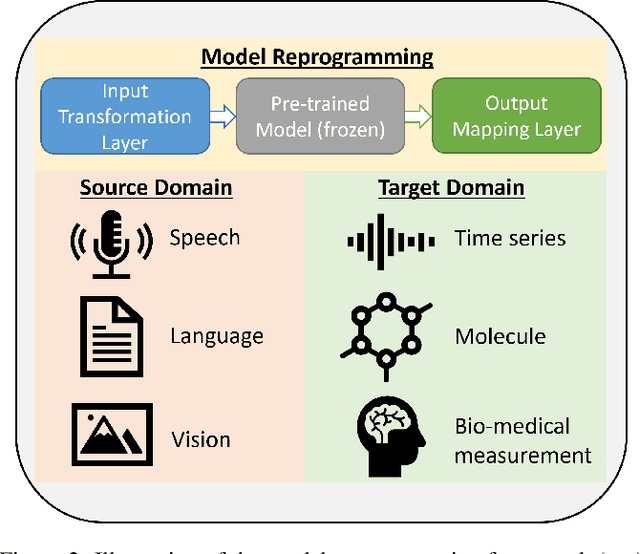

In data-rich domains such as vision, language, and speech, deep learning prevails to deliver high-performance task-specific models and can even learn general task-agnostic representations for efficient finetuning to downstream tasks. However, deep learning in resource-limited domains still faces the following challenges including (i) limited data, (ii) constrained model development cost, and (iii) lack of adequate pre-trained models for effective finetuning. This paper introduces a new technique called model reprogramming to bridge this gap. Model reprogramming enables resource-efficient cross-domain machine learning by repurposing and reusing a well-developed pre-trained model from a source domain to solve tasks in a target domain without model finetuning, where the source and target domains can be vastly different. In many applications, model reprogramming outperforms transfer learning and training from scratch. This paper elucidates the methodology of model reprogramming, summarizes existing use cases, provides a theoretical explanation on the success of model reprogramming, and concludes with a discussion on open-ended research questions and opportunities. A list of model reprogramming studies is actively maintained and updated at https://github.com/IBM/model-reprogramming.
When BERT Meets Quantum Temporal Convolution Learning for Text Classification in Heterogeneous Computing
Feb 17, 2022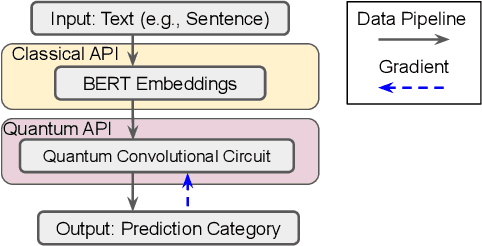
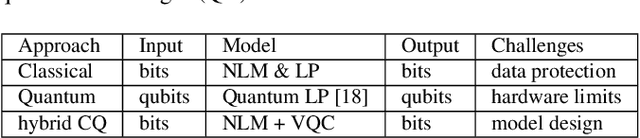
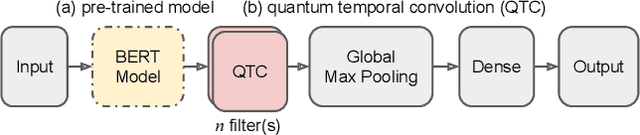

The rapid development of quantum computing has demonstrated many unique characteristics of quantum advantages, such as richer feature representation and more secured protection on model parameters. This work proposes a vertical federated learning architecture based on variational quantum circuits to demonstrate the competitive performance of a quantum-enhanced pre-trained BERT model for text classification. In particular, our proposed hybrid classical-quantum model consists of a novel random quantum temporal convolution (QTC) learning framework replacing some layers in the BERT-based decoder. Our experiments on intent classification show that our proposed BERT-QTC model attains competitive experimental results in the Snips and ATIS spoken language datasets. Particularly, the BERT-QTC boosts the performance of the existing quantum circuit-based language model in two text classification datasets by 1.57% and 1.52% relative improvements. Furthermore, BERT-QTC can be feasibly deployed on both existing commercial-accessible quantum computation hardware and CPU-based interface for ensuring data isolation.
Holistic Adversarial Robustness of Deep Learning Models
Feb 15, 2022


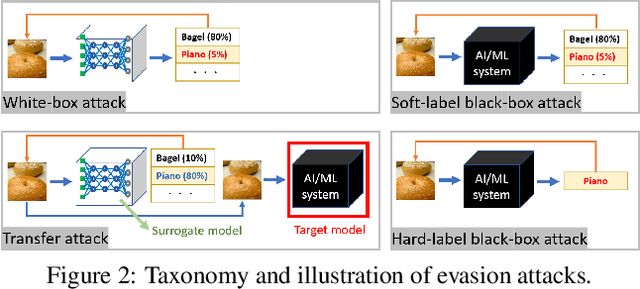
Adversarial robustness studies the worst-case performance of a machine learning model to ensure safety and reliability. With the proliferation of deep-learning based technology, the potential risks associated with model development and deployment can be amplified and become dreadful vulnerabilities. This paper provides a comprehensive overview of research topics and foundational principles of research methods for adversarial robustness of deep learning models, including attacks, defenses, verification, and novel applications.
Towards Compositional Adversarial Robustness: Generalizing Adversarial Training to Composite Semantic Perturbations
Feb 09, 2022Model robustness against adversarial examples of single perturbation type such as the $\ell_{p}$-norm has been widely studied, yet its generalization to more realistic scenarios involving multiple semantic perturbations and their composition remains largely unexplored. In this paper, we firstly propose a novel method for generating composite adversarial examples. By utilizing component-wise projected gradient descent and automatic attack-order scheduling, our method can find the optimal attack composition. We then propose \textbf{generalized adversarial training} (\textbf{GAT}) to extend model robustness from $\ell_{p}$-norm to composite semantic perturbations, such as the combination of Hue, Saturation, Brightness, Contrast, and Rotation. The results on ImageNet and CIFAR-10 datasets show that GAT can be robust not only to any single attack but also to any combination of multiple attacks. GAT also outperforms baseline $\ell_{\infty}$-norm bounded adversarial training approaches by a significant margin.
Auto-Transfer: Learning to Route Transferrable Representations
Feb 04, 2022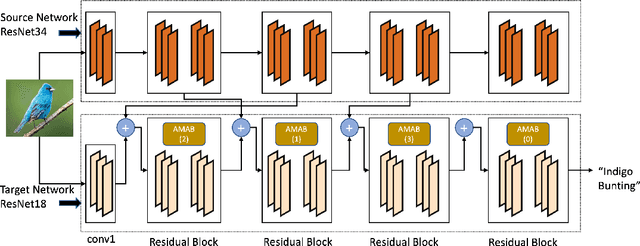
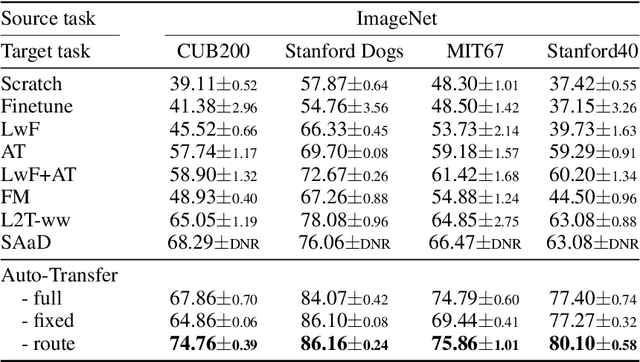
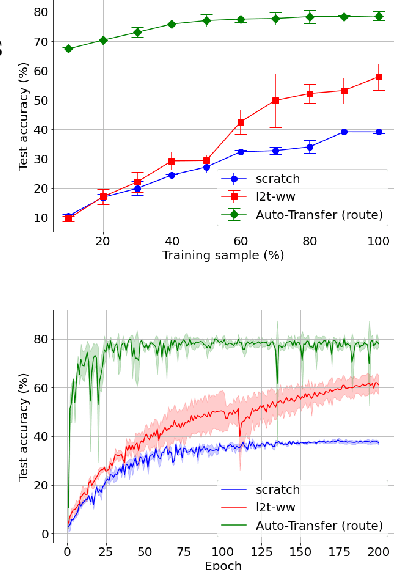

Knowledge transfer between heterogeneous source and target networks and tasks has received a lot of attention in recent times as large amounts of quality labelled data can be difficult to obtain in many applications. Existing approaches typically constrain the target deep neural network (DNN) feature representations to be close to the source DNNs feature representations, which can be limiting. We, in this paper, propose a novel adversarial multi-armed bandit approach which automatically learns to route source representations to appropriate target representations following which they are combined in meaningful ways to produce accurate target models. We see upwards of 5% accuracy improvements compared with the state-of-the-art knowledge transfer methods on four benchmark (target) image datasets CUB200, Stanford Dogs, MIT67, and Stanford40 where the source dataset is ImageNet. We qualitatively analyze the goodness of our transfer scheme by showing individual examples of the important features our target network focuses on in different layers compared with the (closest) competitors. We also observe that our improvement over other methods is higher for smaller target datasets making it an effective tool for small data applications that may benefit from transfer learning.
How does unlabeled data improve generalization in self-training? A one-hidden-layer theoretical analysis
Jan 25, 2022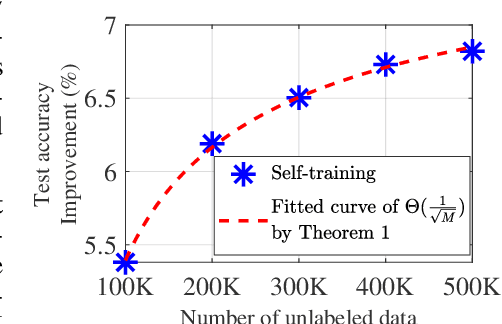

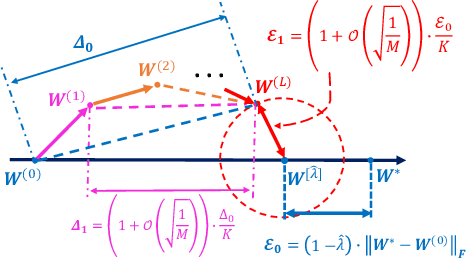
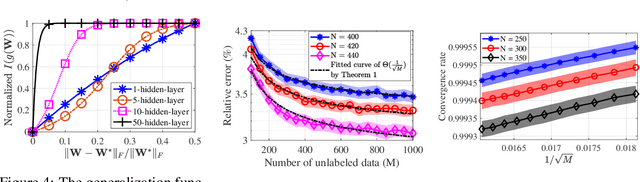
Self-training, a semi-supervised learning algorithm, leverages a large amount of unlabeled data to improve learning when the labeled data are limited. Despite empirical successes, its theoretical characterization remains elusive. To the best of our knowledge, this work establishes the first theoretical analysis for the known iterative self-training paradigm and proves the benefits of unlabeled data in both training convergence and generalization ability. To make our theoretical analysis feasible, we focus on the case of one-hidden-layer neural networks. However, theoretical understanding of iterative self-training is non-trivial even for a shallow neural network. One of the key challenges is that existing neural network landscape analysis built upon supervised learning no longer holds in the (semi-supervised) self-training paradigm. We address this challenge and prove that iterative self-training converges linearly with both convergence rate and generalization accuracy improved in the order of $1/\sqrt{M}$, where $M$ is the number of unlabeled samples. Experiments from shallow neural networks to deep neural networks are also provided to justify the correctness of our established theoretical insights on self-training.
* 15 pages
Neural Capacitance: A New Perspective of Neural Network Selection via Edge Dynamics
Jan 14, 2022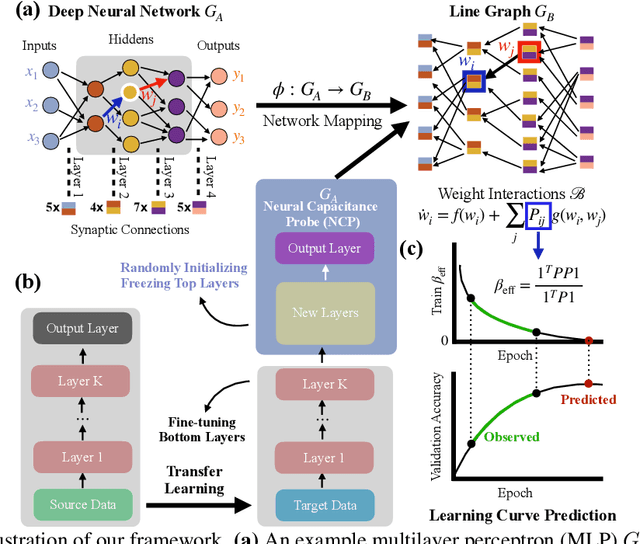
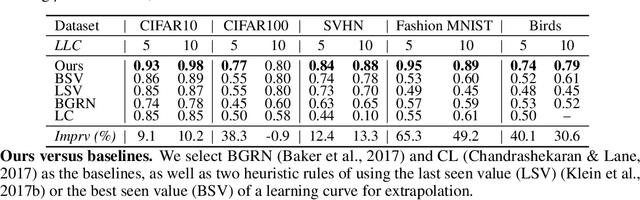
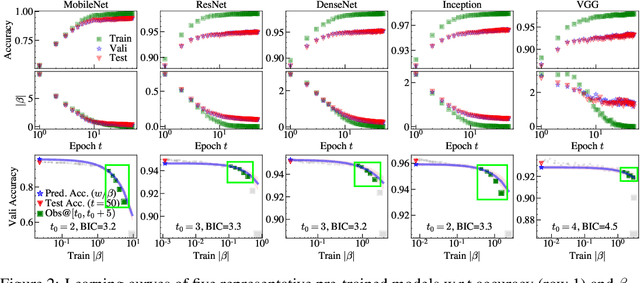
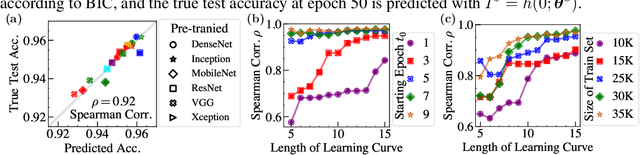
Efficient model selection for identifying a suitable pre-trained neural network to a downstream task is a fundamental yet challenging task in deep learning. Current practice requires expensive computational costs in model training for performance prediction. In this paper, we propose a novel framework for neural network selection by analyzing the governing dynamics over synaptic connections (edges) during training. Our framework is built on the fact that back-propagation during neural network training is equivalent to the dynamical evolution of synaptic connections. Therefore, a converged neural network is associated with an equilibrium state of a networked system composed of those edges. To this end, we construct a network mapping $\phi$, converting a neural network $G_A$ to a directed line graph $G_B$ that is defined on those edges in $G_A$. Next, we derive a neural capacitance metric $\beta_{\rm eff}$ as a predictive measure universally capturing the generalization capability of $G_A$ on the downstream task using only a handful of early training results. We carried out extensive experiments using 17 popular pre-trained ImageNet models and five benchmark datasets, including CIFAR10, CIFAR100, SVHN, Fashion MNIST and Birds, to evaluate the fine-tuning performance of our framework. Our neural capacitance metric is shown to be a powerful indicator for model selection based only on early training results and is more efficient than state-of-the-art methods.